Hive�ܹ������ʽ
[TOC]
ǰ��
���ĵ�����hive 3.1.2��д
hive�Ļ���֪ʶ
�����ܹ�

- ����hive��hiveserver2��hive �ͻ������
- hive�ͻ���������,beeline ��ʹ��jdbc����hiveserver����ʹ��hive CLI(����Ѿ���ʱ,hive�ٷ��Ѿ����Ƽ�,�Ƽ�beeline)
- hive server������hive server2��metastore���
- metastore��hive��Ԫ���ݹ������
- hcatalog ������metastore��,��¶һ��api,ʹ���������,����Pig,FLink�ܹ�ʹ��hive��Ԫ���ݹ�������,�Ӷ��Ա��ӽ�ȥ��������
- webchat ����hcatalog�����ϱ�¶restful�ӿ�
- hive ��ʵ�����ݴ洢��hadoop��hdfs��
- hue�ṩһ��ͼ�λ��ķ�ʽ,�����û�������sql�Ŀ���,��Ȼ�����������ӹ���
metastore
hive�����ݱ����ϴ洢��hdfs�еġ�����Ա����ӽǿ�������,�����metastore�Ĺ���,���洢�˱���schema��Ϣ�����л���Ϣ���洢λ����Ϣ��
metastore���������������
- metastore server
- metatore db
�������ļܹ�,���κ�һ������javaӦ��һ��,server��Ӧ�ñ���,db���洢���ݡ�������metastore����IJ���ģʽ��,������
��Ƕ��������ݿ�
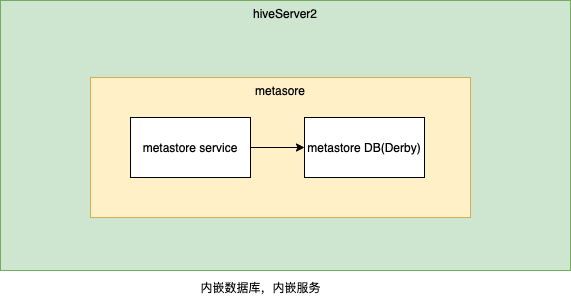 metastore server��metastore DBͬhive server������һ��,����Ƕ�ķ�ʽ���� ����metastore DB��������һ����Ƕ��Derby���ݿ�
metastore server��metastore DBͬhive server������һ��,����Ƕ�ķ�ʽ���� ����metastore DB��������һ����Ƕ��Derby���ݿ�
��Ƕ����
 metastore server���Ǹ�hiveһ���� ��metastore DBʹ�ö�����Mysql���н�
metastore server���Ǹ�hiveһ���� ��metastore DBʹ�ö�����Mysql���н�
��������ݿⵥ������
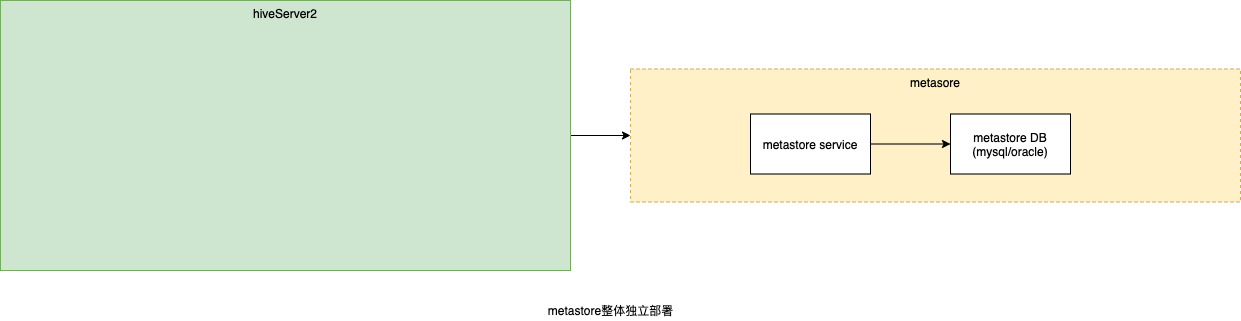 �������ݿ��������֮��,metastore service����Ҳ��������
�������ݿ��������֮��,metastore service����Ҳ��������
hcatalog
hcatalog ������metastore��,��¶һ��api,ʹ���������,����Pig,FLink�ܹ�ʹ��hive��Ԫ���ݹ�������,�Ӷ��Ա��ӽ�ȥ��������
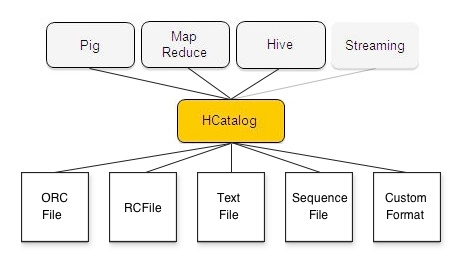
demo
hadoop distcp file:///file.dat hdfs://data/rawevents/20100819/data
hcat "alter table rawevents add partition (ds='20100819') location 'hdfs://data/rawevents/20100819/data'"���������Ƚ��ļ�������hdfs,Ȼ��ͨ��hcatalog,�����������Ϊ��rawevents��һ���·���
