ЯЕСаЮФеТФПТМ
MySQL(вЛ)ЁЊЁЊЫїв§ЕзВуЪ§ОнНсЙЙгыЫуЗЈ
MySQL(Жў)ЁЊЁЊExplainЯъЧщгыЫїв§зюМбЪЕМљ
MySQL(Ш§)ЁЊЁЊMySQLЕФФкВПзщМўНсЙЙМАbin-logЙщЕЕ
MySQL(ЫФ)ЁЊЁЊMySQLЫїв§гХЛЏЪЕеН
MySQL(Юх)ЁЊЁЊMySQLЫїв§гХЛЏЪЕеН(ЖрБэСЊВщгХЛЏ)
MySQL(Сљ)ЁЊЁЊЩюШыРэНтMySQLЪТЮёИєРыМЖБ№гыЫјЛњжЦ
MySQL(Цп)ЁЊЁЊЩюШыРэНтMVCCгыBufferPoolЛКДцЛњжЦ
MySQLЫїв§гХЛЏЪЕеН(ЖрБэСЊВщгХЛЏ)
ЪЕР§SQL
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT 'аеУћ',
`age` int(11) NOT NULL DEFAULT '0' COMMENT 'ФъСф',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT 'жАЮЛ',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'ШыжАЪБМф',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='дБЙЄМЧТМБэ';
ЗжвГВщбЏгХЛЏ
select * from employees limit 10000,10;
ДгБэ employees жаШЁГіДг 10001 ааПЊЪМЕФ 10 ааМЧТМЁЃПДЫЦжЛВщбЏСЫ 10 ЬѕМЧТМ,ЪЕМЪетЬѕ SQL ЪЧЯШЖСШЁ 10010 ЬѕМЧТМ,ШЛКѓХзЦњЧА 10000 ЬѕМЧТМ,ШЛКѓЖСЕНКѓУц 10 ЬѕЯывЊЕФЪ§ОнЁЃвђДЫвЊВщбЏвЛеХДѓБэБШНЯППКѓЕФЪ§Он,жДаааЇТЪЪЧЗЧГЃЕЭЕФЁЃ
- 1ЁЂИљОнзддіЧвСЌајЕФжїМќХХађЕФЗжвГВщбЏ
explain select * from employees limit 90000,5;
explain select * from employees where id > 90000 limit 5;


НсТл:гХЛЏКѓЕФSQL зпСЫЫїв§,ЖјЧвЩЈУшЕФааЪ§ДѓДѓМѕЩй,жДаааЇТЪИќИпЁЃ
етжжИФаДЕУТњзувдЯТСНИіЬѕМў:
жїМќзддіЧвСЌај
НсЙћЪЧАДеежїМќХХађЕФ
- 2ЁЂИљОнЗЧжїМќзжЖЮХХађЕФЗжвГВщбЏ
explain select * from employees ORDER BY name limit 90000,5;
explain select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;

ЗЂЯжВЂУЛгаЪЙгУ name зжЖЮЕФЫїв§(key зжЖЮЖдгІЕФжЕЮЊ null),ОпЬхдвђ:ЩЈУшећИіЫїв§ВЂВщевЕНУЛЫїв§ЕФаа(ПЩФмвЊБщРњЖрИіЫїв§Ъї)ЕФГЩБОБШЩЈУшШЋБэЕФГЩБОИќИп,ЫљвдгХЛЏЦїЗХЦњЪЙгУЫїв§ЁЃ

