?��ӭ��ע������ҳ:����:import_bigdata,����������Ӳ��ԭ������_��֪��(import_bigdata)_CSDN����
https://blog.csdn.net/u013411339
��ӭ���ޡ��ղء����� ,��ӭ���Խ���!
�����ɡ���֪�ޡ�ԭ��,���� CSDN����!
������CSDN��̳,δ�����ٷ��ͱ�������,�Ͻ�ת��!
�����Ƕ�����Ӳ�մ�����֮ѧϰ·��ƪ��2021����㵽������ר�ҵ�ѧϰָ��(ȫ��������)�������Բ��ֲ��䡣
ǰ��
Hive��2008��ʼ��FaceBook����ʦ֮��,����10����ķ�չ����ǿ�������������ֹĿǰHive�Ѿ�������3.1.x�汾,Hive���ʼ��Ϊ��ڸ�����ٶ���Ѹ�ٷ�չ,��ʼ֧�ָ���ļ�������,�����ٶȴ��������
�������ǽ���ԭ����Ӧ�á����ŷֱ�Hive��֧�ֵ�MapReduce��Tez��Spark���档
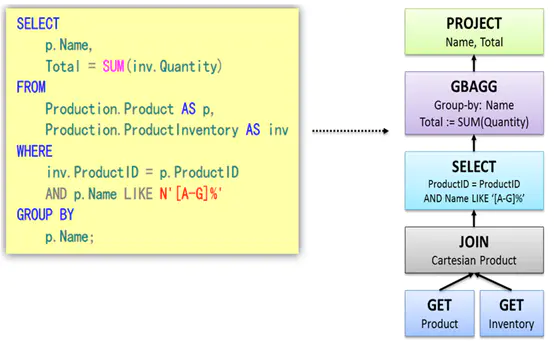
MapReduce����
������֮ǰ��������:
��Hive��MapReduce�����Ѿ������dz���ϸ�Ľ����ˡ�
�������Թ��ں�:��import_bigdata��,�����ݼ�����ܹ���
��Hive2.x�汾��,HiveSQL�ᱻת��ΪMR����,��Ҳ�����Ǿ���˵��HiveSQL��ִ��ԭ����
������������ Hive �ĵײ�ִ�мܹ�ͼ, Hive ����Ҫ����� Hadoop �����Ĺ���:
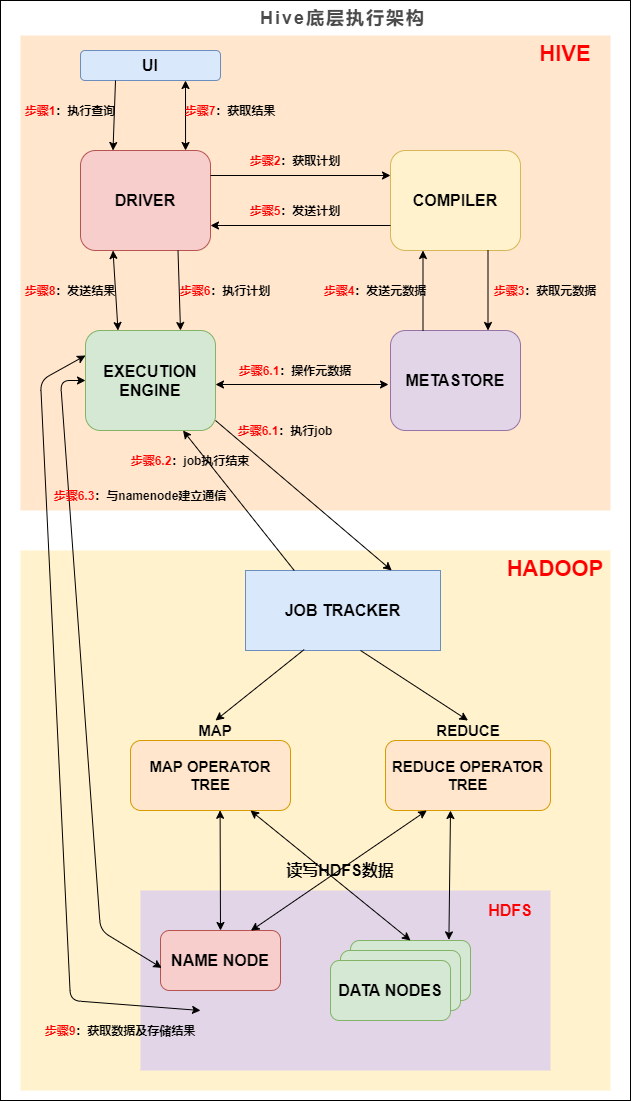
Hive�ײ�ִ�мܹ�
�� Hive ��һ��,�ܹ���������:
-
UI:�û����档�ɿ��������ύSQL���������н��档
-
DRIVER:���������ղ�ѯ������������ʵ���˻Ự����ĸ��
-
COMPILER:������������ SQL ת��Ϊƽ̨��ִ�е�ִ�мƻ����Բ�ͬ�IJ�ѯ��Ͳ�ѯ����ʽ�����������,�����ս������ʹ� metastore ���ҵķ���Ԫ����������ִ�мƻ���
-
METASTORE:Ԫ���ݿ⡣�洢 Hive �и��ֱ��ͷ��������нṹ��Ϣ��
-
EXECUTION ENGINE:ִ�����档�����ύ COMPILER �α���õ�ִ�мƻ�����ͬ��ƽ̨�ϡ�
��ͼ�Ļ���������:
-
����1:UI ���� DRIVER �Ľӿ�;
-
����2:DRIVER Ϊ��ѯ�����Ự���,������ѯ���͵� COMPILER(������)����ִ�мƻ�;
-
����3��4:��������Ԫ���ݴ洢�л�ȡ���β�ѯ����Ҫ��Ԫ����,��Ԫ�������ڶԲ�ѯ���еı���ʽ�������ͼ��,�Լ����ڲ�ѯν��������;
-
����5:���������ɵļƻ��Ƿֽε�DAG,ÿ����Ҫô�� map/reduce ��ҵ,Ҫô��һ��Ԫ���ݻ���HDFS�ϵIJ����������ɵļƻ����� DRIVER��
����� map/reduce ��ҵ,�üƻ����� map operator trees ��һ�� reduce operator tree,ִ�����潫�����Щ��ҵ���� MapReduce :
-
����6��6.1��6.2��6.3:ִ�����潫��Щ���ύ���ʵ����������ÿ�� task(mapper/reducer) ��,��HDFS�ļ��ж�ȡ������м���������������,��ͨ�����������������Щ���ݡ�������Щ����ͨ�����л���д�뵽һ����ʱHDFS�ļ���(�������Ҫ reduce ��,���� map �в���)����ʱ�ļ�������ƻ��к���� map/reduce ���ṩ���ݡ�
-
����7��8��9:���յ���ʱ�ļ����ƶ�������λ��,ȷ������ȡ������(�ļ���������HDFS����ԭ�Ӳ���)�������û��IJ�ѯ,��ʱ�ļ���������ִ������ֱ�Ӵ�HDFS��ȡ,Ȼ��ͨ��Driver���͵�UI��
Hive SQL ����� MapReduce ����
���Ų�������һƪ�dz���ϸ�IJ��ͽ��⡶Hive SQL�ı�����̡���
����Բο�: https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
���� SQL �����������Ͻ��н��ܵ� COMPILER(���������)����ɵġ�Hive��SQLת��ΪMapReduce����,����������̷�Ϊ������:
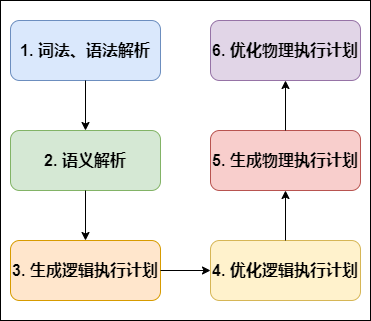
Hive SQL�������
-
�ʷ��������: Antlr ���� SQL �������,��� SQL �ʷ�,�����,�� SQL ת��Ϊ������� AST Tree;
Antlr��һ������ʶ��Ĺ���,�������������������ԡ�ʹ��Antlr�����ض�������ֻ��Ҫ��дһ����ļ�,����ʷ�����滻����,Antlr����˴ʷ������������������������м�������ɵĹ��̡�
-
�������: ���� AST Tree,�������ѯ�Ļ�����ɵ�Ԫ QueryBlock;
-
������ִ�мƻ�: ���� QueryBlock,����Ϊִ�в����� OperatorTree;
-
�Ż���ִ�мƻ�: �����Ż������� OperatorTree �任,�ϲ� Operator,�ﵽ���� MapReduce Job,�������ݴ��估 shuffle ������;
-
��������ִ�мƻ�: ���� OperatorTree,����Ϊ MapReduce ����;
-
�Ż�����ִ�мƻ�: �������Ż������� MapReduce ����ı任,�������յ�ִ�мƻ���
���������������ϸ����:
Ϊ��������,������һ���IJ�ѯ������չʾ,��5��23�ŵĵ���ά�����в�ѯ:
select?*?from?dim.dim_region?where?dt?=?'2021-05-23';
��һ:�ʷ��������
����Antlr�����sql�����,�����sql���дʷ��������,ת��Ϊ�������AST Tree:
ABSTRACT?SYNTAX?TREE:
TOK_QUERY
????TOK_FROM?
