����Ŀ¼
- ��1�� ���ݿ��Ż����
- ��2�� SQL����Ż�
- ��3�� �����Ż�
- ��4�� ���ݿ�ṹ�Ż�
- ��5�� ϵͳ�����Ż�
- ��6�� ������Ӳ���Ż�
��1�� ���ݿ��Ż����
���ݿ��Ż���Ŀ��
�������ҳ����ʴ���
- �������ݿ�����timeout����ҳ��5xx����
- ��������ѯ���ҳ��������
- ������������������ύ
�������ݿ���ȶ���
- �ܶ����ݿ����ⶼ�����ڵ�Ч�IJ�ѯ�����
�Ż��û�����
- ����ҳ��ķ����ٶ�
- ���õ���վ��������
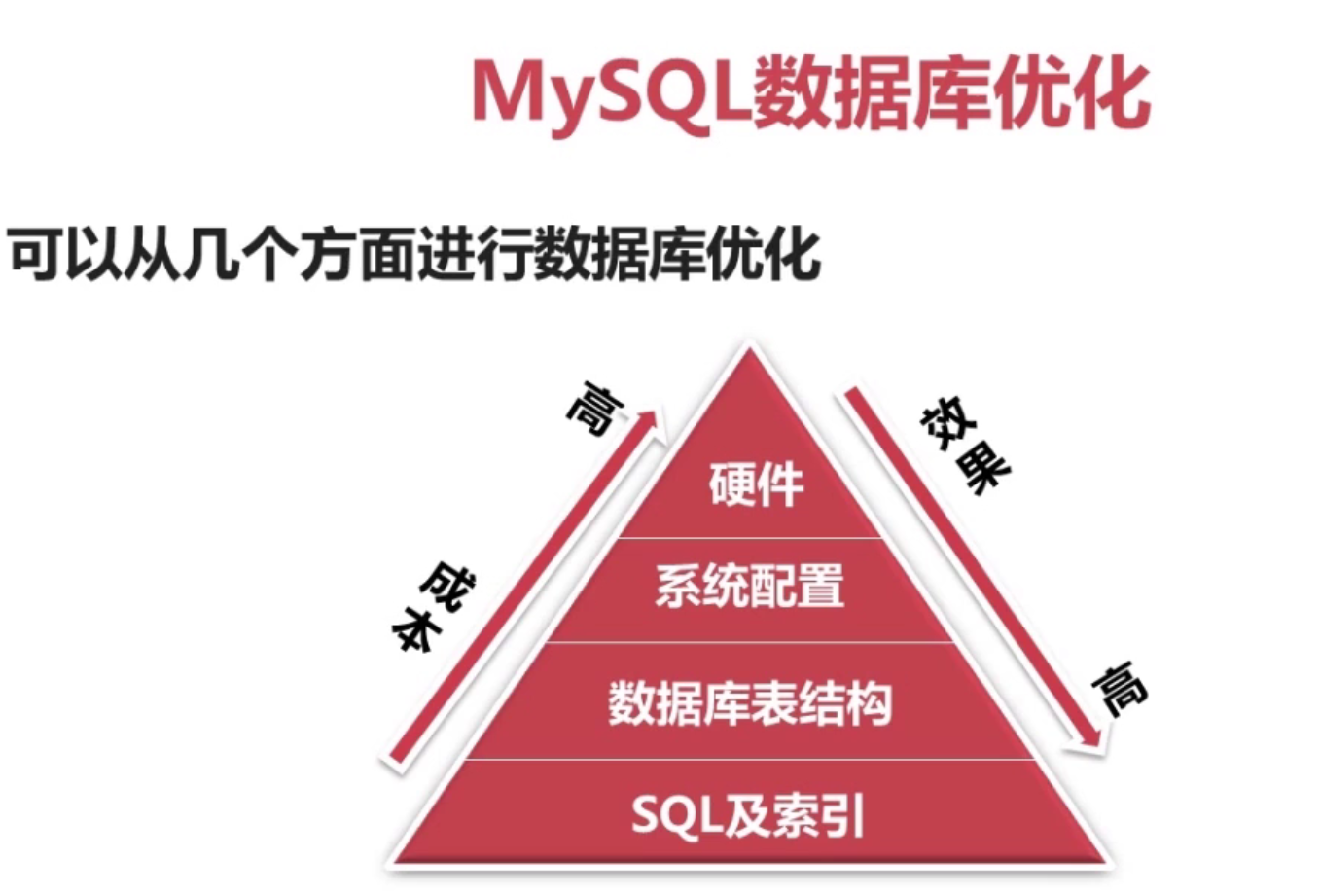
���ݿ��Ż��ķ�ʽ
1 SQL������(�����������,�����)
2 ���ݿ���ṹ(���ݷ�ʽ��Ʊ��ṹ)
3 ϵͳ����(linux��mysql���ļ��������Ƶ�)
4 Ӳ��(����ļ�io���ٶ�,���dzɱ����)
io���Ż� �����ܼ������� ,��sql����û���Ż���,����������������ѯ������,��������mysql���ڲ����������,����Ӳ���ٺ�Ч��Ҳ����
mysql���ں��������Ƶ�
��2�� SQL����Ż�
SELECT��� - �˳��:
1. SELECT
2. DISTINCT <select_list>
3. FROM <left_table>
4. <join_type> JOIN <right_table>
5. ON <join_condition>
6. WHERE <where_condition>
7. GROUP BY <group_by_list>
8. HAVING <having_condition>
9. ORDER BY <order_by_condition>
10.LIMIT <limit_number>
SELECT��� - ִ��˳��:
FROM
<����> # ѡȡ��,�����������ͨ���ѿ��������һ������
ON
<ɸѡ����> # �Եѿ��������������ɸѡ
JOIN <join, left join, right join...>
<join��> # ָ��join,�����������ݵ�on֮��������,����left join�Ὣ�����ʣ���������ӵ������
WHERE
<where����> # �������������ɸѡ
GROUP BY
<��������> # ����
<SUM()�ȾۺϺ���> # ����having�Ӿ�����ж�,����д������ۺϺ�����д��having�ж������
HAVING
<����ɸѡ> # �Է����Ľ�����оۺ�ɸѡ
SELECT
<���������б�> # ���صĵ��б�����group by�Ӿ���,�ۺϺ�������
DISTINCT
# ���ݳ���
ORDER BY
<��������> # ����
LIMIT
<��������>
2-1 ������
��ʾ���ݿ�˵��:
ʹ��MySQL�ṩ��sakila���ݿ�,����ͨ������URL��ȡ�����ʾ���ݿ�
http://dev.mysql.com/doc/index-other.html
sakila���ݿ�ı��ṹ��Ϣ����ͨ��������վ�鿴
http://dev.mysql.com/doc/sakila/en/sakila-installation.html
���ݿ����MySQL5.5�汾,��ͬMySQL�汾���Ż�����һ���IJ��
��������:
1.����sakila���ݿ�
http://dev.mysql.com/doc/index-other.html
��ѹ:
2.����
CMD ���������MySQL $> mysql -u root -p
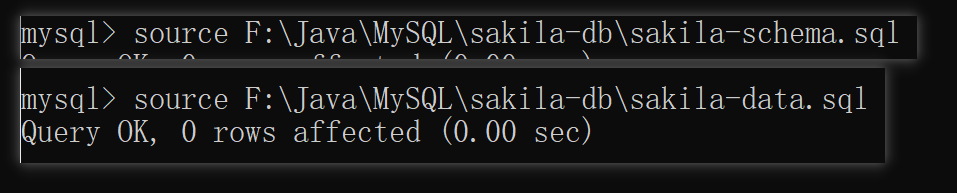
�������ݿ�ṹ
mysql> source /home/tom/mysql/sakila-schema.sql
������д�뵽���ݿ�
mysql> source /home/tom/mysql/sakila-db/sakila-data.sql
Linux��


mysql> select @@version;
��----------+
| @@version |
��----------+
| 5.7.23 |
��----------+
mysql> USE sakila;
Database changed
mysql> SHOW FULL TABLES;
+----------------------------+------------+
| Tables_in_sakila | Table_type |
+----------------------------+------------+
| actor | BASE TABLE |
| actor_info | VIEW |
| address | BASE TABLE |
| category | BASE TABLE |
| city | BASE TABLE |
| country | BASE TABLE |
| customer | BASE TABLE |
| customer_list | VIEW |
| film | BASE TABLE |
| film_actor | BASE TABLE |
| film_category | BASE TABLE |
| film_list | VIEW |
| film_text | BASE TABLE |
| inventory | BASE TABLE |
| language | BASE TABLE |
| nicer_but_slower_film_list | VIEW |
| payment | BASE TABLE |
| rental | BASE TABLE |
| sales_by_film_category | VIEW |
| sales_by_store | VIEW |
| staff | BASE TABLE |
| staff_list | VIEW |
| store | BASE TABLE |
+----------------------------+------------+
23 rows in set (0.01 sec)
mysql> SELECT COUNT(*) FROM film;
+----------+
| COUNT(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(*) FROM film_text;
+----------+
| COUNT(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.00 sec)
2-2 MySQL������־�Ŀ�����ʽ�ʹ洢��ʽ

SQL�������Ż�
��ز���˵��:
- show_query_log_file:������־�洢λ��
- log_queries_not_use_indexes:�Ƿ��û��ʹ�������IJ�ѯ��¼������ѯ��־��
- long_query_time:����������IJ�ѯ��¼������ѯ��־��
ʹ��MySQL������־����Ч�������SQL���м��
- show variables like ��slow_query_log��; //�鿴�Ƿ���������־
- set global slow_query_log_file = ��xxx�� //����������־���ļ���ַ
- set global log_queries_not_using_indexes=on; //�Ƿ��û��ʹ��sql������¼��������־��
- set global long_query_time=1; //����������־��ʱ��,��Ѱ�����������¼(��λ:��)
����:
show variables like ��slow_query_log��; //�鿴�Ƿ���������־
mysql> show variables like 'slow_query_log';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF | ֵ��OFF,˵��û�п����ù���
+----------------+-------+
1 row in set, 1 warning (0.00 sec)
�鿴�Ƿ�û�н��������IJ�ѯ��������ѯ��¼:
show variables like ��%log%��;
��ʾ�Ľ������һ��"log_queries_not_using_indexes"ֵΪoff, ˵��û�п��� ʹ������������:
set global log_queries_not_using_indexes=on; //�Ƿ��û��ʹ��sql������¼��������־��
mysql> set global log_queries_not_using_indexes=on;
Query OK, 0 rows affected (0.00 sec)
�鿴����ѯʱ������:
show variables like ��long_query_time��;
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
��������ѯʱ������:
set global long_query_time=0;
set global long_query_time=0; Ϊɶ��Ч��,�ٲ黹��ԭ����10
��֮��,�ȹر����ݿ�����,����������,�ٴβ�ѯ�Ϳ��Կ���ʵ���������˵ġ�
��������ѯ��־
set global slow_query_log=on;
mysql> set global slow_query_log=on;
�鿴����ѯ��־�ļ�λ��
show variables like ��slow%��;
mysql> show variables like 'slow%';
+---------------------+-------------------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | D:\development\MySQL5.7\data\LAPTOP-9GHMNQJ6-slow.log | ����
+---------------------+-------------------------------------------------------+
# Linux��
mysql> show variables like 'slow%';
+---------------------+-------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/cjbCentos01-slow.log |
+---------------------+-------------------------------------+
3 rows in set (0.00 sec)

