1.mysql���ܹ�
1.���Ӳ�
2.�����
3.�����
4.�洢��
2.mysql�洢����
| �Ա����� | MyISAM | InnoDB |
|---|---|---|
| ����� | ��֧�� | ֧�� |
| ���� | ��֧�� | ֧�� |
| ��� | ���� | ���� |
| ���� | ֻ��������,��������ʵ���� | ������������,��������ʵ����,���ڴ�Ҫ��ϸ�,�ڴ��С�������о����Ե�Ӱ�� |
| ���ռ� | С | �� |
| ��ע�� | ���� | ���� |
| Ĭ�ϰ�װ | Y | Y |
3.join����
1.A+AB
select <select_list> from tableA a left [outer] join tableB b on a.key = b.key;
2.AB+B
select <select_list> from tableA a right [outer] join tableB b on a.key = b.key;
3.A-A^B
select <select_list> from tableA a left [outer] join tableB b on a.key = b.key where b.key is null;
4.B-A^B
select <select_list> from tableA a right [outer] join tableB b on a.key = b.key where a.key is null;
5.A^B
select <select_list> from tableA a inner join tableB b on a.key = b.key;
6.A��B
select <select_list> from tableA a full [outer] join tableB b on a.key = b.key;
7.A+B-A^B
select <select_list> from tableA a full [outer] join tableB b on a.key = b.key where a.key is null or b.key is null;
3.����
1.��������֪ʶ
- ������һ���ź���Ŀ��ٲ������ݽṹ
- B������
- ����:
1)����
2)����
1.����
- ������ݵļ���Ч��
- �������ݵ�����ɱ�
2.����
- ռ�ÿռ�
- ���ͱ������ٶ�
3.��������
- ��ֵ����
- Ψһ����
- ��������
4.�����ṹ
- BTree����
- Hash����
- full-textȫ������
- R-Tree����
2.Explain
1.��ʲô
2.�ܸ���
- ���Ķ�ȡ����
- ���ݶ�ȡ�����IJ�������
- ��Щ��������ʹ��
- ��Щ������ʵ��ʹ��
- ��֮�������
- ÿ�ű��ж����б��Ż�����ѯ
3.��ô��
explain select * from tableName;
4.ִ�мƻ���������Ϣ
- id
1)id��ͬ,ִ��˳�����϶���
2)id��ͬ,id������ȼ�����,��ִ��
3)id��ͬ����ͬͬʱ���� - select_type
1)SIMPLE:��ѯ
2)PRIMARY:������ѯ
3)SUBQUERY:�Ӳ�ѯ
4)DERIVED:����
5)UNION:
6)UNION RESULT: - table
- type:��������
1)ALL:ȫ��ɨ��
2)index:Full Index Scan,index��ALL����Ϊ,indexֻ����������

3)range:ֻ����������Χ����,ʹ��һ��������ѡ����


4)ref:��Ψһ������ɨ��,����ƥ��ij������ֵ��������

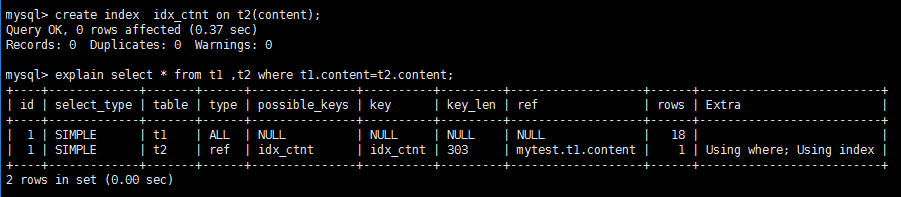
5)eq_ref:Ψһ������ɨ��,����ÿ��������,����ֻ��һ����¼��֮ƥ��,������primary key��unique ����ɨ��

6)const:��ʾͨ������һ���ҵ�,������primary key��unique����

7)system:��ֻ��һ�м�¼,���Բ�����
�������з�������,���ϵ���Խ��Խ��
-
possible_keys
��ʾ����Ӧ�������ű��е�����,һ��������
��ѯ�漰�����ֶ�������������,������������г�,����һ������ѯʵ��ʹ�� -
key
ʵ��ʹ�õ�����,���Ϊnull,��û��ʹ������
��ѯ����ʹ���˸�������,���������������key�б���
��������:��ѯ�ֶκͽ�������������˳��һ��
�Ա���ͼ���� sql ��䡣�� key ��ֵ:����ѯ����ijһ�ֶ�ʱ,���Ǹ��ֶ�������ʱ,key ֵ����ʾΪ����:

-
key_len
��ʾ������ʹ�õ��ֽ���,��ͨ�����м������ѯ��ʹ�õ��������ȡ��ڲ���ʧ��ȷ�Ե������,����Խ��Խ�á�
key_len��ʾ��ֵΪ�����ֶε������ܳ���,����ʵ��ʹ�ó���,��key_len�Ǹ��ݱ��������ó���,����ͨ�����ڼ��������� -
ref
��ʾ��������һ�б�ʹ����,������ܵĻ�,��һ����������Щ�л��������ڲ��������ϵ�ֵ -
rows
���ݱ�ͳ����Ϣ������ѡ�����,���¹�����ҵ�����ļ�¼��Ҫ��ȡ������ -
Extra
�������ʺ�������������ʾ��ʮ����Ҫ�Ķ�����Ϣ
1)Using filesort:�ļ�������
mysql�������ʹ��һ���ⲿ����������,�����ǰ��ձ��ڵ�����˳����ж�ȡ��
mysql��������������ɵ����������Ϊ���ļ�����
����filesort�����:

�Ż���,���ٳ���filesort�����:(�� ename ����������)

2)Using temporary:
ʹ������ʱ�������м���,mysql�ڶԲ�ѯ�������ʱʹ����ʱ��������������order by�ͷ����ѯgroup by
�Ż�ǰ���� using temporary �� using filesort

create index idx_deptno_ename on emp(deptno,ename) ����
�Ż�ǰ���ڵ� using temporary �� using filesort ����,���ܷ������Ա仯:

3)Using index
��ʾ��Ӧ��select������ʹ���˸�������(Covering Index),��������˱���������,Ч�ʲ���!
���ͬʱ����using where,��������������ִ��������ֵ�IJ���;
���û��ͬʱ����using where,��������ֻ��������ȡ���ݶ�����������ִ�в��ҡ�
4)Using where
����ʹ����where����
5)Using join buffer
ʹ�������ӻ���:
6)impossible where
where�Ӿ��ֵ����false,����������ȡ�κ�Ԫ��

7)select tables optimized away
��û��GROUPBY�Ӿ�������,���������Ż�MIN/MAX��������
����MyISAM�洢�����Ż�COUNT(*)����,���صȵ�ִ�н��ٽ��м���,
��ѯִ�мƻ����ɵĽμ�����Ż���
8)distinct
�Ż�distinct����,���ҵ���һ��ƥ���Ԫ���ֹͣ����ͬ��ֵ�Ķ���
3.�����Ż�
1.�����Ż�
####1.�������
CREATE TABLE IF NOT EXISTS `article` (
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES
(1, 1, 1, 1, '1', '1'),
(2, 2, 2, 2, '2', '2'),
(1, 1, 3, 3, '3', '3');
2.��������
����:#��ѯ category_id Ϊ1 �� comments ���� 1 �������,views ���� article_id��
1.����Ȼ,type �� ALL,����������Extra �ﻹ������ Using filesort,Ҳ�����������Ż��DZ����

2.��һ���Ż�:
ALTER TABLE `article` ADD INDEX idx_article_ccv ( `category_id` , `comments`, `views` );
create index idx_article_ccv on article(category_id,comments,views);
EXPLAIN SELECT id,author_id FROM `article` WHERE category_id = 1 AND comments >1 ORDER BY views DESC LIMIT 1;

-������һ���Ż�:
type ����� range,���ǿ������ܵġ����� extra ��ʹ�� Using filesort ���������ܵġ�
���������Ѿ�����������,Ϊɶû����?
������Ϊ���� BTree �����Ĺ���ԭ������:
������ category_id,
���������ͬ�� category_id �������� comments,���������ͬ�� comments �������� views��
�� comments �ֶ������������ﴦ���м�λ��ʱ,
��comments > 1 ������һ����Χֵ(��ν range),
MySQL �����������ٶԺ���� views ���ֽ��м���,�� range ���Ͳ�ѯ�ֶκ����������Ч��
3.�ڶ����Ż�:
#ɾ����һ�ν���������
DROP INDEX idx_article_ccv ON article;
#��2���½�����
#ALTER TABLE `article` ADD INDEX idx_article_cv ( `category_id` , `views` ) ;
create index idx_article_cv on article(category_id,views);

���Կ���,type ��Ϊ�� ref,Extra �е� Using filesort Ҳ��ʧ��,����dz����롣
Backward index scan(����ɨ��): 8.0 �汾�������ԡ������Ȳ��о�,����Ȥ��ͬѧ���Կ�����ƪ����
2.�����Ż�
1.�������
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
2.��������
1.type ��All
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

