实验要求
Java?API实现HDFS以下功能。
1.????在HDFS中创建一个新目录;
2.????从本地拷贝文件到新创建的目录中;
3.????将HDFS中指定文件的内容输出到终端中;
4.????显示一个指定目录下所有文件;
5.????完成指定目录下指定类型文件的合并
6.????在HDFS中,将文件从源路径移动到目的路径。
7.????删除HDFS中指定的文件;
实验环境
操作系统:Linux
Hadoop版本:2.7.0或以上版本
JDK版本:1.8或以上版本
Java IDE:IDEA
项目文件结构
?代码
1.????在HDFS中创建一个新目录
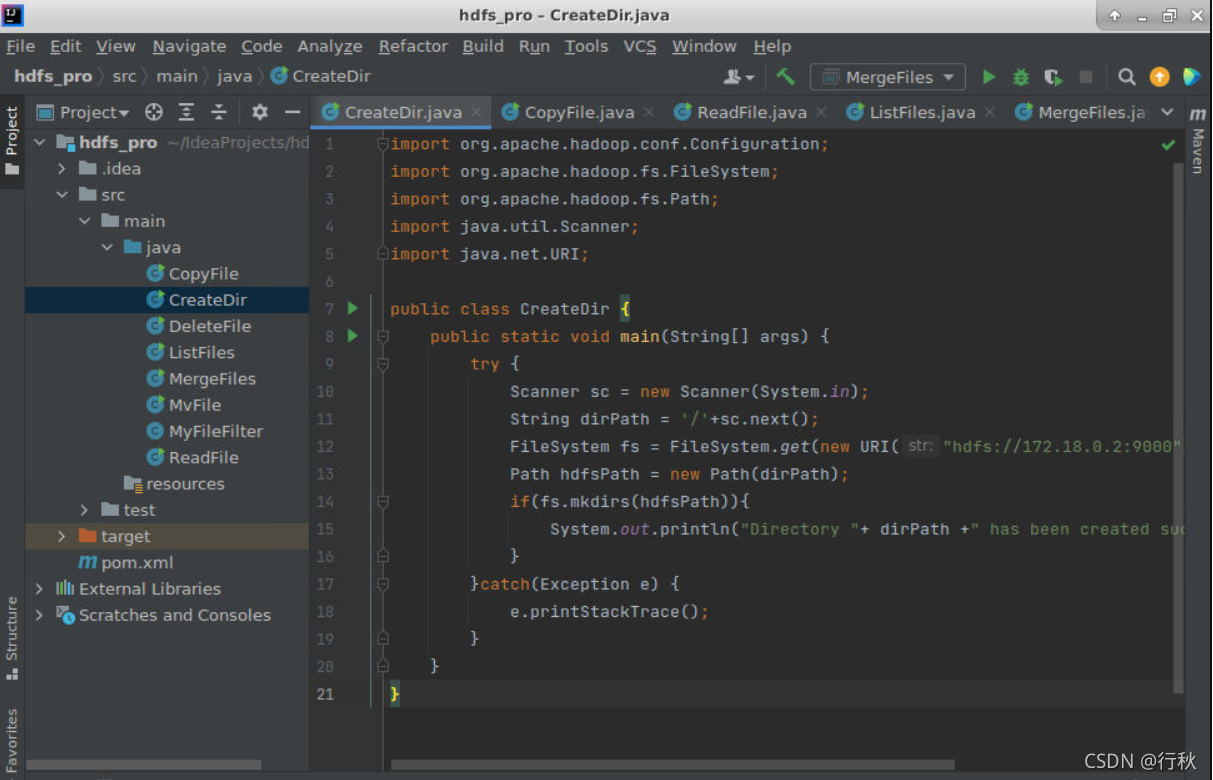
新建Java class命名为 CreateDir
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.util.Scanner;
import java.net.URI;
public class CreateDir {
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
String dirPath = '/'+sc.next();
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path hdfsPath = new Path(dirPath);
if(fs.mkdirs(hdfsPath)){
System.out.println("Directory "+ dirPath +" has been created successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
}
}运行截图:
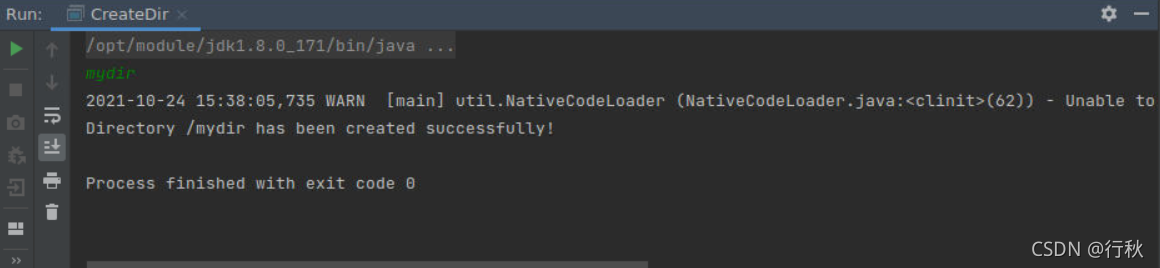
??终端上进行Hadoop检测
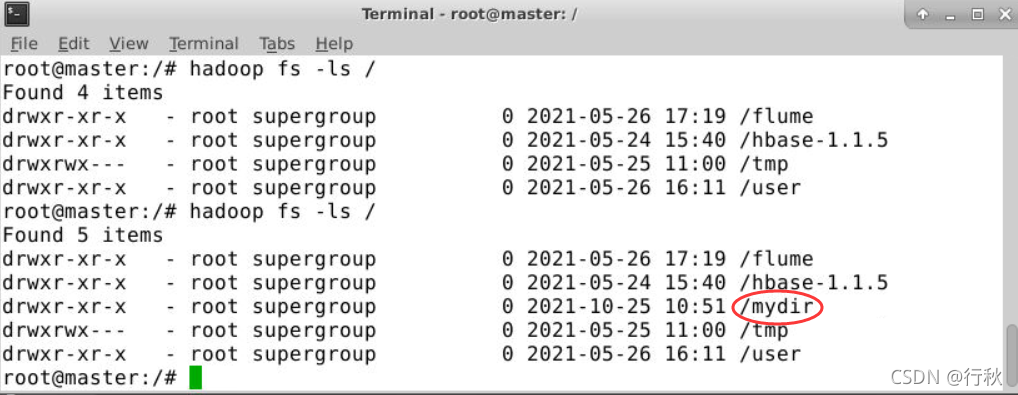
?2.????从本地拷贝文件到新创建的目录中
新建Java class命名为 CopyFile
import java.net.URI;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String args[]) throws Exception {
System.out.println("Input the filepath:");
Scanner sc = new Scanner(System.in);
Path src=new Path(sc.next());
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path dst =new Path("/mydir");