????TOK_TABREF
???????????TOK_TABNAME
???????????????dim
?????????????????dim_region
????TOK_INSERT
??????TOK_DESTINATION
??????????TOK_DIR
??????????????TOK_TMP_FILE
????????TOK_SELECT
??????????TOK_SELEXPR
??????????????TOK_ALLCOLREF
????????TOK_WHERE
??????????=
??????????????TOK_TABLE_OR_COL
??????????????????dt
????????????????????'2021-05-23'
�ζ�:�������
����AST Tree,�������ѯ�Ļ�����ɵ�ԪQueryBlock:
AST Tree���ɺ������临�Ӷ����ɽϸ�,�����ڷ���Ϊmapreduce����,��Ҫ���н�һ������ͽṹ��,�γ�QueryBlock��
QueryBlock��һ��SQL���������ɵ�Ԫ,������������:����Դ,�������,�����������һ��QueryBlock����һ���Ӳ�ѯ��
QueryBlock�����ɹ���Ϊһ���ݹ����,������� AST Tree ,������ͬ�� Token �ڵ�(����Ϊ������),���浽��Ӧ�������С�
����:������ִ�мƻ�
����QueryBlock,����Ϊִ�в�����OperatorTree:
Hive�������ɵ�MapReduce����,Map�κ�Reduce�ξ���OperatorTree��ɡ�
�����IJ���������:
TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator`
Operator��Map Reduce��֮������ݴ��ݶ���һ����ʽ�Ĺ��̡�ÿһ��Operator��һ��������ɲ�����֮�����ݴ��ݸ�childOperator���㡣
����Join/GroupBy/OrderBy����Ҫ��Reduce�����,������������Ӧ������Operator֮ǰ����������һ��ReduceSinkOperator,���ֶ���ϲ����л�ΪReduce Key/value, Partition Key��
����:�Ż���ִ�мƻ�
Hive�е�����ѯ�Ż����Դ��·�Ϊ���¼���:
-
ͶӰ��
-
�Ƶ�����ν��
-
�����
-
��Select-Select,Filter-Filter�ϲ�Ϊ��������
-
��· Join
-
��ѯ��д����ӦijЩ��ֵ��Join��б
����:��������ִ�мƻ�
��������ִ�мƻ����ǽ���ִ�мƻ����ɵ�OperatorTreeת��ΪMapReduce Job�Ĺ���,��Ҫ��Ϊ���漸����:
-
�����������MoveTask
-
��OperatorTree������һ�����ڵ�����������ȱ���
-
ReduceSinkOperator��ʾMap/Reduce�Ľ���,���Job��Ľ���
-
�����������ڵ�,��������JoinOperator�ϲ�MapReduceTask
-
����StatTask����Ԫ����
-
����Map��Reduce���Operator�Ĺ�ϵ
����:�Ż�����ִ�мƻ�
Hive�е������Ż����Դ��·�Ϊ���¼���:
-
������(Partition Pruning)
-
���ڷ�����Ͱ��ɨ����(Scan pruning)
-
�����ѯ���ڳ���,��ɨ����
-
��ijЩ�����,�� map ��Ӧ�� Group By
-
�� mapper ��ִ�� Join
-
�Ż� Union,ʹUnionֻ�� map ��ִ��
-
�ڶ�· Join ��,�����û���ʾ����������ĸ���
-
ɾ������Ҫ�� ReduceSinkOperators
-
���ڴ���Limit�Ӿ�IJ�ѯ,������ҪΪ�ñ�ɨ����ļ���
-
���ڴ���Limit�Ӿ�IJ�ѯ,ͨ������ ReduceSinkOperator ���ɵ��������������� mapper �����
-
�����û��ύ��SQL��ѯ�����Tez��ҵ����
-
����Ǽ���ȡ��ѯ,����ʹ��MapReduce��ҵ
-
���ڴ��оۺϵļ�ȡ��ѯ,ִ�в��� MapReduce ����ľۺ�
-
��д Group By ��ѯʹ������������ԭ���ı�
-
����ɨ��֮�ϵ�ν�������ν����ν���е��о�������ʱ,ʹ������ɨ��
��������������,SQL �ͱ�����ӳ����˼�Ⱥ�ϵ� MapReduce ����
Explain�
Hive Explain �������Mysql ��Explain ���,�ṩ�˶�Ӧ��ѯ��ִ�мƻ�,��������������Hive�ײ�����Hive���š�Hive SQL��д�ȷ����ṩ��һ������,�����ǵ�������������һ����������Ĺ��ߡ�
Hive Explain�
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
Hive Explain�����������,���潫���ն�Ӧ���Ӿ����̽�֡�
EXTENDED ������ִ�мƻ��в�����������(Operator)�Ķ�����Ϣ,��Щ��Ϣ���ǵ��͵�������Ϣ,���ļ����Ƶȡ�
��ִ��Explain QUERY ֮��,һ����ѯ�ᱻת��Ϊ�������Stage�����(����������һ��DAG)����ЩStagesҪô��map/reduce Stage,Ҫô����ЩԪ���ݻ��ļ�ϵͳ������Stage (�� move ��rename��)��Explain���������2������:
-
ִ�мƻ���ͬStage֮���������ϵ(Dependency)
-
ÿ��Stage��ִ��������Ϣ(Description)
���½�ͨ��һ�������ӽ��н��͡�
ִ��Explain ���
EXPLAIN?
SELECT?SUM(id)?FROM?test1;
Explain����������
-
����ͼ
STAGE?DEPENDENCIES:
??Stage-1?is?a?root?stage
??Stage-0?depends?on?stages:?Stage-1
STAGE?PLANS:
??Stage:?Stage-1
????Map?Reduce
??????Map?Operator?Tree:
??????????TableScan
????????????alias:?test1
????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????Select?Operator
??????????????expressions:?id?(type:?int)
??????????????outputColumnNames:?id
??????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????Group?By?Operator
????????????????aggregations:?sum(id)
????????????????mode:?hash
????????????????outputColumnNames:?_col0
????????????????Statistics:?Num?rows:?1?Data?size:?8?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????Reduce?Output?Operator
??????????????????sort?order:
??????????????????Statistics:?Num?rows:?1?Data?size:?8?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????????value?expressions:?_col0?(type:?bigint)
??????Reduce?Operator?Tree:
????????Group?By?Operator
??????????aggregations:?sum(VALUE._col0)
??????????mode:?mergepartial
??????????outputColumnNames:?_col0
??????????Statistics:?Num?rows:?1?Data?size:?8?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????File?Output?Operator
????????????compressed:?false
????????????Statistics:?Num?rows:?1?Data?size:?8?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????table:
????????????????input?format:?org.apache.hadoop.mapred.SequenceFileInputFormat
????????????????output?format:?org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
????????????????serde:?org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
??Stage:?Stage-0
????Fetch?Operator
??????limit:?-1
??????Processor?Tree:
????????ListSink
һ��HIVE��ѯ��ת��Ϊһ����һ������stage��ɵ�����(������ͼDAG)����Щstage������MapReduce stage,Ҳ�����Ǹ���Ԫ���ݴ洢��stage,Ҳ�����Ǹ����ļ�ϵͳ�IJ���(�����ƶ���������)��stage��
���ǽ����������ֿ�,�ȴ�����㿪ʼ,����������IJ���:
-
stage dependencies:����stage֮���������
-
stage plan:����stage��ִ�мƻ�
�ȿ���һ���� stage dependencies ,�������� stage,Stage-1 �Ǹ�stage,˵�����ǿ�ʼ��stage,Stage-0 ���� Stage-1,Stage-1ִ����ɺ�ִ��Stage-0��
�ٿ��ڶ����� stage plan,������һ�� Map Reduce,һ��MR��ִ�мƻ���Ϊ��������
-
Map Operator Tree:MAP�˵�ִ�мƻ���
-
Reduce Operator Tree:Reduce�˵�ִ�мƻ���
������ִ�мƻ��������������sql���� operator
-
TableScan:��ɨ�����,map�˵�һ�������϶��Ǽ��ر�,���Ծ��DZ�ɨ�����,����������:
alias:������
Statistics:��ͳ����Ϣ,����������������,���ݴ�С��
-
Select Operator:ѡȡ����,���������� :
expressions:��Ҫ���ֶ����Ƽ��ֶ�����
outputColumnNames:�����������
Statistics:��ͳ����Ϣ,����������������,���ݴ�С��
-
Group By Operator:����ۺϲ���,����������:
aggregations:��ʾ�ۺϺ�����Ϣ.
mode:�ۺ�ģʽ,ֵ��?hash:����ۺ�,����hash?partition;partial:�ֲ��ۺ�;final:���վۺ�.
keys:������ֶ�,���û�з���,��û�д��ֶ�.
outputColumnNames:�ۺ�֮���������.
Statistics:��ͳ����Ϣ,��������ۺ�֮�����������,���ݴ�С��.
-
Reduce Output Operator:�����reduce����,��������:
sort?order:ֵΪ��?������;ֵΪ?+?��������,ֵΪ?-?��������;ֵΪ?��?�������Ϊ����,��һ��Ϊ����,�ڶ���Ϊ����.
-
Filter Operator:���˲���,����������:
predicate:��������,��sql����е�where?id>=1,��˴���ʾ(id?>=?1).
-
Map Join Operator:join ����,����������:
condition?map:join��ʽ?,��Inner?Join?0?to?1?Left?Outer?Join0?to?2
keys:?join?�������ֶ�
outputColumnNames:join?���֮��������ֶ�
Statistics:join?���֮�����ɵ���������,��С��
-
File Output Operator:�ļ��������,����������:
compressed:�Ƿ�ѹ��
table:������Ϣ,������������ļ���ʽ����ʽ,���л���ʽ��
-
Fetch Operator �ͻ��˻�ȡ���ݲ���,����������:
limit,ֵΪ?-1?��ʾ����������,����ֵΪ���Ƶ�����
Explainʹ�ó���
��ôExplain�ܹ�Ϊ����������ʵ���д�����Щ���������������Щ�Ի���?
�������Թ��ں�:��import_bigdata��,�����ݼ�����ܹ���
join ������� Null ��ֵ��?
����,������hive cli �������²�ѯ�ƻ����
select?a.id,b.user_name?from?test1?a?join?test2?b?on?a.id=b.id;
Ȼ��ִ��:
explain?select?a.id,b.user_name?from?test1?a?join?test2?b?on?a.id=b.id;
�����������:
TableScan
?alias:?a
?Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
?Filter?Operator
????predicate:?id?is?not?null?(type:?boolean)
????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????Select?Operator
????????expressions:?id?(type:?int)
????????outputColumnNames:?_col0
????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????HashTable?Sink?Operator
???????????keys:
?????????????0?_col0?(type:?int)
?????????????1?_col0?(type:?int)
?...