2-3 MySQL������־��������֮mysqldumpslow
Windows�°�װʹ��mysqldumpslow
�����鰲װʹ��,���ܻᵼ��ijЩϵͳ����
Windows��ʹ��
D:\development\Strawberry\perl\bin>perl mysqldumpslow.pl -h
D:\development\Strawberry\perl\bin>perl mysqldumpslow.pl -h
Option h requires an argument
ERROR: bad option
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default(����ʽ)
al: average lock time(ƽ������ʱ��)
ar: average rows sent(ƽ�����ؼ�¼��)
at: average query time(ƽ����ѯʱ��)
c: count(���ʼ���)
l: lock time(����ʱ��)
r: rows sent(���ؼ�¼)
t: query time(��ѯʱ��)
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries(����ǰ��n������)
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string(����ƥ��ģʽ,��Сд������)
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
Linux ��ʹ��
mysqldumpslow -h �鿴�������ߵIJ���
mysqldumpslow���ߵ�ʹ��:
1��mysqldumpslow -t 3 ����ѯ��־�ļ�·�� | more //��ʾʹ��mysqldumpslow���߷���3������ѯ���
mysqldumpslow -t 3 /var/lib/mysql/cjbCentos01-slow.log | more
[root@cjbCentos01 mysql]# mysqldumpslow -t 3 /var/lib/mysql/cjbCentos01-slow.log | more
Reading mysql slow query log from /var/lib/mysql/cjbCentos01-slow.log
Count: 2 Time=0.00s (0s) Lock=0.00s (0s) Rows=2.0 (4), root[root]@localhost
show variables like 'S'
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost
select @@version_comment limit N
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
mysqldumpslow -h
2����������:
Count:ִ�е�����
Time: ִ�е�ʱ��
Lock: ����ʱ��
Rows: ����
��������Ϣ
SQL���ݵ�
2-4 MySQL������־��������֮pt-query-digest
��װpt-query-digest
����pt-query-disgest �� ��Ȩ �� ����ŵ�/usr/bin��:
wget percona.com/get/pt-query-digest
chmod u+x pt-query-digest
mv pt-query-digest /usr/bin/
������Ҫ�İ�װ��������:
yum install perl-DBI
yum install perl-DBD-MySQL
yum install perl-Time-HiRes
yum install perl-IO-Socket-SSL
yum install perl-Digest-MD5 #�ҵ���Ҫ�����
���߰�װ percona-toolkit ��
��Ҫ��װ����ð�װ�����:
wget http://www.percona.com/downloads/percona-toolkit/2.2.4/percona-toolkit-2.2.4.tar.gz
tar -zxvf percona-toolkit-2.2.4.tar.gz
cd percona-toolkit-2.2.4
perl Makefile.PL
make && make install
�������(Can't locate Time/HiRes.pm in @INC (@INC contains....)�Ļ�,
yum -y install perl-Time-HiRes ���� yum install -y perl-CPAN perl-Time-HiRes
ʹ�� pt-query-digest
ʹ�ð���: pt-query-digest --help
pt-query-digest�����Ҫѡ��
pt-query-digest [OPTIONS] [FILES] [DSN]
--create-review-table ��ʹ��--review�����ѷ���������������ʱ,���û�б����Զ�������
--create-history-table ��ʹ��--history�����ѷ���������������ʱ,���û�б����Զ�������
--filter �����������ѯ��ָ�����ַ�������ƥ����˺��ٽ��з���
--limit �����������ٷֱȻ�����,Ĭ��ֵ��20,����������20��������,�����50%������Ӧʱ��ռ�ȴӴ�С����,������ܺʹﵽ50%λ�ý�ֹ��
--host mysql��������ַ
--user mysql�û���
--password mysql�û�����
--history ������������浽����,��������Ƚ���ϸ,�´���ʹ��--historyʱ,���������ͬ�����,�Ҳ�ѯ���ڵ�ʱ���������ʷ���еIJ�ͬ,����¼�����ݱ���,����ͨ����ѯͬһCHECKSUM���Ƚ�ij���Ͳ�ѯ����ʷ�仯��
--review ������������浽����,�������ֻ�ǶԲ�ѯ�������в�����,һ�����͵IJ�ѯһ����¼,�Ƚϼ����´�ʹ��--reviewʱ,���������ͬ��������,�Ͳ����¼�����ݱ��С�
--output ��������������,ֵ������report(����������)��slowlog(Mysql slow log)��json��json-anon,һ��ʹ��report,�Ա����Ķ���
--since ��ʲôʱ�俪ʼ����,ֵΪ�ַ���,������ָ����ij����yyyy-mm-dd [hh:mm:ss]����ʽ��ʱ���,Ҳ�����Ǽ�һ��ʱ��ֵ:s(��)��h(Сʱ)��m(����)��d(��),��12h�ͱ�ʾ��12Сʱǰ��ʼͳ�ơ�
--until ��ֹʱ��,��ϡ�since���Է���һ��ʱ���ڵ�����ѯ��
����:
pt-query-digest /var/lib/mysql/cjbCentos01-slow.log | more
������ļ�:pt-query-digest show-log > slow_log.report
��������ݿ�� pt-query-digest show.log -review
h=127.0.0.1,D=test,p=root.P=3306,u=root,t=query_review
�Ccreate-reviewtable
�Creview-history t=hostname_show
pt-query-digest����ѯ��־�������������
����pt-query-digest������
��һ����:����ͳ�ƽ��
Overall:�ܹ��ж�������ѯ
Time range:��ѯִ�е�ʱ�䷶Χ
unique:Ψһ��ѯ����,���Բ�ѯ�������в������Ժ�,�ܹ��ж��ٸ���ͬ�IJ�ѯ
total:�ܼ� min:��С max:��� avg:ƽ��
95%:������ֵ��С��������,λ��λ��95%���Ǹ���,�����һ������вο���ֵ
median:��λ��,������ֵ��С��������,λ��λ���м��Ǹ���
# �ù���ִ����־�������û�ʱ��,ϵͳʱ��,�����ڴ�ռ�ô�С,�����ڴ�ռ�ô�С
# 340ms user time, 140ms system time, 23.99M rss, 203.11M vsz
# ����ִ��ʱ��
# Current date: Fri Nov 25 02:37:18 2016
# ���з������ߵ�������
# Hostname: localhost.localdomain
# ���������ļ���
# Files: slow.log
# ���������,Ψһ���������,QPS,������
# Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency ________________
# ��־��¼��ʱ�䷶Χ
# Time range: 2016-11-22 06:06:18 to 06:11:40
# ���� �ܼ� ��С ��� ƽ�� 95% �� �е�
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# ���ִ��ʱ��
# Exec time 3s 640ms 2s 1s 2s 999ms 1s
# ��ռ��ʱ��
# Lock time 1ms 0 1ms 723us 1ms 1ms 723us
# ���͵��ͻ��˵�����
# Rows sent 5 1 4 2.50 4 2.12 2.50
# select���ɨ������
# Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k
# ��ѯ���ַ���
# Query size 455 15 440 227.50 440 300.52 227.50
�ڶ�����:��ѯ����ͳ�ƽ��
Rank:������������,Ĭ�ϰ���ѯʱ�併������,ͨ���Corder-byָ��
Query ID:����ID,(ȥ������ո���ı��ַ�,����hashֵ)
Response:�ܵ���Ӧʱ��
time:�ò�ѯ�ڱ��η������ܵ�ʱ��ռ��
calls:ִ�д���,�����η����ܹ��ж������������͵IJ�ѯ���
R/Call:ƽ��ÿ��ִ�е���Ӧʱ��
V/M:��Ӧʱ��Variance-to-mean�ı���
Item:��ѯ����
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT
# 2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base
��������:ÿһ�ֲ�ѯ����ϸͳ�ƽ��
�������ѯ����ϸͳ�ƽ��,������ı����г���ִ�д����������С��ƽ����95%�ȸ���Ŀ��ͳ�ơ�
ID:��ѯ��ID��,����ͼ��Query ID��Ӧ
Databases:���ݿ���
Users:�����û�ִ�еĴ���(ռ��)
Query_time distribution :��ѯʱ��ֲ�, ������������ռ��,������1s-10s֮���ѯ������10s���ϵ�������
Tables:��ѯ���漰���ı�
Explain:SQL���
# Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802 ______
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: all events occurred at 2016-11-22 06:11:40
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 50 1
# Exec time 76 2s 2s 2s 2s 2s 0 2s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 20 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0
# Query size 3 15 15 15 15 15 0 15
# String:
# Databases test
# Hosts 192.168.8.1
# Users mysql
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(2)\G
���:
1.��ѯʱ�䳤,��ѯ������
2.IO���sql,����Rows Examine��,ɨ�������
3.δ����������sql,����Rows Examine��Rows send���͵������ĶԱ�
2-5 ���ͨ��������־�����������SQL
1.��ѯ��������ÿ�β�ѯռ��ʱ�䳤��SQL
ͨ��Ϊpt-query-digest������ǰ������ѯ
2.IO���SQL
ע��pt-query-digest�����е�Rows examine��
3.���������SQL
ע��pt-query-digest�����е�Rows examine��Row send �ĶԱ�
��Rows examine>>Row send ��������ʹ��������ɨ����߱�ɨ��ķ�ʽ�����в�ѯ,��Ҫ�����Ż�
2-6 ͨ��explain��ѯ�ͷ���SQL��ִ�мƻ�
mysql> explain select customer_id,first_name,last_name from customer;
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | customer | ALL | NULL | NULL | NULL | NULL | 599 | NULL |
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
1 row in set (0.00 sec)
explain ���ظ��еĺ���
select_type:
��ʾ select ��ѯ������,��Ҫ���������ָ��ָ��ӵIJ�ѯ,����:��ͨ��ѯ�����ϲ�ѯ���Ӳ�ѯ�ȡ�
- SIMPLE:��ʾ��� select ��ѯ���,�ڲ�ѯ�в������Ӳ�ѯ���߽�����Ȳ�����
- PRIMARY:��ѯ��������SELECT(�����Ӳ�ѯ�����ı�����ΪPRIMARY)��
- SUBQUERY:�Ӳ�ѯ����SELECT��
- DERIVED:��������SELECT�Ӳ�ѯ(�Ӳ�ѯλ��FROM�Ӿ�)��
- UNION:��SELECT֮��ʹ����UNION��
table:��ʾ��һ�е�����ʱ�������ű���
type:��ʾ����ʹ���˺������� const��eq_reg��ref��range��index��ALL;const:����������;eq_reg:�����������ķ�Χ����;ref:���ӵIJ���(join),range:�����ķ�Χ����;index:������ɨ��;
possible_keys:��ʾ����Ӧ�������ű��е�����,���Ϊ��,û�п��ܵ�����
key:ʵ��ʹ�õ�����,���Ϊnull,û��ʹ������
key_len:ʹ�õ������ij���,�ڲ���ʧ��ȷ�Ե������,����Խ��Խ��
ref:��ʾ��������һ�б�ʹ����,������ܵĻ�,��һ������
rows:mysql��Ϊ����������������������ݵ�����;
extra����Ҫע��ķ���ֵ
using filesort:mysql��Ҫ���ж���IJ�������������Է��ص����������������������Լ��洢�����ֵ��ƥ��������ȫ���е���ָ��������ȫ����
using temporary:MySQL��Ҫ����һ����ʱ�����洢���,��ͨ�������ڶԲ�ͬ���м�����order by��,������group by ��
����type����Ҫ����,���´���õ����:
const:��һ����������,һ����������Ψһ��������
eq_reg:������Ψһ�����ķ�Χ����
ref:���ӵIJ���,һ��һ�����ǻ���ijһ�������IJ���
range:���������ķ�Χ����
index:����������ɨ��
all:���ڱ�ɨ��
2-7 Count()��Max()���Ż�
1.��max()��ѯ,����Ϊ����������
����max������ѯ���һ�ʽ���ʱ��
explain select max(payment_date) from payment \G
\g: �����,�ȼ��ڡ�;��
\G: ����ѯ���ĺ�������������,�����Ķ�
mysql> explain select max(payment_date) from payment \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: payment
partitions: NULL
type: ALL # ȫ��ɨ��
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 16086
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
�������һ����ɨ�����,һ��ɨ����16086�����ݡ�������ݱ��ܴ�,�����IOЧ�ʾͻ�ܲ�
�Ż�����:max(field)����ͨ��Ϊfield�������� ���Ż�
�: create index index_name on table_name(column_name �涨��Ҫ��������)
create index idx_paydate on payment(payment_date);
�Ż���:
mysql> explain select max(payment_date) from payment \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Select tables optimized away
1 row in set, 1 warning (0.00 sec)
�Ż�֮����Ҫ��ѯ���е�����,����ͨ�������Ϳ���֪��ִ�еĽ���ˡ�
��Ϊ������˳�����е�,ֻ��Ҫ�����һ�����ݡ������;����ܼ�����IO������
������ʱ��,���ܱ��������ж��,��ѯmax����Ҫ��ʱ���ǻ����̶���
2.count()�Զ���ؼ��ֽ��в�ѯ
������һ��SQL��ͬʱ���2006���2007���Ӱ������,���:
select count(release_year='2006' or null) as '2006���Ӱ����',
count(release_year='2007' or null) as '2007���Ӱ����'
from film;
�������һ��ΪʲôҪ�ӡ�or null��:
count()����ֻ��count(NULL)�DzŲ�����,��count(NULL)=0;
����release_year=��2006��'�Ǹ��Ƚ������,���Ϊ1����0,�����Dz���2006 count�������������
������or null�Ժ�,��ֵ��Ϊ2006,release_year='2006���Ľ��Ϊ0, '0 or null�����Ϊnull,�������ų���2006����Ľ��
count(*) �� count(field) ������
count(*) ��ѯ�Ľ����,�����˸���ֵΪnull�Ľ��
2-8 �Ӳ�ѯ���Ż�

���Ӳ�ѯ���Ż���:
ͨ�������ǰ���Ҫ���Ӳ�ѯ�Ż�Ϊjoin��ѯ,�����Ż�ʱҪע���Ƿ������ݵ��ظ�,��Ϊ�ڹ�������еĿ��ܴ���һ�Զ�Ĺ�ϵ,�Ӷ�����������ࡣ
join������൱�ڽ���������й���,�ڹ���������һһ��������ƥ���ѯ,��˷���ֵ����ȡ����ԭʼ���е����ݸ���,��ȡ��������������֮ƥ������ݵĸ�����
����Ҫ����distinct
select distinct t.id from t join t1 on t.id=t1.tid;
2-9 group by���Ż�


group by���ܻ������ʱ��(Using temporary),�ļ�����(Using filesort)��,Ӱ��Ч�ʡ�
����ͨ���������Ӳ�ѯ,�����������ʱ�����ļ�����,���Խ�ʡio
- using()�������ű���join��ѯ,Ҫ��using()ָ���������������о�����,��ʹ��֮����join������;����: select a., b. from a left join b using(colA);
- group by ���о���Ҫʹ����������������,����ͻ�ʹ����ʱ�����ļ�
��дǰ
select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;
���
select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join(
select actor_id,count(*) as cnt from sakila.film_actor group by
actor_id
)as c using(actor_id);
��дǰ
mysql> explain select actor.first_name,actor.last_name,count(*)
-> from sakila.film_actor
-> inner join sakila.actor using(actor_id)
-> group by film_actor.actor_id \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: Using temporary; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.00 sec)
ERROR:
No query specified
���
mysql> explain select actor.first_name,actor.last_name,c.cnt
-> from sakila.actor inner join(
-> select actor_id,count(*) as cnt from sakila.film_actor group by
-> actor_id) as c using(actor_id) \G;
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
partitions: NULL
type: ref
possible_keys: <auto_key0>
key: <auto_key0>
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: film_actor
partitions: NULL
type: index
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 4
ref: NULL
rows: 5462
filtered: 100.00
Extra: Using index
3 rows in set, 1 warning (0.00 sec)
ERROR:
No query specified
2-10 Limit��ѯ���Ż�
limit�����ڷ�ҳ����,ʱ�������order by�Ӿ�ʹ��,��˴��ʱ���ʹ��Filesorts��������ɴ�����io����
1.ʹ�����������л���������order by����
2.��¼�ϴη��ص�����,���´β�ѯʱʹ����������
�Ż�limit��ѯ
����: select film_id,description from sakila.film order by title limit 50,5; �����Ż�
����������˼���� title �ֶ�����,Ȼ��ȡ�ӵ�51-55�е�����
mysql> explain select film_id,description from sakila.film order by title limit 50,5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
- �Ż�����1:ʹ�����������л��������order by����
- select film_id,description from sakila.film order by film_id limit 50,5;
- (�Ż�ǰ��order by title������,�Ż�����order by film_id,������)
mysql> explain select film_id ,description from sakila.film order by film_id limit 50,5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 2
ref: NULL
rows: 55
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 sec)
- �Ż�����2:��¼�ϴη��ص�����,���´β�ѯʱ�� ��������(��������������ʱɨ�����ļ�¼)
- select film_id,description from sakila.film where film_id >50 order by film_id limit 5;
mysql> explain select film_id,description from sakila.film where film_id >50 order by film_id limit 5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: NULL
rows: 500
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
ʹ�����ַ�ʽ��һ������,��������һ��Ҫ˳�������������,����������ֿ�ȱ���ܻᵼ������ҳ������ʾ���б�����5��,����취�Ǹ���һ��,��֤��һ���������IJ����������Ϳ�����
���Ƽ���ʹ���������ַ�ʽ:
���Ƽ��������ӳٹ��������Ӳ�ѯ�Ż������ҳ������
˵��:MySQL����������offset��,����ȡoffset+N��,Ȼ�ط���ǰoffset��,����N��,�ǵ�offset�ر���ʱ��,Ч�ʾͷdz��ĵ���,Ҫô���Ʒ��ص���ҳ��,Ҫô�Գ����ض���ֵ��ҳ������SQL��д��
����:�ȿ��ٶ�λ��Ҫ��ȡ��id��,Ȼ���ٹ���:
SELECT a.* FROM ��1 a, (select id from ��1 where ���� LIMIT 100000,20 ) b where a.id=b.id
SELECT a.film_id,a.description FROM
sakila.film a, (SELECT film_id from sakila.film LIMIT 500,5) b where a.film_id=b.film_id;
��3�� �����Ż�
3-1 ���ѡ����ʵ��н�������
ѡ����ʵ�������
1.��where,group by,order by,on�Ӿ��г��ֵ���
2.�����ֶ�ԽСԽ��(��Ϊ���ݿ�Ĵ洢��λ��ҳ,һҳ���ܴ��µ�����Խ��Խ�� )
3.��ɢ�ȴ���з�����������ǰ��
select count(distinct customer_id), count(distinct staff_id) from payment;
��index(sftaff_id,customer_id)��?����index(customer_id,staff_id)����?
mysql> select count(distinct customer_id),count(distinct staff_id) from payment;
+-----------------------------+--------------------------+
| count(distinct customer_id) | count(distinct staff_id) |
+-----------------------------+--------------------------+
| 599 | 2 |
+-----------------------------+--------------------------+
1 row in set (0.01 sec)
����customer_id����ɢ�ȸ���,����Ӧ��ʹ��index(customer_id,staff_id)
��ɢ�ȵ��ж�
�鿴�������ݽṹ��Ϣ: desc ����;
��ɢ��:����ΨһֵԽ��,��ɢ��Խ�ߡ�
�ж�ijһ�е���ɢ��:select count(distinct �ֶ���)from ����;���صĽ��ֵԽ��,˵����ɢ��Խ��,������������ʱ,Ӧ�÷ŵ�ǰ��;
����:select count(distinct id),count(distinct real_name) from user;
id ��Ψһֵ,������ɢ�ȸ��ߡ��� real_name ������ظ���>����ͬ��ͬ�յ����,������ɢ�ȵ͡�
3-2 �����Ż�SQL�ķ���
�ظ�����������


�������������Ӱ��д��,����Ӱ���ѯ,����Խ��,����Խ��
����ҵ��ظ��Ͷ��������,�����Ѿ���������,����primay key ����������������uniqueΨһ������
��������,��ָ���������ǰ����ͬ,innodb����ÿ�����������Զ�����������Ϣ
����������ѯ����
pt-duplicate-key-checker
�����ظ�����������
ͨ��ͳ����Ϣ�� information_schma ����һЩ�ظ����������
use information_schema;
SELECT a.TABLE_SCHEMA AS '������'
,a.TABLE_NAME AS '����'
,a.INDEX_NAME AS '����1'
,b.INDEX_NAME AS '����2'
,a.COLUMN_NAME AS '�ظ�����'
FROM STATISTICS a
JOIN STATISTICS b ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
AND a.COLUMN_NAME = b.COLUMN_NAME
WHERE a.SEQ_IN_INDEX = 1 AND a.INDEX_NAME <> b.INDEX_NAME

ʹ�� pt-duplicate-key-checher ������ظ�����������
pt-duplicate-key-checker -uroot -p'123456' -h 127.0.0.1
3-3 ����ά���ķ���

������ά�����Ż���ɾ����������
ĿǰMySQL�л�û�м�¼������ʹ�����,������PerconMySQL��MariaDB�п���ͨ��INDEX_STATISTICS�����鿴��Щ����δʹ��,����MySQL��Ŀǰֻ��ͨ��������־��� pt-index-usage ��������������ʹ������ķ�����
��4�� ���ݿ�ṹ�Ż�
4-1 ѡ����ʵ���������
1.ʹ�ÿɴ������ݵ���С����������
2.ʹ�ü���������,IntҪ��varchar������mysql�����ϸ���
3.������ʹ��not null�����ֶ�,������innodb�����Ծ�����,��Ϊ��not null�����ݿ�����ҪһЩ������ֶν��д洢,�����ͻ�����һЩIO�����ԶԷ�null���ֶ�����һ��Ĭ��ֵ
4.��������text,���ò�������ֱ�,��text�ֶδ�ŵ���һ�ű���,����Ҫ��ʱ����ʹ�����ϲ�ѯ,��������߲�ѯ������Ч��
����1����Int�洢����ʱ��

from_unixtime() �ɽ�Int���͵�ʱ���ת��Ϊʱ���ʽ
select from_unixtime(1392178320); ���Ϊ 2014-02-12 12:12:00
unix_timestamp() �ɽ�ʱ���ʽת��ΪInt����
select unix_timestamp(��2014-02-12 12:12:00��); ���Ϊ1392178320
mysql> create table testtime(id int auto_increment not null,timestr int,PRIMARY KEY(id));
Query OK, 0 rows affected (0.01 sec)
mysql> desc testtime;
+---------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| timestr | int(11) | YES | | NULL | |
+---------+---------+------+-----+---------+----------------+
2 rows in set (0.01 sec)
mysql> insert into testtime(timestr) values(UNIX_TIMESTAMP('2014-06-01 21:00:00'));
Query OK, 1 row affected (0.00 sec)
mysql> select FROM_UNIXTIME(timestr) from testtime;
+------------------------+
| FROM_UNIXTIME(timestr) |
+------------------------+
| 2014-06-01 21:00:00 |
+------------------------+
1 row in set (0.00 sec)
����2���洢IP��ַ����bigInt

���� inet_aton() , inet_ntoa() ת��
select inet_aton(��192.169.1.1��); ���Ϊ3232301313
select inet_ntoa(3232301313); ���Ϊ192.169.1.1
4-2 ���ݿ���ķ�ʽ���Ż�

���ķ�ʽ�������ݿ���ƵĹ淶��:���ݱ������ڷǹؼ��ֶζ�����ؼ��ֶεĴ��ݺ�������,����ϵ�����ʽ��
���Խ�һ�����ݱ����в��,�����������ʽ��Ҫ��
��Ʊ���ʱ����Ϸ�ʽ����Ϊ��:�����������ࡢ���ٱ��IJ��롢���¡�ɾ���쳣
��Ʊ���ʱ��ʹ�÷���ʽ����Ϊ��:�Կռ任ʱ�䡢��ǿ����Ŀɱ���ԺͿ�ά����
�����ϵ�����ʽҪ��ı�������������:
1.��������:(���ࡢ��������)����ÿһ����Ʒ������м�¼
2.���ݲ����쳣
3.���ݸ����쳣
4.����ɾ���쳣(���ɾ�����������������Ʒ,�Ͳ�ѯ��������,����������)
�������������ڷ���,��������������Ʒ����,����Ʒ����Ϊ���������ؼ��ֶ�
�������ϵ�����ʽ��ʱ��,���Բ�ֱ�Ϊ���ݱ�,��֮ǰ�ķǹؼ�������Ϊ�±��Ĺؼ���,Ȼ�������±��;ɱ��Ĺ�����
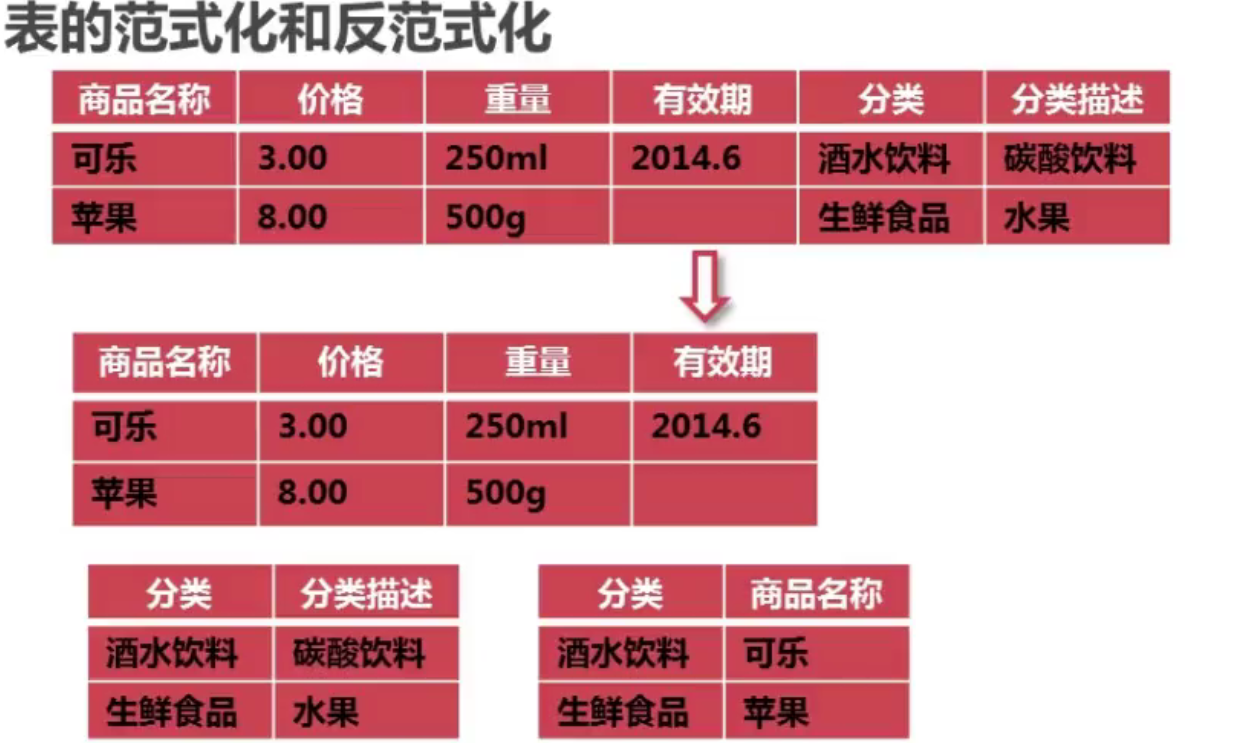
4-3 ���ݿ���ķ���ʽ���Ż�
����ʽ��:Ϊ�˲�ѯЧ�ʵĿ���,��ԭ�����ϵ�����ʽ�ı��ʵ���������,�Դﵽ�Ż���ѯЧ�ʵ�Ŀ�ġ��Կռ任ȡʱ��IJ�����

Ϊ���io����Ч��,����һЩ�洢�ռ�Ĵ��ۡ���������˶�ȡ���ݵ�Ч�ʡ�
���û������������ѯ��������Ϣ,��ô���û���,�绰,��ַ�Ͷ����۸����һ����������,��ȻΥ���˵�����ʽ,��Ϊ����id,�û���,�绰,��ַ��,���ڴ��ݺ�������,�����������ݶ�����һ�ű���,������sql���ʵ��,������Ϣ�Ķ�ȡ,�Ӷ��Ż���io����;
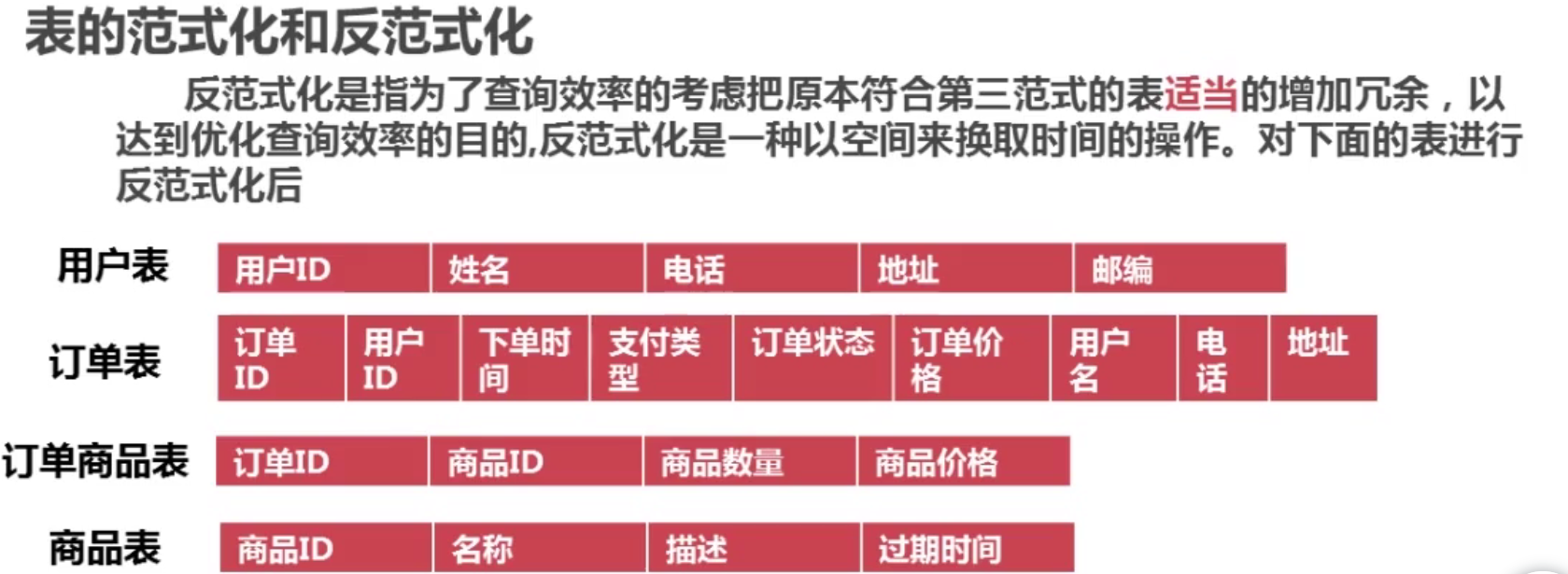

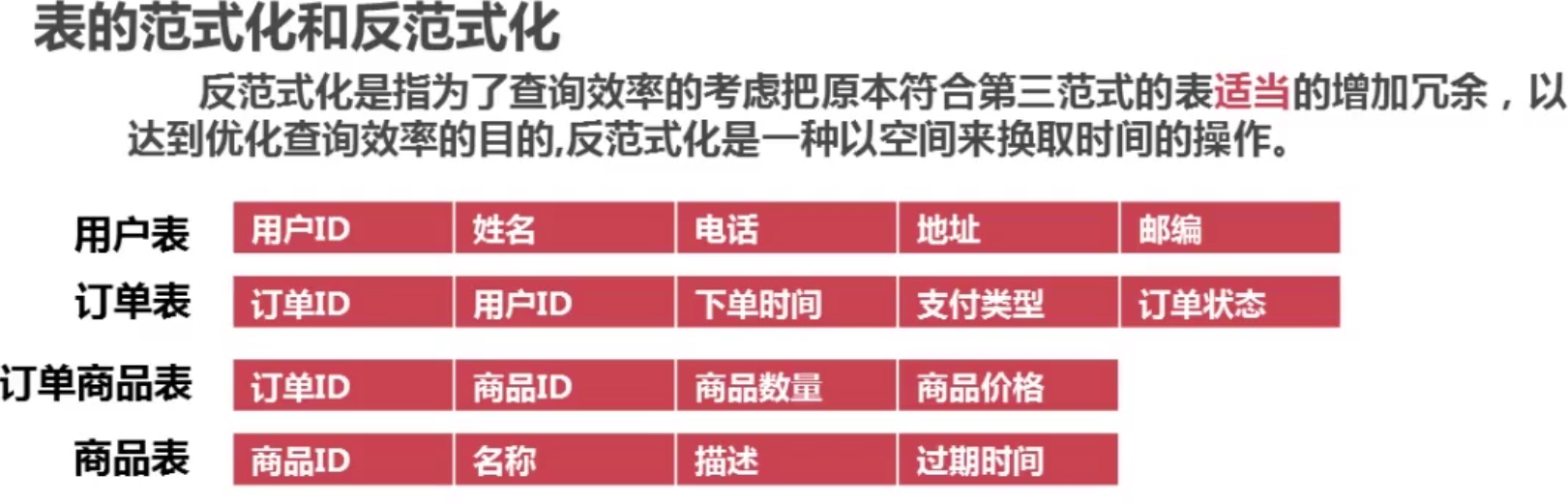
4-4 ���ݿ���Ĵ�ֱ���
���Ĵ�ֱ��ֵ�ԭ��
��ν��ֱ���,���ǰ�ԭ��һ���кܶ��еı���ֳɶ����������Ŀ�������,ͨ�����ԭ������:
1���Ѳ����õ��ֶε�����ŵ�һ������
2���Ѵ��ֶζ�����ŵ�һ������
3���Ѿ���һ��ʹ�õ��ֶηŵ�һ��
�����Ŀ��ȹ�����ʱ��,������Ҫ�Ա����д�ֱ���,����Ľ�������(ԭ����������Ⱥ��,���Ա���):һ������,�����ϲ���һ��,��������һ���!

