Ŀ¼
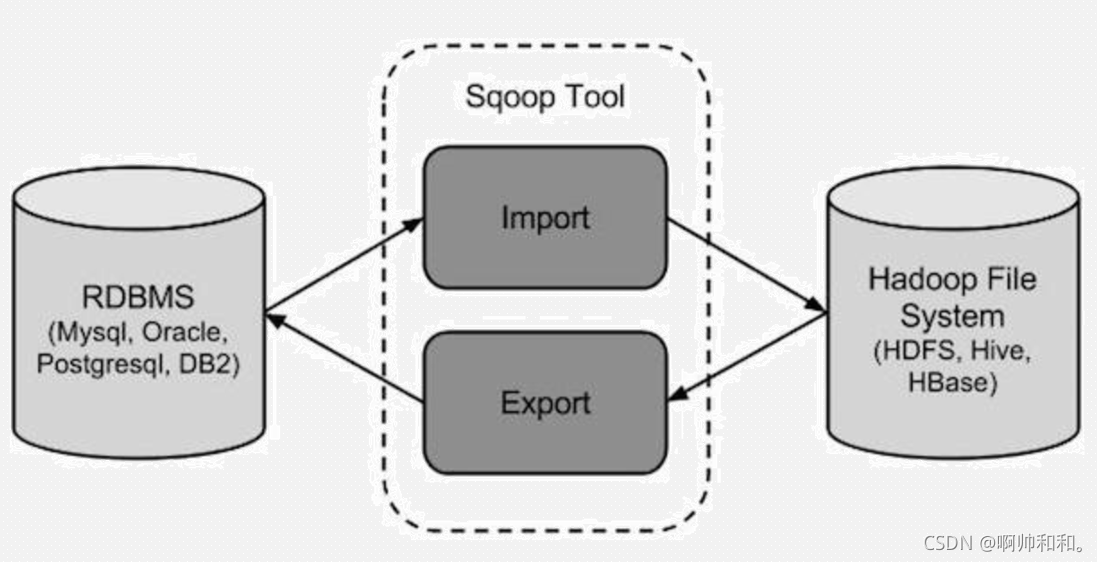
sqoop��һ�����ݼ��ɹ���,��Ҫ�����칹����Դ�Ļ��ർ��,Ҳ����
���Խ���ϵ�����ݿ������(����MySQL������)����HDFS��,���ߴ�HDFS�е��뵽��ϵ�����ݿ���
���Dz����Լ������Լ�,Ҳ����˵,�����Լ���MySQL���뵽MySQL,���ܴ�HDFS���뵽HDFS
import
�Ӵ�ͳ��ϵ�����ݿ�뵽HDFS��HIVE��HBASE��
��ͳ��ϵ�����ݵ����뵽HDFS