������������Կ��� predicate: id is not null ����һ��,˵�� join ʱ���Զ����˵������ֶ�Ϊ null ֵ�����,�� left join �� full join �Dz����Զ�����nullֵ��,��ҿ������г����¡�
group by �����������������?
select?id,max(user_name)?from?test1?group?by?id;
ֱ������ explain ֮����:
TableScan
????alias:?test1
????Statistics:?Num?rows:?9?Data?size:?108?Basic?stats:?COMPLETE?Column?stats:?NONE
????Select?Operator
????????expressions:?id?(type:?int),?user_name?(type:?string)
????????outputColumnNames:?id,?user_name
????????Statistics:?Num?rows:?9?Data?size:?108?Basic?stats:?COMPLETE?Column?stats:?NONE
????????Group?By?Operator
???????????aggregations:?max(user_name)
???????????keys:?id?(type:?int)
???????????mode:?hash
???????????outputColumnNames:?_col0,?_col1
???????????Statistics:?Num?rows:?9?Data?size:?108?Basic?stats:?COMPLETE?Column?stats:?NONE
???????????Reduce?Output?Operator
?????????????key?expressions:?_col0?(type:?int)
?????????????sort?order:?+
?????????????Map-reduce?partition?columns:?_col0?(type:?int)
?????????????Statistics:?Num?rows:?9?Data?size:?108?Basic?stats:?COMPLETE?Column?stats:?NONE
?????????????value?expressions:?_col1?(type:?string)
?...
���ǿ� Group By Operator,������ keys: id (type: int) ˵������ id ���з����,�����¿����� sort order: + ,˵���ǰ��� id �ֶν�����������ġ�
����sqlִ��Ч�ʸ�
�۲���������sql:
SELECT
?a.id,
?b.user_name
FROM
?test1?a
JOIN?test2?b?ON?a.id?=?b.id
WHERE
?a.id?>?2;
SELECT
?a.id,
?b.user_name
FROM
?(SELECT?*?FROM?test1?WHERE?id?>?2)?a
JOIN?test2?b?ON?a.id?=?b.id;
������sql�������Ľ����һ����,��������sqlִ��Ч�ʸ���?
����˵��һ��sqlִ��Ч�ʸ�,��Ϊ�ڶ���sql���Ӳ�ѯ,�Ӳ�ѯ��Ӱ������; ����˵�ڶ���sqlִ��Ч�ʸ�,��Ϊ�ȹ���֮��,�ڽ���joinʱ������������,����ִ��Ч�ʾ��ˡ� ��������sqlЧ�ʸ���,����ֱ����sql���ǰ����� explain,����ִ�мƻ�����֪������!
�ڵ�һ��sql���ǰ���� explain,�õ����½��:
hive?(default)>?explain?select?a.id,b.user_name?from?test1?a?join?test2?b?on?a.id=b.id?where?a.id?>2;
OK
Explain
STAGE?DEPENDENCIES:
??Stage-4?is?a?root?stage
??Stage-3?depends?on?stages:?Stage-4
??Stage-0?depends?on?stages:?Stage-3
STAGE?PLANS:
??Stage:?Stage-4
????Map?Reduce?Local?Work
??????Alias?->?Map?Local?Tables:
????????$hdt$_0:a
??????????Fetch?Operator
????????????limit:?-1
??????Alias?->?Map?Local?Operator?Tree:
????????$hdt$_0:a
??????????TableScan
????????????alias:?a
????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????Filter?Operator
??????????????predicate:?(id?>?2)?(type:?boolean)
??????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????Select?Operator
????????????????expressions:?id?(type:?int)
????????????????outputColumnNames:?_col0
????????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????HashTable?Sink?Operator
??????????????????keys:
????????????????????0?_col0?(type:?int)
????????????????????1?_col0?(type:?int)
??Stage:?Stage-3
????Map?Reduce
??????Map?Operator?Tree:
??????????TableScan
????????????alias:?b
????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????Filter?Operator
??????????????predicate:?(id?>?2)?(type:?boolean)
??????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????Select?Operator
????????????????expressions:?id?(type:?int),?user_name?(type:?string)
????????????????outputColumnNames:?_col0,?_col1
????????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????Map?Join?Operator
??????????????????condition?map:
???????????????????????Inner?Join?0?to?1
??????????????????keys:
????????????????????0?_col0?(type:?int)
????????????????????1?_col0?(type:?int)
??????????????????outputColumnNames:?_col0,?_col2
??????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????????Select?Operator
????????????????????expressions:?_col0?(type:?int),?_col2?(type:?string)
????????????????????outputColumnNames:?_col0,?_col1
????????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????????File?Output?Operator
??????????????????????compressed:?false
??????????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????????????table:
??????????????????????????input?format:?org.apache.hadoop.mapred.SequenceFileInputFormat
??????????????????????????output?format:?org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
??????????????????????????serde:?org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
??????Local?Work:
????????Map?Reduce?Local?Work
??Stage:?Stage-0
????Fetch?Operator
??????limit:?-1
??????Processor?Tree:
????????ListSink
�ڵڶ���sql���ǰ���� explain,�õ����½��:
hive?(default)>?explain?select?a.id,b.user_name?from(select?*?from??test1?where?id>2?)?a?join?test2?b?on?a.id=b.id;
OK
Explain
STAGE?DEPENDENCIES:
??Stage-4?is?a?root?stage
??Stage-3?depends?on?stages:?Stage-4
??Stage-0?depends?on?stages:?Stage-3
STAGE?PLANS:
??Stage:?Stage-4
????Map?Reduce?Local?Work
??????Alias?->?Map?Local?Tables:
????????$hdt$_0:test1
??????????Fetch?Operator
????????????limit:?-1
??????Alias?->?Map?Local?Operator?Tree:
????????$hdt$_0:test1
??????????TableScan
????????????alias:?test1
????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????Filter?Operator
??????????????predicate:?(id?>?2)?(type:?boolean)
??????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????Select?Operator
????????????????expressions:?id?(type:?int)
????????????????outputColumnNames:?_col0
????????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????HashTable?Sink?Operator
??????????????????keys:
????????????????????0?_col0?(type:?int)
????????????????????1?_col0?(type:?int)
??Stage:?Stage-3
????Map?Reduce
??????Map?Operator?Tree:
??????????TableScan
????????????alias:?b
????????????Statistics:?Num?rows:?6?Data?size:?75?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????Filter?Operator
??????????????predicate:?(id?>?2)?(type:?boolean)
??????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????Select?Operator
????????????????expressions:?id?(type:?int),?user_name?(type:?string)
????????????????outputColumnNames:?_col0,?_col1
????????????????Statistics:?Num?rows:?2?Data?size:?25?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????Map?Join?Operator
??????????????????condition?map:
???????????????????????Inner?Join?0?to?1
??????????????????keys:
????????????????????0?_col0?(type:?int)
????????????????????1?_col0?(type:?int)
??????????????????outputColumnNames:?_col0,?_col2
??????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????????Select?Operator
????????????????????expressions:?_col0?(type:?int),?_col2?(type:?string)
????????????????????outputColumnNames:?_col0,?_col1
????????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
????????????????????File?Output?Operator
??????????????????????compressed:?false
??????????????????????Statistics:?Num?rows:?2?Data?size:?27?Basic?stats:?COMPLETE?Column?stats:?NONE
??????????????????????table:
??????????????????????????input?format:?org.apache.hadoop.mapred.SequenceFileInputFormat
??????????????????????????output?format:?org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
??????????????????????????serde:?org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
??????Local?Work:
????????Map?Reduce?Local?Work
??Stage:?Stage-0
????Fetch?Operator
??????limit:?-1
??????Processor?Tree:
????????ListSink
-
�����ʲô����,���˱�������һ��,������ִ�мƻ���ȫһ��,�����Ƚ��� where ��������,�ڽ��� join ����������˵�� hive �ײ���Զ������ǽ����Ż�,����������sql���ִ��Ч����һ���ġ�
-
���Ͻ��о���3�����������м���Ϥ���е��Ժ�������,explain ���кܶ���������;,��鿴stage������������Ų�������б��hive ���ŵ�,С����ǿ������г��ԡ�
explain dependency���÷�
explain dependency��������һ��SQL��Ҫ��������Դ,�����һ��json��ʽ������,������������������ֵ�����:
-
input_partitions:����һ��SQL������������Դ������,����洢���Ƿ��������б�,�������SQL���������б����ǷǷ�����,����ʾΪ�ա�
-
input_tables:����һ��SQL������������Դ��,����洢����Hive�������б���
ʹ��explain dependency�鿴SQL��ѯ�Ƿ�����ͨ��,�� hive cli ��������������:
explain?dependency?select?s_age,count(1)?num?from?student_orc;
�õ����½��:
{"input_partitions":[],"input_tables":[{"tablename":"default@student_tb?_orc","tabletype":"MANAGED_TABLE"}]}
ʹ��explain dependency�鿴SQL��ѯ������,�� hive cli ��������������:
explain?dependency?select?s_age,count(1)?num?from?student_orc_partition;
�õ����:
{"input_partitions":[{"partitionName":"default@student_orc_partition@?part=0"},?
{"partitionName":"default@student_orc_partition@part=1"},?
{"partitionName":"default@student_orc_partition@part=2"},?
{"partitionName":"default@student_orc_partition@part=3"},
{"partitionName":"default@student_orc_partition@part=4"},?
{"partitionName":"default@student_orc_partition@part=5"},
{"partitionName":"default@student_orc_partition@part=6"},
{"partitionName":"default@student_orc_partition@part=7"},
{"partitionName":"default@student_orc_partition@part=8"},
{"partitionName":"default@student_orc_partition@part=9"}],?
"input_tables":[{"tablename":"default@student_orc_partition",?"tabletype":"MANAGED_TABLE"}]
explain dependency��ʹ�ó���������:
-
����һ:�����ų��������ų���Ϊ��ȡ������Ӧ���������ݶ�����������������쳣������,��һ�����������������,����������Ϊ�������̲��ɿ����س����쳣���߿���,�����������������쳣��ͨ�����ַ�ʽ,���Կ��ٲ鿴SQL��ȡ�ķ����Ƿ�����쳣��
-
������:�����������,����������������,�ر��������������ж����Ӳ�ѯ,������ӵ��������롣
����ͨ��������������explain dependency��ʵ������:
ʶ���Ƶȼ۵Ĵ���
����������������ȵ�sql:
����һ:
select?
a.s_no?
from?student_orc_partition?a?
inner?join?
student_orc_partition_only?b?
on?a.s_no=b.s_no?and?a.part=b.part?and?a.part>=1?and?a.part<=2;
�����:
select?
a.s_no?
from?student_orc_partition?a?
inner?join?
student_orc_partition_only?b?
on?a.s_no=b.s_no?and?a.part=b.part?
where?a.part>=1?and?a.part<=2;
���ǿ����������δ���explain dependency��������:
����1��explain dependency���:
{"input_partitions":?
[{"partitionName":"default@student_orc_partition@part=0"},?
{"partitionName":"default@student_orc_partition@part=1"},?
{"partitionName":"default@student_orc_partition@part=2"},
{"partitionName":"default@student_orc_partition_only@part=1"},?
