前言
Kafka是一个分布式的流处理平台(0.10.x版本),在kafka0.8.x版本的时候,kafka主要是作为一个分布式的、可分区的、具有副本数的日志服务系统(Kafka? is a distributed, partitioned, replicated commit log service), 具有高水平扩展性、高容错性、访问速度快、分布式等特性;主要应用场景是:日志收集系统和消息系统
为什么使用Kafka 它有什么优势
有以下特点:大数据领域、高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性、高并发
Kafka适合以下应用场景
大数据领域、日志收集、消息系统、活动跟踪、数据处理、行为日志、等等方面
Kafka经常被用到的模式
有点对点或者 发布/订阅模式:点对点很容易理解 一对一的发布接受消息,发布和订阅模式 类似于广播 就比如 微信公众号推文,每天要给这一个公众号里面的所有用户推文,不能一对一的发送消息,要一对一的发送万一有几百万粉丝订阅,这得创建多少队列在录入数据的时候得有多麻烦,所以就要使用发布/订阅模式去处理,发布/订阅模式里面涉及了一个比较好的点就是 我可以根据场景去选择我要哪一种模式,一种是可以让消费者自动去拉取数据自己去控制流量运行的速度,但是这里有一个缺点就是kafka被动被消费者程序拉去,主动询问是否有新的消息 这里避免不了有一个循环,一直去询问kafka有没有新数据,比较浪费资源。?一种是我主动推送消息到消费者那里,微信公众号就是这样的逻辑,主动推送消息给粉丝。
架构图
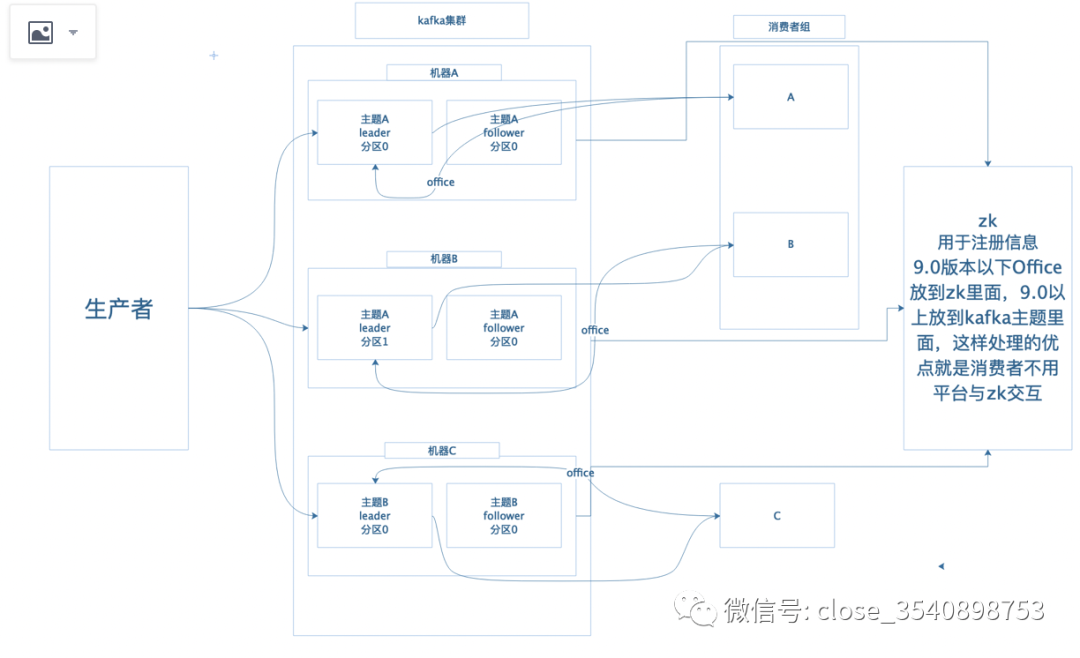
生产者:用来生产消息并推送到对应的主题里面。
kafka集群:可以理解为部署多个kafka,可以在一台机器上面 也可以不输在多台机器上面。
broker:可以理解为单个kafka,也就是图上面机器N 的官方名称。
topic:主题,生产者/消费者订阅主题进行收发消息,主要为了解决某一kafka上面可以支持多个程序处理不同的事。
leader/follower:一个是备份 一个是leader,当leader出问题的时候,follower会上移进化成leader,避免我们的服务挂掉。
分区:主要是用来削峰,能让我们的程序能均匀的处理消息。
消费者:消费者里面有一个概念,就是有一个消费者组的这么一说,里面有一个要注意的地方就是 某一个主题只能被某一个消费者组里面某一个用户用来消费,就是同一个组里面消费者不能订阅同一个主题,最好是主题与消费者组里面消费者个数一致 否则会造成资源浪费,造成空闲的消费者。
zk:用于kafka注册消息使用,9.0以下版本 消息处理的偏移量放到zk里面存储,9.0以上偏移量就放到kafka topic里面存储,主要就是为了解决不频繁的与zk交互。
常用命令
zk 安装:去官网下载对应压缩包:https://zookeeper.apache.org/releases.html
cd /tmp/zookeeper/zookeeper-node1/confcp /tmp/zookeeper/zookeeper-node1/conf/zoo_sample.cfg /tmp/zookeeper/zookeeper-node1/conf/zoo.cfg#data与log 默认zookeeper里面没有需要手动创建#zoo.cfg配置文件需要修改的地方:dataDir=/tmp/zookeeper/zookeeper-node1/data #消息缓存路径dataLogDir=/tmp/zookeeper/zookeeper-node1/log #消息log路径#zookeeper集群需要配置server 伪集群只需要改一下对应的端口就OK了#server.1=47.94.2.151:2888:3888#server.2=47.94.2.151:2889:3889#server.3=47.94.2.151:2890:3890
启动zk的时候要检查是否有java环境,没有的话需要安装一下 以centos7为例:yum install java???????
#启动zkServer.sh?(start|stop|restart)等#启动命令行调试:bash zkCli.sh#ls / 查看是否有kafka注册上来#ls /broker 查看机器#broker 下面与主题等
kafka 使用docker安装
这里使用 docker-compose,具体配置文件 docker-compose.yml 内容如下???????version:?'3'services: zookeeper: image: wurstmeister/zookeeper volumes: - /etc/localtime:/etc/localtime:ro ports: - "2181:2181" restart: always kafka: image: wurstmeister/kafka ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: localhost??????KAFKA_ZOOKEEPER_CONNECT:?zookeeper:2181 volumes: - /var/run/docker.sock:/var/run/docker.sock - /data/db/kafka:/kafka/KafkaLog - /etc/localtime:/etc/localtime:ro depends_on: - zookeeper restart: always