��д�ű�:
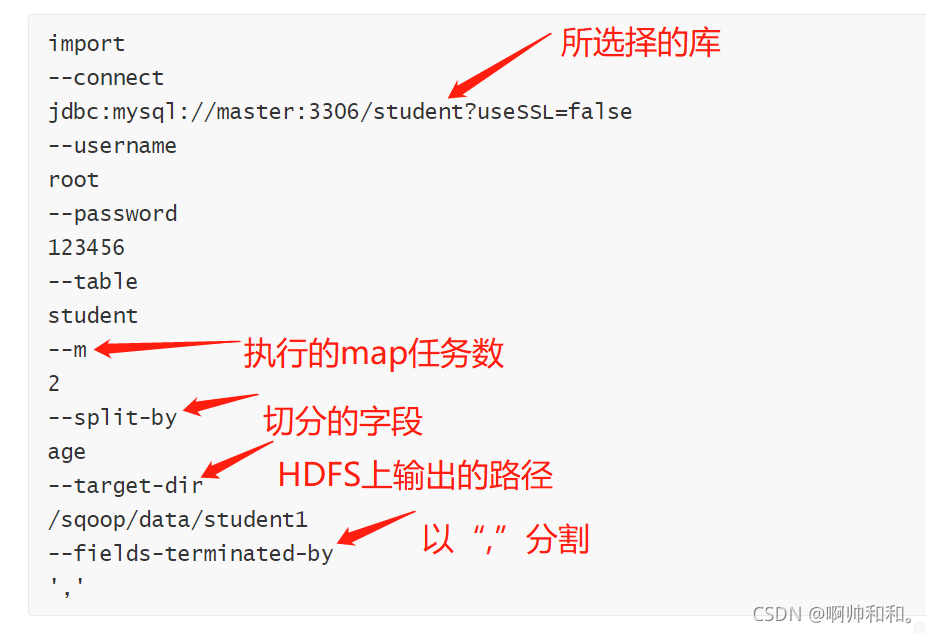
ִ�нű�:
sqoop --options-file /opt/datas/sql/MYSQLtoHDFS.conf
ִ�гɹ�
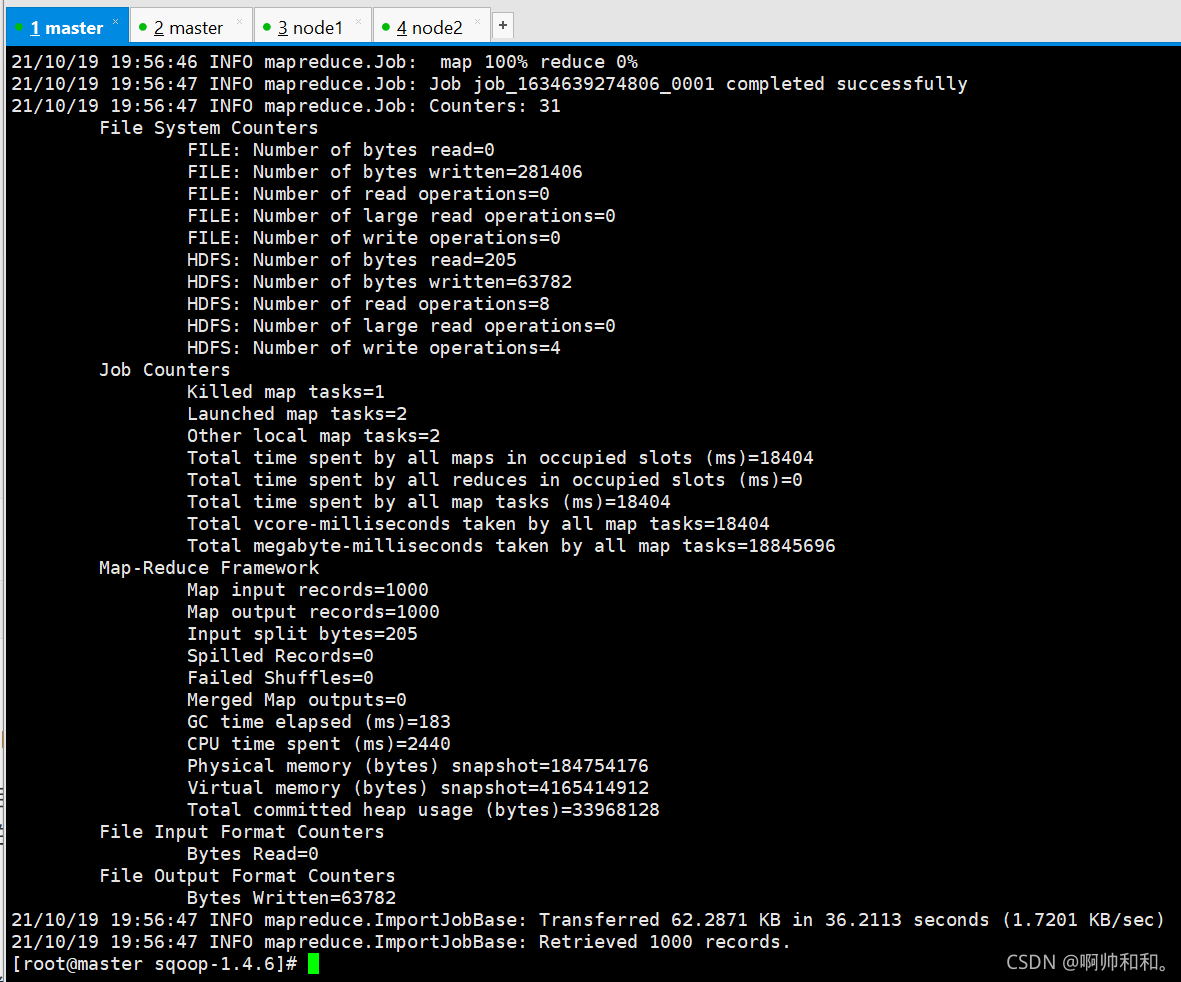
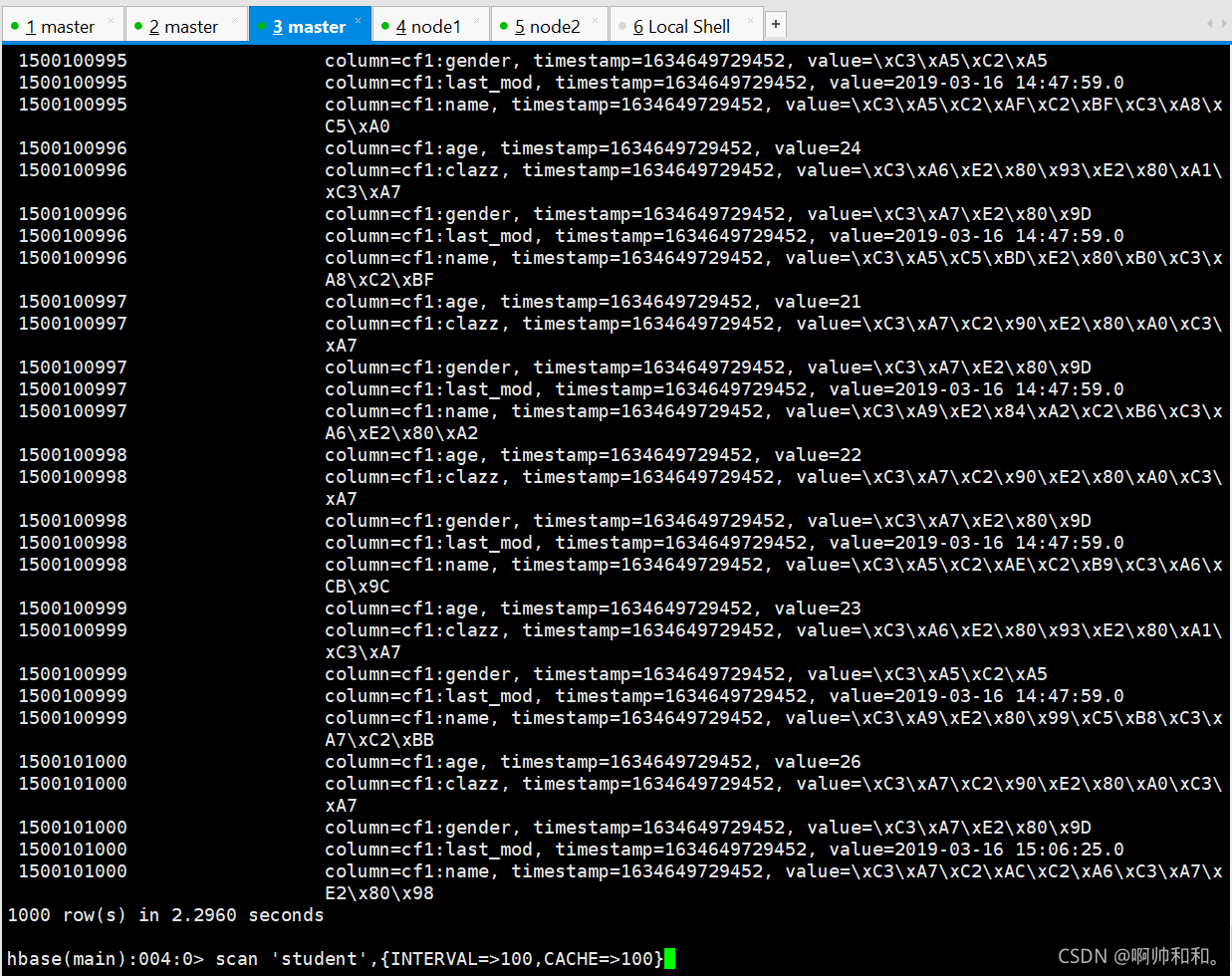
��age��Ϊ�ָ�,����������map��������Ϊ2֮��,�õ��������ļ�(������Կ�������Ϊpart-m-00000��part-m-00001,���е�mָ����map)
