ShardingSphere代码阅读(二)
探索阅读源码的最佳姿势
前言
上一篇说到阅读源码前需要准备什么,热身结束后开始,就需要探索阅读源码的最佳姿势,其实就是合适自己的一种阅读方式。

一、明确目标,带着问题看
在看源码之前,先要明确一下目标,带着一个问题深入源码中找答案,正所谓源码之下无秘密。如果没有带着疑问看源码是啃不下去的,再从官方提供的demo入手,慢慢摸索。
问题:ShardingSphere是如何实现把数据insert到不同的DB和tables

二、ShardingSphere-JDBC-core 源码
ShardingSphere-JDBC的demo中 有关实现有两种方式,分别是Java api和 yaml 配置,因此分别展开探究其实现
1.Java API
入口-过程-结果
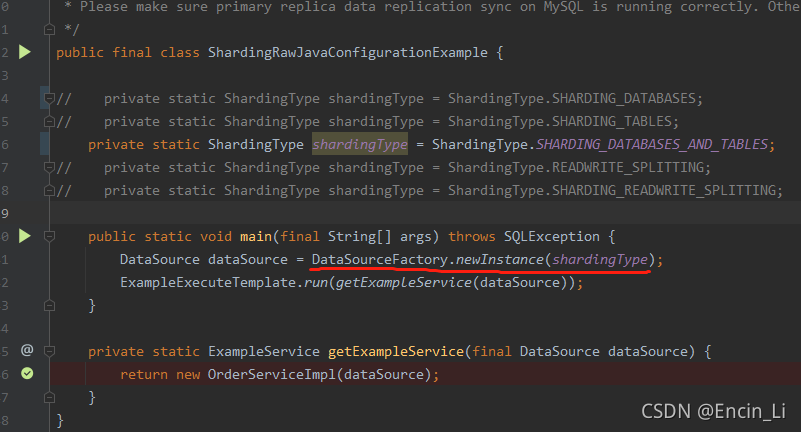
