一、什么是消息系统
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。 分布式消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用: 一种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。

二、Kafka
2.1、Kafka简介
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark可以非常好地集成,用于实时流式数据分析。
2.2、Kafka特性
- 可靠性 - Kafka是分布式,分区,复制和容错的。
- 可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
- 分布式 - 日志的分区partition (分布)在Kafka集群的服务器上。
- 耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
- 性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
2.3、Kafka架构
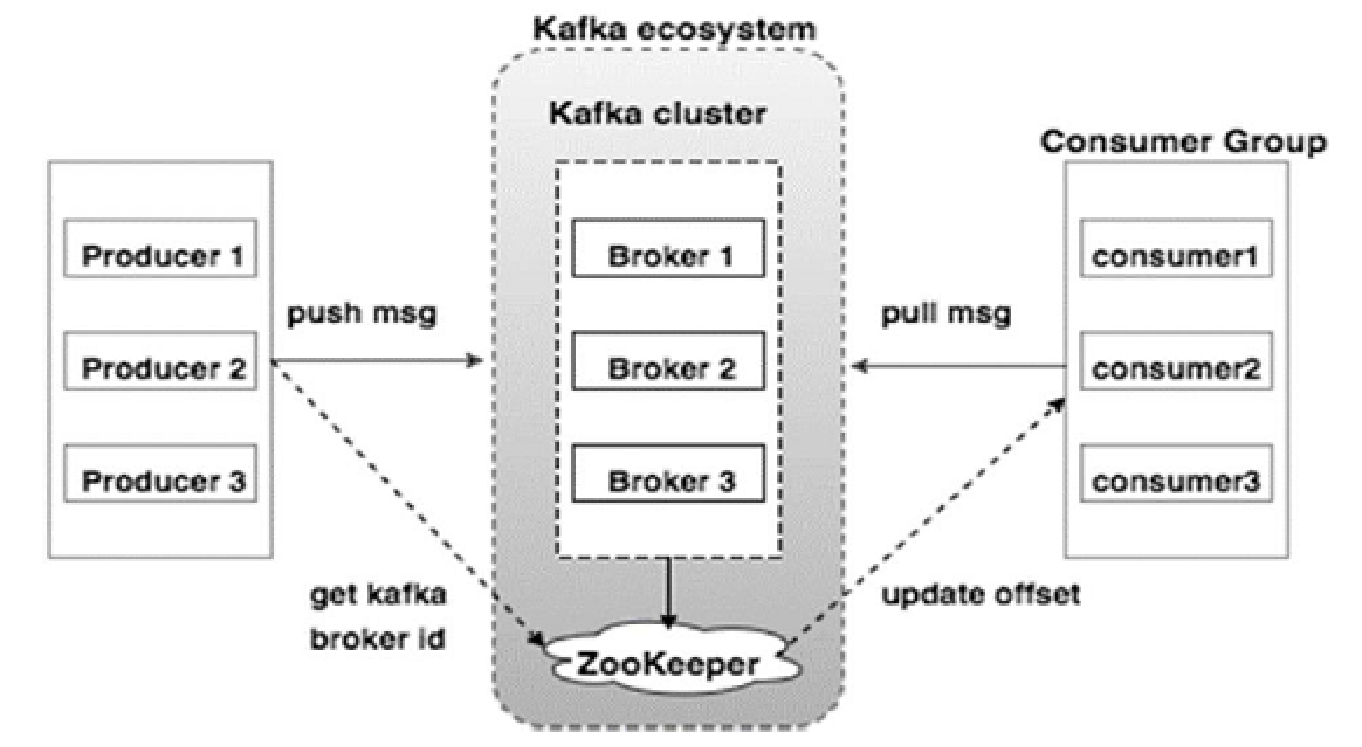
2.4、Kafka核心概念
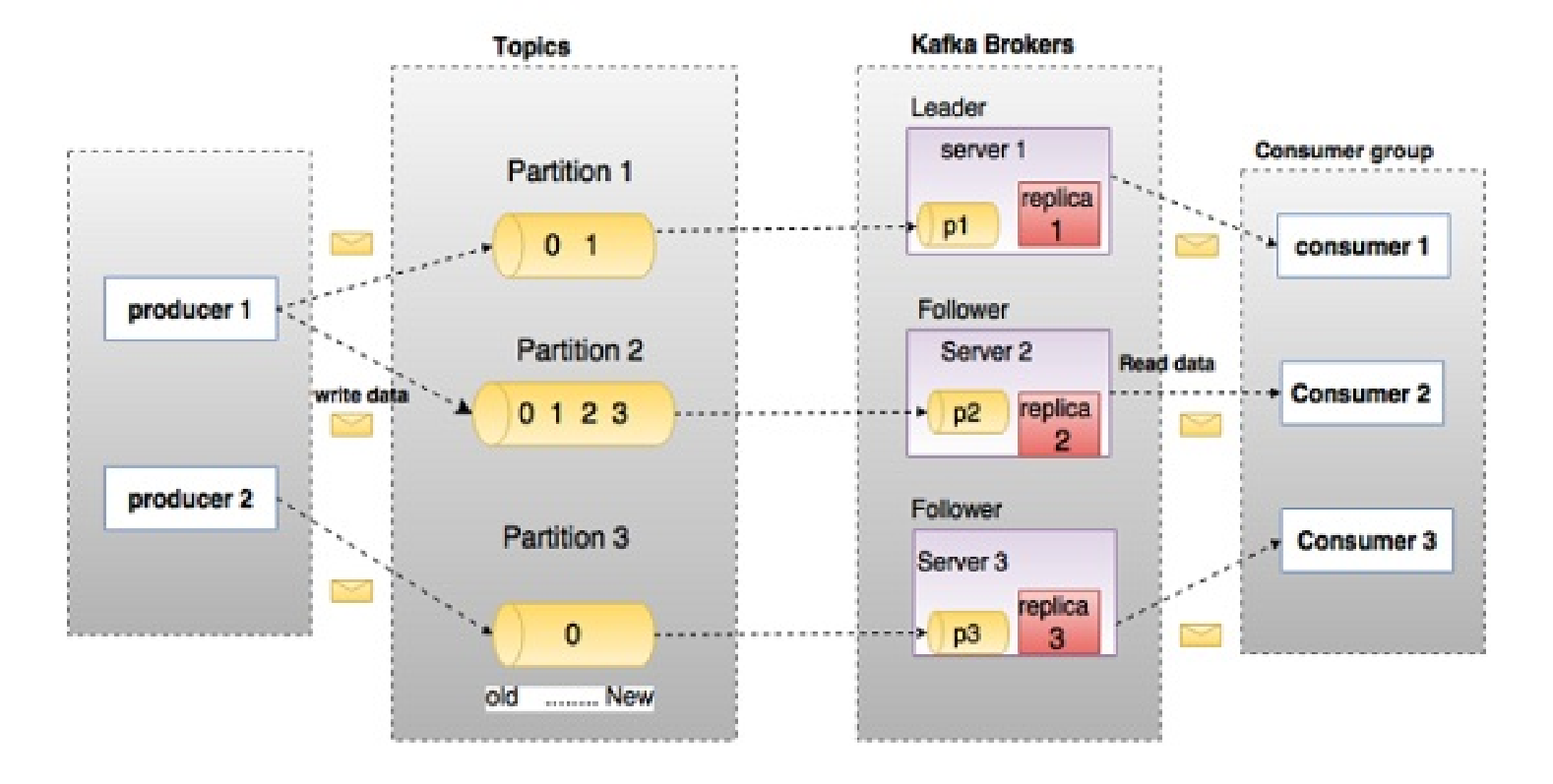
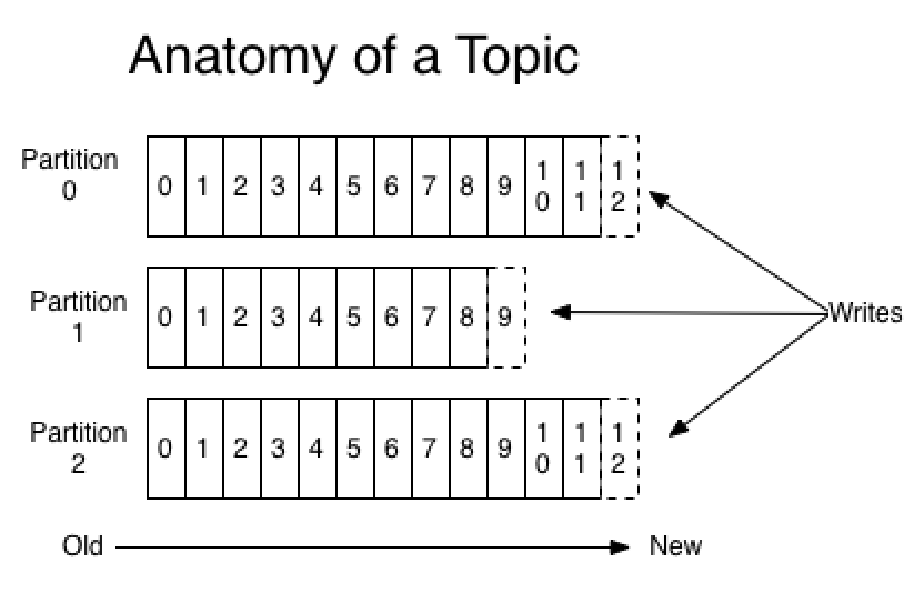
2.5、Kafka数据流
对于每一个topic, Kafka集群都会维持一个分区日志。
每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。
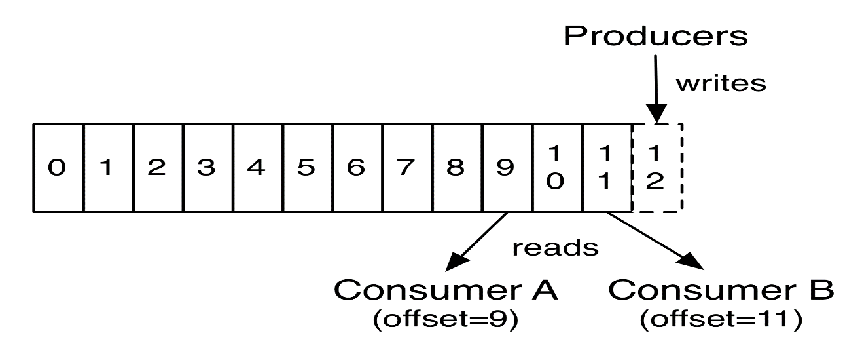
分区中的每一个记录都会分配一个id来表示顺序,也叫offset。offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录―无论他们是否已被消费―并通过一个可配置的参数――保留期限来控制。
例如,如果保留策略设置为100天(当然不建议大家这样做),一条记录发布后100天内,可以随时被消费,100天后这条记录会被抛弃并释放磁盘空间。