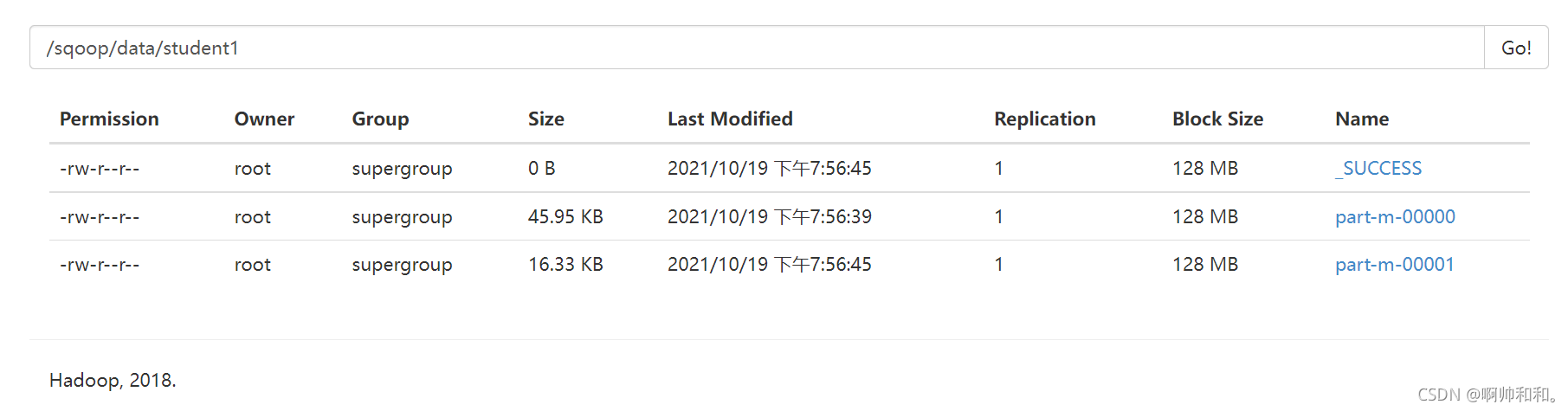
ע������
ע������:
1���Cm ��ʾָ�����ɶ��ٸ�Map����,����Խ��Խ��,��ΪMySQL Server�ij�����������
2����ָ����Map������>1,��ô��Ҫ���--split-by����,ָ���ָ��,��ȷ��ÿ��map����ȡ��һ��������,���ָ����ֵ�͵���,���ָ������(���߷ֲ����ȵ���=>����ÿ��map��������������������)