进行SQL的插入,首先需要创建对应的数据源实例,进入其中,看看是如何构建和区分不同实例的,根据上图的demo是根据枚举进行区别不同实例创建
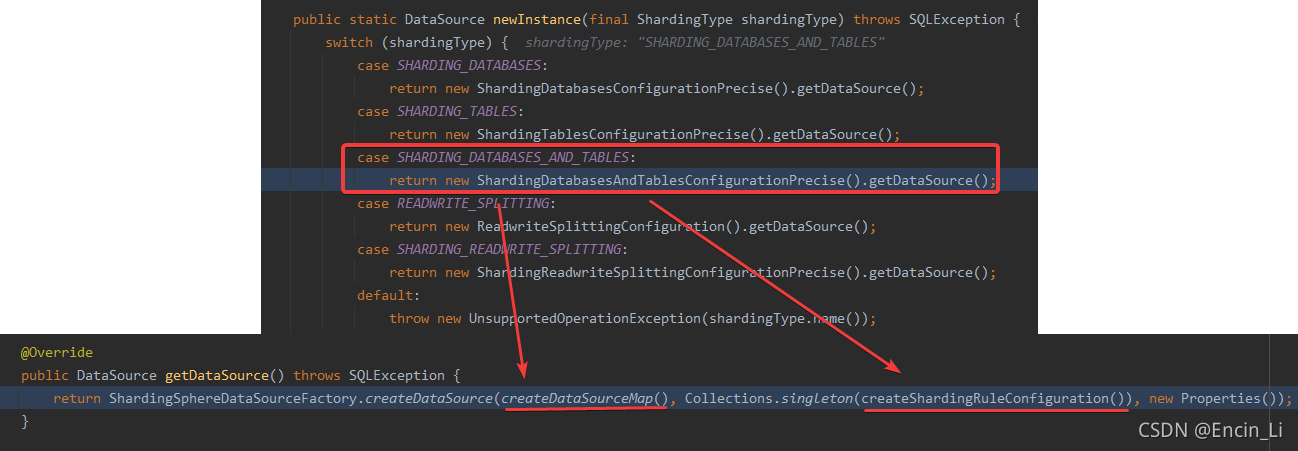
从上图中可以知道,会创建数据源的map和ShardingSphere规则参数,这两部分对应的就是有多少个物理表和库,其映射关系、规则的配置,那么到底如何将这两部分结合并且实现其功能的,继续往下探究ShardingSphere是如何设计的

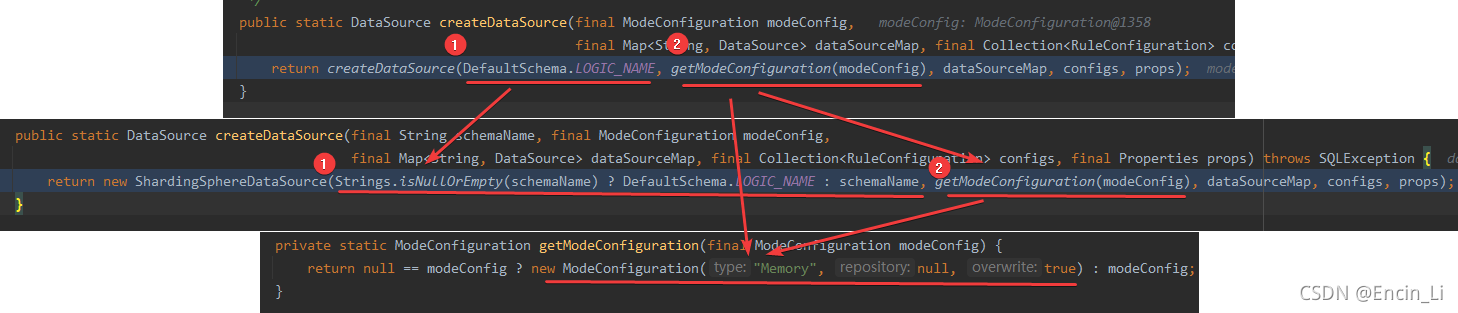
从上图可以看出,modeConfig几乎可以确认的是,只要为空,必然new一个Memory 使用,除此之外,也是写死第一个参数,schemaName=logic_db,意思明确是logic数据库,那到底是有什么用处的呢?
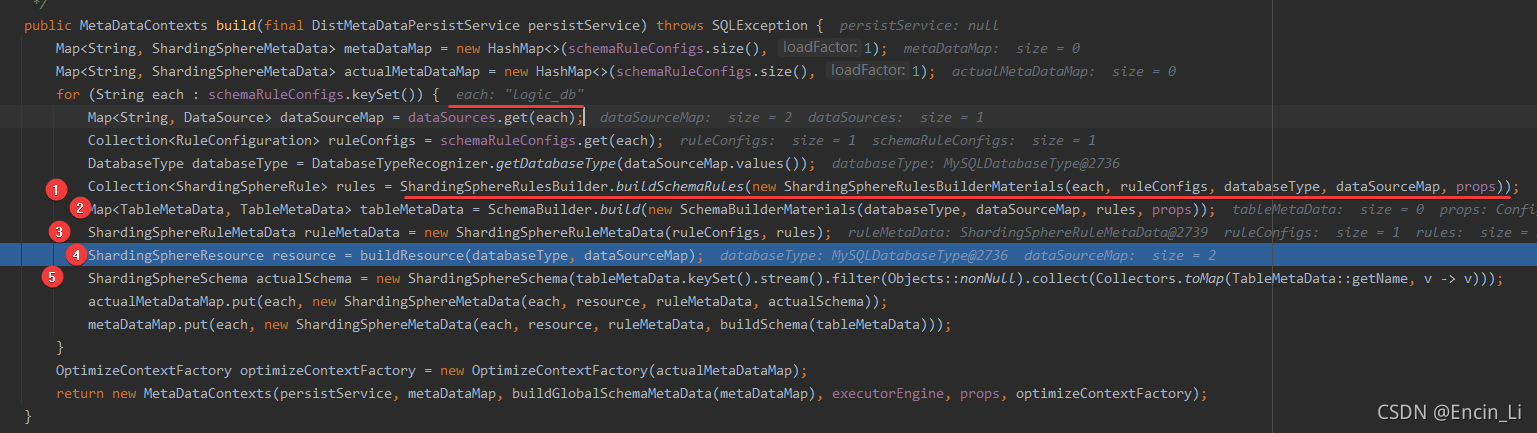