{"partitionName":"default@student_orc_partition_only@part=2"}],?
"input_tables":?[{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"},?{"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
����2��explain dependency���:
{"input_partitions":?
[{"partitionName":"default@student_orc_partition@part=1"},?
{"partitionName"?:?"default@student_orc_partition@part=2"},
{"partitionName"?:"default@student_orc_partition_only@part=1"},
{"partitionName":"default@student_orc_partition_only@part=2"}],?
"input_tables":?[{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"},?{"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
ͨ����������������Կ���,��ʵ����������SQL�����ȼ�,����1��������(inner join)�е���������(on)�м���ǵ�ֵ�Ĺ���������,��û�н������ӵ��������������չ����������й���,��������ִ��ʱ����ȡpart=0�ķ������ݡ����ڴ���2��,����˵������������ķ�����
ʶ��SQL��ȡ���ݷ�Χ�IJ��
�����������:
����һ:
explain?dependency
select
a.s_no?
from?student_orc_partition?a?
left?join?
student_orc_partition_only?b?
on?a.s_no=b.s_no?and?a.part=b.part?and?b.part>=1?and?b.part<=2;
�����:
explain?dependency?
select?
a.s_no?
from?student_orc_partition?a?
left?join?
student_orc_partition_only?b?
on?a.s_no=b.s_no?and?a.part=b.part?and?a.part>=1?and?a.part<=2;
����������������ݶ�ȡ��Χ��һ������?���Dz�һ��,����ͨ��explain dependency������:
����1��explain dependency���:
{"input_partitions":?
[{"partitionName":?"default@student_orc_partition@part=0"},?
{"partitionName":"default@student_orc_partition@part=1"},?���м�ʡ��7������
{"partitionName":"default@student_orc_partition@part=9"},?
{"partitionName":"default@student_orc_partition_only@part=1"},?
{"partitionName":"default@student_orc_partition_only@part=2"}],?
"input_tables":?[{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"},?{"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
����2��explain dependency���:
{"input_partitions":?
[{"partitionName":"default@student_orc_partition@part=0"},?
{"partitionName":"default@student_orc_partition@part=1"},?���м�ʡ��7������?
{"partitionName":"default@student_orc_partition@part=9"},?
{"partitionName":"default@student_orc_partition_only@part=0"},?
{"partitionName":"default@student_orc_partition_only@part=1"},?���м�ʡ��7������?
{"partitionName":"default@student_orc_partition_only@part=9"}],
"input_tables":?[{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"},?{"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
���Կ���,���������������������м���ǵ�ֵ���˵�����,��������������������ұ�(b��)�����˵�Ч��,���ұ�ֻҪɨ��������������,�������(a��)�����ȫ��ɨ�衣�������������������,����ȫû�����˵�����,��ô������������ȫ��ɨ�衣��ʱ���������ͬȫ������һ������Ҫ���������ݽ���ȫ��ɨ�衣
��ʹ�ù�����,������Ϊ����Ƭ��2���������Ƭ��1һ���������ݹ���,ͨ���鿴explain dependency��������,����֪��������ˡ�
explain authorization ���÷�
ͨ��explain authorization����֪����ǰSQL���ʵ�������Դ(INPUTS) ���������(OUTPUTS),�Լ���ǰHive�ķ����û� (CURRENT_USER)�Ͳ���(OPERATION)��
�� hive cli ��������������:
explain?authorization?
select?variance(s_score)?from?student_tb_orc;
�������:
INPUTS:?
??default@student_tb_orc?
OUTPUTS:?
??hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194-?90f1475a3ed5/-mr-10000?
CURRENT_USER:?
??hdfs?
OPERATION:?
??QUERY?
AUTHORIZATION_FAILURES:?
??No?privilege?'Select'?found?for?inputs?{?database:default,?table:student_?tb_orc,?columnName:s_score}
���������Ϣ��֪:
-
���永����������Դ��defalut���ݿ��е� student_tb_orc��;
-
���ݵ����·����hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194-90f1475a3ed5/-mr-10000;
-
��ǰ�IJ����û���hdfs,�����Dz�ѯ;
-
�۲��������Ϣ���ǻ��ῴ��AUTHORIZATION_FAILURES��Ϣ,��ʾ�Ե�ǰ������û�в�ѯȨ��,��������������SQL�Ļ�Ҳ�ܹ��������С�Ϊʲô������������?Hive��Ĭ�ϲ�����Ȩ����������²�����Ȩ����֤,���е��û���Hive���涼�dz�������Ա,��ʹ�����ض����û����и�Ȩ,Ҳ�ܹ�������ѯ��
Tez����
Tez��Apache��Դ��֧��DAG��ҵ�ļ�����,��֧��HADOOP2.x����Ҫ���档��Դ��MapReduce���,����˼���ǽ�Map��Reduce����������һ�����,�ֽ���Ԫ������������������,�����µIJ���,��Щ��������һЩ���Ƴ�����װ��,���γ�һ�����DAG��ҵ��
Tez��Map task��Reduce task��һ�����Ϊ����ͼ��ʾ:
Tez��task��Input��processor��output�����,���Ա������и��ӵ�map��reduce����,����ͼ:
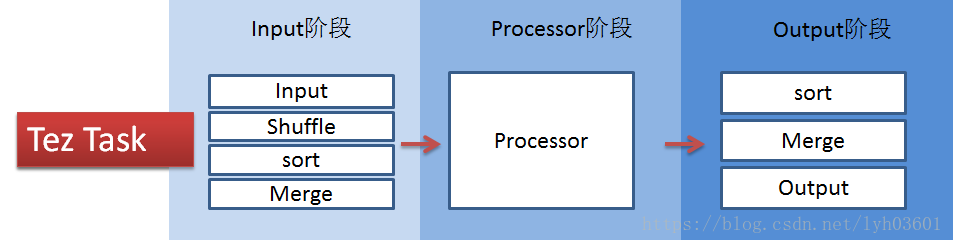
�������Թ��ں�:��import_bigdata��,�����ݼ�����ܹ���
Tez��ʵ��
Tez�����ṩ��6�ֿɱ�����,�ֱ���:
1)Input:����������Դ�ij���,�������������ݸ�ʽ,���³�һ����Key/value
2)Output:���������Դ�ij���,�����û����������Key/valueд���ļ�ϵͳ
3)Paritioner:�����ݽ��з�Ƭ,������MR�е�Partitioner
4)Processor:�Լ���ij���,����һ��Input�л�ȡ����,��������,ͨ��Output���
5)Task:������ij���,ÿ��Task��һ��Input��Ouput��Processor���
6)Maser:��������Task��������ϵ,����˳������ϵִ������
��������6�����,Tez���ṩ����������,�ֱ���Sort(����)��Shuffle(��ϴ),Ϊ���û�ʹ�÷���,�����ṩ�˶���Input��Output��Task��Sort��ʵ��,��������:
1)Inputʵ��:LocalMergedInput(�ļ����غϲ�����Ϊ����),ShuffledMergedInput(Զ�̿��������Һϲ�����Ϊ����)
2)Outputʵ��:InMemorySortedOutput(�ڴ���������),LocalOnFileSorterOutput(���ش�����������),OnFileSortedOutput(������������)
3)Taskʵ��:RunTimeTask(�dz���Task,����û��ʲô��)
4)Sortʵ��:DefaultSorter(������������),InMemoryShuffleSorter(Զ�̿������ݲ�����)
Ϊ��չʾTez��ʹ�÷�������֤Tez��ܵĿ�����,Apache��YARN MRAppMaster������ʹ��Tez��̽ӿ����������MapReduce���,ʹ֮��������YARN�С�Ϊ��,Tez�ṩ�����¼������:
1)Input:SimpleInput(ֱ��ʹ��MR InputFormat��ȡ����)
2)Output:SimpleOutput(ֱ��ʹ��MR OutputFormat��ȡ����)
3)Partition:MRPartitioner(ֱ��ʹ��MR Partitioner��ȡ����)
4)Processor:MapProcessor(ִ��Map Task),ReduceProcessor(ִ��Reduce Task)
5)Task:FinalTask,InitialTask,initialTaskWithInMemSort,InitialTaskWithLocalSort ,IntermediateTask,LocalFinalTask,MapOnlyTask��
����MapReduce��ҵ����,���ֻ��Map Task,��ʹ��MapOnlyTask,����,Map Taskʹ��InitialTaskWithInMemSort��Reduce Task��FinalTask����Ȼ,��������д�������͵���ҵ,��ʹ�������κμ���Task�������,���硱InitialTaskWithInMemSort �C> FinalTask����MapReduce��ҵ��
Ϊ�˼���Tez����������,����Tez�ܹ�������YARN֮��,Tez�����˴�YARN��MRAppMater�Ĵ���,�����ͻ��ˡ���Դ���롢�����Ʋ�ִ�С����������ȡ�
Tez��MapReduce��ҵ�ıȽ�:
-
Tez�ƹ���MapReduce�ܶ��Ҫ���м�����ݴ洢�Ͷ�ȡ�Ĺ���,ֱ����һ����ҵ�б�����MapReduce��Ҫ�����ҵ��ͬЭ��������ɵ����顣
-
Tez��MapReduceһ��������ʹ��YARN��Ϊ��Դ���Ⱥ���������MapReduce on YARN��ͬ,Tez on YARN�����ǽ���ҵ�ύ��ResourceManager,�����ύ��AMPoolServer�ķ�����,AMPoolServer����������Ѿ�Ԥ������ApplicationMaster�ķ���
-
���û��ύһ����ҵ������,AMPoolServer����ѡ��һ��ApplicationMaster���ڹ����û��ύ��������ҵ,�����ȿ��Խ�ʡResourceManager����ApplicationMaster��ʱ��,�����ܹ�����ÿ��ApplicationMaster����Դ,��ʡ����Դ�ͷźʹ���ʱ�䡣
Tez�����MapReduce�м����ش�Ľ�:
-
����ѯ��Ҫ�ж��reduce��ʱ,Hive��MapReduce����Ὣ�ƻ��ֽ�,ÿ��Redcue�ύһ��MR��ҵ��������е�����MR��ҵ����Ҫ�������,ÿ����ҵ�������HDFS�����¶�ȡ��һ����ҵ�����������ϴ�ơ�����Tez��,����reduce����������ֱ������,���ݿ�����ˮ�ߴ���,������Ҫ��ʱHDFS�ļ�,����ģʽ��ΪMRR(Map-reduce-reduce*)��
-
Tez������һ�η���������ѯ�ƻ�,ʵ��Ӧ�ó���̬�滮,�Ӷ�ʹ����ܹ������ܵط�����Դ,��ͨ����������ˮ�ߴ������ݡ����ڸ����ӵIJ�ѯ��˵,����һ����ĸĽ�,��Ϊ��������IO/sync�ϰ�������֮��ĵ��ȿ�����
-
��MapReduce����������,�������ݴ�С,��Shuffle�ζ�����ͬ�ķ�ʽִ��,���������л�������,�������εij���ȥ��ȡ,�������л���Tez��������С���ݼ���ȫ���ڴ��д���,��MapReduce��û���������Ż����ֿ��ѯ������Ҫ�ڴ�������������ݺ��С�����ݼ����������ۺ�,Tez���Ż�Ҳ�ܼ��������Ч�ʡ�
�� Hive ���� Tez �dz���,ֻ��� hive-site.xml ������:
<property>
????<name>hive.execution.engine</name>
????<value>tez</value>
</property>
����hive.execution.engineΪ tez ����뵽 Hive ִ�� SQL:
hive>?select?count(*)?as?c?from?userinfo;
Query?ID?=?zhenqin_20161104150743_4155afab-4bfa-4e8a-acb0-90c8c50ecfb5
Total?jobs?=?1
Launching?Job?1?out?of?1
?
