前言:
之前的文章中介绍过Zookeeper服务器(单机版)的启动流程。但是在实际的运用中,Zookeeper大都以集群模式来运行(这样才能实现其高可用)。所以从本文开始,我们正式进入集群模式的分析。包括服务器的启动、Leader的选举、集群处理各种事务非事务请求的过程。
1.搭建一个伪集群Zookeeper
笔者资源有限,所以在本地就搭了一个伪集群模式的Zookeeper服务,仅用于分析集群启动的过程。
1.1 将单机版本的Zookeeper资源拷贝
网上很多使用一份Zookeeper服务端资源的示例,笔者为了方便,直接拷贝成三份,这样后续直接修改每一份的配置即可,如下所示:
1.2 修改zoo.cfg配置
1.2.1 zookeeper-3.4.11_1/conf/zoo.cfg修改如下
dataDir=../data
clientPort=2181
server.1=localhost:2287:3387
server.2=localhost:2288:3388
server.3=localhost:2289:33891.2.2?zookeeper-3.4.11_2/conf/zoo.cfg修改如下
dataDir=../data
clientPort=2182
server.1=localhost:2287:3387
server.2=localhost:2288:3388
server.3=localhost:2289:33891.2.3?zookeeper-3.4.11_3/conf/zoo.cfg修改如下
dataDir=../data
clientPort=2183
server.1=localhost:2287:3387
server.2=localhost:2288:3388
server.3=localhost:2289:33891.3 添加myid文件(整个文件名即为myid,没有后缀)
zookeeper-3.4.11_1/data/下添加myid文件,文件内容为:3;
zookeeper-3.4.11_2/data/下添加myid文件,文件内容为:2;
zookeeper-3.4.11_3/data/下添加myid文件,文件内容为:1;
1.4 逐个启动
执行zookeeper-3.4.11_1/bin/zkServer.cmd;
执行zookeeper-3.4.11_2/bin/zkServer.cmd;
执行zookeeper-3.4.11_3/bin/zkServer.cmd;
验证 TODO
2.zookeeper集群版启动流程
参考之前单机版启动流程,我们可知,本质上还是启动QuorumPeerMain.main()方法
2.1?QuorumPeerMain.main()
public class QuorumPeerMain {
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
// 直接调用initializeAndRun
main.initializeAndRun(args);
} catch (IllegalArgumentException e) {
...
System.exit(0);
}
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// 直接将zoo.cfg配置文件交由QuorumPeerConfig解析
config.parse(args[0]);
}
// 提供一个定时任务,来清理data数据和log数据
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.servers.size() > 0) {
// 集群模式启动
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// 单机模式的启动
ZooKeeperServerMain.main(args);
}
}
}与之前分析单机版本的路线不同,这里执行了runFromConfig()这个方法。
2.2 QuorumPeerMain.runFromConfig()
public class QuorumPeerMain {
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
// 端口服务类,监听请求
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
// 在这里配置的是clientPort和maxClientCnxns参数
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// 重要的QuorumPeer对象,后续都是对其的分析
quorumPeer = getQuorumPeer();
// 设置QuorumPeer参数,基本都是在zoo.cfg中配置的参数
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
...
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
}到这里基本启动就结束了,都交由QuorumPeer来执行了。一头雾水,我们慢慢看,先来看下QuorumPeer具体是做什么的。
3.QuorumPeer
3.1?QuorumPeer主要属性分析
// This class manages the quorum protocol
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
// 内存数据库
private ZKDatabase zkDb;
// 集群中的节点信息
protected Map<Long, QuorumServer> quorumPeers;
// 当前节点的myid值
private long myid;
// 是否运行状态
volatile boolean running = true;
// 节点状态,有LOOKING, FOLLOWING, LEADING, OBSERVING;这些状态
private ServerState state = ServerState.LOOKING;
// 配置的server.1=localhost:2287:3387地址信息
private InetSocketAddress myQuorumAddr;
// leader选举算法类
Election electionAlg;
// 端口服务监听
ServerCnxnFactory cnxnFactory;
// 事务日志、快照日志处理器
private FileTxnSnapLog logFactory = null;
public static class QuorumServer {
// 服务用的节点地址
public InetSocketAddress addr;
// 选举用的节点地址
public InetSocketAddress electionAddr;
public String hostname;
public int port=2888;
public int electionPort=-1;
public long id;
// 当前节点状态 FOLLOWER | OBSERVER
public LearnerType type = LearnerType.PARTICIPANT;
}
// 节点运行状态,默认是LOOKING
public enum ServerState {
LOOKING, FOLLOWING, LEADING, OBSERVING;
}
// 跟随者的状态,要么FOLLOWER要么OBSERVER
public enum LearnerType {
PARTICIPANT, OBSERVER;
}
}如何理解QuorumPeer呢?可以把它理解成ZookeeperServer的托管者,每个QuorumPeer代表了集群中的一台机器,QuorumPeer对象存放了该节点的基本信息。
3.2 QuorumPeer.start() 启动服务
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
public synchronized void start() {
// 加载快照日志,具体见3.2.1
loadDataBase();
// 启动服务监听,基本同单机版
cnxnFactory.start();
// 启动leader选举,后续博客分析
startLeaderElection();
// 由于QuorumPeer继承了Thread,故其start()方法会执行当前run()方法
super.start();
}