fs.copyFromLocalFile(src, dst);
}
}运行结果
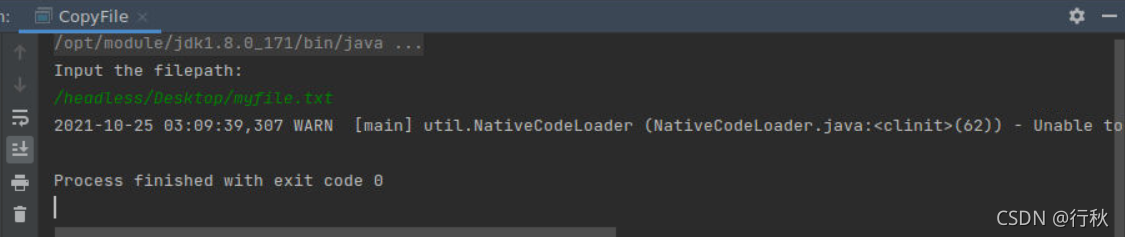
终端上进行Hadoop检测

3.????将HDFS中指定文件的内容输出到终端中
新建Java class命名为 ReadFile
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.Scanner;
public class ReadFile {
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
String filePath = '/'+sc.next();
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path srcPath = new Path(filePath);
FSDataInputStream is = fs.open(srcPath);
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}运行结果
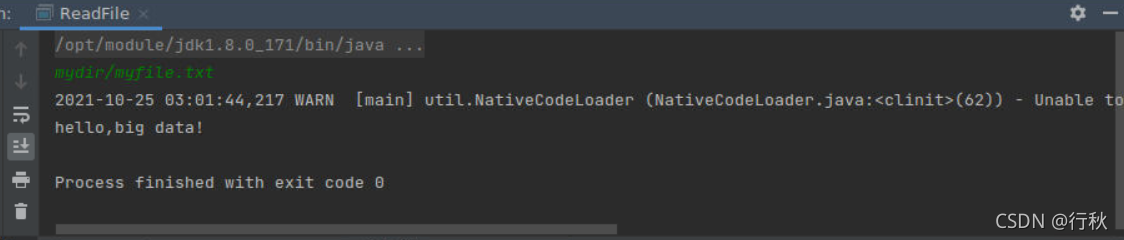
终端上进行Hadoop检测

这里为了第4,5问达到更好看的效果,Hadoop下面的mydir目录中,又上传了yourfile.txt文件,内容为“goodbye,big data!"。和herfile文件,内容是“big data is good!”如图:

?4.????显示一个指定目录下所有文件
新建Java class命名为 ListFile
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.Scanner;
public class ListFiles {
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
String filePath = sc.next();
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path srcPath = new Path(filePath);
FileStatus[] stats = fs.listStatus(srcPath);
Path[] paths = FileUtil.stat2Paths(stats);
for(Path p : paths)
System.out.println(p.getName());
}catch(Exception e) {
e.printStackTrace();
}
}
}运行结果
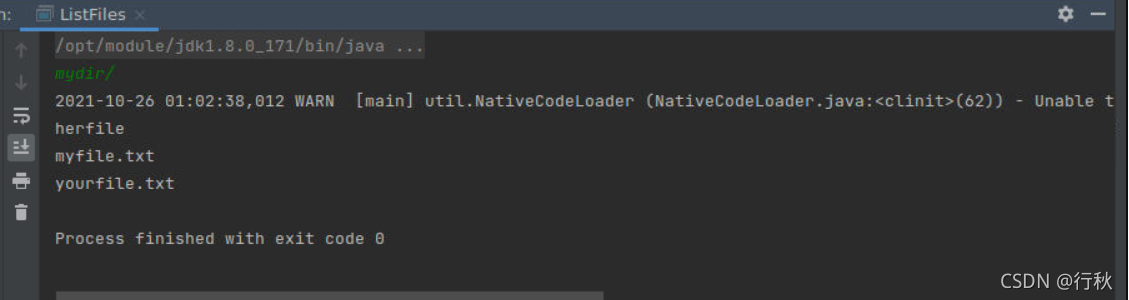
终端上进行Hadoop检测

5.????完成指定目录下指定类型文件的合并