?
Status:?Running?(Executing?on?YARN?cluster?with?App?id?application_1478229439699_0007)
?
--------------------------------------------------------------------------------
????????VERTICES??????STATUS??TOTAL??COMPLETED??RUNNING??PENDING??FAILED??KILLED
--------------------------------------------------------------------------------
Map?1?..........???SUCCEEDED??????2??????????2????????0????????0???????0???????0
Reducer?2?......???SUCCEEDED??????1??????????1????????0????????0???????0???????0
--------------------------------------------------------------------------------
VERTICES:?02/02??[==========================>>]?100%??ELAPSED?TIME:?6.19?s?????
--------------------------------------------------------------------------------
OK
1000000
Time?taken:?6.611?seconds,?Fetched:?1?row(s)
���Կ���,�ҵ� userinfo ���� 100W ����¼,ִ��һ�� count ��Ҫ 6.19s�� ���ڰ� engine ��Ϊ mr
set?hive.execution.engine=mr;
�ٴ�ִ�� count userinfo:
hive>?select?count(*)?as?c?from?userinfo;
Query?ID?=?zhenqin_20161104152022_c7e6c5bd-d456-4ec7-b895-c81a369aab27
Total?jobs?=?1
Launching?Job?1?out?of?1
Starting?Job?=?job_1478229439699_0010,?Tracking?URL?=?http://localhost:8088/proxy/application_1478229439699_0010/
Kill?Command?=?/Users/zhenqin/software/hadoop/bin/hadoop?job??-kill?job_1478229439699_0010
Hadoop?job?information?for?Stage-1:?number?of?mappers:?1;?number?of?reducers:?1
2016-11-04?15:20:28,323?Stage-1?map?=?0%,??reduce?=?0%
2016-11-04?15:20:34,587?Stage-1?map?=?100%,??reduce?=?0%
2016-11-04?15:20:40,796?Stage-1?map?=?100%,??reduce?=?100%
Ended?Job?=?job_1478229439699_0010
MapReduce?Jobs?Launched:?
Stage-Stage-1:?Map:?1??Reduce:?1???HDFS?Read:?215?HDFS?Write:?0?SUCCESS
Total?MapReduce?CPU?Time?Spent:?0?msec
OK
1000000
Time?taken:?19.46?seconds,?Fetched:?1?row(s)
hive>?
���Կ���,ʹ�� Tez Ч�ʱ� MapReduce �н�3��������������,Hive ��ʹ�� Tez ����ִ��ʱ,�� ==>> ��̬�Ľ���ָʾ������ʹ�� mr ʱ,ֻ����־��� map and reduce �Ľ��Ȱٷֱȡ�ʹ�� tez,�������־Ҳ��ˬ�ܶࡣ
���Ҳ��Եĺܶิ�ӵ� SQL,Tez �Ķ��� MapReduce ��ܶ�,����ȡ���� SQL �ĸ��Ӷȡ�ִ�м� select �Ȳ��������� tez �����ơ�Tez �ڲ����� SQL ������� Map,Reduce,Reduce ���,�� MR ֻ�� Map->Reduce->Map->Reduce,�����ִ�и��� SQL ʱ, Tez ���������ԡ�
Tez �����Ż�
�Ż��β���(��ͬ��������,ʹ����tez��300s+����200s+)
set?hive.execution.engine=tez;
set?mapred.job.name=recommend_user_profile_$idate;
set?mapred.reduce.tasks=-1;
set?hive.exec.reducers.max=160;
set?hive.auto.convert.join=true;
set?hive.exec.parallel=true;
set?hive.exec.parallel.thread.number=16;?
set?hive.optimize.skewjoin=true;
set?hive.exec.reducers.bytes.per.reducer=100000000;
set?mapred.max.split.size=200000000;
set?mapred.min.split.size.per.node=100000000;
set?mapred.min.split.size.per.rack=100000000;
set?hive.hadoop.supports.splittable.combineinputformat=true;
set?hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Tez�ڴ��Ż�
1. AM��Container������
tez.am.resource.memory.mb
����˵��:Set tez.am.resource.memory.mb tobe the same as yarn.scheduler.minimum-allocation-mb the YARNminimum container size.
hive.tez.container.size
����˵��:Set hive.tez.container.size to be the same as or a small multiple(1 or 2 times that) of YARN container size yarn.scheduler.minimum-allocation-mb but NEVER more than yarn.scheduler.maximum-allocation-mb.
2. AM��Container JVM��������
tez.am.launch.cmd-opts?
Ĭ��ֵ:80% * tez.am.resource.memory.mb,һ�㲻��Ҫ����
hive.tez.java.ops
Ĭ��ֵ:80% * hive.tez.container.size ����˵��:Hortonworks����"�Cserver �CDjava.net.preferIPv4Stack=true�CXX:NewRatio=8 �CXX:+UseNUMA �CXX:UseG1G"
tez.container.max.java.heap.fraction
Ĭ��ֵ:0.8,����˵��:task/AMռ��JVM Xmx�ı���,�ò����������,����ݾ���ҵ�������;
3. Hive�ڴ�Map Join��������
tez.runtime.io.sort.mb
Ĭ��ֵ:100,����˵��:���������Ҫ���ڴ��С������ֵ:40% * hive.tez.container.size,һ�㲻����2G.
hive.auto.convert.join.noconditionaltask
Ĭ��ֵ:true,����˵��:�Ƿ��mapjoin�ϲ�Ϊһ��,ʹ��Ĭ��ֵ
hive.auto.convert.join.noconditionaltask.size
Ĭ��ֵΪ10MB,����˵��:���mapjoinת��Ϊ1��ʱ,����С�����ļ���С�ܺ͵����ֵ,���ֵֻ����������ı��ļ��Ĵ�С,��������ʵ��mapjoinʱhashtable�Ĵ�С�� ����ֵ:1/3 * hive.tez.container.size
tez.runtime.unordered.output.buffer.size-mb
Ĭ��ֵ:100,����˵��:Size of the buffer to use if not writing directly to disk������ֵ: 10% * hive.tez.container.size.
