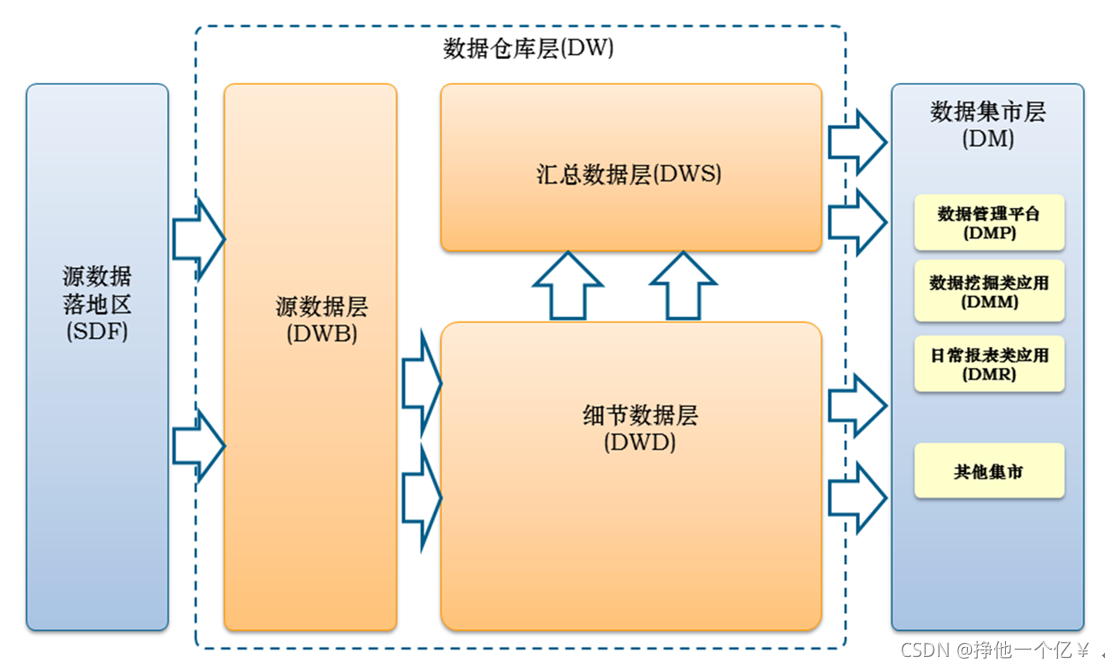
1.数据架构
2.数据仓库建模
目前的构建方法主要有三种:
? 范式建模法
? 维度建模法
? 实体建模法
1.范式建模:主要解决关系型数据库的数据存储
数据库六大范式说明
? 第1范式-1NF:无重复的列、列不可再拆分。
? 第2范式-2NF:属性完全依赖于主键
? 第3范式-3NF:属性不依赖于其它非主属性,即属于依赖于主键不能出现传递依赖。
? 巴斯-科德范式(BCNF),第四范式(4NF),第五范式(5NF,又称完美范式)
2.维度建模法
事实表,维度表来构建数据仓库,最被人广泛知晓的名字就是星型模式(Star-schema)和雪花模式(Snowflake-schema)。
事实表:
发生在某个时间点上的一个事件,即具体的实体内容。
维度表:
从事实表中抽离出来的分析粒度,维度表中包含事实数据表中事实记录的特性。
星型建模法
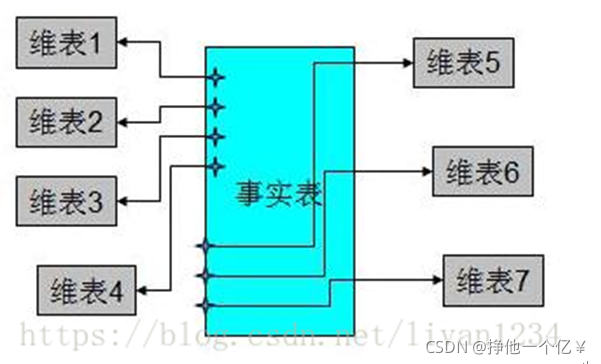
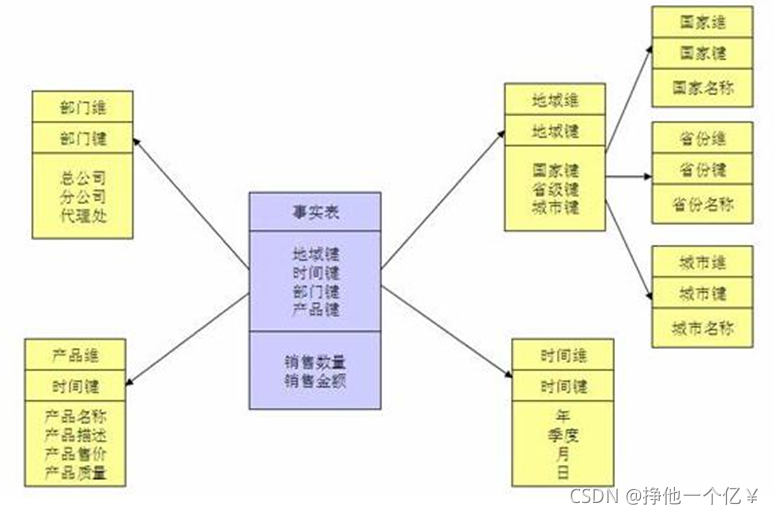
雪花建模法
优点是通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。
雪花型结构去除了数据冗余。
3.数据分析
3.1 函数分类
分析函数
- ROW_NUMBER:序列分析函数,用于排序,按照顺序,不关心是否有相等情况,从1开始逐条给数据一个加1后的序列号。如1,2,3,4…
- RANK:序列分析函数,用于排序,按照顺序,关心相等情况,如遇到相等情况,名次会留下空位。如1,2,2,4,4,6…
- DENSE_RANK:序列分析函数,用于排序,关心相等情况,如遇到相等情况,名次不会留下空位。如1,2,2,3,3,4…
窗口函数
- LAG:函数LAG(col,n,DEFAULT)用于统计窗口内往上第n行值。
- LEAD:与LAG作用相反,函数形式如LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值。
- FIRST_VALUE: 取分组内排序后,截止到当前行,第一个值
- LAST_VALUE:与FIRST_VALUE相反
over()从句:指定分析窗口函数的细化落围规则
- 与标准的聚合函数COUNT、SUM、MIN、MAX、AVG联用,如sum(…) over(…)
- PARTITION BY语句,使用一个或者多个原始数据类型的列
- PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
使用窗口规范窗口规范支持以下格式:
- ROWSBETWEEN:窗口子句,属于物理截取,即物理窗口,从行数上控制截取数据的大小多少。
- RANGE BETWEEN:窗口子句,属于逻辑截取,即逻辑窗口,从列值上控制窗口的大小多少。
- PRECEDING:window子句之往前
- FOLLOWING:window子句之往后 CURRENT ROW:window子句之当前行
- UNBOUNDED:window子句之起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED
- FOLLOWING:表示到后面的终点。 注意:order by子句后边如果没有跟着多大窗口,则默认为range between unbounded preceding and current row