�ͻ���
�ͻ��˵ı���ģʽ
�������ܵ�metastore��Ƕ���remote����,������hiveserver���ӽ���˵�ġ�hiveserver�����Ƕ����IJ��𡣵���hive�ͻ�����˵,����ͨ��remoteģʽ,���ӵ��Ѿ�����õ�remote server �� �����������ͻ��˵�ʱ��,˳����һ�����ص�hive server�����Ӧ��metastore����һ��һ��Ҫ�����
beeline
��Ϊhive�Ƽ�����һ���ͻ��ˡ���ʹ��Thrift Զ�̵��á� beeline�ı���ģʽ
$HIVE_HOME/bin/hiveserver2 #�ȶ�������hiveserver
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT # Ȼ����host��port����ʽ��hiveserver����
beeline�ı���ģʽ
$HIVE_HOME/bin/beeline -u jdbc:hive2:// #���Dz���host��port,�ò�������ͬһ����������hiveserver ��metastore,�Լ�beeline �� ����������ʹ��,ֻ����Ԫ�������غ�Զ�̵�����,�����Ƿ�ָ��Զ�̵�Host��port��û�еĻ�,���DZ���ģʽ
beeline���Զ�ģʽ
ÿ��ͨ��beeline����Զ�˵�hiveserverʱ,��Ҫָ���ܳ�һ�ε�jdbc url,���鷳,����������û�beeline����,ֱ�Ӿ�����Զ�˵�hiveserver2,�������hive�������ļ�Ŀ¼����beeline-site.xml�����ļ�,�ļ����ݴ�������
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>beeline.hs2.jdbc.url.tcpUrl</name>
<value>jdbc:hive2://localhost:10000/default;user=hive;password=hive</value>
</property>
<property>
<name>beeline.hs2.jdbc.url.httpUrl</name>
<value>jdbc:hive2://localhost:10000/default;user=hive;password=hive;transportMode=http;httpPath=cliservice</value>
</property>
<property>
<name>beeline.hs2.jdbc.url.default</name>
<value>tcpUrl</value>
</property>
</configuration>����������beeline���ӵ����ַ�ʽ,�;����jdbc�����ַ�����һ��ʹ��tcp,һ��ʹ��http��Ĭ������tcp
jdbc
jdbc����hiveҲ������ģʽ
- For a remote server, the URL format is
jdbc:hive2://<host>:<port>/<db>;initFile=<file>(default port for HiveServer2 is 10000). - For an embedded server, the URL format is
jdbc:hive2:///;initFile=<file>(no host or port).
