hadoop�������ü�α�ֲ�ʵ��
Ŀ¼
����Ŀ¼
һ������������
-
����ϵͳ��
-
��װubuntu�����
�����ַ:https://mirrors.nju.edu.cn/ubuntu-releases/18.04/ubuntu-18.04.6-desktop-amd64.iso
-
���ʹ��docker
docker pull ubuntu:18.04
-
-
��Դ
-
������ʼԴ�б�
-
sudo cp /etc/apt/sources.list /etc/apt/sources.list_backup
-
-
��Դ�б� (gedit�����Ǵ�ubuntu�ı༭��,�����docker�Ļ�,��Ҫ����vi����)
-
sudo gedit /etc/apt/sources.list
-
-
���ļ���ǰ��������������
-
# ����Դ deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
-
-
ˢ���б�
-
sudo apt-get update sudo apt-get upgrade sudo apt-get install build-essential
-
-
-
��װjava
-
ֱ������openJdk
-
sudo apt-get update sudo apt-get install openjdk-8-jdk
-
-
��֤java
-
java -version
-
-
-
��װ��������
-
��װssh
-
sudo apt-get install ssh -
����ssh��Կ
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa��ȡ����ssh����Ȩ��
ssh-copy-id localhost���»س������ȷ���Ƿ����hostList��ѯ��,���� ��yes�� �ٰ��س�
Ȼ����Ҫ�����뱾������
-
����ssh����
ssh localhost��װrsync
-
sudo apt-get install rsync
-
-
��������hadoop��װ������
-
hadoop�İ�װ
-
����hadoopѹ����
-
cd ~ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
-
-
��ѹ������
-
hadoop@ubuntu:~$ tar �Czxvf hadoop-3.2.2.tar.gz
-
-
����Ƿ��ѹ�ɹ�
-
hadoop@ubuntu:~$ ls Desktop Downloads hadoop-3.2.2 Music Public Videos Documents examples.desktop hadoop-3.2.2.tar.gz Pictures Templates -
�Ƿ���hadoop-3.2.2���ļ���?
-
-
����JAVA_HOME��������
-
gedit ~/hadoop-3.2.2/etc/hadoop/hadoop-env.sh -
�ڱ༭�����ҵ� ��# export JAVA_HOME=��

����һ�и�Ϊ export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64,�����˳�����
-
PS:���������ַ�Ļ�÷�����������������,Ȼ�����
update-alternatives --config java
-
-
-
hadoop���� �C ����α�ֲ�ʽ
������˵һ��,���������,����һ�ո�,һ��������������Сд�Ĵ��ᵼ����������ʧ��,��������֮ǰһ��Ҫ���!!
-
core-site.xml
-
�༭��
gedit ~/hadoop-3.2.2/etc/hadoop/core-site.xml -
��������,ע�����ݲ��ü�
<configuration> # ���� <property> # ij������ <name>fs.defaultFS</name> # ���Ե���������� <value>hdfs://localhost:9000</value> # ���Ե�ֵ�����,���ֵ��hdfs��·�� </property> # ���Եıպϱ�ǩ,һ��Ҫ��,б�߲�Ҫ�� </configuration>
-
-
hdfs-site.xml
-
gedit ~/hadoop-3.2.2/etc/hadoop/hdfs-site.xml���������
<configuration> <property> <name>dfs.replication</name> # ���ݵı��ݸ��� <value>1</value> # ������Ϊһ�� </property> </configuration>
-
-
����Hadoop������
-
����hadoop����������
-
��ʽ��NameNode������
-
��ʽ��
~/hadoop-3.2.2/bin/hdfs namenode -format -
