任务一
安装centOS 7
配置网络
任务二
Ssh免密操作
安装JDK和hadoop
废话不多说直接开始了
需准备软件如下:
VMware 14.X以上的版本,官网下也可以,也可以用百度网盘链接
下载链接:https://pan.baidu.com/s/1BWA55zt7TvLU9AjxNqKhrg,提取码:123l
centOS 7镜像,可在官网免费下载,官网https://www.centos.org
Xshell和xftp,都可以在官网下载
Eclipse直接在官网下Linux系统版本
任务一
安装好VMware后开始centOS 7的安装,进入如图所示的界面后点击“创建新的虚拟机”然后点“典型推荐”,完成后点下一步
好好看截图

小提示:
在进行这一步之前请务必记住centOS 7所在的文件夹,并且文件夹不可有中文。
点击浏览将centOS文件放进去。
?
点下一步,然后先在某个盘下(最好是跟vmware一个盘)新建一个文件并在该目录下创建一个装新建虚拟机的文件夹,如图所示:

然后看图可知,我们要给虚拟机取名字,随便取一个就行。然后点“浏览”找到上一步新建的装虚拟机的文件夹,把虚拟机放到这里面去,如图所示的路径。
?
继续下一步,磁盘大小20G足够了,注意要点“将虚拟机磁盘拆分成多个文件”选项。

点“自定义硬件”
?
内存可以设置大一点方便后面虚拟机的运行,当然也可以默认。

处理器看自己电脑来,也可以默认。

弄完点关闭后再直接点完成即可。

?点了“完成”以后虚拟机自动启动了,出现了如图所示界面,点“Install CentOS 7”

选择中文,然后继续
?
?时间选如图所示时间,软件选择安装建议装有桌面的,不然后面用指令安装图形界面很麻烦。
?
?点软件选择进入如图所示界面,选如图所示的“GNOME桌面”,附加项可以不选。
?
安装位置选“自动分区”如图所示:
?
?
?点“网络和主机名称”
?
?打开以太网,设置主机名然后点击“应用”(一定要点,还要记住自己主机名字),然后点“完成”

?弄好这些然后点“开始安装”,安装需要一会时间,慢慢等。

在centOS安装的时候把root密码和用户建立一下,切记一定要记住密码和用户名,后面有用,密码简单点,用户名名和root免密最好一致以免后面记混淆,密码太简单点两次完成就可以退出当前界面。
?


?遇到这个三角形加感叹号提示的直接点进去
?
?然后点“我同意许可协议”再点完成
?
出来了点“完成配置”就可以继续安装了。
点“重启”重新启动虚拟机
?
出现这个代表着centOS 7安装完成了,点这个用户输入密码进入图形界面。
?
?确认所选没问题,就一路点前进
?
这就是图形桌面
?
?
下面来配置网络
点击右键选中“打开终端”选项,进入终端后输入如图所示指令。
?
?
我们的权限并不高,所有我们来弄一个提高权限操作
输入指令:vi /etc/sudoers,找的root所在的那一行,然后在下边添加(添加内容要按i)一行内容为:hadoop ?ALL=(root) ?NOPASSWD:ALL,注意:hadoop为主机名。如图所示:

然后按Esc键+:+wq!为保存退出操作
切换到hadoop用户,指令:su hadoop

来验证一下权限,发现cd /root权限很低,但是sudo cd /root却可以。

开始配置网络了,注意啦!
?首先点击VMware的编辑点开“虚拟网络编辑器”

然后点“VMnet8”再点“NAT”设置查看IP地址等相关信息
?
?然后记住如图所示信息,截个图就行。
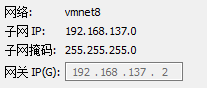
在终端输入指令:sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改如图所示内容,将BOOTPROTO后面的内容改成"static"
添加内容有:
IPADDR=
NETMASK=
GATEWAY
DNS1=
DNS2=
在等号后面填入你的ip地址与你的子网ip不同,子网掩码和网关要和刚刚查看NAT设置截图的一致,一定要保存,命令是:Esc+:+wq!

