提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
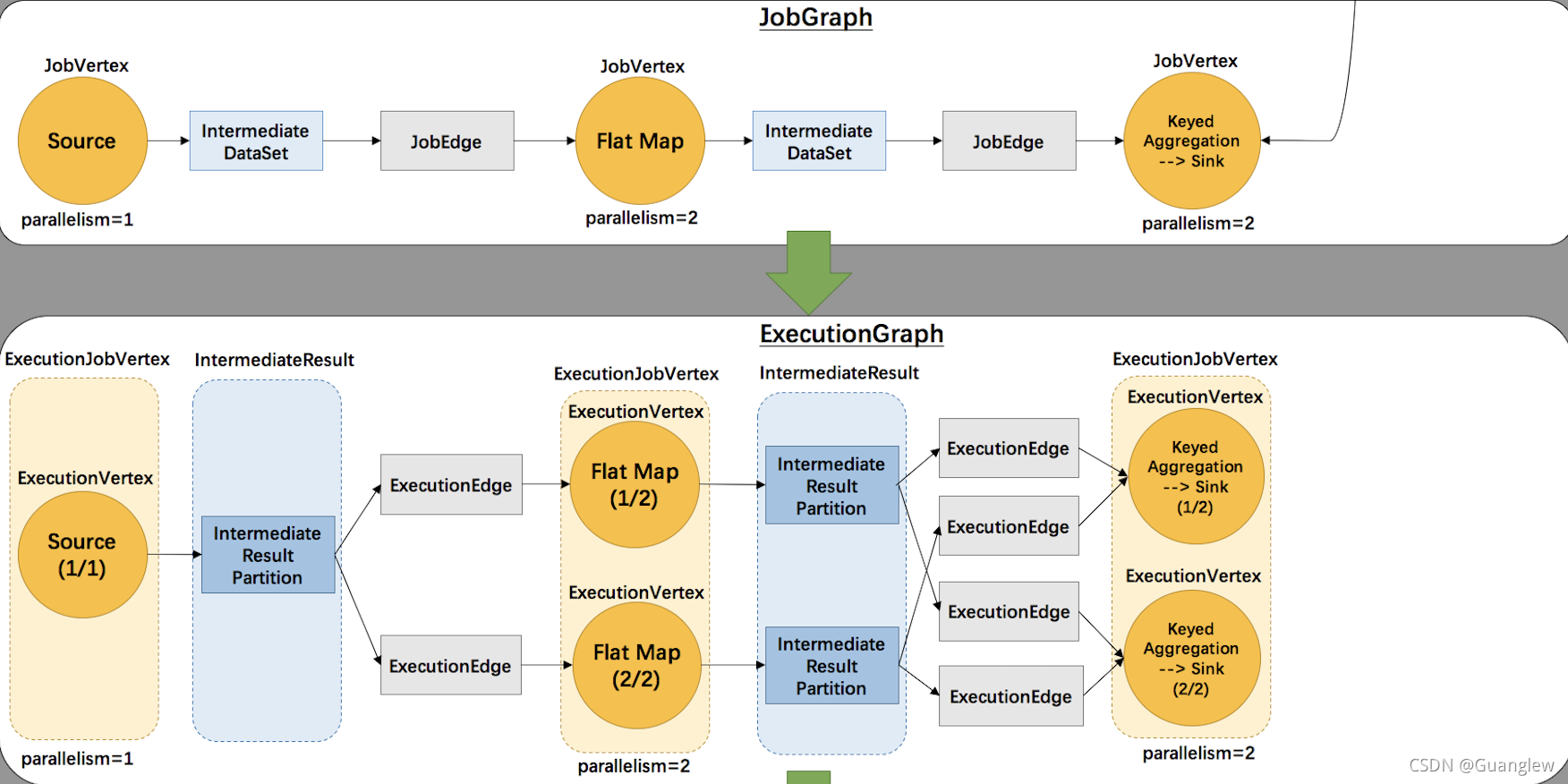
主要的变化如下:
- JobVertex 变成了 ExecutionJobVertex,且 ExecutionJobVertex 根据并行度被分解为一个/多个 ExecutionVertex
- Intermediate DataSet 被转化为 Intermediate Result,且根据并行度被分解为 一个/多个 IntermediateResultPartition
- JobEdge 变成了 ExecutionEdge // 思考:ExecutionEdge的并行度/个数由什么决定呢?・
提示:以下是本篇文章正文内容,下面案例可供参考
一、ExecutionGraph的详细构成
这次我们直接找到方法:createAndRestoreExecutionGraph 的使用。(因为这次一路点点点没找到)
 ?
?
ExecutionJobVertex
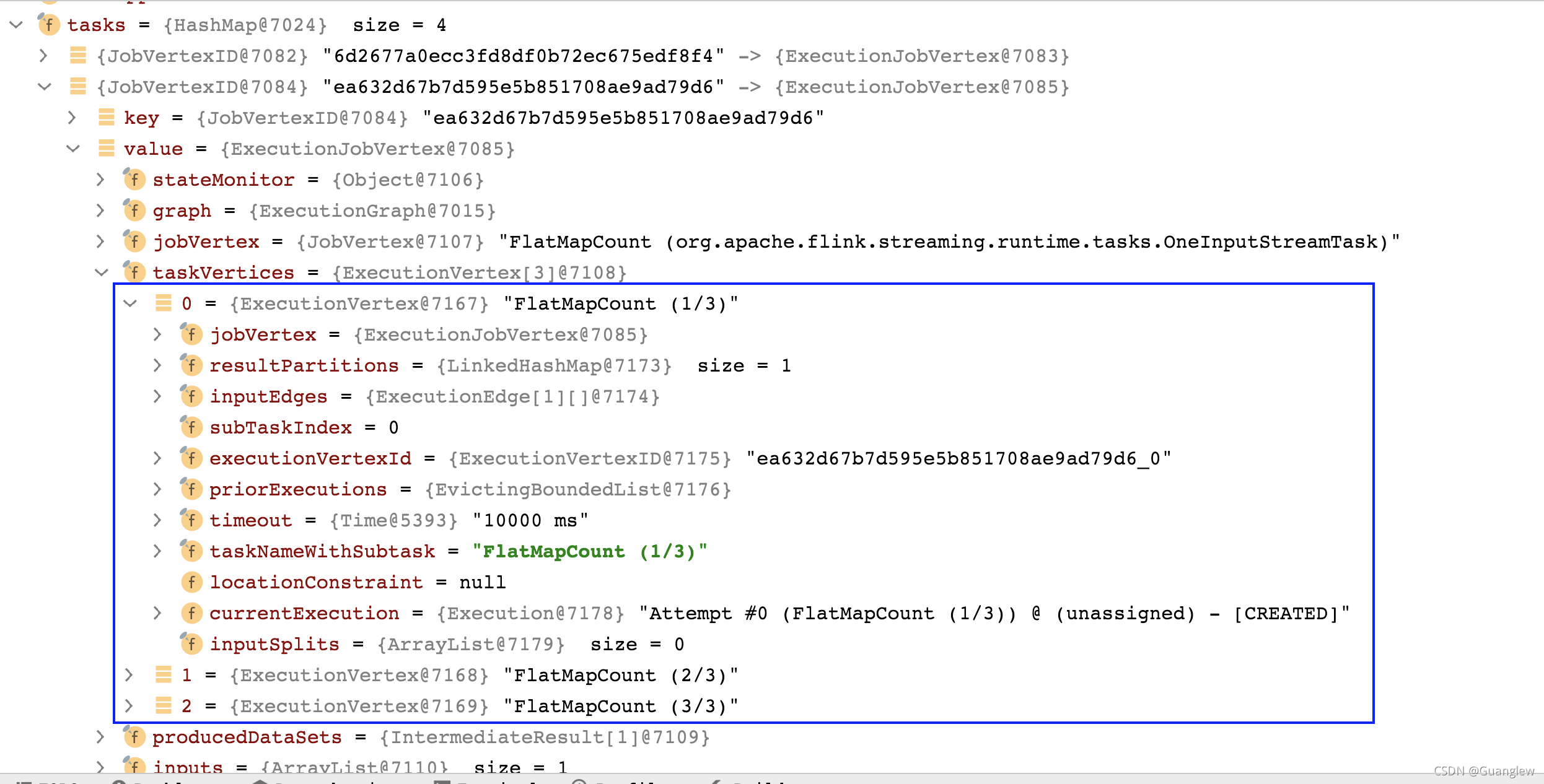
?里面有一个?ExecutionVertex 类型的数组,数组的长度就是该算子(ExecutionJobVertex)的并行度。
IntermediateResult
 ??
??
思考:IntermediateResult的并行度由什么决定??
?
二、ExecutionGraph是如何生成的?
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。