����
һ��hive�����������漰������,��Ҫ��Ҫ����ǰ����
- metastore�IJ���
- hiveserver2�IJ���
- client�IJ���
- hcatalog server �IJ���(�DZ���)
- webhcat server�IJ���(�DZ���)
����1,2�������Ժ���һ��,��hiveserver2��Ƕmetastore, ֻ�ǽ�metastore��DB,��ҵ�Mysql��
���嵽������������,�����������,���Բ���������ͬ������,��Ȼhive clientһ����ڶ�������ϡ�
���������Ӧ�����ö�������hive-site.xml,���������ݲ�һ����ͬ������hiveserver2��Ҫ����,meta DB��������Ϣ,��client����Ҫ��Щ��Ϣ��
����hive-site.xml֮��,hive��֧�������������ط���������
- ����������ʱ ͨ��
--hiveconf����,ָ�����ƻ�������,��bin/hive --hiveconf hive.exec.scratchdir=/tmp/mydir - �� hivemetastore-site.xml�ļ���ָ��,metastore��ص�����
- ��hiveserver2-site.xml��ָ��,hiveserver2���������á�
������Щ·���������ļ���ӵ����ͬ����ʱ,hiveʶ�����ȼ�����,��������,�������� hive-site.xml -> hivemetastore-site.xml -> hiveserver2-site.xml -> '-hiveconf'
����,��ѵ����ò�����:
- ��hive-site.xml������,hiveserver2��hive client�����õ�����,�������������ֱ�ӷַ����������
- ��metastore��ص����÷ŵ� hivemetastore-site.xml �С�meta���ݿ��������,ֻ��metaserver����Ļ����ϴ���,�����Ĵ��ַ����ݿ�����
- ��hiveserver2���е����÷ŵ�hiveserver2-site.xml ��
����hiveserver2
��������,������Ƕmetastore server , remote metastore DB�ķ�ʽ����hiveserver ����
����Ҫ����hive�Ļ����ϡ�����һ��hive�˺�,adduser hive ���������hadoop��,���к������ú���������hive�û�����
����hive��װ����������conf�µĸ�template�ļ�ȥ��,������������á� hive-default.xml.template��Ҫ�ij�hive-site.xml
hive-default.xml.template���������е�hive�������ص�Ĭ�����á�
��hdfs�д���hive���ݴ��·��
��hdfs�д��������ļ�,����hive�����鸳дȨ��
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse/user/hive/warehouse��hive�еı�����ʵ�ʴ洢�ĵط�������Ĭ��·��,�㵱Ȼ������hive-site.xml��ͨ������hive.metastore.warehouse.dir������ָ���µ�·��
����hive�Ļ�������
export HIVE_HOME=/opt/apache-hive-3.1.2-bin/
export PATH=$HIVE_HOME/bin:$PATH������־���·��
hive��Ĭ�����·��Ϊ/tmp/<user.name>/hive.log,���������hive�û�����,��ô��·��Ϊ/tmp/hive/hive.log
/tmp·����linux������Ÿ�Ӧ�ó�������ʱ���м�״̬����,һ����ڲ���ϵͳ������,�Զ����������� ��Ȼ�������hive��log4j�ļ�,��ָ��hive.log.dir=<other_location>·��
Ҳ����������hiveserver2ʱ,��̬��ȥͨ��hiveconf����ָ��·��bin/hiveserver2 --hiveconf hive.root.logger=INFO,DRFA
hive����ʱ�ļ�����
hive����ʱҲ����host����,��hdfs�д����ʱ�ļ�,��֮Ϊscratch�ļ�����ŵ��ļ�·��Ϊ hdfs :/tmp/hive-<username> ����:/tmp/<username>
ֵ��˵������,hive-site.xmlģ����,�д���·��������${java.io.tmpdir}/${user.name}/,${java.io.tmpdir}��ʾ�����õ�Ĭ��ֵ��ȡJavaʹ����ʱĿ¼,һ����linux��Ҳ��/tmp,${user.name}��ʾȡ��ǰ����hive���û��������������ָ��,��ɾ����Ӧ�����������Ҫֱ��������Ҳд��${java.io.tmpdir}/${user.name}/,xml����ʶ������Щռλ���ġ�
����metastore ��DB��Ϣ����ʼ��
��hive-site.xml��Ӧ��Ŀ¼��,����һ��hivemetastore-site.xml�ļ�,��������metastore�����Ϣ 
��ʼ��metastore db
$HIVE_HOME/bin/schematool -dbType <db type> -initSchema����dbType��ȡֵ������derby, oracle, mysql, mssql, postgres
����� https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration
����hiveserver2
$HIVE_HOME/bin/hiveserver2��������Ϊǰ̨����,�����no hang up �Ӻ��̨��ʽ����
nohup $HIVE_HOME/bin/hiveserver2 > /opt/apache-hive-3.1.2-bin/logs/hive_runtime_log.log < /dev/null &������hive��web�����Ӧ�Ķ˿���:10002
�����ͻ��˲���
�������ַ�
������hive���Ͱ�,ͬ����,��������Ҫ����beeline�Ļ�����,����ɿͻ��˵����á������ļ�ֻ��Ҫhive-site.xml,�ɸ��ݾ����������,ȥ����Ӧ��·��������Ϣ,����Ҫhivemetastore-site.xml �� hiveserver2-site.xml�ļ�
������������
export HIVE_HOME=/opt/apache-hive-3.1.2-bin/
export PATH=$HIVE_HOME/bin:$PATH��־·������
ͬhiveserverһ��,���ݾ������,��һЩ·��������
����
ʹ��$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT��������hiveserver2��
����hive��hdfs��ʹ�õ�Ŀ¼,Ĭ����/user/hive/warehouse,����Ϊ�˱���Ȩ����صĴ�,��Ҫ��ͨ��beeline�����Ǽ�-n����,����ָ����ǰ�ͻ���ʹ�õ��û������Ҹ��û�Ҫ��/user/hive/warehouse�������ļ������Ȩ��,û�еĻ���Ҫ�����ӡ�Ȩ��ģ��,ͬLinux���ơ������Ȩ������,һ��Ĵ�������
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=yarn, access=WRITE, inode="/user/hive/warehouse/test.db":hive:hadoop:drwxr-xr-x���û�������Ϊ��ʽΪ:
beeline -u jdbc:hive2://master:10000 -n hive������hive�û����ӵ�hiveserver
beeline����ʹ���ĵ�:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
hiveserver�߿��ò���
���������
��������Ҫ����hiverserver�Ļ�����,����hiveserver2-site.xml������������������
<!--�����߿�������-->
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<!--������zk�еĵ�ַ�ռ�-->
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2</value>
</property>
<!--������zk�ĵ�ַ-->
<property>
<name>hive.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>ͬʱ��ס,��Ҫ�����hiverserver�Ļ���,��Ҫ����ͬmetastore������,��֤��������ʱͬһ��mysql,�ɽ�hivemetastore-site.xml���ÿ����������Ҫ����hiveserver�Ļ���
�����:http://lxw1234.com/archives/2016/05/675.htm
�ͻ�������
��beeline�����ӷ�ʽ����:
beeline -u "jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" -n hiveע�����е�jdbc urlһ��Ҫ������
��֤
����ѡ��Kerberos��Ϊ��֤ѡ�����Ҫ���õ���������������:
Authentication mode:
hive.server2.authentication �C Authentication mode, default NONE. Options are NONE (uses plain SASL), NOSASL, KERBEROS, LDAP, PAM and CUSTOM.
Set following for KERBEROS mode:
hive.server2.authentication.kerberos.principal �C Kerberos principal for server.