4. Container��������
tez.am.container.reuse.enabled
Ĭ��ֵ:true,����˵��:Container���ÿ���
Spark����
Hive������2014���Ƴ���Hive on Spark��Ŀ(HIVE-7292),��Spark��Ϊ��MapReduce��Tez֮��Hive�ĵ������������档����Ŀ��Cloudera��Intel��MapR�ȼ��ҹ�˾��ͬ����,���ܵ�������Hive��Spark���������Ĺ�ͬ��ע��ͨ������Ŀ,�������Hive��ѯ������,ͬʱΪ�Ѿ�������Hive����Spark���û��ṩ�˸�������ѡ��,�Ӷ���һ�����Hive��Spark���ռ��ʡ�
�������Թ��ں�:��import_bigdata��,�����ݼ�����ܹ���
�������
Hive on Spark��������˼·��,����������Hive������Ĺ���;�����������ƻ���ʼ,�ṩһ�������Spark��ʵ��,���� SparkCompiler��SparkTask��,����Hive�IJ�ѯ�Ϳ�����ΪSpark��������ִ���ˡ������Ǽ�����Ҫ�����ԭ��
-
�����ܼ��ٶ�Hiveԭ�д�����ġ����Ǻ�֮ǰ��Shark���˼·���IJ�ͬ��Shark��Hive�ĸĶ�̫������������Hive��������,Hive on Spark�������ٸĶ�Hive�Ĵ���,�Ӷ���Ӱ��HiveĿǰ��MapReduce��Tez��֧�֡�ͬʱ,Hive on Spark��֤�����е�MapReduce��Tezģʽ�ڹ��ܺ����ܷ��治�����κ�Ӱ�졣
-
����ѡ��Spark���û�,Ӧʹ���ܹ��Զ��Ļ�ȡHive���еĺ�δ�������Ĺ��ܡ�
-
�����ܽ���ά���ɱ�,���ֶ�Spark����������ϡ�
��������˼·��ԭ��,�����һЩ��Ƽܹ����¡�
Hive ���û�����ͨ��hive.execution.engine�����ü�������,Ŀǰ�ò�����ѡ��ֵΪmr��tez��Ϊ��ʵ��Hive on Spark,���ǽ�spark��Ϊ�ò����ĵ�����ѡ�Ҫ����Hive on Sparkģʽ,�û����轫�����������Ϊspark���ɡ�
��hive��ʹ��������俪��:
hive>?set?hive.execution.engine=spark;
�������
Spark �Էֲ�ʽ�ɿ����ݼ�(Resilient Distributed Dataset,RDD)��Ϊ�����ݳ���,���������Ҫ��Hive�ı�ת��ΪRDD�Ա�Spark������������,Hive�ı���Spark�� HadoopRDD����HDFS�ϵ�һ���ļ�,ͨ��InputFormat��RecordReader��ȡ���е�����,������ת������Ȼ��Ȼ�ġ�
SparkΪRDD�ṩ��һϵ�е�ת��(Transformation),������Щת��Ҳ������SQL ��,��groupByKey��join�ȡ������ʹ����Щת��(����Shark����������),����ζ������Ҫ����ʵ��һЩHive���еĹ���;���ҵ� Hive�����µĹ���ʱ,������Ҫ��Ӧ����Hive on Sparkģʽ���м��ڴ�,����ѡ��Hive�IJ�������װΪFunction,Ȼ��Ӧ�õ�RDD�ϡ�����,����ֻ��Ҫ�������ٵļ���RDD��ת��,����Ҫ�ļ���������Hive�ṩ��
����ʹ����Hive��ԭ��,���������Ҫ��ʽ�ص���һЩTransformation��ʵ��Shuffle�Ĺ��ܡ��±����о���Hive on Sparkʹ�õ�����ת����
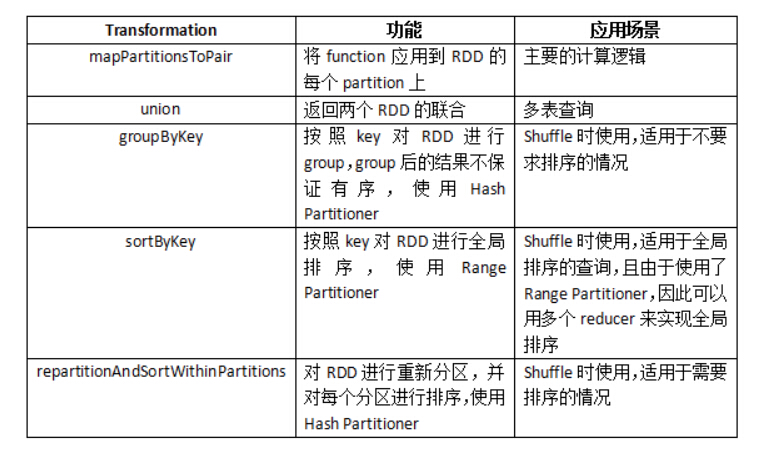
Hive on Spark
��repartitionAndSortWithinPartitions ��˵��һ��,���������SPARK-2978����,Ŀ�����ṩһ��MapReduce����Shuffle����ȻsortByKeyҲ�ṩ������Ĺ� ��,��ijЩ��������Dz�����Ҫȫ������,������ʹ�õ�Range Partitioner����ijЩHive�IJ�ѯ�������á�
����ִ�мƻ�
ͨ��SparkCompiler��Operator Treeת��ΪTask Tree,������Ҫ�ύ��Sparkִ�е�����ΪSparkTask����ͬ��MapReduce��Map+Reduce������ִ��ģʽ,Spark����DAGִ��ģʽ,���һ��SparkTask������һ����ʾRDDת����DAG,���ǽ����DAG��װΪSparkWork��ִ��SparkTask ʱ,����SparkWork����ʾ��DAG��������յ�RDD,Ȼ��ͨ��RDD��foreachAsync���������㡣ʹ��foreachAsync����Ϊ����ʹ����Hiveԭ��,��˲���ҪRDD���ؽ��;����foreachAsync�첽�ύ����������Ƕ�������м�ء�
SparkContext��������
SparkContext ���û���Spark��Ⱥ���н����Ľӿ�,Hive on SparkӦ��Ϊÿ���û��ĻỰ����һ��SparkContext������SparkĿǰ��ʹ�÷�ʽ����SparkContext������������SparkӦ �ü����,����Ŀǰ��ͬһ��JVM�в��ܴ������SparkContext��������������HiveServer2��Ӧ�ó���,��Ϊ����ͻ�����Ҫͨ��ͬһ��HiveServer2���ṩ�����ڴ�,������Ҫ�ڵ�����JVM������SparkContext,��ͨ��RPC��Զ�̵�SparkContext����ͨ�š�
��������ͳ����Ϣ�ռ�
Spark�ṩ��SparkListener�ӿ�����������ִ���ڼ�ĸ����¼�,������ǿ���ʵ��һ��Listener���������ִ�н����Լ��ռ������ͳ���� Ϣ(Ŀǰ�����ͳ����SparkListener�ɼ�,�����������Spark�ṩ��ר�ŵ�API�����)������Hive���ṩ��Operator�� ���ͳ��������Ϣ,�����ȡ�������ȡ���MapReduceģʽ��,��Щ��Ϣͨ��Hadoop Counter�ռ������ǿ���ʹ��Spark�ṩ��Accumulator��ʵ�ָù��ܡ�
ϸ��ʵ��
Hive on Spark����SQL����
SQL����ڷ���ִ�й����лᾭ����ͼ��ʾ�ļ�������
-
�����
-
������
-
�Ż�ִ�в���
-
����ִ��
�����
�����֮��,���γ�һ�����,����ͼ��ʾ�����е�ÿ���ڵ���ִ�е�rule,��������֮Ϊִ�в��ԡ�
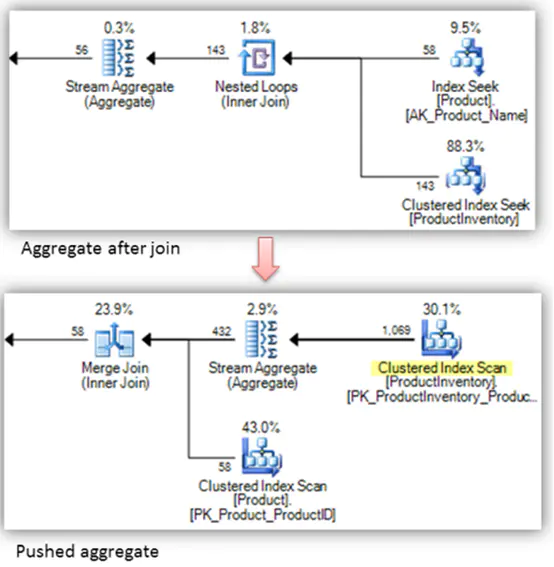
�����Ż�
�γ�������ִ�в�������ֻ�ǵ�һ��,��Ϊ���ִ�в��Կ��Խ����Ż�,��ν���Ż����Ƕ����нڵ���кϲ����ǽ���˳���ϵĵ�����
�Դ����Ϥ��join����Ϊ��,��ͼ����һ��join�Ż���ʾ����A JOIN B��ͬ��B JOIN A,����˳��ĵ������ܸ�ִ�е����ܴ��������Ӱ��,��ͼ���ǵ���ǰ��ĶԱ�ͼ��
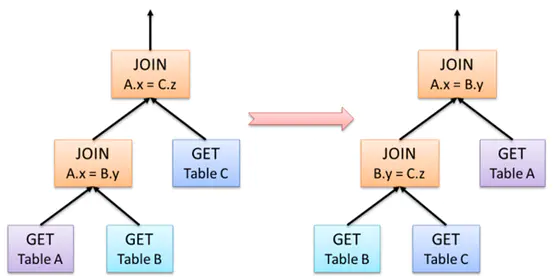
��Hash Join��,���ȱ����ʵı���֮Ϊ���ڲ���������,�ڶ�����Ϊ��̽�����롱�������ڲ���ʱ,�Ὣ�����ƶ������ݲֿ�ָ���·��;�����ⲿ��,����¼�������ڵ�·����
�پ�һ��,һ����˵�����ܵ���ʵʩ�ۺϲ���(Aggregate)Ȼ����join
�����Ż��Զ����,�ڵ���ʱ����Ҫ���ǡ�
SQL��Spark��ҵ��ת������
-
native command��ִ������
����native command��һЩ�Ǻ�ʱ�IJ���,ֱ��ʹ��Hive��ԭ�е�exeucte engine��ִ�м��ɡ���Щcommand��ִ��ʾ��ͼ����:

-
SparkTask�����ɺ�ִ��
����ͨ��һ����������һ��һ��������JOIN��ѯ��α�ת��ΪSparkTask����ִ�С���ͼ��벿��չʾ�������ѯ��Operator Tree,�Լ���Operator Tree��α�ת����SparkTask;�Ұ벿��չʾ�˸�SparkTaskִ��ʱ��εõ����յ�RDD��ͨ��foreachAsync�ύSpark����
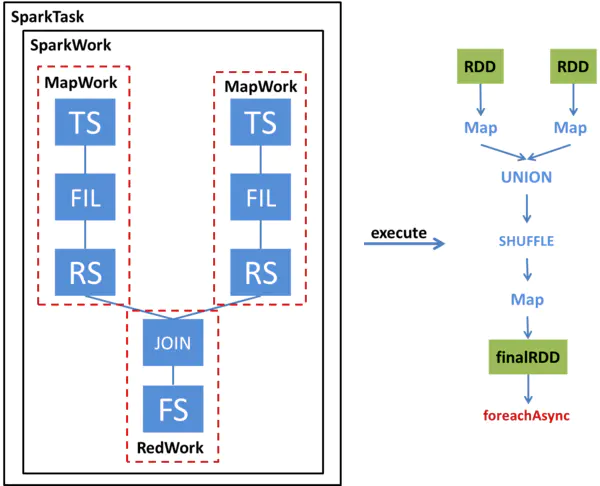
SparkCompiler����Operator Tree,���仮��Ϊ��ͬ��MapWork��ReduceWork��
MapWorkΪ���ڵ�,������TableScanOperator(Hive�жԱ�����ɨ��IJ�����)��ʼ;������Work��ΪReduceWork��ReduceSinkOperator(Hive�н���Shuffle����IJ�����)�����������Work֮��Ľ���,����ReduceSinkOperator��ʾ��ǰWork����һ��Work֮���������Ҫ����Shuffle�����,�����Ƿ���ReduceSinkOperatorʱ,�ͻᴴ��һ���µ�ReduceWork����Ϊ��ǰWork���ӽڵ㡣������FileSinkOperator(Hive�н����������ļ��IJ�����)��WorkΪҶ�ӽڵ㡣
