1:键管理
??本节将按照单个键、遍历键、数据库管理三个维度对一些通用命令进行介绍。
1.1: 单个键
??针对单个键的命令,前面几节已经介绍过一部分了,例如type、del、 object、exists、expire等,下面将介绍剩余的几个重要命令。
1.键重命名:rename key newkey
注:
1:如果在rename之前,键java已经存在,那么它的值也将被覆盖,所以为了防止被强行rename,Redis提供了renamenx命令,确保只有newKey不存在时候才被覆盖
如果rename和renamenx中的key和newkey如果是相同的,在Redis3.2和之 前版本返回结果略有不同。Redis3.2中会返回OK,而Redis3.2之前的版本会提示错误
2.随机返回一个键:randomkey

3.键过期:除了expire、ttl命令以外,Redis还提供了 expireat、pexpire、pexpireat、pttl、persist等一系列命令
-
persist命令可以将键的过期时间清除

-
对于字符串类型键,执行set命令会去掉过期时间


-
Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功 能,例如不能对列表类型的一个元素做过期时间设置。
-
setex命令作为set+expire的组合,不但是原子执行,同时减少了一次网络通讯的时间。

1.2:遍历键
??Redis提供了两个命令遍历所有的键,分别是keys和scan。
1.全量遍历键:keys pattern
??之前介绍果keys命令的简单使用,实际上keys命令是支持pattern匹配的。
??因为考虑到Redis是单线程架构,如果Redis包含了 大量的键,执行keys命令很可能会造成Redis阻塞,所以一般建议不要在生产环境下使用keys命令。
2.渐进式遍历
??Redis从2.8版本后,提供了一个新的命令scan,它能有效的解决keys命令存在的问题。和keys命令执行时会遍历所有键不同,scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是 O(1),但是要真正实现keys的功能,需要执行多次scan。Redis存储键值对实际使用的是hashtable的数据结构,其简化模型如图所示:
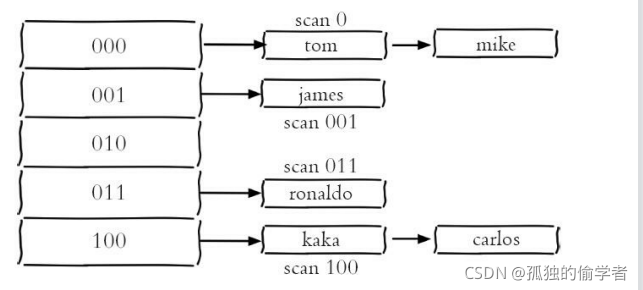
??那么每次执行scan,可以想象成只扫描一个字典中的一部分键,直到将 字典中的所有键遍历完毕。
scan的使用方法:scan cursor [match pattern] [count number]
・cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
・match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的 模式匹配很像。
・count number是可选参数,它的作用是表明每次要遍历的键个数,默认 值是10,此参数可以适当增大。
?? 现有一个Redis有26个键(英文26个字母),现在要遍历所有的键,使 用scan命令效果的操作如下。第一次执行scan0,返回结果分为两个部分:第 一个部分6就是下次scan需要的cursor,第二个部分是10个键
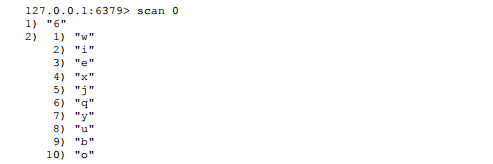
使用新的cursor=“6”,执行scan6:

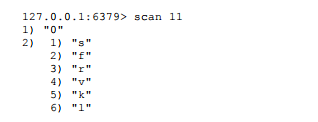
这次得到的cursor=“11”,继续执行scan11得到结果cursor变为0,说明所有的键已经被遍历过了:
1.3:数据库管理
??Redis提供了几个面向Redis数据库的操作,它们分别是dbsize、select、 flushdb/flushall命令,本节将通过具体的使用场景介绍这些命令。
1.切换数据库:select dbIndex
??Redis默认配置中是有16个数据库,序号从0开始,默认连接0号数据库,Redis只是用数字作为多个数据库的实现。但是Redis3.0中已经逐渐弱化这个功能,例如Redis的分布式实现Redis Cluster只允许使用0号数据库,只不过为了向下兼容老版本的数据库功能, 该功能没有完全废弃掉。
为什么要废弃掉这个“优秀”的功能 呢?总结起来有三点:
1:Redis是单线程的。如果使用多个数据库,那么这些数据库仍然是使用 一个CPU,彼此之间还是会受到影响的。
2:多数据库的使用方式,会让调试和运维不同业务的数据库变的困难, 假如有一个慢查询存在,依然会影响其他数据库,这样会使得别的业务方定 位问题非常的困难。
3:部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候 来回切换数字形式的数据库,很容易弄乱。
如果要使用多个数据库功能,完全可以在一台机器上部署多个 Redis实例,彼此用端口来做区分,因为现代计算机或者服务器通常是有多 个CPU的。这样既保证了业务之间不会受到影响,又合理地使用了CPU资源。
2.flushdb/flushall
??flushdb/flushall命令用于清除数据库,两者的区别的是flushdb只清除当前数据库,flushall会清除所有数据库。