构建ShardingSphere和Mysql之间的关系,建立映射,
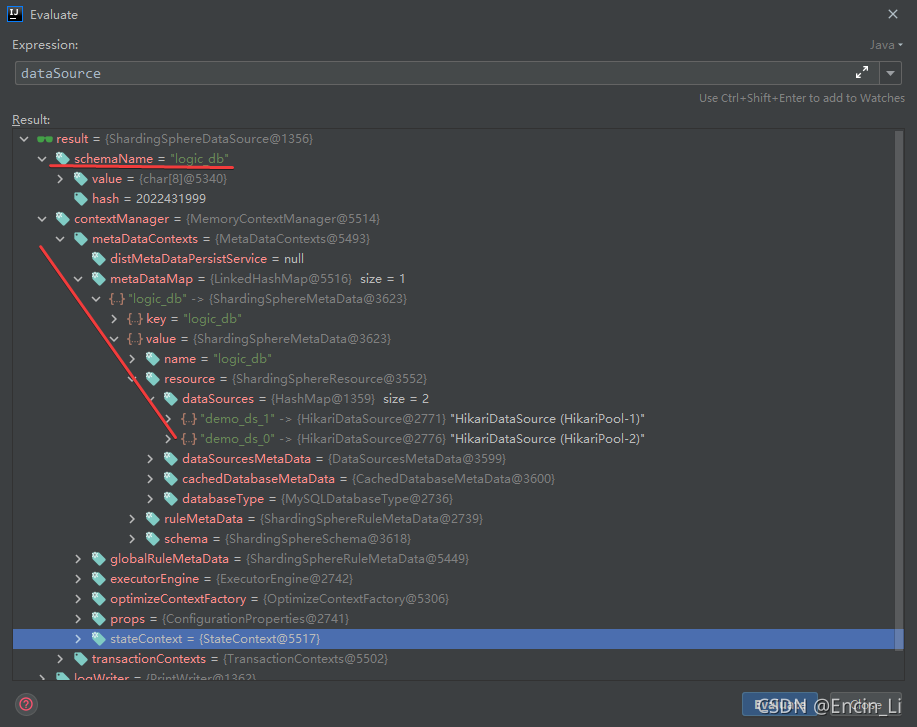
从结果上看,是把两个实体数据库绑定在logic_db上了,
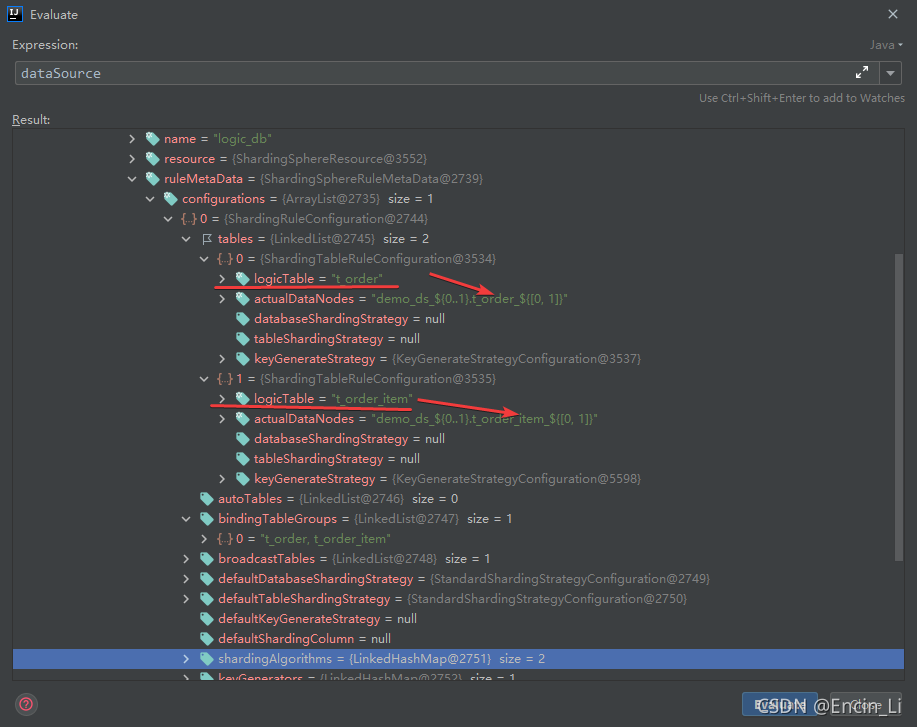
logic_table也都是在初期写好的,在创建sharing规则配置时的策略配置,继续看看,当插入数据,是如何划分库表的
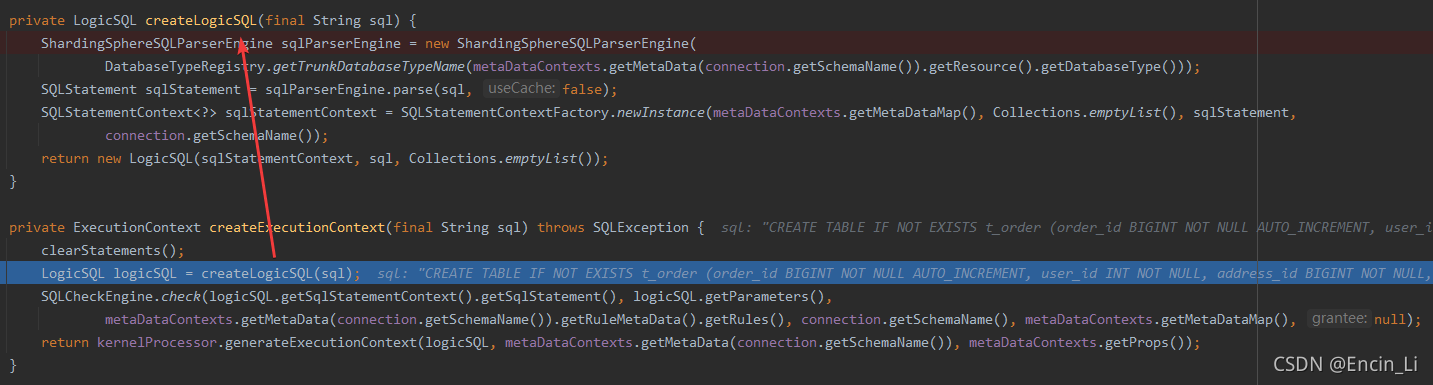
从构建的关系来看,t_order表示一个logic表,并不是实质的的数据表,如果直接插入数据库中,必然会报错,告诉我们这张表并不存在,所以就去下图中的 createLogicSQL(sql),但是logic SQL可以很直观知道这个SQL是给ShardingSphere使用的

构建后的logicSQL给kernelProcessor使用,那么具体logic的实现就是在里面处理了,继续深入看看处理过程