}3.2.1 QuorumPeer.loadDataBase() 加载快照日志
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
private void loadDataBase() {
File updating = new File(getTxnFactory().getSnapDir(),
UPDATING_EPOCH_FILENAME);
try {
// 这里与之前分析单机版的ZKDatabase没有区别
zkDb.loadDataBase();
// load the epochs
long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid;
long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid);
try {
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
if (epochOfZxid > currentEpoch && updating.exists()) {
LOG.info("{} found. The server was terminated after " +
"taking a snapshot but before updating current " +
"epoch. Setting current epoch to {}.",
UPDATING_EPOCH_FILENAME, epochOfZxid);
setCurrentEpoch(epochOfZxid);
if (!updating.delete()) {
throw new IOException("Failed to delete " +
updating.toString());
}
}
} catch(FileNotFoundException e) {
// pick a reasonable epoch number
// this should only happen once when moving to a
// new code version
currentEpoch = epochOfZxid;
LOG.info(CURRENT_EPOCH_FILENAME
+ " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation",
currentEpoch);
writeLongToFile(CURRENT_EPOCH_FILENAME, currentEpoch);
}
if (epochOfZxid > currentEpoch) {
throw new IOException("The current epoch, " + ZxidUtils.zxidToString(currentEpoch) + ", is older than the last zxid, " + lastProcessedZxid);
}
try {
acceptedEpoch = readLongFromFile(ACCEPTED_EPOCH_FILENAME);
} catch(FileNotFoundException e) {
// pick a reasonable epoch number
// this should only happen once when moving to a
// new code version
acceptedEpoch = epochOfZxid;
LOG.info(ACCEPTED_EPOCH_FILENAME
+ " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation",
acceptedEpoch);
writeLongToFile(ACCEPTED_EPOCH_FILENAME, acceptedEpoch);
}
if (acceptedEpoch < currentEpoch) {
throw new IOException("The accepted epoch, " + ZxidUtils.zxidToString(acceptedEpoch) + " is less than the current epoch, " + ZxidUtils.zxidToString(currentEpoch));
}
} catch(IOException ie) {
LOG.error("Unable to load database on disk", ie);
throw new RuntimeException("Unable to run quorum server ", ie);
}
}
}除了标准的加载快照日志到ZKDatabase中的操作外,还有关于currentEpoch和acceptedEpoch的操作。
epoch就是关于Leader纪元的概念,通过ZXID我们可以确定当前Zookeeper集群的纪元,每更换一次leader,epoch加1。
启动完流程我们会发现在我们指定的dataDir目录下有两个文件currentEpoch、acceptedEpoch,里面写了一个数字(首次就是1)。
有关于这两个参数的更多释义可以参考:?ZOOKEEPER335 为什么要区分acceptedEpoch 和 currentEpoch - 云+社区 - 腾讯云? ?
3.3 QuorumPeer.run()
在执行完leader选举后(后续专门博客分析),下面就是执行当前run()方法
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
public void run() {
// 设置 当前线程名称
setName("QuorumPeer" + "[myid=" + getId() + "]" +
cnxnFactory.getLocalAddress());
LOG.debug("Starting quorum peer");
try {
// jmx相关,可以不了解
jmxQuorumBean = new QuorumBean(this);
MBeanRegistry.getInstance().register(jmxQuorumBean, null);
for(QuorumServer s: getView().values()){
ZKMBeanInfo p;
if (getId() == s.id) {
p = jmxLocalPeerBean = new LocalPeerBean(this);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxLocalPeerBean = null;
}
} else {
p = new RemotePeerBean(s);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
}
}
}
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxQuorumBean = null;
}
try {
// 这里是关键
while (running) {
// 获取当前节点的状态LOOKING, FOLLOWING, LEADING, OBSERVING
// 根据不同的状态启动不同的server
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
...
break;
case OBSERVING:
...
break;
case FOLLOWING:
...
break;
case LEADING:
...
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
try {
MBeanRegistry.getInstance().unregisterAll();
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
}
}
}我们把run()方法拆开来分析,后续会有三篇博客分别介绍Leader、Follower、Observer类型的server启动的过程。
可以先来看下其继承关系
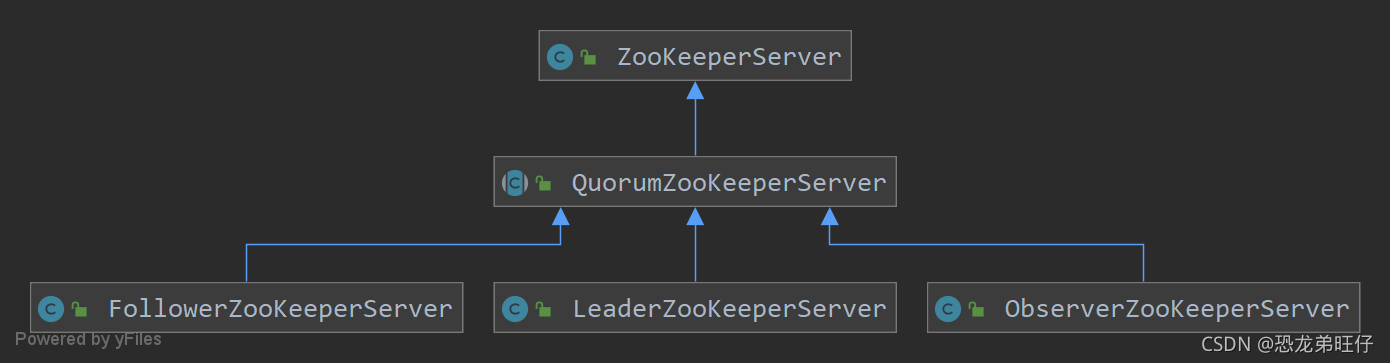
之前我们分析单机版启动过程时,分析的就是ZookeeperServer。
总结:
本文算是一篇引导文,Zookeeper集群相关的知识点相对于单机版多了不少,所以,我们先了解其启动框架,后续会对每一种角色的节点进行详细分析。