docker-compose基础命令
docker-compose up -d 在后台启动docker-compose down 停止
kafka分布式安装
去官网下载对应压缩包:http://kafka.apache.org/downloads???????
vim?/tmp/kafka/config/server.properties#机器的ID必须唯一且为intbroker.id=0?#kafka地址listeners=PLAINTEXT://127.0.0.1:9092#消息存储路径log.dirs=/tmp/kafka/logs#zk 路径zookeeper.connect=127.0.0.1:2181
kafka启动关闭:???????
#start开启 stop停止bash /bin/kafka-server-start.sh -daemon ../config/server.properties
kafka cmd操作:
所有主题:
bash kafka-topics.sh --list --zookeeper 127.0.0.1:2181创建:
bash kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test删除:
bash kafka-topics.sh --delete --zookeeper localhost:2181 --topic testkafka 生产者:
./kafka-c testkafka 消费者:
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic testkafka消费者组:
bash kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic deamon --consumer.config ../config/consumer.propertiesbash kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic deamon --consumer.config ../config/consumer.properties
消费方式+分区分配策略
注:消费者组里面的消费者不可重复订阅 主题里面的分区
消费方式:
主要有两种:
-
消息队列主动推送消息给对应订阅的消费者,不好之处就是不知道消费者那面处理的速度如何,还有就是消费者没办法控制消息发送的速度。
-
消费者主动拉取消息队列中的数据,不好之处是消费者因为需要经常去询问是否有数据需要一直有一个循环去询问,建议在循环里面增加sleep,如果没有拉取到数据就让程序休息一下,不然一直空转消耗比较大。
分区分配策略
主要有两种:
-
轮训,他的不好之处就是在有消费者组和多个分区的情况下有可能会消费到不是本消费者订阅的数据,因为他的处理逻辑是把该消费者组订阅的所有主题都当为一个主题,来轮训,所有有的消费者订阅了有的没订阅,就会出现消费多的情况,但是一般的情况下也不会这么设计,最好是在全部都订阅相同主题的情况下去使用这种方式
-
范围,底层逻辑 用分区数磨消费者
文件存储机制
简单描述:每一个主题下面都会有不同多个分区,分区的存储是按照 主题名称+序列,序列是从0开始的。

上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,
分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息),
其中497表示该消息的物理偏移地址(位置)为497。
生产者(数据一致性与分区策略)选举机制ISR 故障细节处理
分区策略,生产者 在生产消息?往 分区里面打数据的时候有三种形式:
-
可以指定partition 去生产数据。
-
可以指定对应的key值,kafka会根据key值算hash 然后除以 分区数据 再取余数。
-
partition没有指定 key也没有指定 会随机选取一个分区 然后在之后的发送数据会轮询着来发送。
数据一致性
生产者发送数据 如何保持数据一致性的问题:
????都知道 kafka 分区里面是有 leader 和 follower的,这块引出一个概念就是ack(确认已收到)的意思,这时候就有一个问题就是 假如有多个follower ack是等这个全部同步成功后还是半数同步成功后才返回给生产者这个信息说明确认已收到,全部同步和半数同步里面有一个概念 就是 全部同步 需要n+1台机器同步成功再返回ack 就是n台机器挂掉了最少还有一台存活,半数同步的必须 2n+1 台机器同步成功后再返回ack 就是n台机器挂掉了最少还有n+1台机器存活 因为他是 半数同步的所以需要n+1个follower 同步成功,kafka为此选了全部同步成功的,全部成功还有问题 假如有部分follower 处理很慢或者他挂了 岂不是 生产需要一直等待这个kafka返回ack。
kafka为了解决这个问题加了一个ISR,这个isr是做什么的呢?