新建Java class命名为 MergeFiles,MyFileFilter
(本人对此处的“合并”,理解为“内容合并”,即将指定目录下的同类型文件内容写进一个文件。比如mydir目录下有三个文件myfile.txt、yourfile.txt、herfile,需过滤掉herfile文件,将两个文本文件myfile.txt、yourfile.txt内容写入一个文件mergeNew.txt,进行“合并”。)
注:通过自定义过滤函数实现指定类型功能。
MyFileFilter代码
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
class MyFileFilter implements PathFilter {
String reg = null;
MyFileFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if( (path.toString().matches(reg)) ) {
return true;
}
return false;
}
}?MergeFiles代码
import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
public class MergeFiles{
Path inputPath = null;//待合并文件所在目录的路径
Path outputPath = null;//输出文件的路径
public MergeFiles(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
//org.apache.hadoop.conf.Configuration 即访问配置项。
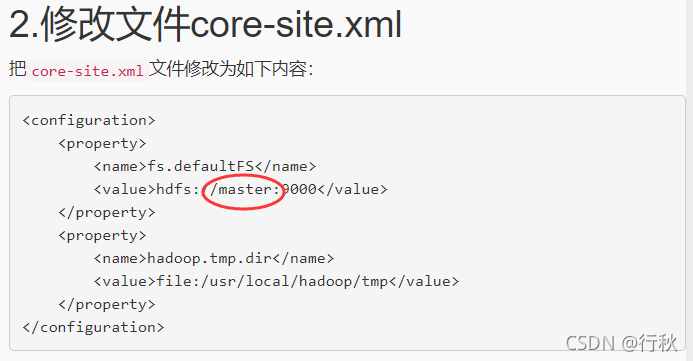
//所有的配置项的值,如果在core-site.xml中有对应的配置,则以core-site.xml为准。
conf.set("fs.defaultFS", "hdfs://172.18.0.2:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过找到输入目录中后缀为.txt的文件,需自写过滤函数MyPathFilter
FileStatus[] sourceStatus = fsSource.listStatus(inputPath, new MyPathFilter(“.*\\.txt”));
//org.apache.hadoop.fs.FileStatus是一个接口,用于向客户端展示系统中文件和目录的元数据,
//具体包括文件大小、块大小、副本信息、所有者、修改时间等。可通过FileSystem.listStatus()方法获得具体的实例对象。
// .*表示0个或多个任意字符 \\.构成一个转义字符,表示.