3�����ָ���ķָ�����ݷֲ�����,���ܵ���������б����
4���ָ�ļ����ָ����ֵ�͵�,�����ֶε�����Ϊint��bigint��������ֵ��
5����д�ű���ʱ��,ע��:����:--username����,����ֵ���ܺͲ�����ͬһ��
�Cusername root // �����
// Ӧ�÷ֳ�����
�Cusername
root
6��ʵ����sqoop�ڶ�ȡmysql���ݵ�ʱ��,�õ���JDBC�ķ�ʽ,���Ե����������ʱ��,Ч�ʲ��Ǻܸ�
7��sqoop�ײ�ͨ��MapReduce������ݵ��뵼��,ֻ��ҪMap����,����ҪReduce����
8��ÿ��Map���������һ���ļ�
��ͳ��ϵ�����ݵ����뵽HIVE
��д�ű�
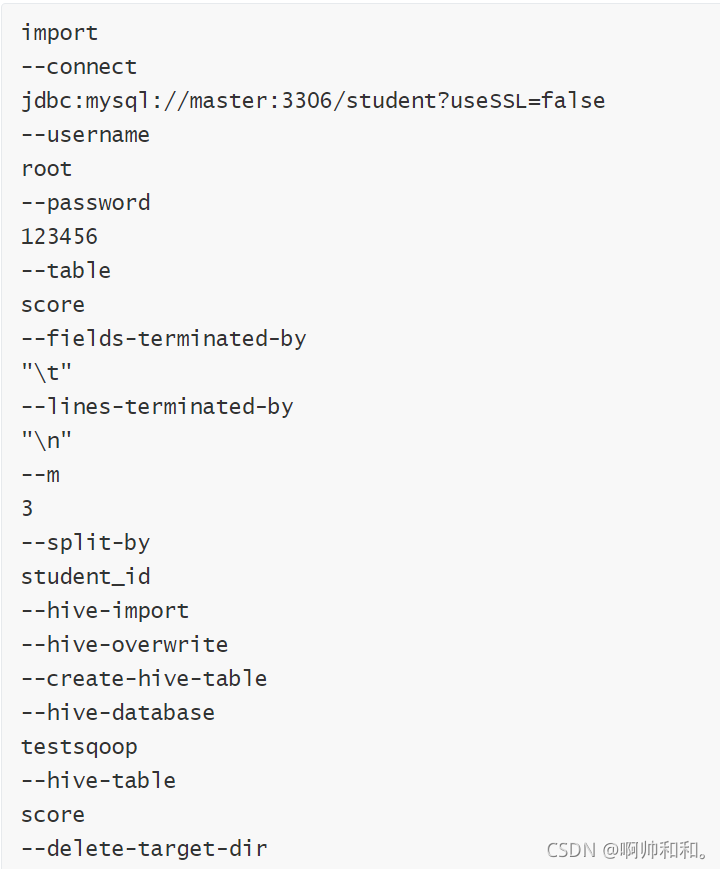
��hive���testsqoop��

��HADOOP_CLASSPATH���뵽��������(/etc/profile)��
export HADOOP_CLASSPATH=$HADOOP_HOME/lib:$HIVE_HOME/lib/*
��hive-site.xml����SQOOP_HOME/conf/