?用指令:ping www.baidu.com看能不能ping通,ping通了说明连到网络了,因为我的是校园网所有ping不到外网,但是不影响后面操作。

?重启一下网络,指令:sudo service netwoek restart,再ping一次

?然后使用指令:ip a查看一下新ip,我这个新ip是:192.168.137.15

?
下载一个vim包,遇到(y/n)输入y就行,指令如图所示:

下面做一个虚拟机与主机的映射操作
指令:sudo ?vim ?/etc/hosts,将文件里的前两行注释掉,注释符号为“#”,在添加圈出内容,即ip地址+主机名

?
任务二
ssh免密登入操作
输入命令:ssh-keygen -t rsa,然后按三次回车
?
?查看ssh生成文件

?
Pub表示公开,我们要把公开信息写入一个文件里authorized_keys
命令:cat id_rsa.pub >> authorized_keys,其中两个大于号的意思表示追加,使内容不重复。

?再输入命令:sudo ?chmod ?600 ?~/.ssh/authorized_keys

测试一下SSH免密登入操作是否成功,命令:ssh hadoop@hadoop000,从图片可看出我们的免密操作时成功了的。

?因为虚拟机窗口不可以往上滑动,下面我们切换到xshell,在这里还要弄个东西,windows系统与虚拟机的映射,打开如图所示的文件目录下的hosts文件。注:C盘下的Windows文件---->System32---->drivers---->etc---->hosts,用你电脑上可以编辑代码的软件打开。

?
?添加图中点中所示的内容,即ip+虚拟机主机名,然后保存该文件

?
按win+r输入cmd,在doc系统里输入:ping ?hadoop000,表明映射成功。

在xshell中输入命令:ssh hadoop@hadoop000,弹出如图所示内容,点击“接受并保存”然后输入密码即可。

如图所示为连接成功

?
注意这里要进行关闭防火墙操作,命令如圈出内容所示
Sudo sysremctl stop firewalld.service 表示关闭防火墙
Sudo systemctl disable firewalld.service 不让防火墙运行
Sudo systemctl disable firewalld.service 查看防火墙状态,看到如图圈出的dead单词说明关闭成功
?
安装JDK和hadoop
需要的安装包有:JDK安装和hadoop安装包
JDK链接:百度网盘 请输入提取码![]() https://pan.baidu.com/s/1IGXbauo5YSgcjxddohDTdA
https://pan.baidu.com/s/1IGXbauo5YSgcjxddohDTdA
提取码:1234
Hadoop链接:百度网盘 请输入提取码![]() https://pan.baidu.com/s/1hZ7Asw97ICdwjUHnU6JiXg
https://pan.baidu.com/s/1hZ7Asw97ICdwjUHnU6JiXg
提取码:1234
现在虚拟机里建立一个文件夹
命令:mkdir softwares
?
通过Xftp与虚拟机连接后进入到安装包所在文件目录,将安装包传送到softwares文件。如图所示直接将安装包拖过去就行。
?
?输入如图所示命令(先cd softwares再ll),查看softwares文件目录的东西
?
?在新建一个文件夹(我的叫app),用来存放解压后安装的软件

?
进入到softwares文件目录下,然后开始解压JDK和hadoop,可以一个接一个的解压。
命令:tar ?-zxvf ?jdk-8u144-linux-x64.tar.gz ?-C ?~/app
tar ?-zxvf ?hadoop-2.6.0.tar.gz ?-C ?~/app
在xshell里可以直接在softwares目录下复制文件名。
![]()
?进入app文件夹查看解压情况,从图中可以看到两个安装包都解压成功。

?查看jdk

?输入命令:vim ?~/.bash_profile,配置JDK和hadoop路径。
![]()
?添加内容如图内容所示,注意这一步内容千万不要错,文件路径可以在Xftp里面看到。


?输入指令:source ~/.bash_profile和java查看java信息
?
?
使用命令:cd ?~/app/hadoop-2.6.0/etc/hadoop/和ll查看hadoop文件