��MapReduce���IJ�ͬ����,���Dz���Ҫ��ReduceWorkһ����Ҷ�ӽڵ�,��ReduceWork֮��������Ӹ����ReduceWork,����ͬһ��SparkTask��ִ�С�
�Ӹ�ͼ���Կ���,�����ѯ��Operator Tree��ת����������MapWork��һ��ReduceWork��
ִ��SparkTask����:
-
����MapWork��������ײ��HadoopRDD,
-
������MapWork��ReduceWork��װ��FunctionӦ�õ�RDD�ϡ�
-
����������Work֮��,��Ҫ��ʽ�ص���Shuffleת��,����ѡ������Shuffle��Ҫ���ݲ�ѯ��������ȷ��������,������������漰�����ѯ,�����Shuffle֮ǰ��Ҫ��RDD����Union��
-
������һϵ��ת����,�õ����յ�RDD,��ͨ��foreachAsync�ύ��Spark��Ⱥ�Ͻ��м��㡣
��logicalPlan��physicalPlan��ת��������,toRdd��ؼ���Ԫ��
override?lazy?val?toRdd:?RDD[Row]?=
??????analyzed?match?{
????????case?NativeCommand(cmd)?=>
??????????val?output?=?runSqlHive(cmd)
??????????if?(output.size?==?0)?{
????????????emptyResult
??????????}?else?{
????????????val?asRows?=?output.map(r?=>?new?GenericRow(r.split("\t").asInstanceOf[Array[Any]]))
????????????sparkContext.parallelize(asRows,?1)
??????????}
????????case?_?=>
??????????executedPlan.execute().map(_.copy())
??????}
SparkTask�����ɺ�ִ��
����ͨ��һ����������һ��һ��������JOIN��ѯ��α�ת��ΪSparkTask����ִ�С���ͼ��벿��չʾ�������ѯ��Operator Tree,�Լ���Operator Tree��α�ת����SparkTask;�Ұ벿��չʾ�˸�SparkTaskִ��ʱ��εõ����յ�RDD��ͨ��foreachAsync�ύSpark����
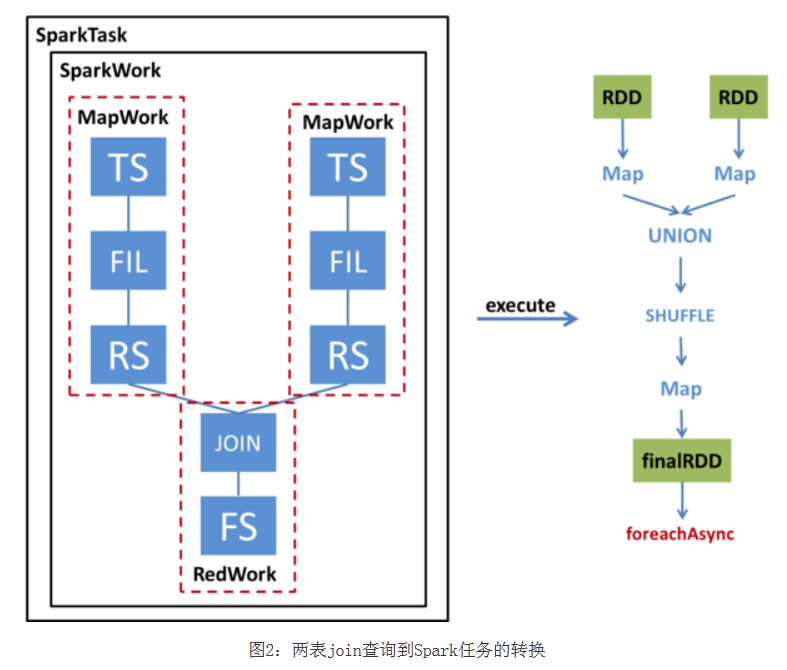
SparkCompiler����Operator Tree,���仮��Ϊ��ͬ��MapWork��ReduceWork��MapWorkΪ���ڵ�,������TableScanOperator(Hive�жԱ� ����ɨ��IJ�����)��ʼ;������Work��ΪReduceWork��ReduceSinkOperator(Hive�н���Shuffle����IJ�����) �����������Work֮��Ľ���,����ReduceSinkOperator��ʾ��ǰWork����һ��Work֮���������Ҫ����Shuffle�����, �����Ƿ���ReduceSinkOperatorʱ,�ͻᴴ��һ���µ�ReduceWork����Ϊ��ǰWork���ӽڵ㡣������ FileSinkOperator(Hive�н����������ļ��IJ�����)��WorkΪҶ�ӽڵ㡣��MapReduce���IJ�ͬ����,���Dz���Ҫ�� ReduceWorkһ����Ҷ�ӽڵ�,��ReduceWork֮��������Ӹ����ReduceWork,����ͬһ��SparkTask��ִ�С�
�Ӹ�ͼ���Կ���,�����ѯ��Operator Tree��ת����������MapWork��һ��ReduceWork����ִ��SparkTaskʱ,���ȸ���MapWork��������ײ�� HadoopRDD,Ȼ����MapWork��ReduceWork��װ��FunctionӦ�õ�RDD�ϡ�����������Work֮��,��Ҫ��ʽ�ص��� Shuffleת��,����ѡ������Shuffle��Ҫ���ݲ�ѯ��������ȷ��������,������������漰�����ѯ,�����Shuffle֮ǰ��Ҫ��RDD���� Union��������һϵ��ת����,�õ����յ�RDD,��ͨ��foreachAsync�ύ��Spark��Ⱥ�Ͻ��м��㡣
����ģʽ
Hive on Spark֧����������ģʽ:���غ�Զ�̡����û���Spark Master URL����Ϊlocalʱ,���ñ���ģʽ;������������Զ��ģʽ������ģʽ��,SparkContext��ͻ���������ͬһ��JVM��;Զ��ģʽ ��,SparkContext������һ��������JVM�С��ṩ����ģʽ��Ҫ��Ϊ�˷������,һ���û���Ӧѡ���ģʽ�������������Ҳ��Ҫ����Զ��ģʽ (Remote SparkContext,RSC)����ͼչʾ��RSC�Ĺ���ԭ����
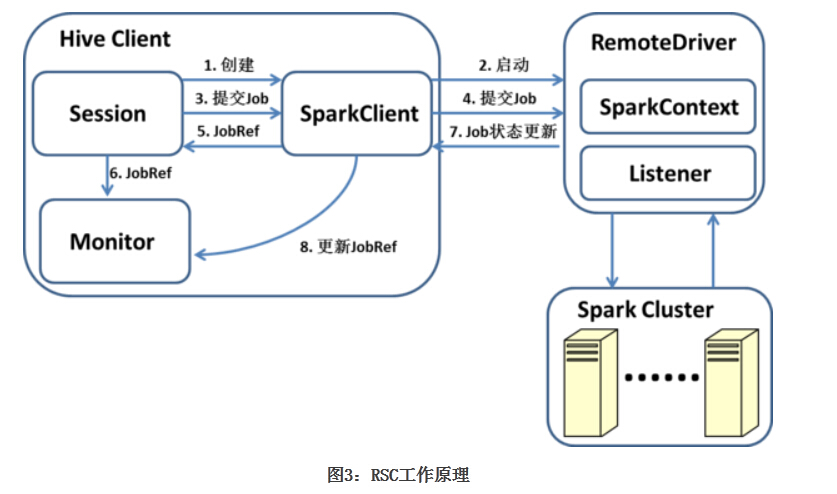
�û���ÿ��Session�ᴴ��һ��SparkClient,SparkClient������RemoteDriver����,����RemoteDriver�� ��SparkContext��SparkTaskִ��ʱ,ͨ��Session�ύ����,�����������Ƕ�Ӧ��SparkWork��SparkClient �������ύ��RemoteDriver,������һ��SparkJobRef,ͨ����SparkJobRef,�ͻ��˿��Լ������ִ�н���,���д�����, �Լ��ɼ�ͳ����Ϣ�ȡ��������յ�RDD����û�з��ؽ��,��˿ͻ���ֻ��Ҫ���ִ�н��ȶ�����Ҫ��������ֵ��RemoteDriverͨ�� SparkListener�ռ������ͳ������,ͨ��Accumulator�ռ�Operator�����ͳ������(Accumulator����װΪ SparkCounter),�����������ʱ���ظ�SparkClient��
SparkClient ��RemoteDriver֮��ͨ������Netty��RPC����ͨ�š������ύ����,SparkClient���ṩ����������Jar������ȡ��Ⱥ��Ϣ�Ƚ� �ڡ�����ͻ�����Ҫʹ�ø�һ���SparkContext�Ĺ���,�����Զ���һ������ͨ��SparkClient���͵�RemoteDriver��ִ �С�
��������˵,Hive on Spark����Spark��Ⱥ�IJ���ʽû���ر��Ҫ��,����local����,RemoteDriver�������ӵ������Spark��Ⱥ��ִ���������� �ǵIJ�����,Hive on Spark��Standalone��Spark on YARN�ļ�Ⱥ�϶�����������(��Ҫ��̬����Jar���IJ�ѯ��yarn-clusterģʽ�»���������,��ο�HIVE-9425)��
�Ż�
Yarn������
yarn.nodemanager.resource.cpu-vcores��yarn.nodemanager.resource.memory-mb,���������������⼯Ⱥ��Դ�������ܹ��ж�����Դ��������yarn�ϵ����� ������������ֵ���ɻ��������ü�ͬʱ�ڻ��������е��������̹�ͬ���������ļ������hdfs��datanode��yarn��nodemanager�����ڸýڵ㡣
-
����cores
����������datanode��nodemanager��һ����,����ϵͳ������,Ȼ��ʣ��28��������Ϊyarn��Դ��Ҳ����yarn.nodemanager.resource.cpu-vcores=28
-
�����ڴ�
�����ڴ�,Ԥ��20GB������ϵͳ,datanode,nodemanager,ʣ��100GB��Ϊyarn��Դ��Ҳ���� yarn.nodemanager.resource.memory-mb=100*1024
Spark����
����Yarn�ڵ��������,������32��,120GB�ڴ档
��Yarn������Դ�Ժ�,�Ǿ�Ҫ����spark���ʹ����Щ��Դ��,��Ҫ���ö���:
execurtor ��driver�ڴ�,executro���,���жȡ�
-
executor�ڴ�
����executor�ڴ���Ҫ������������:
-
executor�ڴ�Խ��,Խ��Ϊ����IJ�ѯ�ṩmap join���Ż��������������յ�ѹ���ᵼ�¿������ӡ�
-
ijЩ�����hdfs�Ŀͻ��˲��ܺܺõĴ�������д��,���Թ���ĺ��Ŀ��ܻᵼ�¾�����
Ϊ�����ʹ��core,���齫core����Ϊ4,5,6(����Ļᵼ�²�������,����д�����ʱ�������Ǿ�̬�����ӵ�Ҫ���Dz�������)������������Ҫ���yarn���ṩ�ĺ������� ���ڱ������漰����node�ڵ���28��,��ô�����Է���Ϊ4�Ļ����Ա�����,spark.executor.cores����Ϊ4 �����ж���ĺ�ʣ��,����Ϊ5,6������coreʣ�ࡣ spark.executor.cores=4,�����ܹ���28����,��ô�����������executor����7�����ڴ洦��7,Ҳ���� 100/7,���Եõ�ÿ��executorԼ14GB�ڴ档
Ҫ֪�� spark.executor.memory ��spark.executor.memoryOverhead��ͬ������executor�ڴ档����spark.executor.memoryOverheadվ���ڴ�� 15%-20%�� ��ô����spark.executor.memoryOverhead=2G��spark.executor.memory=12G.