ЦфЪЕЙиМќЪЧШУХХађЪБЗЕЛиЕФзжЖЮОЁПЩФмЩй,ЫљвдПЩвдШУХХађКЭЗжвГВйзїЯШВщГіжїМќ,ШЛКѓИљОнжїМќВщЕНЖдгІЕФМЧТМЁЃ
д SQL ЪЙгУЕФЪЧ filesort ХХађ,ЖјгХЛЏКѓЕФ SQL ЪЙгУЕФЪЧЫїв§ХХађЁЃ
JoinЙиСЊВщбЏгХЛЏ
-- ВхШывЛаЉЪОР§Ъ§Он
-- Эљt6БэВхШы1ЭђааМЧТМ
drop procedure if exists insert_t6;
delimiter ;;
create procedure insert_t6()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t6(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t6();
-- Эљt7БэВхШы100ааМЧТМ
drop procedure if exists insert_t7;
delimiter ;;
create procedure insert_t7()
begin
declare i int;
set i=1;
while(i<=100)do
insert into t7(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t7();
mysqlЕФБэЙиСЊГЃМћгаСНжжЫуЗЈ
Nested-Loop Join ЫуЗЈ
Block Nested-Loop Join ЫуЗЈ
1ЁЂ ЧЖЬзбЛЗСЌНг Nested-Loop Join(NLJ) ЫуЗЈ
вЛДЮвЛаабЛЗЕиДгЕквЛеХБэ(ГЦЮЊЧ§ЖЏБэ)жаЖСШЁаа,дкетааЪ§ОнжаШЁЕНЙиСЊзжЖЮ,ИљОнЙиСЊзжЖЮдкСэвЛеХБэ(БЛЧ§ЖЏБэ)РяШЁГіТњзуЬѕМўЕФаа,ШЛКѓШЁГіСНеХБэЕФНсЙћКЯМЏЁЃ
EXPLAIN select * from t6 inner join t7 on t6.a= t7.a;

ДгжДааМЦЛЎжаПЩвдПДЕНетаЉаХЯЂ:
- 1.Ч§ЖЏБэЪЧ t7,БЛЧ§ЖЏБэЪЧ t6ЁЃЯШжДааЕФОЭЪЧЧ§ЖЏБэ(жДааМЦЛЎНсЙћЕФidШчЙћвЛбљдђАДДгЩЯЕНЯТЫГађжДааsql);гХЛЏЦївЛАуЛсгХЯШбЁдёаЁБэзіЧ§ЖЏБэ,гУwhereЬѕМўЙ§ТЫЭъЧ§ЖЏБэ,ШЛКѓдйИњБЛЧ§ЖЏБэзіЙиСЊВщбЏЁЃЫљвдЪЙгУ inner join ЪБ,ХХдкЧАУцЕФБэВЂВЛвЛЖЈОЭЪЧЧ§ЖЏБэЁЃ
- 2.ЕБЪЙгУleft joinЪБ,зѓБэЪЧЧ§ЖЏБэ,гвБэЪЧБЛЧ§ЖЏБэ,ЕБЪЙгУright joinЪБ,гвБэЪБЧ§ЖЏБэ,зѓБэЪЧБЛЧ§ЖЏБэ,ЕБЪЙгУjoinЪБ,mysqlЛсбЁдёЪ§ОнСПБШНЯаЁЕФБэзїЮЊЧ§ЖЏБэ,ДѓБэзїЮЊБЛЧ§ЖЏБэЁЃ