开始修改文件啦,注意不要打错内容。
第一个文件,输入命令:vim hadoop-env.sh,添加内容如圈出内容所示,将JDK路径写死,然后按Esc+:+wq!保存退出。
?
第二个文件,命令:vim core-site.xml,添加如下内容
<configuration>
??<property>
????<name>fs.defaultFS</name>
????<value>hdfs://hadoop000:8020</value>
??</property>
??<property>
????<name>hadoop.tmp.dir</name>
????<value>/home/hadoop/app/tmp</value>
??</property>
</configuration>
?
?保存退出就行了。
第三个文件,命令:vim hdfs-site.xml
添加内容:
<configuration>
??<property>
????<name>dfs.replication</name>
????<value>1</value>
??</property>
??<property>
????<name>dfs.permissions</name>
????<value>false</value>
??</property>
</configuration>
如图所示

?
第四个文件,一开始MapReduce文件是没有的,但是官方提供了模板,我们直接copy过去。
命令:cp mapred-site.xml.template mapred-site.xml,copy完成后输入命令:vim mapred-site.xml打开这个文件并在里面添加如下内容:
<configuration>
??<property>
????<name>mapreduce.framework.name</name>
????<value>yarn</value>
??</property>
</configuration>
图示内容如下:

第五个文件,命令:vim yarn-site.xml
添加内容为:
<configuration>
??<property>
????<name>yarn.resourcemanager.hostname</name>
????<value>hadoop000</value>
??</property>
??<property>
????<name>yarn.nodemanager.aux-services</name>
????<value>mapreduce_shuffle</value>
??</property>
</configuration>
图片所示:
?
文件修改为就来进行格式化,注意格式化只能进行一次,出错需删掉tmp文件重新来。
命令:hdfs ?namenode ?-format
看到这一句话说明格式化成功
![]()
?进行下面一系列操作,做这些都是为了启动HDFS,启动和关闭都需要一些时间慢慢等:

?
?
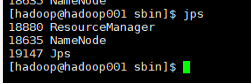
输入命令:jps检测启动是否成功,成功如图所示:
?
?关闭命令:stop-all.sh

?
测试
关闭电脑防火墙,打开浏览器,输入:http://hadoop000:50070,得到如图所示界面(因为我有现成截图就没有再截新的了,反正换汤不换药,效果一样,大家不要忘记自己的主机名就行)
?
?查看share文件:

?然后打开里面的hadoop文件再打开mapreduce文件,看到hadoop-mapreduce-examples-2.6.0.jar

?回到根目录下创建一个叫data的文件,命令:mkdir data

?最后进入一个word.txt的文件来测试,命令:vim word.txt
内容随便输入。

把word.txt上传到input文件里,进行下面的指令操作文件
hadoop fs -mkdir /input??#创建input文件
hadoop fs -put word.txt /input/word.txt??#把word.txt上传到HDFS文件系统上
hadoop fs -text word.txt /input/word.txt??#查看该文件,把-text改成-cat效果一样
?![]()
?![]()
?在网页中可以看到input文件,看到可以看到word.txt文件,点击他可以查看相关信息

?
?
?
?
?最后再打开mapreduce文件。输入:cd? ~/app/hadoop-2.6.0/share/hadoop/---->ll---->cd mapreduce/---->ll---->hadoop jar hadoop-mapreduce-examples-2.6.0.jar

?用wordcount统计字符,命令如图圈出所示

然后输入命令:hadoop fs -ls? /output,可以看到一个SUCCESS单词,说明统计成功。
输入命令:hadoop fs -text? /output/part-r-0000,可以清楚的知道word.txt的单词数量。
?好了到这hadoop的安装就算是完成了,祝大家安装顺利。
?我的学习资料视频链接:CENTOS7下的HADOOP伪分布式安装教程![]() https://www.bilibili.com/video/BV1sE41197mi?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1sE41197mi?spm_id_from=333.999.0.0