cp /opt/modules/hive-1.2.1/conf/hive-site.xml /opt/modules/sqoop-1.4.6/conf/
�ڴ����ű���ִ��·����ִ�нű�
sqoop --options-file MySQLToHIVE.conf
ִ�гɹ�
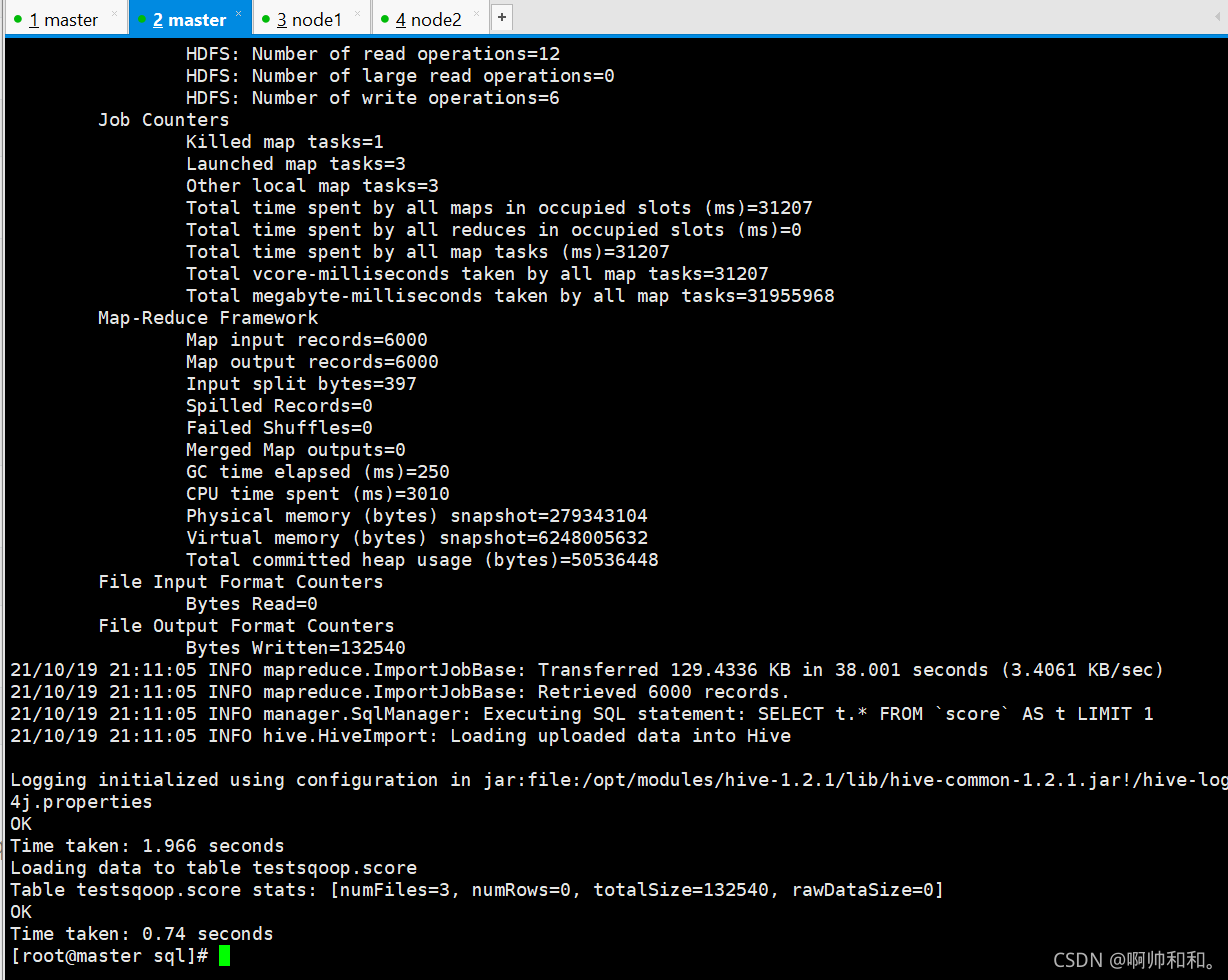
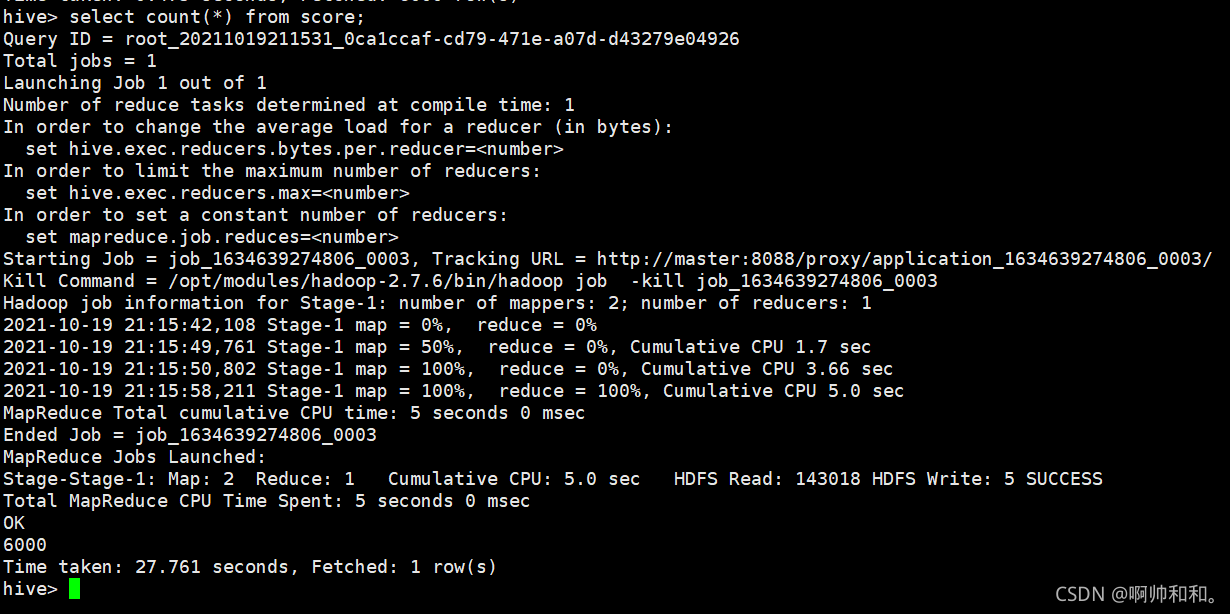
������ϵ�����ݿ�뵽HIVE��ִ��Ч��
-direct
