索引是为了快速查找数据的一种有序的数据结构。
不选择二叉树作为索引的存储结构的原因
二叉树的每个节点有2个子节点,当插入数据量较大的时候会导致树非常高,增大了IO的次数,导致读取数据变慢。而选择好的数据结构来减少IO次数是高效查询的关键。因此,B树与B+树应运而生。
B树
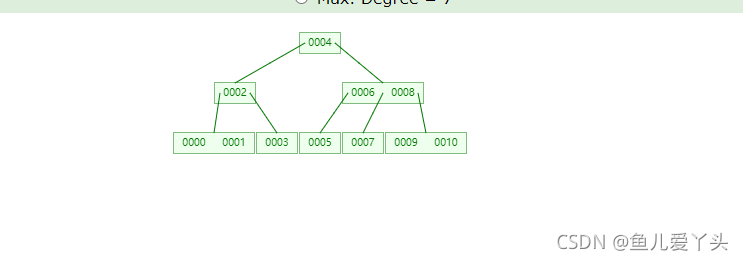
B树上的节点上存在数据,假设每个节点对应一个磁盘块,之多可以存储16条数据,那么三层高的树就能存16的三次方条数据,但是每一条数据都包含了指针,key和data,所以占用空间很大,能存储的的数据就相对来说比较少,因此B+树应运而生。
B+树
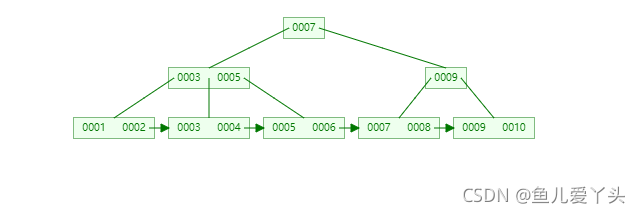
B+树相对于B树来说叶子节点之间存在节点之间的双向指针,同时非叶子节点只存储指针和Key值,不存储data,那么非叶子节点就可以存储成倍数的key。一般情况下三到四层的B+树可以存储上千万的数据。
在设计索引的时候应该尽可能少的让索引占用较少的空间(字段的长度)。
自增id和uuid的选择
自增id优点: 插入有序.在innodb引擎下,查询和插入速度快,占用空间小
自增id缺点: 多表合并和数据迁移会有id冲突,高并发的情况下,竞争自增锁会降低数据库的吞吐能力,容易被人知晓业务量,会被爬虫设定。
uuid优点: 生成唯一id不会冲突
uuid缺点: 占用空间大,插入和查询速度慢,读取出来的数据也是没有规律的,通常需要order by,其实也很消耗数据库资源,表中数据是按照主键顺序存放的。也就是说,如果发生了随机io,那么就会频繁地移动磁盘块。当数据量大的时候,写的短板将非常明显。
数据量较大的项目或者对读写速度有要求的项目中推荐使用自增id。