2.���е�һ���Ż�,�����������ұ�
ALTER TABLE `book` ADD INDEX Y ( `card`);

- ����:
���Կ����ڶ��е� type ��Ϊ�� ref,rows ��Ϊ1,�Ż��Ƚ����ԡ�
���������������Ծ����ġ�LEFT JOIN ��������ȷ����δ��ұ�������,���һ������,
�����ұ������ǵĹؼ���,һ����Ҫ����������
3.���еڶ����Ż�,�������������
DROP INDEX Y ON book;
ALTER TABLE class ADD INDEX X (card);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

- ����:
�����ӽ������û�������Ż� - �����ϰ����ó�����,���������������ұ�;�����������������
3.�����Ż�
- ͬ�����Ż�
4.����
- ��֤����������join�ֶ��Ѿ�������
- left join ʱ,ѡ��С����Ϊ������,�����Ϊ����������
- inner join ʱ,mysql���Լ������С������ı�ѡΪ��������
- �Ӳ�ѯ������Ҫ���ڱ�������,�п���ʹ�ò���������
5.����ʧЧ
- ȫֵƥ�����
- �����ǰ����:��������˶���,Ҫ��������ǰ����ָ���Dz�ѯ������������ǰ�п�ʼ���������������е���;
- ���������������κβ���(���㡢������(�Զ������ֶ�)����ת��),����ᵼ������ʧЧ
- �洢���治��ʹ���������з�Χ�����ұߵ���
- ����ʹ�ø�������
- mysql��ʹ�ò����ڵ�ʱ����ʹ������,�ᵼ��ȫ��ɨ��
- is null,is not nullҲ��ʹ������
- like��ͨ�����ͷ(%abc��)�ᵼ������ʧЧ
�Cͨ������������� - �ַ������ӵ����Żᵼ������ʧЧ:��Ϊ��������ʽ����ת��
- ����or,����������ʱ�ᵼ������ʧЧ
6.����
- ���ڵ�������,����ѡ����Ե�ǰquery��������õ�����
- ��ѡ�����������ʱ��,��ǰquery�й�������õ��ֶ��������ֶ�˳����,λ��Խ��ǰԽ��
- ��ѡ�����������ʱ��,����ѡ���������ǰquery�е�where�Ӿ��и����ֶε�����
- ������ͨ������ͳ����Ϣ�͵���query��д�����ﵽѡ�����������Ŀ��
7.��ԶС���������
- in
- exists
����ѡ��in����exists,ֻ����ѭС���������ԭ��
8.order by�ؼ����Ż�
- ����ʹ��Index��ʽ����,����ʹ��FileSort��ʽ����
1.����
CREATE TABLE tblA(
id int primary key not null auto_increment,
age INT,
birth TIMESTAMP NOT NULL,
name varchar(200)
);
INSERT INTO tblA(age,birth,name) VALUES(22,NOW(),'abc');
INSERT INTO tblA(age,birth,name) VALUES(23,NOW(),'bcd');
INSERT INTO tblA(age,birth,name) VALUES(24,NOW(),'def');
CREATE INDEX idx_A_ageBirth ON tblA(age,birth,name);
SELECT * FROM tblA;
2.����
- ����һ

- ������

3.mysql����ʽ
MySQL֧�ֶ��ַ�ʽ������,FileSort��Index,IndexЧ�ʸ�.
��ָMySQLɨ�����������������FileSort��ʽЧ�ʽϵ͡�
4.ORDER BY���������,��ʹ��Index��ʽ����
- ORDER BY ���ʹ����������ǰ��
- ʹ��Where�Ӿ���Order BY�Ӿ����������������������ǰ��
- where�Ӿ���������������ķ�Χ��ѯ(��explain�г���range)�ᵼ��order by ����ʧЧ��
4.�ܽ�

5.���������������,filesort�������㷨
1.˫·����
- ��ȡ��ָ���order by��,�����ǽ�������,Ȼ��ɨ���Ѿ�����õ��б�,�����б��е�ֵ���´��б��ж�ȡ��Ӧ���������
- �Ӵ���ȡ�����ֶ�,��buffer��������,�ٴӴ���ȡ�����ֶΡ�
ȡһ������,Ҫ�Դ��̽���������ɨ��,������֪,I\O�Ǻܺ�ʱ��,������mysql4.1֮��,�����˵ڶ��ָĽ����㷨,���ǵ�·����
2.��·����
- �Ӵ��̶�ȡ��ѯ��Ҫ��������,����order by����buffer�����ǽ�������,Ȼ��ɨ���������б��������,����Ч�ʸ���һЩ,�����˵ڶ��ζ�ȡ���ݡ����Ұ����IO�����˳��IO,��������ʹ�ø���Ŀռ�,��Ϊ����ÿһ�ж��������ڴ����ˡ�
- ���ڵ�·�Ǻ����,������Ժù�˫·;�����õ�·�����һЩ����:
��sort_buffer��,����B�ȷ���AҪ��ռ�úܶ�ռ�,��Ϊ����B�ǰ������ֶζ�ȡ��, �����п���ȡ�������ݵ��ܴ�С������sort_buffer������,����ÿ��ֻ��ȡsort_buffer������С������,��������(����tmp�ļ�,��·�ϲ�),������ȡȡsort_buffer������С,���š����Ӷ����I/O��������ʡһ��I/O����,���������˴�����I/O����,�����ò���ʧ��
3.�Ż�����
- ����sort_buffer_size����������
- ����max_length_for_sort_data����������
- ȥ��select ���治��Ҫ���ֶ�
- why?
1) Order byʱselect * ��һ�����ֻQuery��Ҫ���ֶ�, ���dz���Ҫ���������Ӱ����:
1.1 ��Query���ֶδ�С�ܺ�С��max_length_for_sort_data ���������ֶβ��� TEXT|BLOB ����ʱ,���øĽ�����㷨������·����, ���������㷨������·����
1.2 �����㷨�����ݶ��п��ܳ���sort_buffer������,����֮��,�ᴴ��tmp�ļ����кϲ�����,���¶��I/O,�����õ�·�����㷨�ķ��ջ����һЩ,����Ҫ���sort_buffer_size��
2)������� sort_buffer_size
�����������㷨,�����������������Ч��,��Ȼ,Ҫ����ϵͳ������ȥ���,��Ϊ������������ÿ�����̵�
3)������� max_length_for_sort_data
����������, �������øĽ��㷨�ĸ��ʡ�����������̫��,��������������sort_buffer_size�ĸ��ʾ�����,����֢״�ǸߵĴ���I/O��͵͵Ĵ�����ʹ����.��
9.group by�ؼ����Ż�
- group byʵ�������������з���,�����������������ǰ
- ����ʹ��������,����max_length_for_sort_data����������+����sort_buffer_size����������
- where����having,��д��where���������Ͳ�Ҫȥhaving���ˡ�
4.��ѯ��ȡ����
1.����ѯ��־
- MySQL������ѯ��־��MySQL�ṩ��һ����־��¼,��������¼��MySQL����Ӧʱ�䳬����ֵ�����,����ָ����ʱ�䳬��long_query_timeֵ��SQL,��ᱻ��¼������ѯ��־�С�
- long_query_time��Ĭ��ֵΪ10,��˼������10�����ϵ���䡣
- �������鿴��ЩSQL���������ǵ��������ʱ��ֵ,����һ��sqlִ�г���5����,���Ǿ�����SQL,ϣ�����ռ�����5���sql,���֮ǰexplain����ȫ�������
1.˵��
Ĭ�������,MySQL���ݿ�û�п�������ѯ��־,��Ҫ�����ֶ����������������
��Ȼ,������ǵ�����Ҫ�Ļ�,һ�㲻���������ò���,��Ϊ��������ѯ��־������ٴ���һ��������Ӱ�졣����ѯ��־֧�ֽ���־��¼д���ļ�
2.�鿴�Ƿ�������ο���
- Ĭ�������slow_query_log��ֵΪOFF,��ʾ����ѯ��־�ǽ��õ�,
����ͨ������slow_query_log��ֵ������
SHOW VARIABLES LIKE '%slow_query_log%';
- ʹ��set global slow_query_log=1����������ѯ��־ֻ�Ե�ǰ���ݿ���Ч,���MySQL���������ʧЧ
set global slow_query_log=1;
- ���Ҫ������Ч,�ͱ����������ļ�my.cnf(����ϵͳ����Ҳ�����)
��my.cnf�ļ�,[mysqld]�����ӻ��IJ���
slow_query_log ��slow_query_log_file��,Ȼ������MySQL�����������������������ý�my.cnf�ļ�
slow_query_log =1
slow_query_log_file=/var/lib/mysql/atguigu-slow.log
��������ѯ�IJ���slow_query_log_file ,��ָ������ѯ��־�ļ��Ĵ��·��,ϵͳĬ�ϻ��һ��ȱʡ���ļ�host_name-slow.log(���û��ָ������slow_query_log_file�Ļ�)
3.��ô����������ѯ��־��,ʲô����SQL�Ż��¼������ѯ��־������?
������ɲ���long_query_time����,Ĭ�������long_query_time��ֵΪ10��,
����:SHOW VARIABLES LIKE ��long_query_time%��;
����ʹ��������,Ҳ������my.cnf���������ġ�
��������ʱ�����õ���long_query_time�����,�����ᱻ��¼������Ҳ����˵,
��mysqlԴ�������жϴ���long_query_time,���Ǵ��ڵ��ڡ�
4.case
- �鿴��ǰ����������
SHOW VARIABLES LIKE 'long_query_time%';
- ����������ֵʱ��
ʹ������
set global long_query_time=1
��Ϊ��ֵ��1���ӵľ�����sql