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);//文件输出流,用于写Hadoop文件
for (FileStatus sta : sourceStatus) {//分别读取过滤之后的每个文件的内容,并输出到同一个文件中
System.out.println("path:" + sta.getPath() + " file size:" + sta.getLen() +
" auth:" + sta.getPermission() + " content:");//打印后缀不为.txt的文件的路径、大小、权限、内容
FSDataInputStream fsdis = fsSource.open(sta.getPath());
//文件输入流,用于读取Hadoop文件
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}//end of for
ps.close();
fsdos.close();
}//end of doMerge()
public static void main(String[] args) throws IOException{
MergeFiles MergeFiles = new MergeFiles(
"hdfs://172.18.0.2:9000/mydir",
"hdfs://172.18.0.2:9000/mergeNew.txt"
);
MergeFiles.doMerge();
}
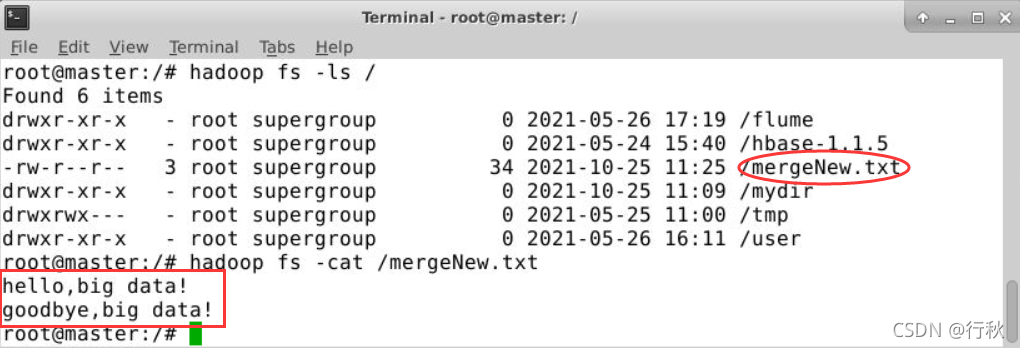
}?运行结果