从①看出路由处理,②是重写这个SQL,往下就是execute了,获得最终结果,那么如何把logicSQL写到 mysql中,必然是在①和②中发生的,那么继续分析①
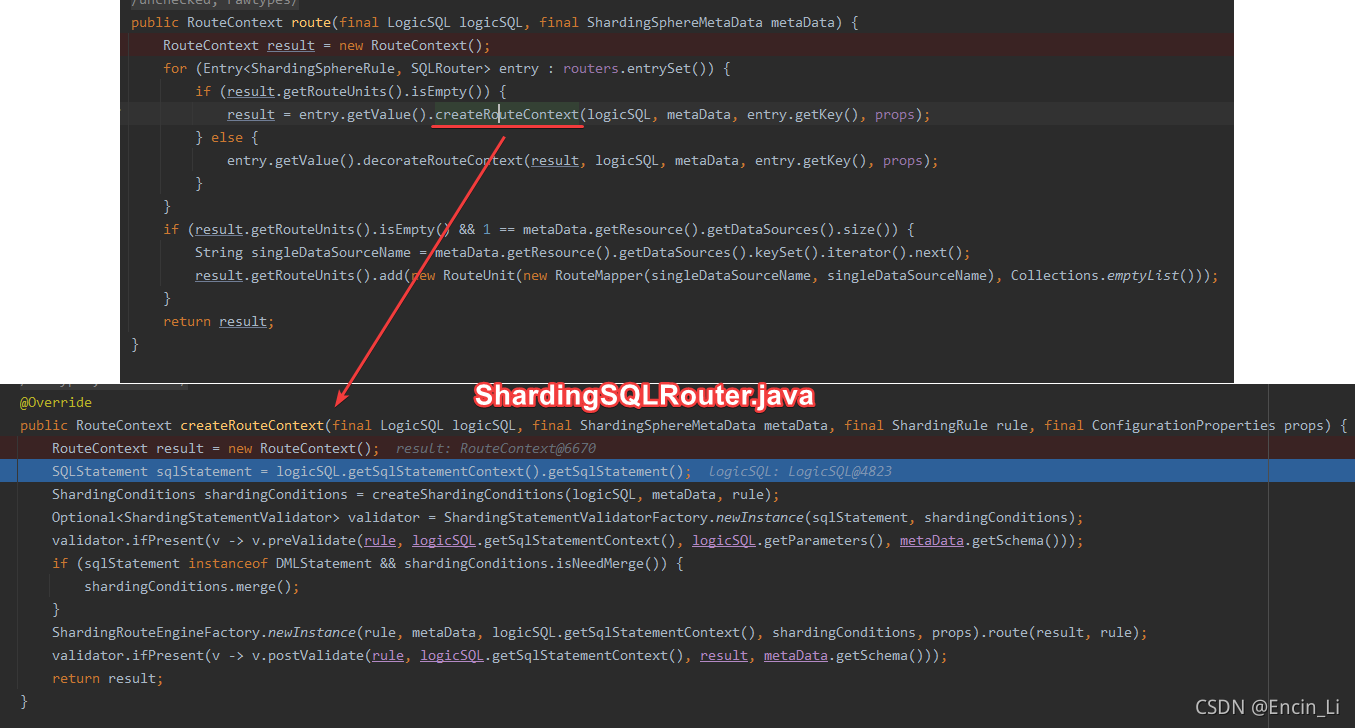
创建这个router上下文,目的就是为了去找到对应的表,
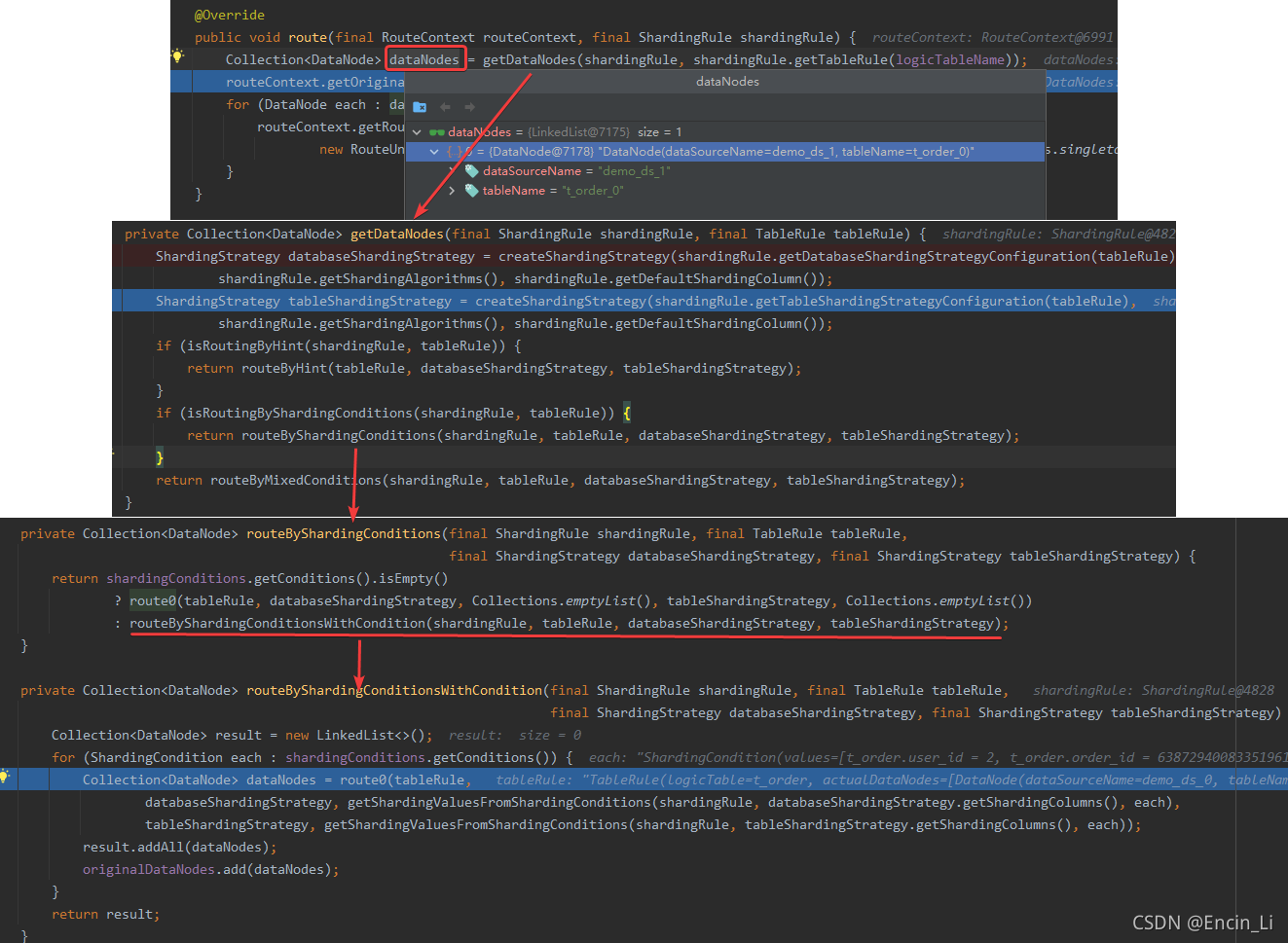
从上图看到,dataNodes结果就是我们想要的,那是怎么获得这个结果的,就继续往下看到database分库策略和tables的分表策略,然后根据这个策略进行分配
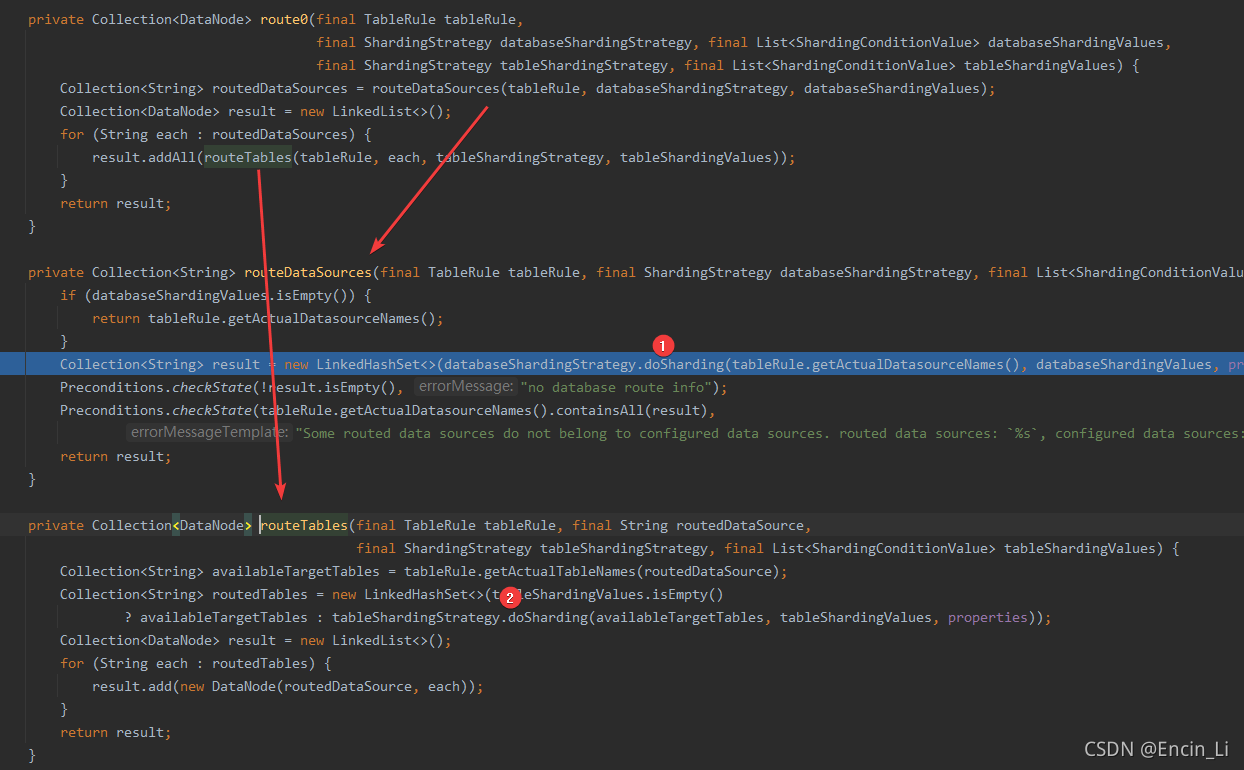
上图的①处和②处都是具体的分库分表细则
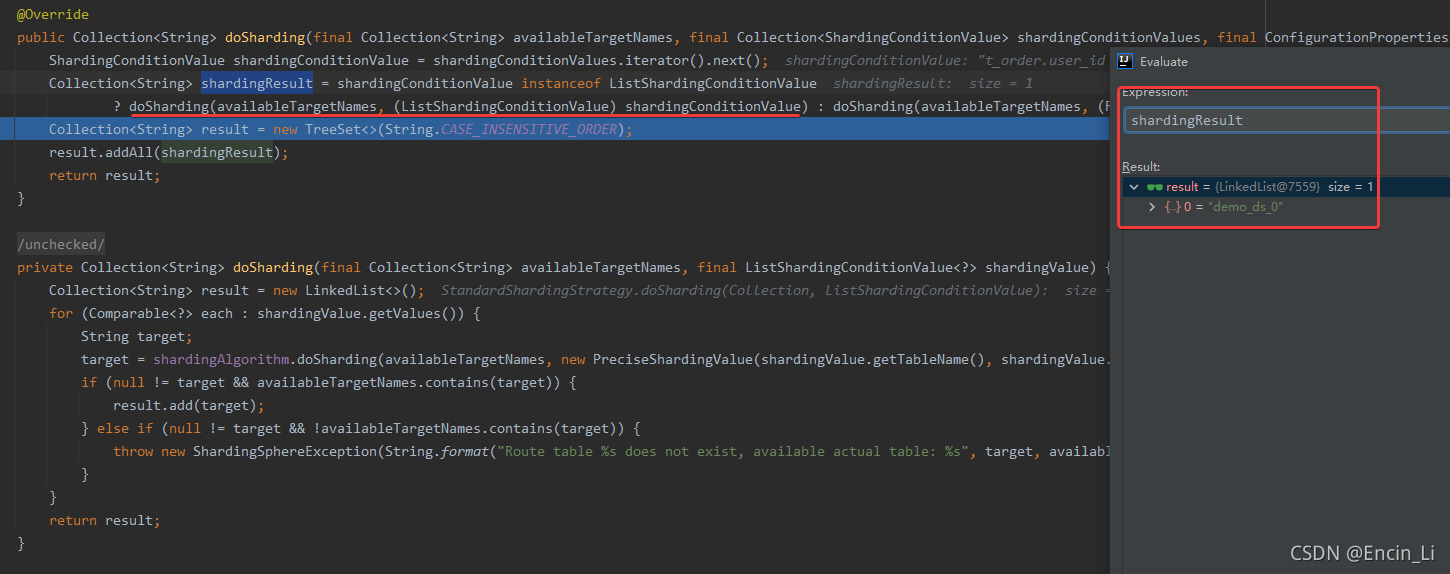
