外连接查询
特点:查询结果至少是一个表的所有记录
语法:select f1,f2,f3,....
from table1 left/right outer join table2
on 条件;
(1)左外连接
from table1 left outer join table2
驱动表 table1
匹配表 table2
查询结果是table1驱动表的所有记录
回顾:查询每个员工的姓名,职位和领导的姓名
使用内连接(自连接)的连接方式
分析:
表 t_employee e 员工表
t_employee m 领导表
关联条件 员工表.领导编号=领导表.员工编号
e.MGR=m.empno
select e.ename,e.job,m.ename
from t_employee e inner join t_employee m
on e.MGR=m.empno;
查询结果是13条数据,少了一条king的数据,king没有
上级领导,所以king这条数据没有显出出来。
内连接查询的特点:符合条件查询出来,不符合条件过滤掉。
使用左外连接查询
分析:
驱动表 t_employee e 员工表
匹配表 t_employee m 领导表
关联条件 e.MGR=m.empno
select e.ename,e.job,m.ename
from t_employee e left outer join t_employee m
on e.MGR=m.empno;
查询结果为14条数据,t_employee e员工表为驱动表,
查询结果显示驱动表中所有的数据。
t_employee员工表插入一条在50部门的员工信息。
在t_dept表中只有10,20,30,40部门,没有50部门。
insert into t_employee values(7999,'xiaohong','clerk',7782,19811016,5200,null,50);
说明:
t_employee 员工表
15条数据,员工分别在10,20,30,50部门
t_dept 部门表
4条数据,有10,20,30,40部门
例子:查询每个员工的编号、姓名、职位、部门名称和位置
方式1:使用内连接查询的方式
分析:表 t_employee e 员工表
t_dept d 部门表
关联关系 员工表的部门编号=部门表的部门编号