����NameNode
~/hadoop-3.2.2/sbin/start-dfs.sh -
�鿴��Ⱥ״̬
hadoop@ubuntu:~$ jps 10960 NameNode 11529 Jps 11115 DataNode 11372 SecondaryNameNode -
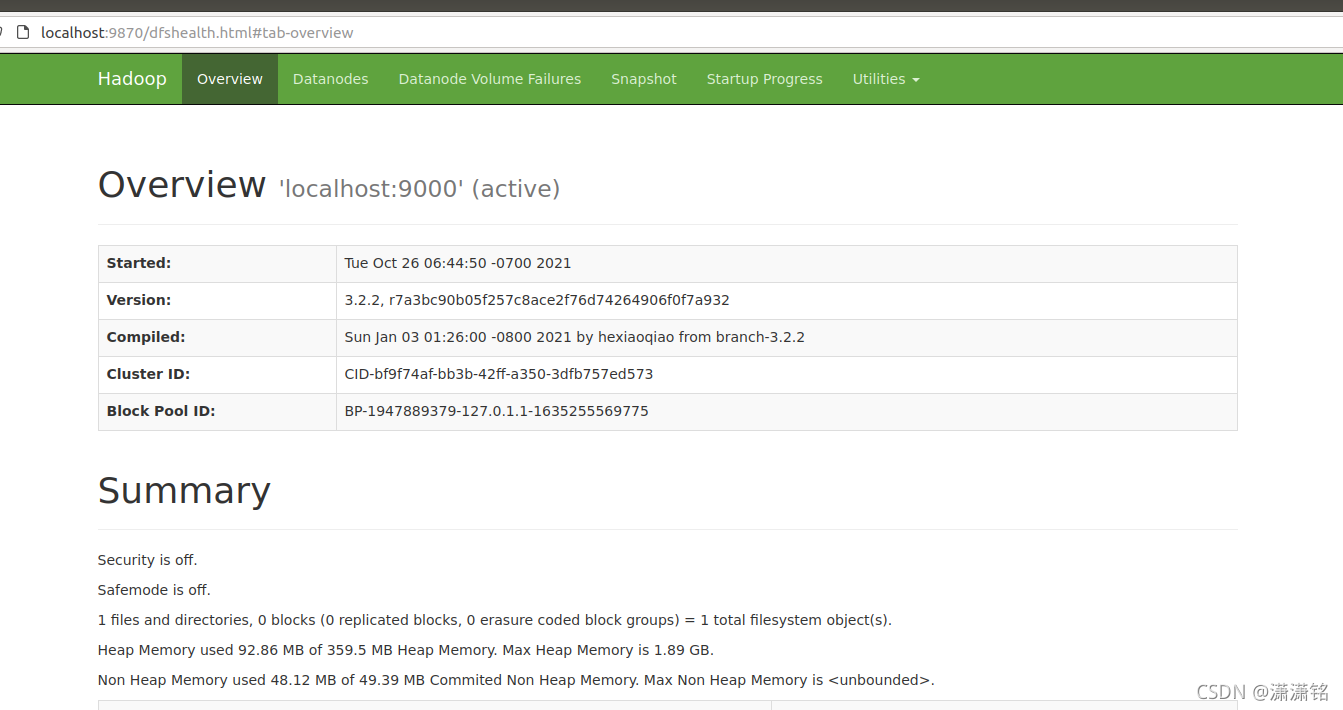
���NameNode��web�ӿ�
ֱ������������������� http://localhost:9870
-
-
ִ��һЩhdfs����(֮��ᾭ���õ�,���)
hdfs��һ���ļ�ϵͳ,�����͵��Ե��ļ���������,�д����ļ��С��ƶ��ļ��Ȳ���
-
����hdfsĿ¼
~/hadoop-3.2.2/bin/hdfs dfs -mkdir /user # -mkdir path �Ǵ���Ŀ¼ ~/hadoop-3.2.2/bin/hdfs dfs -mkdir /user/input -
���������ļ���hdfs��
~/hadoop-3.2.2/bin/hdfs dfs -put ~/hadoop-3.2.2/etc/hadoop/*.xml /user/input # -put a b�ǽ����ص�a����hdfs��b����������ǽ�-put����� etc/hadoop/Ŀ¼�����к�Ϊxml���ļ����Ƶ�hdfs�ļ�ϵͳ��/user/hadoopĿ¼��
-
�鿴һ��hdfs���ļ�
hadoop@ubuntu:~$ ~/hadoop-3.2.2/bin/hdfs dfs -ls /user/input # -ls a���г�Ŀ¼a�������ļ� Found 9 items -rw-r--r-- 1 hadoop supergroup 9213 2021-10-26 06:54 /user/hadoop/capacity-scheduler.xml -rw-r--r-- 1 hadoop supergroup 867 2021-10-26 06:54 /user/hadoop/core-site.xml -rw-r--r-- 1 hadoop supergroup 11392 2021-10-26 06:54 /user/hadoop/hadoop-policy.xml -rw-r--r-- 1 hadoop supergroup 849 2021-10-26 06:54 /user/hadoop/hdfs-site.xml -rw-r--r-- 1 hadoop supergroup 620 2021-10-26 06:54 /user/hadoop/httpfs-site.xml -rw-r--r-- 1 hadoop supergroup 3518 2021-10-26 06:54 /user/hadoop/kms-acls.xml -rw-r--r-- 1 hadoop supergroup 682 2021-10-26 06:54 /user/hadoop/kms-site.xml -rw-r--r-- 1 hadoop supergroup 758 2021-10-26 06:54 /user/hadoop/mapred-site.xml -rw-r--r-- 1 hadoop supergroup 690 2021-10-26 06:54 /user/hadoop/yarn-site.xml
-
-
����MapReduce
-
����hadoop�Դ���ʾ��
~/hadoop-3.2.2/bin/hadoop jar ~/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep /user/input /user/output 'dfs[a-z.]+'���������������:
- ~/hadoop-3.2.2/bin/hadoop: ����hadoop����
- jar:ִ����������jarָ��,���Ǹ��߳���,Ҫ����jar��
- ~/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar:Ҫִ�е�jar���ĵ�ַ
- grep:grep�����jar�����ָ��,�������������jar��hadoop�Ĺ�ϵ(��֮���Լ�д��hadoop������ָ��������,���Բ��������ָ֧��)
- /user/input:�������ַ
- /user/output:�������ַ,������ַ����hdfs�ϵĵ�ַ,��Ҫע����� /user/outputĿ¼�������ȴ���
- '��dfs[a-z.]+��:��grepָ��IJ�����grep����������ɸѡ�ı�,����������Ǹ���grep������ģʽɸѡ�ı���
-
�鿴���н��:
-
�Ƚ�hdfs�ϵĽ����ȡ������
~/hadoop-3.2.2/bin/hdfs dfs -get /user/output ~/output -
��ȡ���
cat ~/output/* # cat����ʾ�ı�������
-
-
-
���ر�hadoop��Ⱥ,������֮ǰҪ�ȹرռ�Ⱥ
~/hadoop-3.2.3/sbin/stop-dfs.sh
-