- 3.ЪЙгУСЫ NLJЫуЗЈЁЃвЛАу join гяОфжа,ШчЙћжДааМЦЛЎ Extra жаЮДГіЯж Using join bufferдђБэЪОЪЙгУЕФ join ЫуЗЈЪЧ NLJЁЃ
ЩЯУцsqlЕФДѓжТСїГЬШчЯТ:
ДгБэ t7 жаЖСШЁвЛааЪ§Он(ШчЙћt7БэгаВщбЏЙ§ТЫЬѕМўЕФ,гУЯШгУЬѕМўЙ§ТЫЭъ,дйДгЙ§ТЫНсЙћРяШЁГівЛааЪ§Он);
ДгЕк 1 ВНЕФЪ§Онжа,ШЁГіЙиСЊзжЖЮ a,ЕНБэ t6 жаВщев;
ШЁГіБэ t6 жаТњзуЬѕМўЕФаа,Ињ t7 жаЛёШЁЕНЕФНсЙћКЯВЂ,зїЮЊНсЙћЗЕЛиИјПЭЛЇЖЫ;
жиИДЩЯУц 3 ВНЁЃ
ећИіЙ§ГЬЛсЖСШЁ t7 БэЕФЫљгаЪ§Он(ЩЈУш100аа),ШЛКѓБщРњетУПааЪ§ОнжазжЖЮ a ЕФжЕ,ИљОн t7 Бэжа a ЕФжЕЫїв§ЩЈУш t6 БэжаЕФЖдгІаа(ЩЈУш100ДЮ t6 БэЕФЫїв§,1ДЮЩЈУшПЩвдШЯЮЊзюжежЛЩЈУш t6 БэвЛааЭъећЪ§Он,вВОЭЪЧзмЙВ t6 БэвВЩЈУшСЫ100аа)ЁЃвђДЫећИіЙ§ГЬЩЈУшСЫ 200 ааЁЃ
ШчЙћБЛЧ§ЖЏБэЕФЙиСЊзжЖЮУЛЫїв§,ЪЙгУNLJЫуЗЈадФмЛсБШНЯЕЭ(ЯТУцгаЯъЯИНтЪЭ),mysqlЛсбЁдёBlock Nested-Loop JoinЫуЗЈЁЃ
2ЁЂ ЛљгкПщЕФЧЖЬзбЛЗСЌНг Block Nested-Loop Join(BNL)ЫуЗЈ
АбЧ§ЖЏБэЕФЪ§ОнЖСШыЕН join_buffer жа,ШЛКѓЩЈУшБЛЧ§ЖЏБэ,АбБЛЧ§ЖЏБэУПвЛааШЁГіРДИњ join_buffer жаЕФЪ§ОнзіЖдБШЁЃ
EXPLAIN select * from t6 inner join t7 on t6.b= t7.b;

Extra жа ЕФUsing join buffer (Block Nested Loop)ЫЕУїИУЙиСЊВщбЏЪЙгУЕФЪЧ BNL ЫуЗЈЁЃ
ЩЯУцsqlЕФДѓжТСїГЬШчЯТ:
- 1.Аб t7 ЕФЫљгаЪ§ОнЗХШыЕН join_buffer жа
- 2.АбБэ t6 жаУПвЛааШЁГіРД,Ињ join_buffer жаЕФЪ§ОнзіЖдБШ
- 3.ЗЕЛиТњзу join ЬѕМўЕФЪ§Он
ећИіЙ§ГЬЖдБэ t6 КЭ t7 ЖМзіСЫвЛДЮШЋБэЩЈУш,вђДЫЩЈУшЕФзмааЪ§ЮЊ10000(Бэ t6 ЕФЪ§ОнзмСП) + 100(Бэ t7 ЕФЪ§ОнзмСП) = 10100ЁЃВЂЧв join_buffer РяЕФЪ§ОнЪЧЮоађЕФ,вђДЫЖдБэ t6 жаЕФУПвЛаа,ЖМвЊзі 100 ДЮХаЖЯ,ЫљвдФкДцжаЕФХаЖЯДЮЪ§ЪЧ 100 * 10000= 100 ЭђДЮЁЃ
етИіР§згРяБэ t7 ВХ 100 аа,вЊЪЧБэ t7 ЪЧвЛИіДѓБэ,join_buffer ЗХВЛЯТдѕУДАьФи?ЁЄ