hive.server2.authentication.kerberos.keytab �C Keytab for server principal.ʹ����kerberos��֤���beeline���ӷ�ʽ
beeline -u "jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"��������ʹ��ǰ,һ����֤�Ѿ�ͨ��kinitʵ���˵�ǰ������kerberos��֤������beeline����ᱨ��,��Ϊû��ȡ��kerberos��֤Ʊ�ݡ�
��������Զ�ȥ��ȡ,��ǰ��¼��kerberos�û���Ϣ,��ִ�е������ʱ�����
INFO : Executing with tokens: [Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:haixue-hadoop, Ident: (token for test: HDFS_DELEGATION_TOKEN owner=test, renewer=yarn, realUser=hive/master@HAIXUE.COM, issueDate=1594627135369, maxDate=1595231935369, sequenceNumber=66, masterKeyId=27)]���統ǰkerberos��tgt��test�û�,��ô��hivesql ��Ӧ��owner����test��ʵ�����֮���ͨ����֤��ʹ�õ�hive/master@HAIXUE.COM �û�������Ȩ���Ȼ���Ƶ�test�ϡ�
���������hive���õĵ�hive.server2.enable.doAs ���������Ƶ�,������Ϊtrueʱ,��ʾ�������ύ�û���Ϊ����sqlִ�е��û�
����,���������hiveserver�������ļ���,��hive.server2.allow.user.substitution�ر�Ϊfalse. ��Ϊ��ѡ��,�������û���-n����ָ��һ���û��������ᵼ��һ���û����Լ���kerberosƾ֤,�������˵Ŀ���������ú�,hue���������¼�û���Ϊ�ύjob���ˡ�
����hive-site.xml�Ŀͻ�������
������¼������hiveserver2�ķ�ʽ,��ͨ��jdbc��ʵ�ֵġ�����Щ����hive�ij���,��ֻ��ͨ��hive-site.xml ���ַ�ʽ����hiveserver�����͵ľ���hue
hue��ȥ${HIVE_CONF_DIR}������������/etc/hive/conf·������hive-site.xml��beeline-hs2-connection.xml���������ļ�,��ȡ���е���Ϣ,ʵ�ֶ�hiveserver�����ӡ�
�����Ⱥ������kerberos,��ô��Ҫ��hive-site.xml������,��hiveserver2-site.xmlһ����kerberos��֤����,����
<property>
<name>hive.server2.authentication</name>
<value>KERBEROS</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.principal</name>
<value>hive/master@HAIXUE.COM</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.keytab</name>
<value>/opt/keytab_store/hive.service.keytab</value>
</property>��hue ��ʹ��beeline����,����������beeline-hs2-connection.xml,������ָ��һЩЩ����hiveserver2�Ĵ����û���Ϣ,����Ŀǰ���ֲ�������Ȼ����ʹ�á�����:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>beeline.hs2.connection.user</name>
<value>hive</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>hive</value>
</property>
</configuration>һЩ����
����1 guava
��ʼ��metastore schema�DZ���
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)Vԭ����hadoop·��share/hadoop/common/lib/�µ�guava��ͬhive��lib�µ�guava���汾��һ�¡�
����취,ɾ��hive��guava��,��hadoop�Ķ�Ӧguava����������
����2,mysql����
[hive@master bin]$ ./schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://xxx.xx.xx.xx:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
Underlying cause: java.lang.ClassNotFoundException : com.mysql.jdbc.Driver
Use --verbose for detailed stacktrace.
*** schemaTool failed ***����ԭ��,hiveȱ��mysql������
����취,����һ��mysql������,��װ��hive��lib��
����3
��ʹ��beeline�ͻ���:beeline -u jdbc:hive2://master:10000����,hiveserver2ʱ,�����´���
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate anonymous (state=08S01,code=0)
Beeline version 3.1.2 by Apache Hive��������hive�û�,������hiveserver2������,���пͻ���,�����������û����ӵ�hiveserver2,����hiveserver2ȥ����hadoop��Ⱥʱ,������hive���û�ȥ���ʵġ�
�������û��hadoop��,����ص�����,��hadoopĬ���Dz�����hive����û���Ϊ�����û��Ĵ����û�ʹ�ü�Ⱥ��,������Ҫ��hadoop��core-site.xml��,����������
<!--����Ȩ����,������֮master,slave1,slave2�ϵ���������û�,��hive�û�����ʹ��Hadoop��Ⱥ,����hiveҲ��һ���û�-->
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<!--�������ø�hadoop.proxyuser.hive.groups��ѡһ,�������������á�����ָ��hadoop.proxyuser.hive.hosts������,������Щ�û����Դ�����hive��-->
<property>
<name>hadoop.proxyuser.super.users</name>
<value>user1,user2</value>
</property>�����
https://cwiki.apache.org/confluence/display/Hive/GettingStarted https://cwiki.apache.org/confluence/display/Hive/HCatalog+InstallHCat https://stackoverflow.com/questions/22533814/what-is-use-of-hcatalog-in-hadoop https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
��ӭ��ע�ҵĸ��˹��ں�"����ƫ��UP",��¼��������,��ҵ˼��,�Ƽ�����