��ֺ�
�� title �� description ͨ�� film_id ����һ���±�


4-5 ���ݿ����ˮƽ���
����ˮƽ���: ��Ҫ�ǽ�����������������,ˮƽ���ÿ�����ı��ṹ������ȫһ�µ�(�����������ݴ���һ��ʱ,���ܼ�������,���ǻ�Ƚ���);

���õķ�����:hashȡģ���

1���Դ��������idֵ����hash����,����Ҫ���Ϊ5�ű�,����ʹ��mod(����id,5)ȡ��0-4��ֵ
2����Բ�ͬ��hashID�����ݴ浽��ͬ�ı��С�
��ս:
- ��������������ݲ�ѯ
- ͳ�Ƽ���̨��������
��ֱ�����ˮƽ�������:
ˮƽ��� ��������������� ��ֱ��ֽ�����Ŀ�������,��̨���ܱ�,ǰ̨�ò�ֱ�
��ֱ����Dz��ֶ� ˮƽ����DZ��ṹ���� �����ݸ��ֿ���
��5�� ϵͳ�����Ż�
5-1 ���ݿ�ϵͳ�����Ż�
1. ���緽��

- ����tcp֧�ֵĶ�����Ŀ,net.ipv4.tcp_max_syn_backlog=65535
- ���ٶϿ����ӵ���Ŀ,��ʱ������Դ
net.ipv4.tcp_max_tw_buckets = 8000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle =1
net.ipv4.tcp_fin_timeout=10
2. ���ļ���������
��/etc/security/limits.conf�ļ�,����һ���������Ĵ��ļ����������ơ�
�ر�iptables,selinux�ȷ���ǽ����

5-2 MySQL�����ļ��Ż�

/usr/sbin/mysqld - -verbose - -help | grep -A 1 'Default options ��
�鿴MySQL�����ļ�·��,������ڶ�������ļ�,�����ĻḲ��ǰ���
- innodb_buffer_pool_size
��Ҫ,����صĴ�С �Ƽ����ڴ�����75%,Խ��Խ�á�
select engine,
round(sum(data_length+index_length)/1024/1024,1) as "Total MB"
FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA NOT IN
("inoformation_schema","performance_schema")
Group by engine;
mysql> select engine,
-> round(sum(data_length+index_length)/1024/1024,1) as "Total MB"
-> FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA NOT IN
-> ("inoformation_schema","performance_schema")
-> Group by engine;
+--------+----------+
| engine | Total MB |
+--------+----------+
| NULL | NULL |
| CSV | 0.0 |
| InnoDB | 9.0 |
| MEMORY | 0.0 |
| MyISAM | 0.3 |
+--------+----------+
5 rows in set (0.11 sec)
- innodb_buffer_pool_instances
Ĭ��ֻ��һ�������,���һ��������в���������,��������,��ʱ���Է�Ϊ��������;
- innodb_log_buffer_size
log����Ĵ�С,һ���1s�ͻ�ˢ��һ��,�ʲ���̫��;
?
- innodb_flush_log_at_trx_commit
��Ҫ,��ioЧ��Ӱ��ϴ�
0: 1sˢ��һ�ε�����;
1:ÿ���ύ����ˢ�µ�����;
2:ÿ���ύˢ�µ�������,1sˢ�µ�����;Ĭ��Ϊ1��

?
- innodb_read_io_threads
- innodb_write_io_threads
��д��io��������,Ĭ��Ϊ4
- innodb_file_per_table
��Ҫ,����ÿ����ʹ�ö����ı��ռ�,Ĭ��ΪOFF,�����б�������һ�������ı��ռ��С����IOƿ�����Ƽ�����ON
?
- innodb_stats_on_metadata
mysql��ʲô����»�ˢ�±���ͳ����Ϣ,һ��ΪOFF��
?
5-3 ���������ù���ʹ��
mysql���������ù���:
https://tools.percona.com/wizard
��6�� ������Ӳ���Ż�
6-1 ������Ӳ���Ż�
������Ӳ���Ż�:
1.cpuѡ��:mysqlһ��sql��ִ��ֻ���õ����˵�cpu,���,�ڸ��ƽ��̵�ʱ��Ҳ��ֻ���õ����˵�cpu,����cpu������Խ��Խ��,mysql5.5�ǵķ�������Ҫ����32��,ƫ��ѡ��Ƶ�ʸ����cpu;
2.Disk IO �Ż�

���õ�RAID ������
RAID0: Ҳ��Ϊ����,������̽ӳ�һ��ʹ��,io���(���Ǵ��̻���,����û��,��ȫ�Բ�)
RAID1: Ҳ�ƾ���,Ҫ��������������,ÿ����̴洢��������ͬ;
RAID1+0: ����RAID1��RAID0�Ľ��,ͬʱ�߱������������ȱ��,�Ƽ����ݿ�ʹ���������;
Ŀǰ���ܻ��и��õĴ洢�豸:����ssd��
