����:50�ڸ��绰����,����10���,�ж�10w���绰�����Ƿ����?
��bitmap/hyperloglog�Ļ�,�ڼ�����Ҳ�Ƿdz����ڴ�Ӵ��

�Ǹ�ɶ:
��һ����ʼֵ��Ϊ0��bit�����Ͷ����ϣ��������,���ڿ����ж�ij�������Ƿ���ڡ�(���hash����,����hash��ͻ����)
����:���������ж������Ƿ������һ����ļ����С�����set,����ͳ�ƽ����̫ȷ��
�ص�:
1.��������ѯ��Ч,ռ�ռ���,���ؽ����ȷ����
2.һ��Ԫ��,����ʱ,bloom���ж�����һ���ʹ���;���Dz����ڵ�,bloom���ж�,���һ�������ڡ�(hash��ͻ)
3.��������Ԫ��,��������ɾ��,ɾ����������������
4.����ֻ�ᷢ����bloomû���ӹ���Ԫ��,���ӹ���Ԫ�ز�������
��Ҫ���:
��1.���洩

�ն����α겻�α�!�ڿͶ�ʱ�䷢��������ͬ�ġ������ڵ�key�Ļ�,���ɻ����ѹ����
Google��guava������洩(������)
Redis��bloom�������-Redisson(��Ⱥ���èC�Ƽ�)
Rebloom-��ҵ����뷽ʽʵ�ֵIJ�¡,ֱ�Ӱ�װ��redis������,�൱һ��redis���
fpp(�����)���õIJ���ԽСԽ��,�����ʵ�,�ռ�ռ�ȴ�,ͬʱִ��Ч��Ҳ�ή�͡�
������洩����:

ҵ��:�ڡ�������
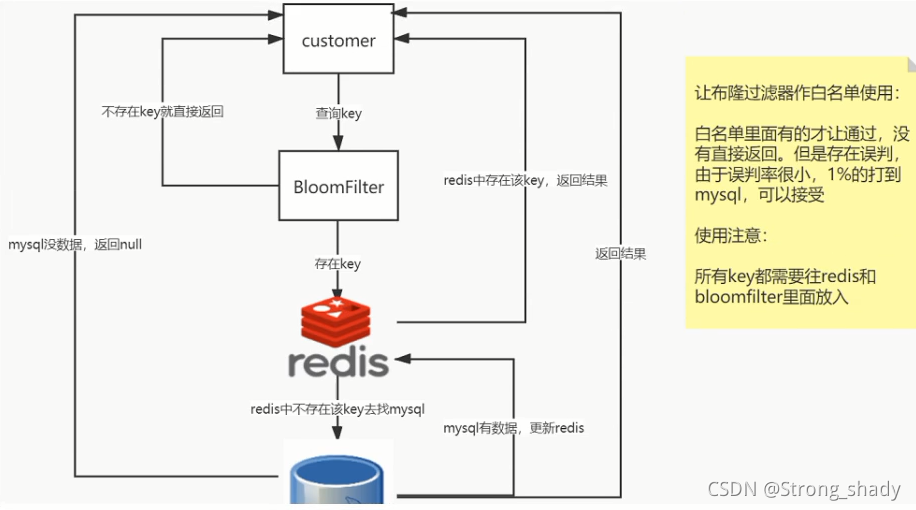
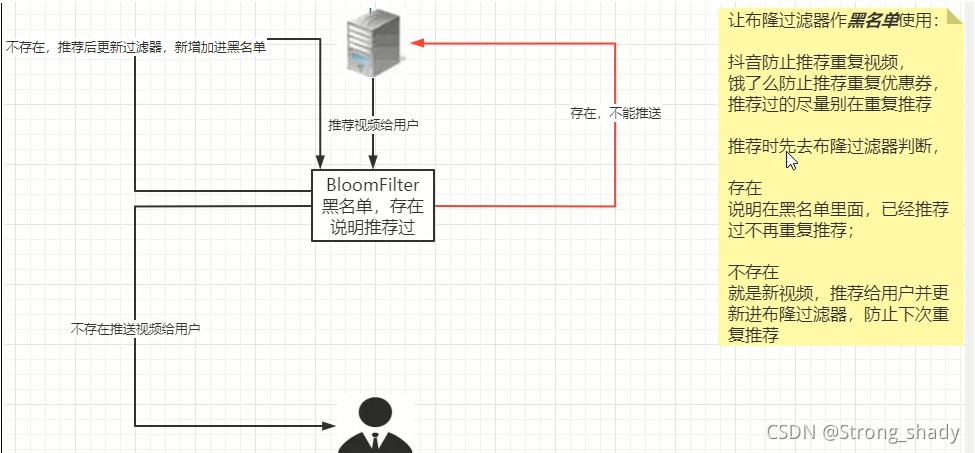
2.�ڰ�����У��

ԭ��:




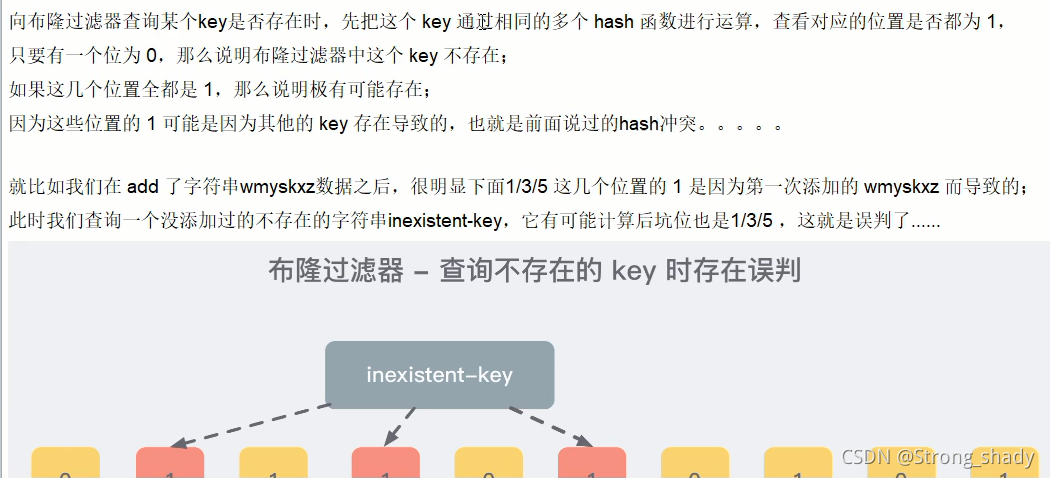
����Dz���ɾ����ԭ��:�����ϣ�����Զ��obj��ϣ����ʱ,�п��ܳ�����ͼ3�Ų�λ�ij�ͻ,ɾ����������ɾ��,��ʵ�����������Ǵ��ڵ�,�ᱻ����Ϊ�������ڡ�

���ԭ��һ�仰�ܽ�:
1.��ʼ�� ��

2.����Ԫ���������� (��������redis�����ݰ�λ���0/1���ʶ��,���ǰ���ʵ���ݴ��������!)��

3.�ж��Ƿ���ڡ�
��redis��֮���ٴ���bloom,ֻҪbloom����,û��ôredis�����Ҳ��,bloom������ż�����洩һ��������ν;ֻҪbloom�ж�û��,��ô�Ͳ���ȥredis���ˡ�

hash��ͻ�İ���:
sout(��Aa��.hashcode());
sout(��BB��.hashcode());
2.

��һ��:�����������������ɾ��,��ѯЧ�ʺͿռ������ʶ�����bloom