e.deptno=d.deptno
select e.empno,e.ename,e.job,d.dname,d.loc
from t_employee e inner join t_dept d
on e.deptno=d.deptno;
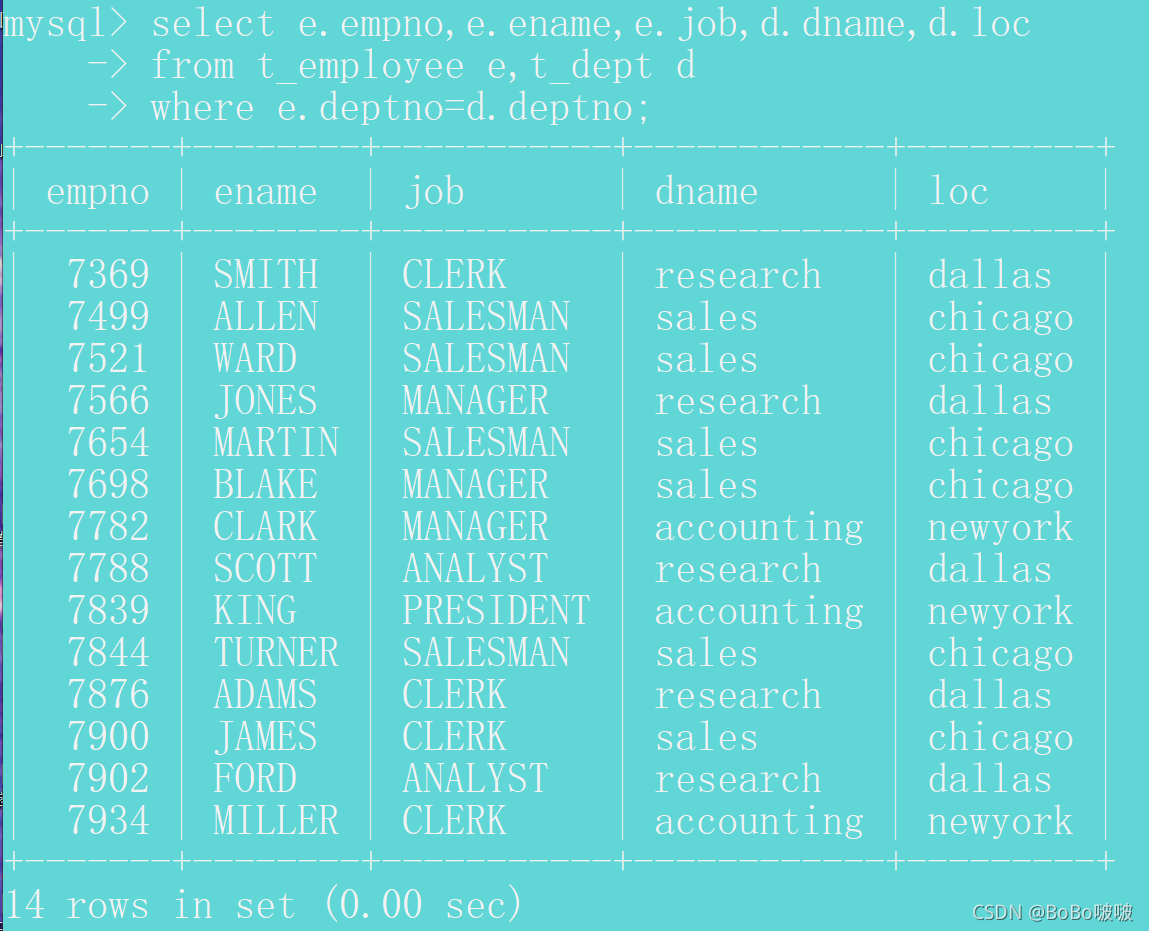
查询结果是14条数据,内连接查询的特点是符合条件的
会查询出结果,不符合条件的会过滤掉。
xiaohong是50部门,在部门表中未匹配到50部门,过滤掉
operations是40部门,未匹配到有员工在40部门,过滤掉
方式2:使用左外连接查询的方式
分析:驱动表 t_employee e 员工表
匹配表 t_dept d 部门表
关联关系 e.deptno=d.deptno
查询的结果是驱动表中的所有数据
select e.empno,e.ename,e.job,d.dname,d.loc
from t_employee e left outer join t_dept d
on e.deptno=d.deptno;
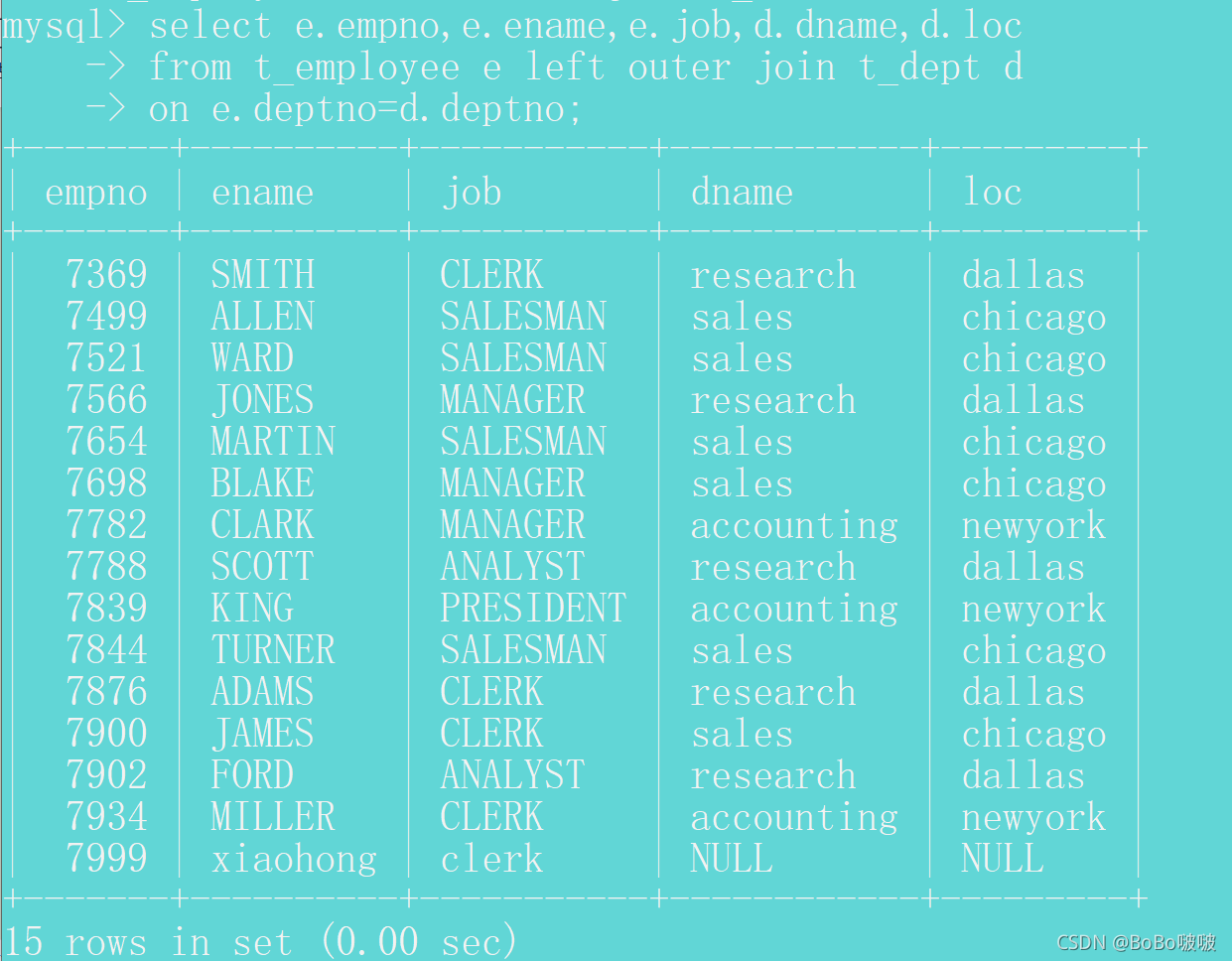
查询结果是15条数据,查询结果是驱动表t_employee表中的全部数据,外连接查询的特点是符合关联条件的正常显示数据,如果不符合关联条件,查询不到数据,会使用null代替。
(2)右外连接
from table1 right outer join table2
驱动表 table2
匹配表 table1
查询结果是table2驱动表的所有记录
使用右外连接的方式
分析:
驱动表 t_dept d 部门表
匹配表 t_employee e 员工表
关联关系 d.deptno=e.deptno
select e.empno,e.ename,d.deptno,d.dname,d.loc
from t_employee e right outer join t_dept d
on e.deptno=d.deptno;

显示结果是15条数据,显示的结果是部门表的全部数据,部门表是4条数据,显示结果是15条,因为有的部门匹配到了多名员工的数据。
10部门20部门30部门都匹配到了多名员工的信息,40部门没有匹配到员工的信息,用null代替。