join_buffer ЕФДѓаЁЪЧгЩВЮЪ§ join_buffer_size ЩшЖЈЕФ,ФЌШЯжЕЪЧ 256kЁЃШчЙћЗХВЛЯТБэ t7 ЕФЫљгаЪ§ОнЕФЛА,ВпТдКмМђЕЅ,ОЭЪЧЗжЖЮЗХЁЃ
БШШч t7 Бэга1000ааМЧТМ, join_buffer вЛДЮжЛФмЗХ800ааЪ§Он,ФЧУДжДааЙ§ГЬОЭЪЧЯШЭљ join_buffer РяЗХ800ааМЧТМ,ШЛКѓДг t6 БэРяШЁЪ§ОнИњ join_buffer жаЪ§ОнЖдБШЕУЕНВПЗжНсЙћ,ШЛКѓЧхПе join_buffer ,дйЗХШы t7 БэЪЃгр200ааМЧТМ,дйДЮДг t6 БэРяШЁЪ§ОнИњ join_buffer жаЪ§ОнЖдБШЁЃЫљвдОЭЖрЩЈСЫвЛДЮ t6 БэЁЃ
БЛЧ§ЖЏБэЕФЙиСЊзжЖЮУЛЫїв§ЮЊЪВУДвЊбЁдёЪЙгУ BNL ЫуЗЈЖјВЛЪЙгУ Nested-Loop Join Фи?
ШчЙћЩЯУцЕкЖўЬѕsqlЪЙгУ Nested-Loop Join,ФЧУДЩЈУшааЪ§ЮЊ 100 * 10000 = 100ЭђДЮ,етИіЪЧДХХЬЩЈУшЁЃ
КмЯдШЛ,гУBNLДХХЬЩЈУшДЮЪ§ЩйКмЖр,ЯрБШгкДХХЬЩЈУш,BNLЕФФкДцМЦЫуЛсПьЕУЖрЁЃ
вђДЫMySQLЖдгкБЛЧ§ЖЏБэЕФЙиСЊзжЖЮУЛЫїв§ЕФЙиСЊВщбЏ,вЛАуЖМЛсЪЙгУ BNL ЫуЗЈЁЃШчЙћгаЫїв§вЛАубЁдё NLJ ЫуЗЈ,гаЫїв§ЕФЧщПіЯТ NLJ ЫуЗЈБШ BNLЫуЗЈадФмИќИп
ЖдгкЙиСЊsqlЕФгХЛЏ
- ЙиСЊзжЖЮМгЫїв§,ШУmysqlзіjoinВйзїЪБОЁСПбЁдёNLJЫуЗЈ,Ч§ЖЏБэвђЮЊашвЊШЋВПВщбЏГіРД,ЫљвдЙ§ТЫЕФЬѕМўвВОЁСПвЊзпЫїв§,БмУтШЋБэЩЈУш,змжЎ,ФмзпЫїв§ЕФЙ§ТЫЬѕМўОЁСПЖМзпЫїв§
- аЁБэЧ§ЖЏДѓБэ,аДЖрБэСЌНгsqlЪБШчЙћУїШЗжЊЕРФФеХБэЪЧаЁБэПЩвдгУstraight_joinаДЗЈЙЬЖЈСЌНгЧ§ЖЏЗНЪН,ЪЁШЅmysqlгХЛЏЦїздМКХаЖЯЕФЪБМф
straight_joinНтЪЭ:straight_joinЙІФмЭЌjoinРрЫЦ,ЕЋФмШУзѓБпЕФБэРДЧ§ЖЏгвБпЕФБэ,ФмИФБэгХЛЏЦїЖдгкСЊБэВщбЏЕФжДааЫГађЁЃ
БШШч:select * from t2 straight_join t1 on t2.a = t1.a; ДњБэжИЖЈmysqlбЁзХ t2 БэзїЮЊЧ§ЖЏБэЁЃ
straight_joinжЛЪЪгУгкinner join,ВЂВЛЪЪгУгкleft join,right joinЁЃ(вђЮЊleft join,right joinвбОДњБэжИЖЈСЫБэЕФжДааЫГађ)
ОЁПЩФмШУгХЛЏЦїШЅХаЖЯ,вђЮЊДѓВПЗжЧщПіЯТmysqlгХЛЏЦїЪЧБШШЫвЊДЯУїЕФЁЃЪЙгУstraight_joinвЛЖЈвЊЩїжи,вђЮЊВПЗжЧщПіЯТШЫЮЊжИЖЈЕФжДааЫГађВЂВЛвЛЖЈЛсБШгХЛЏв§ЧцвЊППЦзЁЃ
ЖдгкаЁБэЖЈвхЕФУїШЗ
дкОіЖЈФФИіБэзіЧ§ЖЏБэЕФЪБКђ,гІИУЪЧСНИіБэАДееИїздЕФЬѕМўЙ§ТЫ,Й§ТЫЭъГЩжЎКѓ,МЦЫуВЮгы join ЕФИїИізжЖЮЕФзмЪ§ОнСП,Ъ§ОнСПаЁЕФФЧИіБэ,ОЭЪЧЁАаЁБэЁБ,гІИУзїЮЊЧ§ЖЏБэЁЃ
inКЭexsitsгХЛЏ
ддђ:аЁБэЧ§ЖЏДѓБэ,МДаЁЕФЪ§ОнМЏЧ§ЖЏДѓЕФЪ§ОнМЏ
in:ЕБBБэЕФЪ§ОнМЏаЁгкAБэЕФЪ§ОнМЏЪБ,inгХгкexists
select * from A where id in (select id from B)
#ЕШМлгк:
ЁЁЁЁfor(select id from B){
select * from A where A.id = B.id
}
exists:ЕБAБэЕФЪ§ОнМЏаЁгкBБэЕФЪ§ОнМЏЪБ,existsгХгкin
НЋжїВщбЏAЕФЪ§Он,ЗХЕНзгВщбЏBжазіЬѕМўбщжЄ,ИљОнбщжЄНсЙћ(trueЛђfalse)РДОіЖЈжїВщбЏЕФЪ§ОнЪЧЗёБЃСє
select * from A where exists (select 1 from B where B.id = A.id)
#ЕШМлгк:
for(select * from A){
select * from B where B.id = A.id
}
#AБэгыBБэЕФIDзжЖЮгІНЈСЂЫїв§
1ЁЂEXISTS (subquery)жЛЗЕЛиTRUEЛђFALSE,вђДЫзгВщбЏжаЕФSELECT * вВПЩвдгУSELECT 1ЬцЛЛ,ЙйЗНЫЕЗЈЪЧЪЕМЪжДааЪБЛсКіТдSELECTЧхЕЅ,вђДЫУЛгаЧјБ№
2ЁЂEXISTSзгВщбЏЕФЪЕМЪжДааЙ§ГЬПЩФмОЙ§СЫгХЛЏЖјВЛЪЧЮвУЧРэНтЩЯЕФж№ЬѕЖдБШ
3ЁЂEXISTSзгВщбЏЭљЭљвВПЩвдгУJOINРДДњЬц,КЮжжзюгХашвЊОпЬхЮЪЬтОпЬхЗжЮі
count(*)ВщбЏгХЛЏ
-- СйЪБЙиБеmysqlВщбЏЛКДц,ЮЊСЫВщПДsqlЖрДЮжДааЕФецЪЕЪБМф
set global query_cache_size=0;
set global query_cache_type=0;
EXPLAIN select count(1) from employees;
EXPLAIN select count(id) from employees;
EXPLAIN select count(name) from employees;
EXPLAIN select count(*) from employees;
зЂвт:вдЩЯ4ЬѕsqlжЛгаИљОнФГИізжЖЮcountВЛЛсЭГМЦзжЖЮЮЊnullжЕЕФЪ§Онаа
ЫФИіsqlЕФжДааМЦЛЎвЛбљ,ЫЕУїетЫФИіsqlжДаааЇТЪгІИУВюВЛЖр
зжЖЮгаЫїв§:count(*)Ёжcount(1)>count(зжЖЮ)>count(жїМќ id)
зжЖЮгаЫїв§,count(зжЖЮ)ЭГМЦзпЖўМЖЫїв§,ЖўМЖЫїв§ДцДЂЪ§ОнБШжїМќЫїв§Щй,Ыљвдcount(зжЖЮ)>count(жїМќ id)
зжЖЮЮоЫїв§:count(*)Ёжcount(1)>count(жїМќ id)>count(зжЖЮ)
зжЖЮУЛгаЫїв§count(зжЖЮ)ЭГМЦзпВЛСЫЫїв§,count(жїМќ id)ЛЙПЩвдзпжїМќЫїв§,Ыљвдcount(жїМќ id)>count(зжЖЮ)
count(1)Ињcount(зжЖЮ)жДааЙ§ГЬРрЫЦ,ВЛЙ§count(1)ВЛашвЊШЁГізжЖЮЭГМЦ,ОЭгУГЃСП1зіЭГМЦ,count(зжЖЮ)ЛЙашвЊШЁГізжЖЮ,ЫљвдРэТлЩЯcount(1)БШcount(зжЖЮ)ЛсПьвЛЕуЁЃ
count( * ) ЪЧР§Эт,mysqlВЂВЛЛсАбШЋВПзжЖЮШЁГіРД,ЖјЪЧзЈУХзіСЫгХЛЏ,ВЛШЁжЕ,АДааРлМг,аЇТЪКмИп,ЫљвдВЛашвЊгУcount(СаУћ)Лђcount(ГЃСП)РДЬцДњ count(*)ЁЃ
ЮЊЪВУДЖдгкcount(id),mysqlзюжебЁдёИЈжњЫїв§ЖјВЛЪЧжїМќОлМЏЫїв§?вђЮЊЖўМЖЫїв§ЯрЖджїМќЫїв§ДцДЂЪ§ОнИќЩй,МьЫїадФмгІИУИќИп,mysqlФкВПзіСЫЕугХЛЏ(гІИУЪЧдк5.7АцБОВХгХЛЏ)ЁЃ
ГЃМћгХЛЏЗНЗЈ
1ЁЂВщбЏmysqlздМКЮЌЛЄЕФзмааЪ§
ЖдгкmyisamДцДЂв§ЧцЕФБэзіВЛДјwhereЬѕМўЕФcountВщбЏадФмЪЧКмИпЕФ,вђЮЊmyisamДцДЂв§ЧцЕФБэЕФзмааЪ§ЛсБЛmysqlДцДЂдкДХХЬЩЯ,ВщбЏВЛашвЊМЦЫу

ЖдгкinnodbДцДЂв§ЧцЕФБэmysqlВЛЛсДцДЂБэЕФзмМЧТМааЪ§(вђЮЊгаMVCCЛњжЦ,КѓУцЛсНВ),ВщбЏcountашвЊЪЕЪБМЦЫу
2ЁЂshow table status
ШчЙћжЛашвЊжЊЕРБэзмааЪ§ЕФЙРМЦжЕПЩвдгУШчЯТsqlВщбЏ,адФмКмИп
show table status like 'employees';
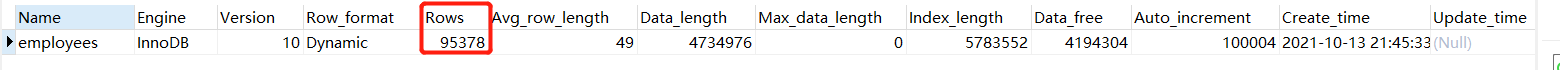
3ЁЂНЋзмЪ§ЮЌЛЄЕНRedisРя
ВхШыЛђЩОГ§БэЪ§ОнааЕФЪБКђЭЌЪБЮЌЛЄredisРяЕФБэзмааЪ§keyЕФМЦЪ§жЕ(гУincrЛђdecrУќСю),ЕЋЪЧетжжЗНЪНПЩФмВЛзМ,КмФбБЃжЄБэВйзїКЭredisВйзїЕФЪТЮёвЛжТад
4ЁЂдіМгЪ§ОнПтМЦЪ§Бэ
ВхШыЛђЩОГ§БэЪ§ОнааЕФЪБКђЭЌЪБЮЌЛЄМЦЪ§Бэ,ШУЫћУЧдкЭЌвЛИіЪТЮёРяВйзї
MySQLЪ§ОнРраЭбЁдё
дкMySQLжа,бЁдёе§ШЗЕФЪ§ОнРраЭ,ЖдгкадФмжСЙиживЊЁЃвЛАугІИУзёбЯТУцСНВН:
(1)ШЗЖЈКЯЪЪЕФДѓРраЭ:Ъ§зжЁЂзжЗћДЎЁЂЪБМфЁЂЖўНјжЦ;
(2)ШЗЖЈОпЬхЕФРраЭ:гаЮоЗћКХЁЂШЁжЕЗЖЮЇЁЂБфГЄЖЈГЄЕШЁЃ
дкMySQLЪ§ОнРраЭЩшжУЗНУц,ОЁСПгУИќаЁЕФЪ§ОнРраЭ,вђЮЊЫќУЧЭЈГЃгаИќКУЕФадФм,ЛЈЗбИќЩйЕФгВМўзЪдДЁЃВЂЧв,ОЁСПАбзжЖЮЖЈвхЮЊNOT NULL,БмУтЪЙгУNULLЁЃ
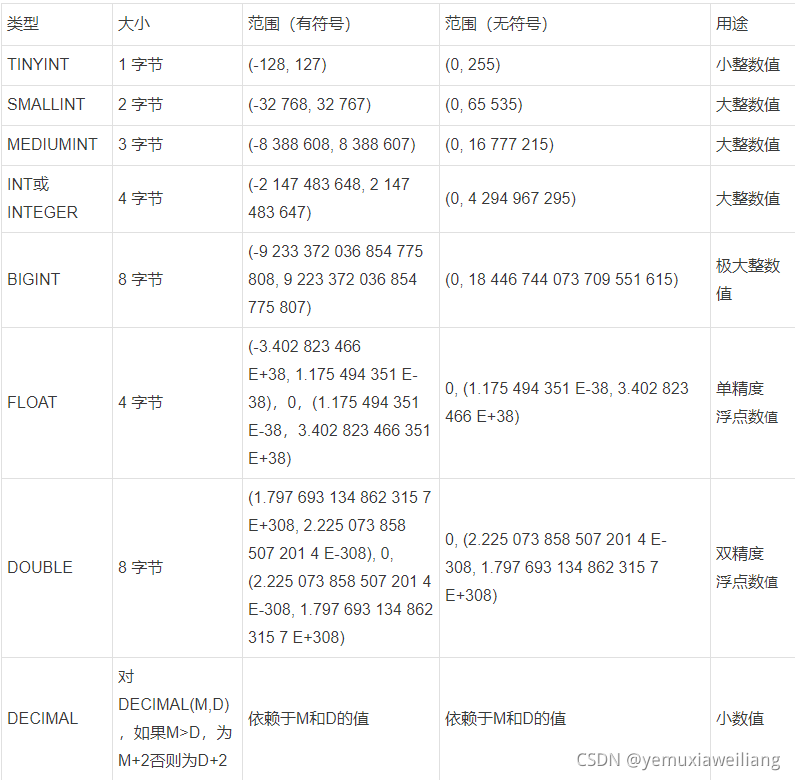
1ЁЂЪ§жЕРраЭ
гХЛЏНЈвщ
- 1.ШчЙћећаЮЪ§ОнУЛгаИКЪ§,ШчIDКХ,НЈвщжИЖЈЮЊUNSIGNEDЮоЗћКХРраЭ,ШнСППЩвдРЉДѓвЛБЖЁЃ
- 2.НЈвщЪЙгУTINYINTДњЬцENUMЁЂBITENUMЁЂSETЁЃ
- 3.БмУтЪЙгУећЪ§ЕФЯдЪОПэЖШ(ВЮПДЮФЕЕзюКѓ),вВОЭЪЧЫЕ,ВЛвЊгУINT(10)РрЫЦЕФЗНЗЈжИЖЈзжЖЮЯдЪОПэЖШ,жБНггУINTЁЃ
- 4.DECIMALзюЪЪКЯБЃДцзМШЗЖШвЊЧѓИп,ЖјЧвгУгкМЦЫуЕФЪ§Он,БШШчМлИёЁЃЕЋЪЧдкЪЙгУDECIMALРраЭЕФЪБКђ,зЂвтГЄЖШЩшжУЁЃ
- 5.НЈвщЪЙгУећаЮРраЭРДдЫЫуКЭДцДЂЪЕЪ§,ЗНЗЈЪЧ,ЪЕЪ§ГЫвдЯргІЕФБЖЪ§КѓдйВйзїЁЃ
- 6.ећЪ§ЭЈГЃЪЧзюМбЕФЪ§ОнРраЭ,вђЮЊЫќЫйЖШПь,ВЂЧвФмЪЙгУAUTO_INCREMENTЁЃ
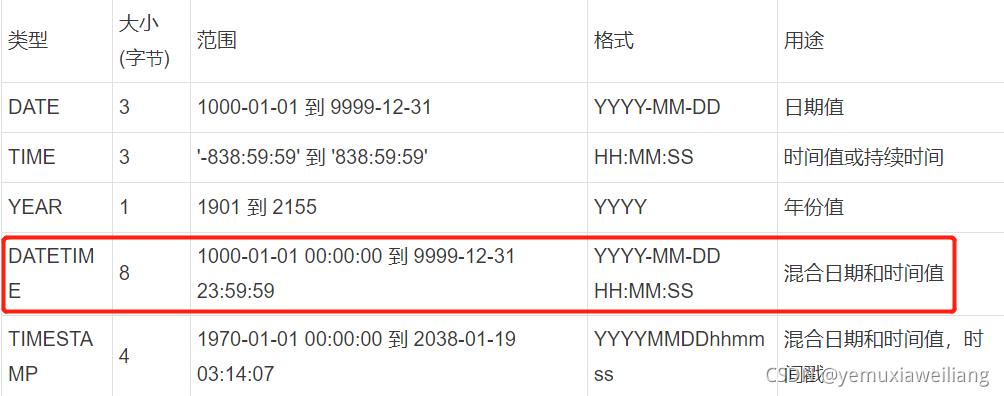
2ЁЂШеЦкКЭЪБМф
гХЛЏНЈвщ
- 1.MySQLФмДцДЂЕФзюаЁЪБМфСЃЖШЮЊУыЁЃ
- 2.НЈвщгУDATEЪ§ОнРраЭРДБЃДцШеЦкЁЃMySQLжаФЌШЯЕФШеЦкИёЪНЪЧyyyy-mm-ddЁЃ
- 3.гУMySQLЕФФкНЈРраЭDATEЁЂTIMEЁЂDATETIMEРДДцДЂЪБМф,ЖјВЛЪЧЪЙгУзжЗћДЎЁЃ
- 4.ЕБЪ§ОнИёЪНЮЊTIMESTAMPКЭDATETIMEЪБ,ПЩвдгУCURRENT_TIMESTAMPзїЮЊФЌШЯ(MySQL5.6вдКѓ),MySQLЛсздЖЏЗЕЛиМЧТМВхШыЕФШЗЧаЪБМфЁЃ
- 5.TIMESTAMPЪЧUTCЪБМфДС,гыЪБЧјЯрЙиЁЃ
- 6.DATETIMEЕФДцДЂИёЪНЪЧвЛИіYYYYMMDD HH:MM:SSЕФећЪ§,гыЪБЧјЮоЙи,ФуДцСЫЪВУД,ЖСГіРДОЭЪЧЪВУДЁЃ
- 7.Г§ЗЧгаЬиЪташЧѓ,вЛАуЕФЙЋЫОНЈвщЪЙгУTIMESTAMP,ЫќБШDATETIMEИќНкдМПеМф,ЕЋЪЧЯёАЂРяетбљЕФЙЋЫОвЛАуЛсгУDATETIME,вђЮЊВЛгУПМТЧTIMESTAMPНЋРДЕФЪБМфЩЯЯоЮЪЬтЁЃ
- 8.гаЪБШЫУЧАбUnixЕФЪБМфДСБЃДцЮЊећЪ§жЕ,ЕЋЪЧетЭЈГЃУЛгаШЮКЮКУДІ,етжжИёЪНДІРэЦ№РДВЛЬЋЗНБу,ЮвУЧВЂВЛЭЦМіЫќЁЃ
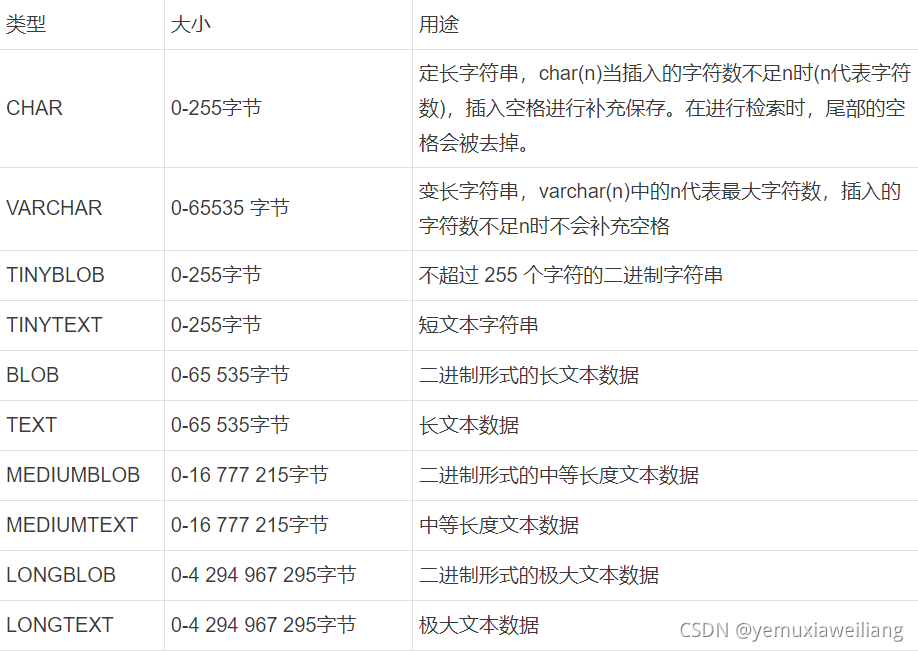
3ЁЂзжЗћДЎ
гХЛЏНЈвщ
- 1.зжЗћДЎЕФГЄЖШЯрВюНЯДѓгУVARCHAR;зжЗћДЎЖЬ,ЧвЫљгажЕЖМНгНќвЛИіГЄЖШгУCHARЁЃ
- 2.CHARКЭVARCHARЪЪгУгкАќРЈШЫУћЁЂгЪеўБрТыЁЂЕчЛАКХТыКЭВЛГЌЙ§255ИізжЗћГЄЖШЕФШЮвтзжФИЪ§зжзщКЯЁЃФЧаЉвЊгУРДМЦЫуЕФЪ§зжВЛвЊгУVARCHARРраЭБЃДц,вђЮЊПЩФмЛсЕМжТвЛаЉгыМЦЫуЯрЙиЕФЮЪЬтЁЃЛЛОфЛАЫЕ,ПЩФмгАЯьЕНМЦЫуЕФзМШЗадКЭЭъећадЁЃ
- 3.ОЁСПЩйгУBLOBКЭTEXT,ШчЙћЪЕдквЊгУПЩвдПМТЧНЋBLOBКЭTEXTзжЖЮЕЅЖРДцвЛеХБэ,гУidЙиСЊЁЃ
- 4.BLOBЯЕСаДцДЂЖўНјжЦзжЗћДЎ,гызжЗћМЏЮоЙиЁЃTEXTЯЕСаДцДЂЗЧЖўНјжЦзжЗћДЎ,гызжЗћМЏЯрЙиЁЃ
- 5.BLOBКЭTEXTЖМВЛФмгаФЌШЯжЕЁЃ
4.INTЯдЪОПэЖШ
ЮвУЧОГЃЛсЪЙгУУќСюРДДДНЈЪ§ОнБэ,ЖјЧвЭЌЪБЛсжИЖЈвЛИіГЄЖШ,ШчЯТЁЃЕЋЪЧ,етРяЕФГЄЖШВЂЗЧЪЧTINYINTРраЭДцДЂЕФзюДѓГЄЖШ,ЖјЪЧЯдЪОЕФзюДѓГЄЖШЁЃ
CREATE TABLE `user`(
`id` TINYINT(2) UNSIGNED
);
етРяБэЪОuserБэЕФidзжЖЮЕФРраЭЪЧTINYINT,ПЩвдДцДЂЕФзюДѓЪ§жЕЪЧ255ЁЃЫљвд,дкДцДЂЪ§ОнЪБ,ШчЙћДцШыжЕаЁгкЕШгк255,Шч200,ЫфШЛГЌЙ§2ЮЛ,ЕЋЪЧУЛгаГЌГіTINYINTРраЭГЄЖШ,ЫљвдПЩвде§ГЃБЃДц;ШчЙћДцШыжЕДѓгк255,Шч500,ФЧУДMySQLЛсздЖЏБЃДцЮЊTINYINTРраЭЕФзюДѓжЕ255ЁЃ
дкВщбЏЪ§ОнЪБ,ВЛЙмВщбЏНсЙћЮЊКЮжЕ,ЖМАДЪЕМЪЪфГіЁЃетРяTINYINT(2)жа2ЕФзїгУОЭЪЧ,ЕБашвЊдкВщбЏНсЙћЧАЬюГф0ЪБ,УќСюжаМгЩЯZEROFILLОЭПЩвдЪЕЯж,Шч:
`id` TINYINT(2) UNSIGNED ZEROFILL
етбљ,ВщбЏНсЙћШчЙћЪЧ5,ФЧЪфГіОЭЪЧ05ЁЃШчЙћжИЖЈTINYINT(5),ФЧЪфГіОЭЪЧ00005,ЦфЪЕЪЕМЪДцДЂЕФжЕЛЙЪЧ5,ЖјЧвДцДЂЕФЪ§ОнВЛЛсГЌЙ§255,жЛЪЧMySQLЪфГіЪ§ОнЪБдкЧАУцЬюГфСЫ0ЁЃ
ЛЛОфЛАЫЕ,дкMySQLУќСюжа,зжЖЮЕФРраЭГЄЖШTINYINT(2)ЁЂINT(11)ВЛЛсгАЯьЪ§ОнЕФВхШы,жЛЛсдкЪЙгУZEROFILLЪБгагУ,ШУВщбЏНсЙћЧАЬюГф0ЁЃ