�����������,�����ڵ���MySQL���ݵ�ʱ��,ʹ��MySQL�ṩ�ĵ�������mysqldump,�ӿ쵼���ٶ�,���Ч��
��Ҫ��master�ϵ�/usr/bin/mysqldump�ַ��� node1��node2��/usr/binĿ¼��
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
-e������ʹ��
��ͳ��ϵ�����ݵ����뵽HBASE
��д�ű�

hbase���student��
create ��student��,��cf1��
ִ�нű�
sqoop --options-file MYSQLtoHBase.conf
ִ�гɹ�
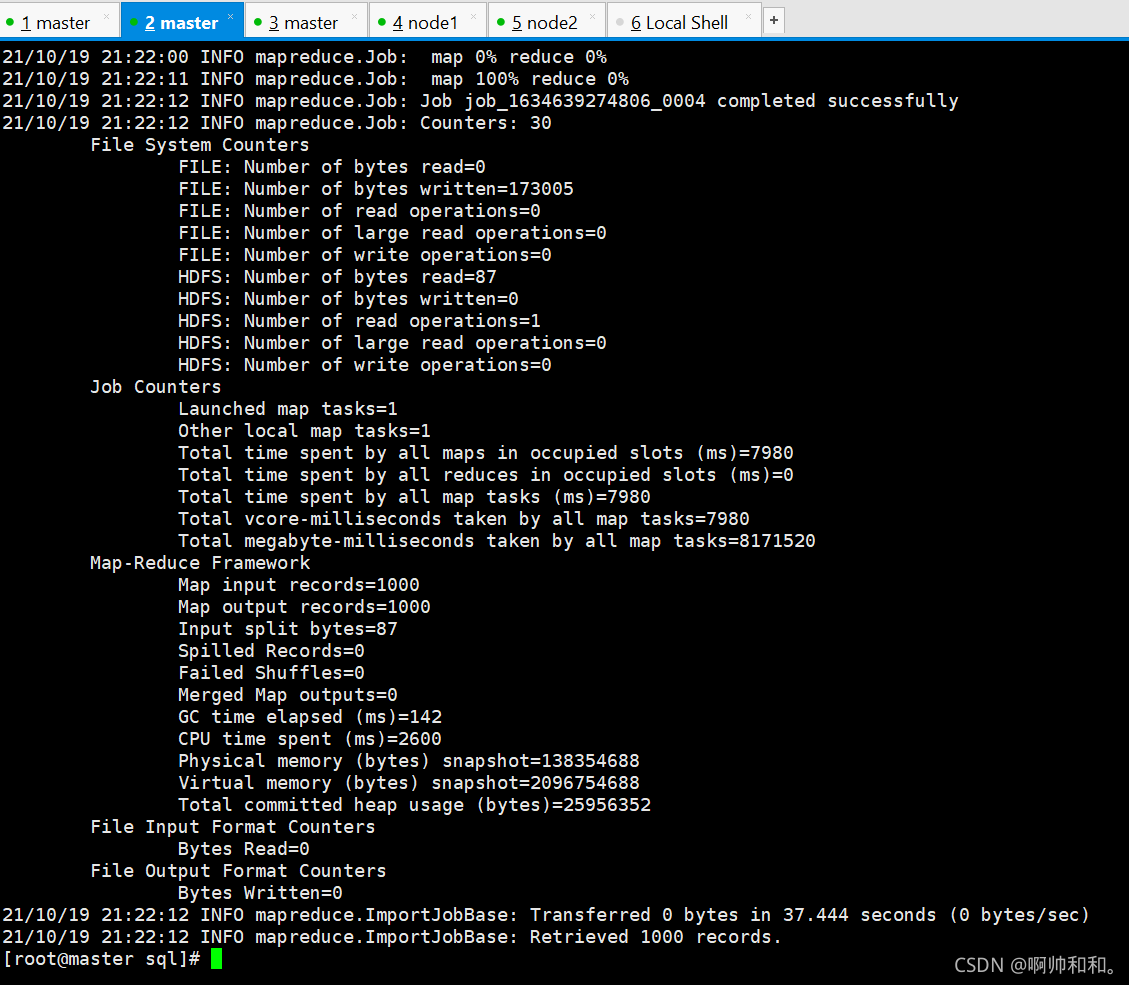
hbase�����ݵ���ɹ�
export
��HDFS�е����ݵ��뵽MYSQL
��д�ű�
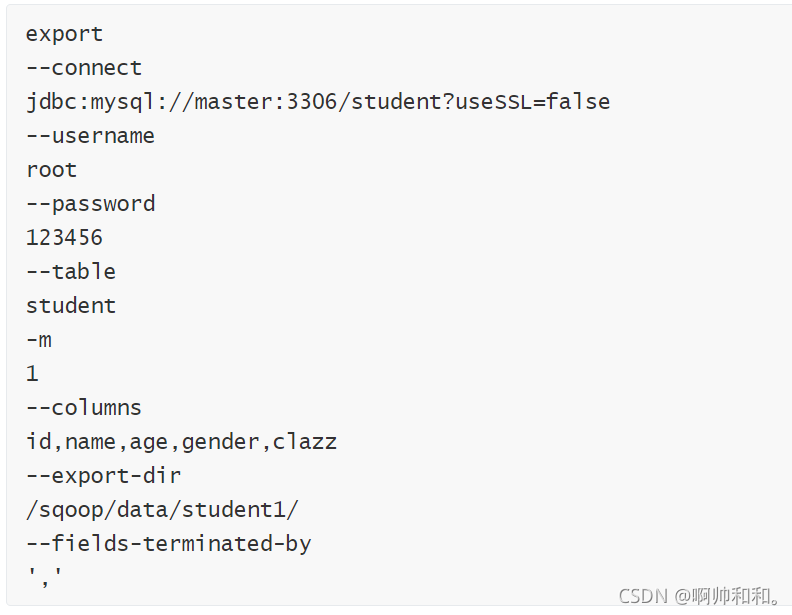
���MySQL��student�������
ִ�нű�
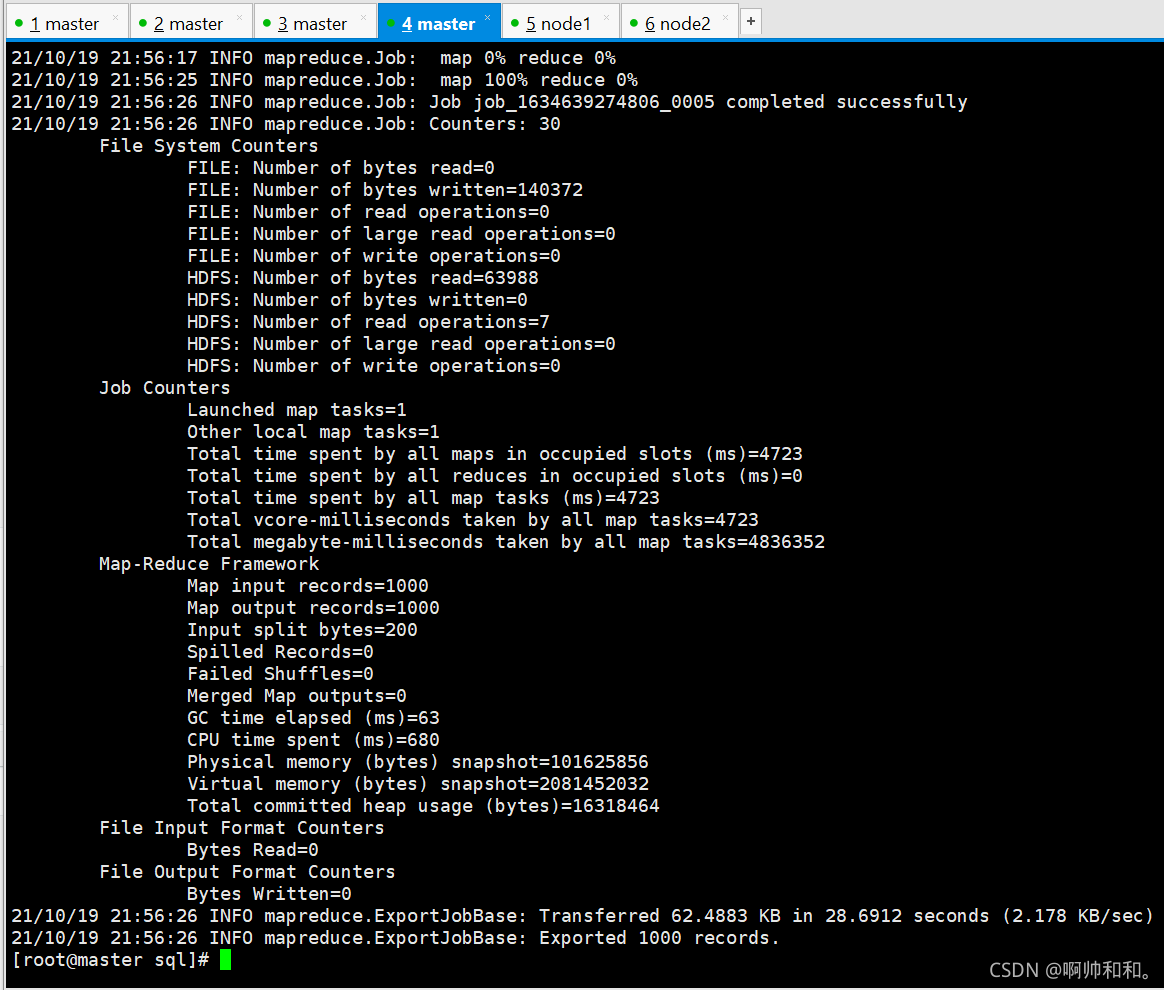
sqoop --options-file HDFSToMySQL.conf
ִ�гɹ�
��л�Ķ�,���ǰ�˧�ͺ�,һλ������רҵ����ѧ��,ף����֡