�ĺ���long_query_time��û�иı䡣 - Ϊʲô���ú����仯?
��Ҫ�������ӻ��¿�һ���Ự���ܿ�����ֵ�� SHOW VARIABLES LIKE ��long_query_time%��;
����ͨ��set session long_query_time=1���ı䵱ǰsession����; - ��¼��sql
select sleep(4);
select sleep(2);

- ��ѯ��ǰϵͳ���ж�������sql
show global status like '%Slow_queries%';
5.��־��������mysqldumpslow
- �鿴mysqldumpslow�İ�����Ϣ

- �������òο�
�õ����ؼ�¼������10��SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
�õ����ʴ�������10��SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
�õ�����ʱ�������ǰ10�����溬�������ӵIJ�ѯ���
mysqldumpslow -s t -t 10 -g ��left join�� /var/lib/mysql/atguigu-slow.log
���⽨����ʹ����Щ����ʱ��� | ��more ʹ�� ,�����п��ܳ��ֱ������
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
6.�������ݽű�
1.����
#1 ����dept
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=INNODB DEFAULT CHARSET=UTF8 ;
#2 ����emp
CREATE TABLE emp
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*���*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*����*/
job VARCHAR(9) NOT NULL DEFAULT "",/*����*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*�ϼ����*/
hiredate DATE NOT NULL,/*��ְʱ��*/
sal DECIMAL(7,2) NOT NULL,/*нˮ*/
comm DECIMAL(7,2) NOT NULL,/*����*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*���ű��*/
)ENGINE=INNODB DEFAULT CHARSET=UTF8 ;
2.����log_bin_trust_function_creators
��������,���籨��:This function has none of DETERMINISTIC��
���ڿ���������ѯ��־,��Ϊ���ǿ����� bin-log, ���Ǿͱ���Ϊ���ǵ�functionָ��һ��������
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;
���������˲����Ժ�,���mysqld����,���������ֻ���ʧ,
���÷���:
windows��my.ini[mysqld]����log_bin_trust_function_creators=1
linux�� /etc/my.cnf��my.cnf[mysqld]����log_bin_trust_function_creators=1
3.��������,��֤ÿ�����ݶ���ͬ
- ��������ַ���
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN ##������ʼ
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
##����һ�� �ַ��ܳ���Ϊ 100 �ı��� chars_str ,Ĭ��ֵ
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
##ѭ����ʼ
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
##concat ���Ӻ��� ,substring(a,index,length) ��index����ʼ��ȡ
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
- ����������ű��
#��������������ű��
DELIMITER $$
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100+RAND()*10);
RETURN i;
END $$
4.�����洢����
- ������emp���в������ݵĴ洢����
DELIMITER $$
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 ��autocommit���ó�0 ;���ִ��Ч��
SET autocommit = 0;
REPEAT ##ѭ��
SET i = i + 1;
INSERT INTO emp(empno, ename ,job ,mgr ,hiredate ,sal ,comm ,deptno ) VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),FLOOR(1+RAND()*20000),FLOOR(1+RAND()*1000),rand_num());
UNTIL i = max_num ##ֱ�� ����Ҳ��һ��ѭ��
END REPEAT; ##�������������ѭ��
COMMIT; ##ִ����ɺ�һ���ύ
END $$
- ������dept���в������ݵĴ洢����
#ִ�д洢����,��dept�������������
DELIMITER $$
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept (deptno ,dname,loc ) VALUES (START +i ,rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
5.���ô洢����
- dept
DELIMITER ; #��������־���� ;
CALL insert_dept(100,10);
- emp
DELIMITER ; #��������־���� ;
CALL insert_emp(100001,500000);
7.show Profile
1.ʲô��show Profile
��mysql�ṩ��������������ǰ�Ự�����ִ�е���Դ�����������������SQL�ĵ��ŵIJ���
2.����
3.Ĭ�������,�������ڹر�״̬,���������15�ε����н��
4.����
- ������ǰ��mysql�汾�Ƿ�֧��show Profile
show variables like 'profiling';
- ��������,Ĭ���ǹر�,ʹ��ǰ��Ҫ����
show variables like 'profiling';
set profiling=1;
- ������sql
select * from emp group by id%10 limit 150000;
select * from emp group by id%20 order by 5
- �鿴���
show profiles;