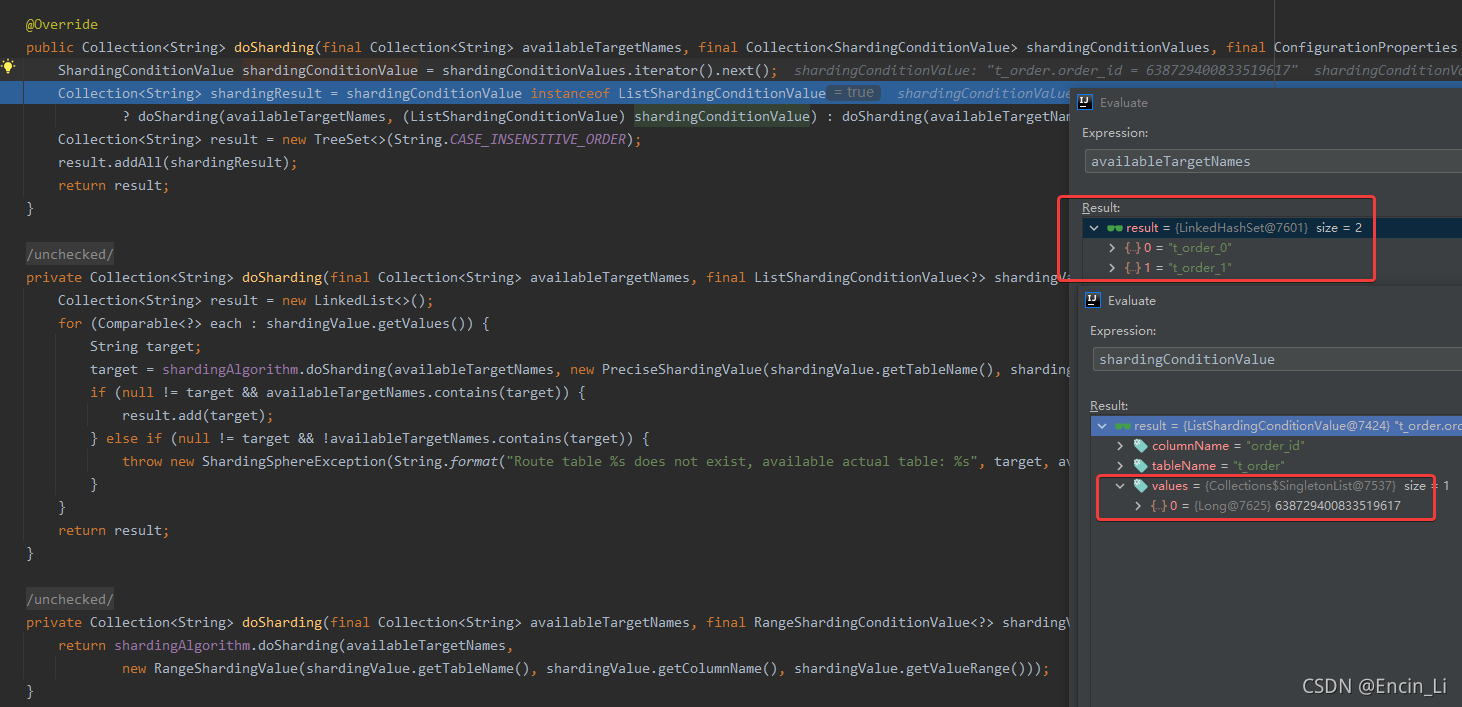
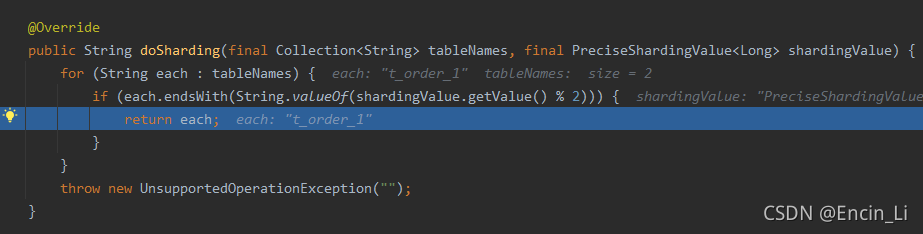
深入其中,可以看到去找到其中真是的库表,然后在StandardModuloShardingTableAlgorithm.doSharding()中,根据配置后的分配算法,进行获取结果,得到具体的插入表库信息,但是我们细看其doSharding里面的logic 代码,是基于shardingValue.getValue() %2 取模,说明是写死的取模方式,看起路径,是example自己重写的,因为example固定了两库两表,以2取模合理,那么如果需要自己实际开发,说明需要重写方法,具体根据自己的分库分表数量实际取模,最终获得actual DB找到数据需要插入的库表后,下一步操作就是具体插入到库表中去
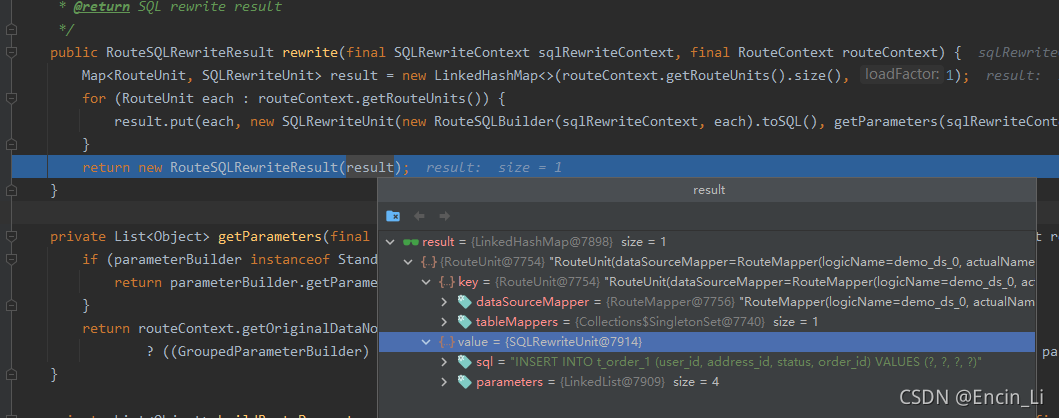