������������õĻ�,ÿ�������Ϳ�������7��executor,ÿ��executor��������4������,ÿ��coreһ��task����ôÿ��task��ƽ���ڴ��� 14/4 = 3.5GB����executor���е�task�����ڴ档 ��ʵ,executor�ڲ�����newCachedThreadPool����task�ġ�
ȷ��spark.executor.memoryOverhead��spark.executor.memory�ĺͲ�����yarn.scheduler.maximum-allocation-mb��
-
driver�ڴ�
����drvier���ڴ�����,��ȻҲ��������������
-
spark.driver.memoryOverhead ÿ��driver�ܴ�yarn����Ķ����ڴ�Ĵ�С��
-
spark.driver.memory ������hive on spark��ʱ��,ÿ��spark driver����������jvm ���ڴ档�ò������ spark.driver.memoryOverhead��ͬ������driver���ڴ��С��
driver���ڴ��С����ֱ��Ӱ������,����Ҳ��Ҫjob������������driver���ڴ�. �������spark driver�ڴ�����ķ���,����yarn.nodemanager.resource.memory-mb�� X��
-
driver�ڴ�����12GB,���� X > 50GB
-
driver�ڴ����� 4GB,���� 12GB < X <50GB
-
driver�ڴ�����1GB,���� 1GB < X < 12 GB
-
driver�ڴ�����256MB,���� X < 1GB
��Щ��ֵ��spark.driver.memory�� spark.driver.memoryOverhead�ڴ���ܺ͡������ڴ�վ���ڴ��10%-15%�� ���� yarn.nodemanager.resource.memory-mb=100*1024MB,��ôdriver�ڴ�����Ϊ12GB,��ʱ spark.driver.memory=10.5gb��spark.driver.memoryOverhead=1.5gb
ע��,��Դ����ֱ�Ӷ�Ӧ�����������Ĵ�С������Ҫ�����Դ�������������ʵ����������ӡ�
-
executor��
executor����Ŀ����ÿ���ڵ����е�executor��Ŀ�ͼ�Ⱥ�Ľڵ�����ͬ���������������ʮ���ڵ�,��ôhive����ʹ�õ����executor������ 280(40*7). �����Ŀ���ܱ����С��,��ΪdriverҲ������1core��12GB��
��ǰ������û��yarnӦ�����ܡ�
Hive�������������в�ѯ��executor����ֱ����ء� ����,��ͨ��ѯ���Dz�ͨ�� ͨ��,������executor�������ɱ����� ����,��ѯʹ���ĸ�executor��Լ��Ҫʹ������executor��һ��ʱ�䡣 ����,������һ��������executor�дﵽ��ֵ,���ڴ�ֵʱ,������������������ܲ��ҿ��ܲ�������Ӱ�졣
�ڴ���������,ʹ��һ��ļ�Ⱥ����(executor������һ��)�����ṩ���õ����ܡ� Ϊ�˻���������,���ʹ�����п��õ�executor�� ����,����spark.executor.instances = 280�� ���ڻ����Ժ����ܲ���,ǿ�ҽ�����������
-
��̬executor����
��Ȼ��spark.executor.instances����Ϊ���ֵͨ����������ȵ��������,���������ڶ���û�����Hive��ѯ�������������������� ����Ϊ�û��Ự����̶�������executor,��Ϊ���executor����,executor���ܱ������û���ѯʹ�á� ������������,Ӧ�úúüƻ�executor����,�������������Դ������
Spark���������ݹ������ض�̬��չ�����SparkӦ�ó���ļ�Ⱥ��Դ���� Ҫ���ö�̬����,�밴�ն�̬�����еIJ�����в����� ������ijЩ�����,ǿ�ҽ������ö�̬���䡣
-
���ж�
Ҫʹ���õ�executor�õ��������,����ͬʱ�����㹻������(����)���ڴ���������,Hive���Զ�ȷ�����ж�,��Ҳ�����ڵ��Ų����ȷ�����һЩ����Ȩ�� �������,map������������������ʽ���ɵ�split��������Hive on Spark,�����ʽΪCombineHiveInputFormat,�����Ը�����Ҫ�Ի��������ʽ���ɵ�split���з��顣 ���Ը��õؿ���stage�߽�IJ��жȡ�����hive.exec.reducers.bytes.per.reducer�Կ���ÿ��reducer������������,Hive���ݿ��õ�executor,ִ�г����ڴ�,�Լ�����������ȷ����ѷ������� ʵ�����,ֻҪ�����㹻���������������п��õ�executor��æ,Spark�ͱ�MapReduce��hive.exec.reducers.bytes.per.reducerָ����ֵ���жȵ͡� Ϊ����������,��Ϊ������ѡ��һ��ֵ,�Ա�Hive�����㹻����������ȫʹ�����п��õ�executor��
Hive����
Hive on spark �����˺ܶ�hive������ص����á����������hive on mapreduceһ������hive on spark�� Ȼ��,hive.auto.convert.join.noconditionaltask.size�ǻ���ͳ����Ϣ������joinת��Ϊmap join����ֵ,���ܻ�����ܲ����ش�Ӱ�졣 ���ܸ����ÿ�����hive on mr��hive on spark,�������ߵĽ��Ͳ�ͬ��
���ݵĴ�С������ͳ��ָ��:
-
totalSize- �����ڴ����ϵĽ��ƴ�С
-
rawDataSize- �������ڴ��еĽ��ƴ�С
hive on mr�õ���totalSize��hive on sparkʹ�õ���rawDataSize�����ڿ��ܴ���ѹ�������л�,������ֵ���нϴ�IJ�� ����hive on spark ��Ҫ�� hive.auto.convert.join.noconditionaltask.sizeָ��Ϊ�����ֵ,���ܽ���hive on mr��ͬ��joinת��Ϊmap join��
�������Ӵ˲�����ֵ,��ʹ��ͼ����ת���������͡� ��common join ת��Ϊ map join ����������ܡ� �����ֵ���õ�̫��,������С�������ݽ�ʹ�ù����ڴ�,������ܻ����ڴ治���ʧ�ܡ� ����Ⱥ������������ֵ��
ͨ������ hive.stats.collect.rawdatasize ���Կ����Ƿ��ռ� rawDataSize ͳ����Ϣ��
����hiveserver2,������������������IJ���: hive.stats.fetch.column.stats=true �� hive.optimize.index.filter=true.
Hive���ܵ���ͨ������ʹ����������:
hive.optimize.reducededuplication.min.reducer=4
hive.optimize.reducededuplication=true
hive.merge.mapfiles=true
hive.merge.mapredfiles=false
hive.merge.smallfiles.avgsize=16000000
hive.merge.size.per.task=256000000
hive.merge.sparkfiles=true
hive.auto.convert.join=true
hive.auto.convert.join.noconditionaltask=true
hive.auto.convert.join.noconditionaltask.size=20M(might?need?to?increase?for?Spark,?200M)
hive.optimize.bucketmapjoin.sortedmerge=false
hive.map.aggr.hash.percentmemory=0.5
hive.map.aggr=true
hive.optimize.sort.dynamic.partition=false
hive.stats.autogather=true
hive.stats.fetch.column.stats=true
hive.compute.query.using.stats=true
hive.limit.pushdown.memory.usage=0.4?(MR?and?Spark)
hive.optimize.index.filter=true
hive.exec.reducers.bytes.per.reducer=67108864
hive.smbjoin.cache.rows=10000
hive.fetch.task.conversion=more
hive.fetch.task.conversion.threshold=1073741824
hive.optimize.ppd=true
Ԥ����YARN����
�ڿ�ʼ�»Ự���ύ��һ����ѯʱ,�ڲ鿴��ѯ��ʼ֮ǰ���ܻ������Գ����ӳ١�����ע�,����ٴ�������ͬ�IJ�ѯ,��������ٶȱȵ�һ����öࡣ
Sparkִ�г�����Ҫ�����ʱ���������ͳ�ʼ��yarn�ϵ�Spark,��ᵼ�½ϳ����ӳ١�����,Spark����ȴ�����executor��������ҵ֮ǰȫ���������,����ڽ���ҵ�ύ��Ⱥ����,ijЩexecutor�������������� ����,������Spark�����е���ҵ,��ҵ�ύʱ����executor���������־�����reducer��������������executor������δ�ﵽ���ֵʱ,��ҵ����û������жȡ�����ܻ��һ��Ӱ���һ����ѯ�����ܡ�
���û��ϳ��ڻỰ��,�������ʱ�䲻�ᵼ���κ�����,��Ϊ��ֻ�ڵ�һ�β�ѯִ��ʱ������Ȼ��,����Oozie�����Hive����֮��Ķ��ڻ滭������ʵ��������ܡ�
Ϊ��������ʱ��,��������ҵ��ʼǰ��������Ԥ�ȡ�ֻ���������executor������ʱ,��ҵ�ŻῪʼ���С�����,��reduce��һ�����ٶ̻Ự�IJ����ԡ�
Ҫ����Ԥ�ȹ���,���ڷ�����ѯ֮ǰ��hive.prewarm.enabled����Ϊtrue��������ͨ������hive.prewarm.numcontainers����������������Ĭ��ֵΪ10��
Ԥ�ȵ�executor��ʵ��������spark.executor.instances(��̬����)��spark.dynamicAllocation.maxExecutors(��̬����)��ֵ���ơ� hive.prewarm.numcontainers��ֵ��Ӧ����������û��Ự��ֵ��
ע��:Ԥ����Ҫ������,���ڶ̻Ự��˵��һ���ܺõ�����,�ر��������ѯ�漰reduce�Ρ� ����,���hive.prewarm.numcontainers��ֵ����Ⱥ���п��õ�ֵ,��ù�����������Ҫ30�롣�����ʹ��Ԥ�ȡ�
����,һ���������Ű�������Բο�: https://blog.csdn.net/u010010664/article/details/77066031