- ���SQL,show profile cpu,block io for query n (nΪ��һ��ǰ�������SQL���ֺ���);
show profile cpu,block io for query n;

-
������ע
type:
| ALL --��ʾ���еĿ�����Ϣ
| BLOCK IO --��ʾ��IO��ؿ���
| CONTEXT SWITCHES --�������л���ؿ���
| CPU --��ʾCPU��ؿ�����Ϣ
| IPC --��ʾ���ͺͽ�����ؿ�����Ϣ
| MEMORY --��ʾ�ڴ���ؿ�����Ϣ
| PAGE FAULTS --��ʾҳ�������ؿ�����Ϣ
| SOURCE --��ʾ��Source_function,Source_file,Source_line��صĿ�����Ϣ
| SWAPS --��ʾ����������ؿ�������Ϣ -
�ճ�������Ҫע��Ľ���
1)converting HEAP to MyISAM ��ѯ���̫��,�ڴ涼���������������ϰ��ˡ�
2)Creating tmp table ������ʱ��:�������ݵ���ʱ��,������ɾ��
3)Copying to tmp table on disk ���ڴ�����ʱ�����Ƶ�����,Σ��!!!
4)locked
8.ȫ�ֲ�ѯ��־
- ��������
��mysql��my.cnf��,��������:
#����
general_log=1
��¼��־�ļ���·��
general_log_file=/path/logfile
#�����ʽ
log_output=FILE - ��������
set global general_log=1;
#ȫ����־���Դ�ŵ���־�ļ���,Ҳ���Դ�ŵ�Mysqlϵͳ���С���ŵ���־�����ܸ���һЩ,�洢������
set global log_output=��TABLE��;
�˺� ,������д��sql���,�����¼��mysql�����general_log��,���������������鿴
select * from mysql.general_log; - ������Ҫ���������������������
5.mysql������
5.1����
���Ǽ����Э��������̻��̲߳�������ijһ��Դ�Ļ��ơ�
�����ݿ���,����ͳ�ļ�����Դ(��CPU��RAM��I/O��)����������,����Ҳ��һ�ֹ������û���������Դ����α�֤���ݲ������ʵ�һ���ԡ���Ч�����������ݿ��������һ������,����ͻҲ��Ӱ�����ݿⲢ���������ܵ�һ����Ҫ���ء�������Ƕ���˵,�������ݿ�����Ե�������Ҫ,Ҳ���Ӹ��ӡ�
5.2���ķ���
5.2.1�Ӷ����ݲ��������ͷ�
- ����(������):���ͬһ������,�������������ͬʱ���ж����ụ��Ӱ��
- д��(������):��ǰд����û�����ǰ,�����������д���Ͷ���
5.2.2�Ӷ����ݲ��������ȷ�
??Ϊ�˾�����������ݿ�IJ�����,ÿ�����������ݷ�ΧԽСԽ��,������ÿ��ֻ������ǰ���������ݵķ�����õ����IJ�����,���ǹ������Ǻܺ���Դ������(�漰��ȡ,���,�ͷ����ȶ���),������ݿ�ϵͳ��Ҫ�ڸ߲�����Ӧ��ϵͳ�������������ƽ��,�����Ͳ����ˡ�������(Lock granularity)���ĸ��
??һ����߹�����Դ�������Եķ�ʽ���������������ѡ���ԡ�����ֻ������Ҫ�ĵIJ�������,���������е���Դ��������ķ�ʽ��,ֻ�Ի��ĵ�����Ƭ���о�ȷ���������κ�ʱ��,�ڸ�������Դ��,������������Խ��,��ϵͳ�IJ����̶�Խ��,ֻҪ�֮�䲻������ͻ���ɡ�
- ����
- ����
5.3����(ƫ��)
5.3.1�ص�
??ƫ��MyISAM�洢����,����С,������;������;�������ȴ�,��������ͻ�ĸ������,��������͡�5.3.2��������
5.3.2.1����sql
create table mylock( id int not null primary key auto_increment, name varchar(20) )engine myisam; insert into mylock(name) values('a'); insert into mylock(name) values('b'); insert into mylock(name) values('c'); insert into mylock(name) values('d'); insert into mylock(name) values('e'); select * from mylock; #�ֶ����ӱ��� lock table ������1 read(write),������2 read(write),����; #�鿴���ϼӹ����� show open tables; #�ͷű��� unlock tables;
####5.3.2.2 �Ӷ���
| session_1 | session_2 |
|---|---|
��ñ�mylock��READ���� | �����ն� |
��ǰsession���Բ�ѯ�ñ���¼ | ����sessionҲ���Բ�ѯ�ñ��ļ�¼ |
��ǰsession���ܲ�ѯ����û�������ı� | ����session���Բ�ѯ���߸���δ�����ı�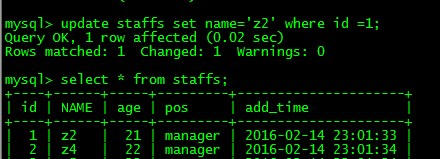 |
��ǰsession�в�����߸��������ı�������ʾ����: | ����session������߸�����������һֱ�ȴ������: |
�ͷ���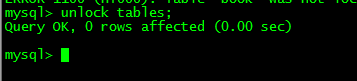 | Session2�����,����������: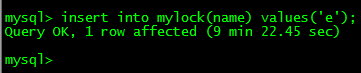 |
5.3.2.3 ���
��ñ�mylock��WRITE����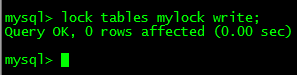 | �����ն� |
��ǰsession���������IJ�ѯ+����+�������������ִ��: | ����session���������IJ�ѯ������,��Ҫ�ȴ������ͷ�: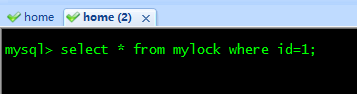 ������ǰ,���session2�����ݻ���,�����Ժ�,����ס�ı��������ı�������session2���Զ�����������,һ�����ݷ����ı�,���潫ʧЧ,������������ס�� ������ǰ,���session2�����ݻ���,�����Ժ�,����ס�ı��������ı�������session2���Զ�����������,һ�����ݷ����ı�,���潫ʧЧ,������������ס�� |
�ͷ���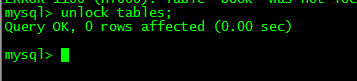 | Session2�����,��ѯ����: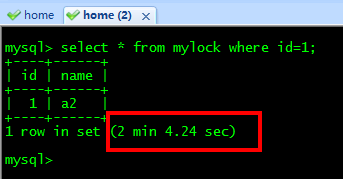 |
5.3.2.4 ����
MyISAM��ִ�в�ѯ���(SELECT)ǰ,���Զ����漰�����б��Ӷ���,��ִ����ɾ�IJ���ǰ,���Զ����漰�ı���д����
����:
����ϱ�,���Զ�MyISAM�����в���,�����������:
1����MyISAM���Ķ�����(�Ӷ���),���������������̶�ͬһ���Ķ�����,����������ͬһ����д����ֻ�е������ͷź�,�Ż�ִ���������̵�д������
2����MyISAM����д����(��д��),�������������̶�ͬһ���Ķ���д����,ֻ�е�д���ͷź�,�Ż�ִ���������̵Ķ�д������
�����֮,���Ƕ���������д,���Dz������������д�����Ѷ���д������
5.3����(ƫд)
5.3.1 ����sql
create table test_innodb_lock (
a int(11),
b varchar(16)
)engine=innodb;
create index test_innodb_a_ind on test_innodb_lock(a);
create index test_innodb_lock_b_ind on test_innodb_lock(b);
insert into test_innodb_lock values(1,'b2');
insert into test_innodb_lock values(3,'3');
insert into test_innodb_lock values(4,'4000');
insert into test_innodb_lock values(5,'5000');
insert into test_innodb_lock values(6,'6000');
insert into test_innodb_lock values(7,'7000');
insert into test_innodb_lock values(8,'8000');
insert into test_innodb_lock values(9,'9000');
insert into test_innodb_lock values(1,'b1');
select * from test_innodb_lock;
5.3.2 ������������ʾ
| Session_1 | Session_2 |
|---|---|
 | 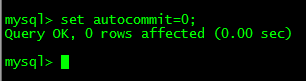 |
���µ��Dz��ύ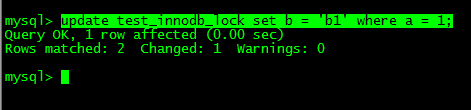 | Session_2������,ֻ�ܵȴ� |
�ύ���� | �������,������������ |
5.3.3 ������������������
| Session_1 | Session_2 |
|---|---|