rewrite SQL ,目的是把logicSQL转换为能插入数据库中的SQL,其结果是在toSQL()中转换的,获得了真实的SQL后,那么就是最后一步,执行SQL

往下只有result和return result了,那么执行SQL必然是在createExecutionContext()中处理的,但是我们是探究怎么把不同数据insert到不同库,目的已经达到,那么整个流程很显然环环相扣的,重要的是分库分表和rewrite SQL处理好,必然就能insert到正确的库表中了

2.YAML config
YAML config 处理创建实例的方式不一样外,其他大差不差的
入口-过程-结果

从上图看出,处理和JAVA API方式一致的,只不过几换成了配置文件的方式,官方的
sharding-databases-tables.yaml文件的内容如下:
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_address
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
props:
sql-show: false
创建数据库是基于yaml的方法,就需要基于yaml获得对应的配置

入口和API 的是一样的,那么创建数据源就是和API的方法一致了。
继续探索下去,发现底层实现是一致的,只有加载数据源的方式不同外,整个过程和结果是完全一致的。
总结
初始浅读源码,但是基于问题阅读,可看在这个过程中获得问题的答案,后面的多次阅读源码,根据个人情况调整之后,得出的结论如下:
- 必须确认问题,带着问题深入,用记事本记录下问题,这个问题是贯穿整个源码阅读的,不然容易迷失
- 在阅读过程是越来越多问题的,都记录下来后,然后回到第一点,后续加入的问题都是混淆你的,所以问题需要解决一个再看下一个
- 在阅读源码的时候,一般有一个入口,在入口处先不要急着往下看,先看看当前类的结构图和相关的层次图,查看一下父子类和兄弟类的关系,最好是用图画出来,理清关系,不会画图也可以自己用记事本整理出一个调用结构,对整体架构有一定的认知有助于理解,如果没有图,一直深入阅读时,逐渐会忘记从什么地方调用,上一步功能是什么,而当你阅读下一步前,对图进行变色来区别是调用哪个类,回头也更加清晰,其实和debug的堆栈显示是一样的道理
- 阅读源码之后,在每一处的代码加上自己的注释理解,缩写名词也要有标记出处,后续回看也能快速记起
- 正所谓好记性不如烂笔头,虽然写文章比较花费时间,但是写下来后,重新组织过的语言也会让你更加深刻的理解,任何形式的都可以,包括简单的记事文章,如果后续想变成博客、公众号的话,也能有初始的文稿参考
上述是合适博主我的姿势,有些人就喜欢在第三点一探到底,不能说哪个最好,只能说找到合适自己的就行了,最后希望大家都能坚持下去,慢慢变强,成为一方大佬,加油!!!