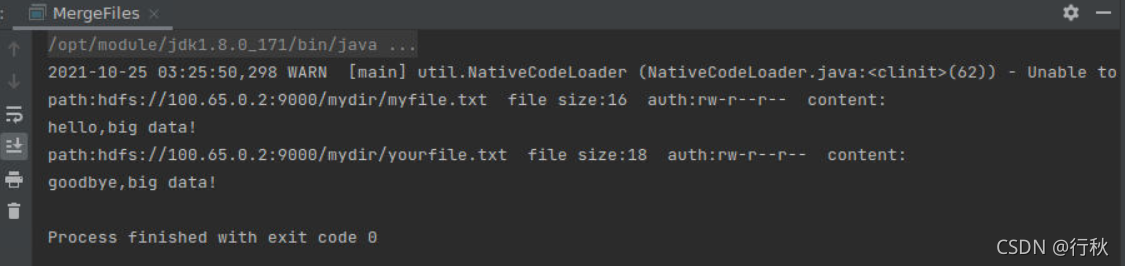
终端上进行Hadoop检测
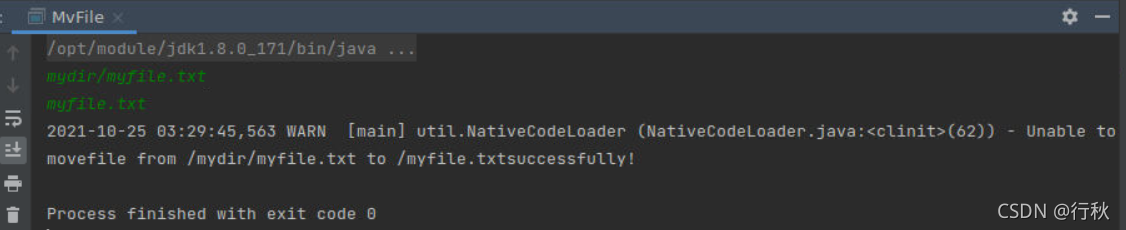
6.????在HDFS中,将文件从源路径移动到目的路径
新建Java class命名为 MvFile
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.Scanner;
public class MvFile{
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
String srcStrPath = '/'+sc.next();
String dstStrPath = '/'+sc.next();
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path srcPath = new Path(srcStrPath);
Path dstPath = new Path(dstStrPath);
if(fs.rename(srcPath,dstPath)) {
System.out.println("movefile from " + srcStrPath + " to " + dstStrPath + "successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
}
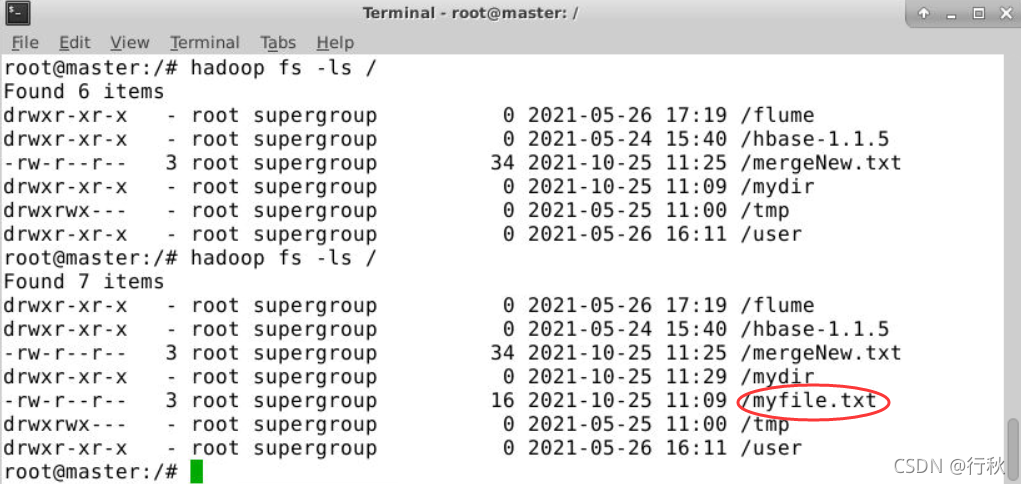
}?运行结果?
?终端上进行Hadoop检测?
?7.????删除HDFS中指定的文件
新建Java class命名为 DeleteFile
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.util.Scanner;
public class DeleteFile {
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
String filePath = '/'+sc.next();
FileSystem fs = FileSystem.get(new URI("hdfs://172.18.0.2:9000"), new Configuration());
Path hdfsPath = new Path(filePath);
if(fs.delete(hdfsPath,false)){
System.out.println("File "+ filePath +" has been deleted successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
}
}?运行结果
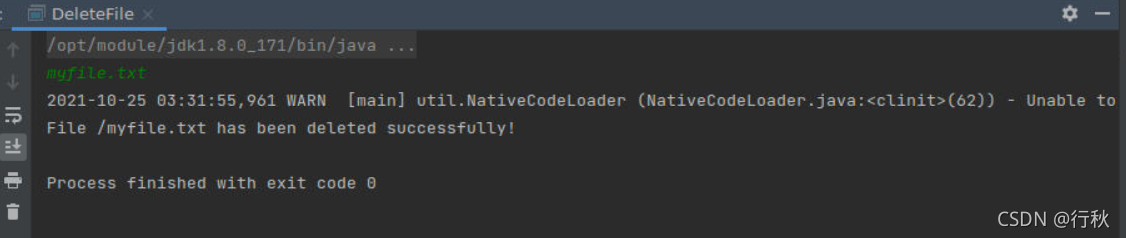
??终端上进行Hadoop检测
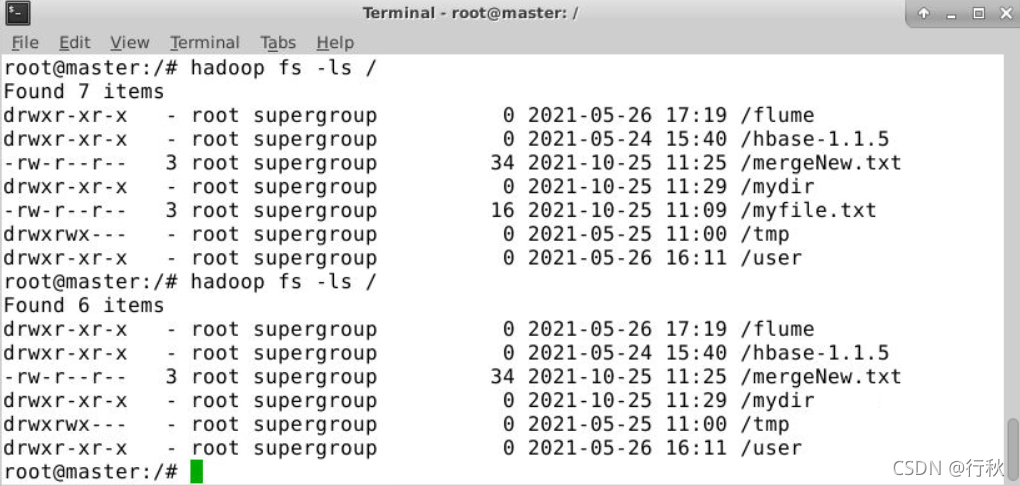
?备注
问题1
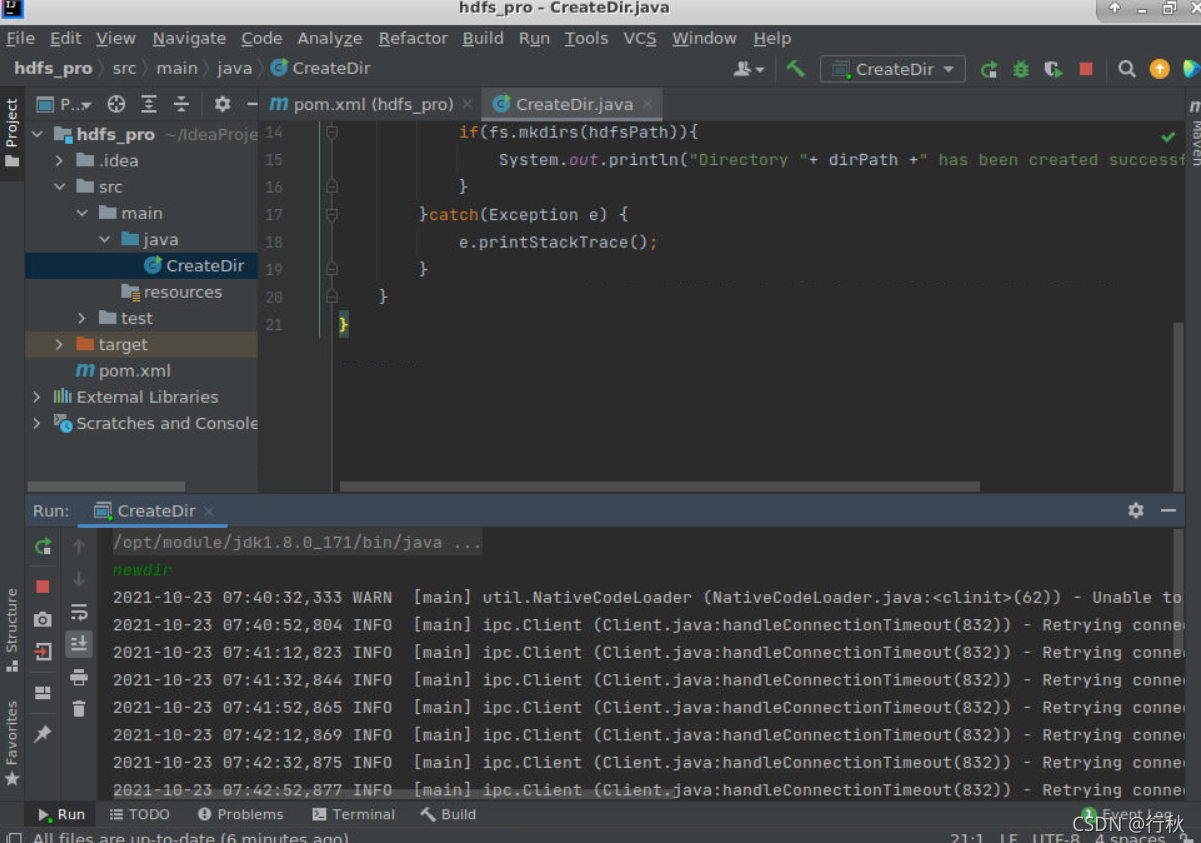
用java操作hdfs的时候会报这个错误,大概是这个原因:因为在配置Hadoop时,fs.defaultFS值使用的是节点名称,所以ip要与master节点对应。"hdfs://100.65.0.2:9000"