主要就是选举哪些 follower同步成功了,当leader挂了,会从ISR里面选取一个follower提升级别为leader,不是所有的follower都能够提升为leader,只有ISR里面的follower才能晋升为leader,想进入到 ISR里面有两个概念就是一个是时间的同步数据,一个是条数的概念,但是后来版本把这两个其中一个给去掉了,就是那个条数的那个,为什么去掉主要是你假如设置在十条差距数据以外的就要被踢出ISR,假如现在消费者群发消息 一次发送15条数据,现在所有的follower都相差15条数据比设置为10的预值多了五,就会被踢出去,然后等follower同步完 10条数据后又被加回来,就会出现一个问题前脚你踢出去了紧跟着有加回来。
ack有一个应答机制:
0 ?生产者只管发送数据 不接受ack,会造成数据丢失 因为我都不知道这个leader的死活 有可能在网络连接的时候就挂掉了。
1 ?生产者发送数据leader写入成功后,返回ack,这个里面还是会丢数据,如果这个时候leader挂了,他的follower没有同步完数据然后提升为leader之前未同步数据就会丢失。
-1(ALL) 生产者发送数据到leader写入成功后再 等follower也写入成功后返回ack给生产者,这个里面有一个问题就是数据重复,什么样的时候会造成数据重复呢就是follower写入成功后刚要回传ack leader就挂了,这个时候生产者认为数据并没有发送成功,kafka这面会把follower晋升为leader 这个时候的leader已经同步完了但是生产者不知道,又重新发送一个一遍数据,就重复了。
关于数据重复kafka里面有一个 解决方案 就是 幂等性 的问题其实就是可以理解为去重,具体就是在生产者连接kafka的时候会生成一个pid 这个pid是 生产者ID不是进程id,关于幂等性只能存在与同一个连接里面才会有这个概念,他会根据偏移量去判断是否全部成功 成功后会检测消息是否已存在存在的不进行发送,这个幂等性是在ACK为-1的时候才会有这个概念,这个其实设置也非常简单就在配置文件的一个参数改为true就行了,默认会把ack的模式为-1。
故障细节处理
A 为leader 数据为1-10
B 为follower 已同步数据为 1-6
C 为follower 已同步数据为 1-8
假如leader挂掉了,B选举为leader了 c再去同步发现数据不一样一个是1-8 一个 是1-6 假如这个时候A恢复了 为1-10,这个时候他们的消息不等 消费者消费消息就会出现问题,kefka是用两个标识来处理的一个是HW(在所有消息队列里面最短的一个LEO)为HW,LEO(log end office)最后一个消息的偏移量,HW在选举为B的时候 他为1-6 他会发送命令 所有人给我截取到6 其余的数据都扔掉,消费者来消费消息也只会消费到HW所在对应的那一个偏移量,假如这个时候选取的是C同步数据为1-8,他的HW为6的数据上面 会发送指定 都给我截取到6 卡卡卡都截取了,再给我A和B再去询问是否有新数据 发现有 7-8 就会同步上去

?扫码关注公众号,每天推送不同的技术文章,公众号私聊获取学习资料,期待你我之间一起进步!?
总结:如有遗漏的地方欢迎大家来补充!