| �������,�����������Ե���,���Ӱ��,һ��2000��һ��3000 | |
 |  |
| ������column�ֶ�b���潨������,���û������ʹ��,�ᵼ����������� | |
����û�ӵ����ŵ�������ʧЧ,�����Զ�����ת��,������������� | ������,�ȴ���ֻ��Session_1�ύ����������,��ɸ��� |
5.3.4 ��϶��Σ��
??�������÷�Χ�������������������������,����������������ʱ,InnoDB��������������������ݼ�¼�����������;���ڼ�ֵ��������Χ�ڵ��������ڵļ�¼,��������϶(GAP)��,
??InnoDBҲ����������϶������,���������ƾ�����ν�ļ�϶��(GAP Lock)��
- ��:
??��ΪQueryִ�й�����ͨ������Χ���ҵĻ�,��������������Χ�����е�������ֵ,��ʹ�����ֵ�������ڡ�
??��϶����һ���Ƚ�����������,���ǵ�����һ����Χ��ֵ֮��,��ʹijЩ�����ڵļ�ֵҲ�ᱻ��������,�������������ʱ��������������ֵ��Χ�ڵ��κ����ݡ���ijЩ����������ܻ��������ɺܴ��Σ��
| Session_1 | Session_2 |
|---|---|
 | ��������,��ʱ���ܲ��� |
| commit; | �������,��ɲ��� |
5.3.4 ��������
??Innodb�洢��������ʵ�����м�����,��Ȼ���������Ƶ�ʵ�ַ�����������������Ŀ��ܱȱ���������Ҫ����һЩ,���������岢��������������ҪԶԶ����MyISAM�ı��������ġ���ϵͳ�������ϸߵ�ʱ��,Innodb���������ܺ�MyISAM��Ⱦͻ��бȽ����Ե������ˡ�
??����,Innodb���м�����ͬ��Ҳ���������һ��,������ʹ�ò�����ʱ��,���ܻ���Innodb���������ܱ��ֲ������ܱ�MyISAM��,�������ܻ���
5.3.5 ��������
- ͨ�����InnoDB_row_lock״̬����������ϵͳ�ϵ��������������
show status like 'innodb_row_lock%';
- �Ը���״̬����˵������:
Innodb_row_lock_current_waits:��ǰ���ڵȴ�����������;
Innodb_row_lock_time:��ϵͳ����������������ʱ�䳤��;
Innodb_row_lock_time_avg:ÿ�εȴ�����ƽ��ʱ��;
Innodb_row_lock_time_max:��ϵͳ���������ڵȴ����һ��������ʱ��;
Innodb_row_lock_waits:ϵͳ�����������ܹ��ȴ��Ĵ���;
������5��״̬����,�Ƚ���Ҫ����Ҫ��
Innodb_row_lock_time_avg(�ȴ�ƽ��ʱ��),
Innodb_row_lock_waits(�ȴ��ܴ���)
Innodb_row_lock_time(�ȴ���ʱ��)�����
�����ǵ��ȴ������ܸ�,����ÿ�εȴ�ʱ��Ҳ��С��ʱ��,���Ǿ���Ҫ����ϵͳ��Ϊʲô������˶�ĵȴ�,Ȼ����ݷ����������ָ���Ż��ƻ���
������ͨ��
SELECT * FROM information_schema.INNODB_TRX;
����ѯ���ڱ���������sql��䡣
5.3.6 �Ż�����
- ���������������ݼ�����ͨ�����������,������������������Ϊ������
- �����ܽ��ټ�������,�����϶��
- �������������С,����������Դ����ʱ�䳤��
- ��סij�к�,������Ҫȥ������л��,�Ͻ���������ס����Ȼ���ͷŵ�����
- �漰��ͬ��������,���ڵ��ñ���˳��������һ�¡�
- ��ҵ�������������,�����ܵͼ����������
5.3ҳ��
??�����ͼ���ʱ����ڱ���������֮��;���������;�������Ƚ��ڱ���������֮��,������һ�㡣
6.���Ӹ���
6.1���ƵĻ���ԭ��
- slave���master��ȡbinlog����������ͬ��
- ������+ԭ��ͼ

MySQL���ƹ��̷ֳ�����:
1 master���ı��¼����������־(binary log)����Щ��¼���̽�����������־�¼�,binary log events;
2 slave��master��binary log events�����������м���־(relay log);
3 slave�����м���־�е��¼�,���ı�Ӧ�õ��Լ������ݿ��С� MySQL�������첽���Ҵ��л���