文章目录
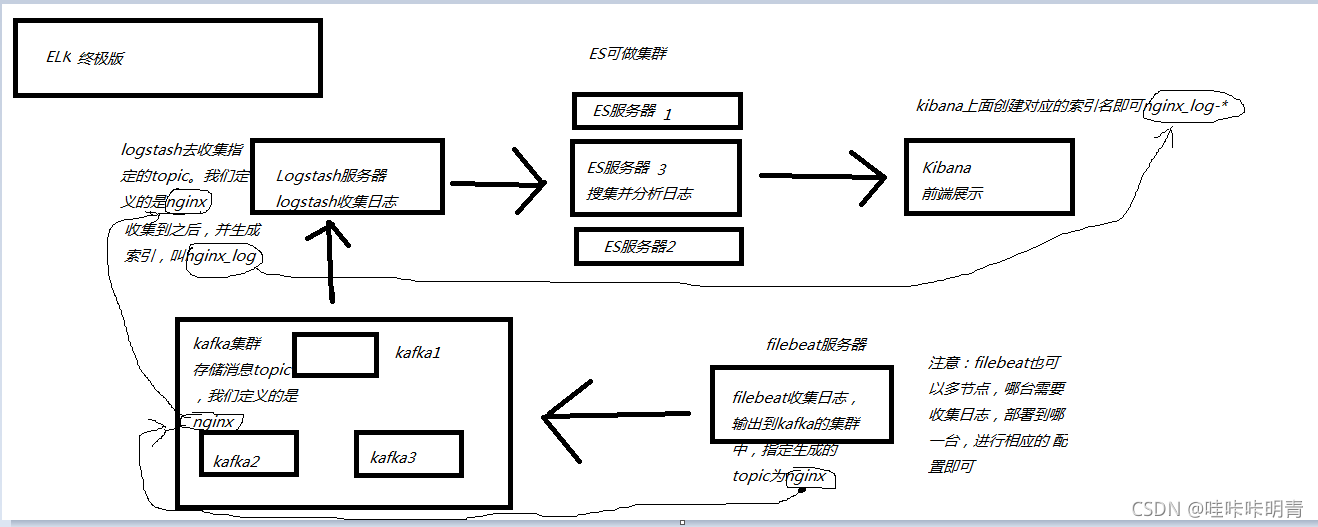
ELK+Kafka+Filebeat 终极版
4、Kafka:
数据缓冲队列(消息队列)。同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批量处理系统、低延迟的实时系统、web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka的特性:
- 高吞吐量:kafka每秒可以处理几十万条消息。
- 可扩展性:kafka集群支持热扩展- 持久性、
- 可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
它主要包括以下组件
话题(Topic):是特定类型的消息流。(每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的)
生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务).
消费者(Consumer):可以订阅一个或多个话题,从而消费这些已发布的消息。
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
partition(区):每个 topic 包含一个或多个 partition。
replication:partition 的副本,保障 partition 的高可用。
leader:replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
follower:replica 中的一个角色,从 leader 中复制数据。
zookeeper:kafka 通过 zookeeper 来存储集群的信息。
zookeeper:
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、分布式同步等。Kafka的运行依赖ZooKeeper。
ZooKeeper用于分布式系统的协调,Kafka使用ZooKeeper也是基于相同的原因。ZooKeeper主要用来协调Kafka的各个broker,不仅可以实现broker的负载均衡,而且当增加了broker或者某个broker故障了,ZooKeeper将会通知生产者和消费者,这样可以保证整个系统正常运转。
在Kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况与消费者当前消费的状态信息都会保存在ZooKeeper中。
集群概念图 适合海量级吞吐
搭建架构
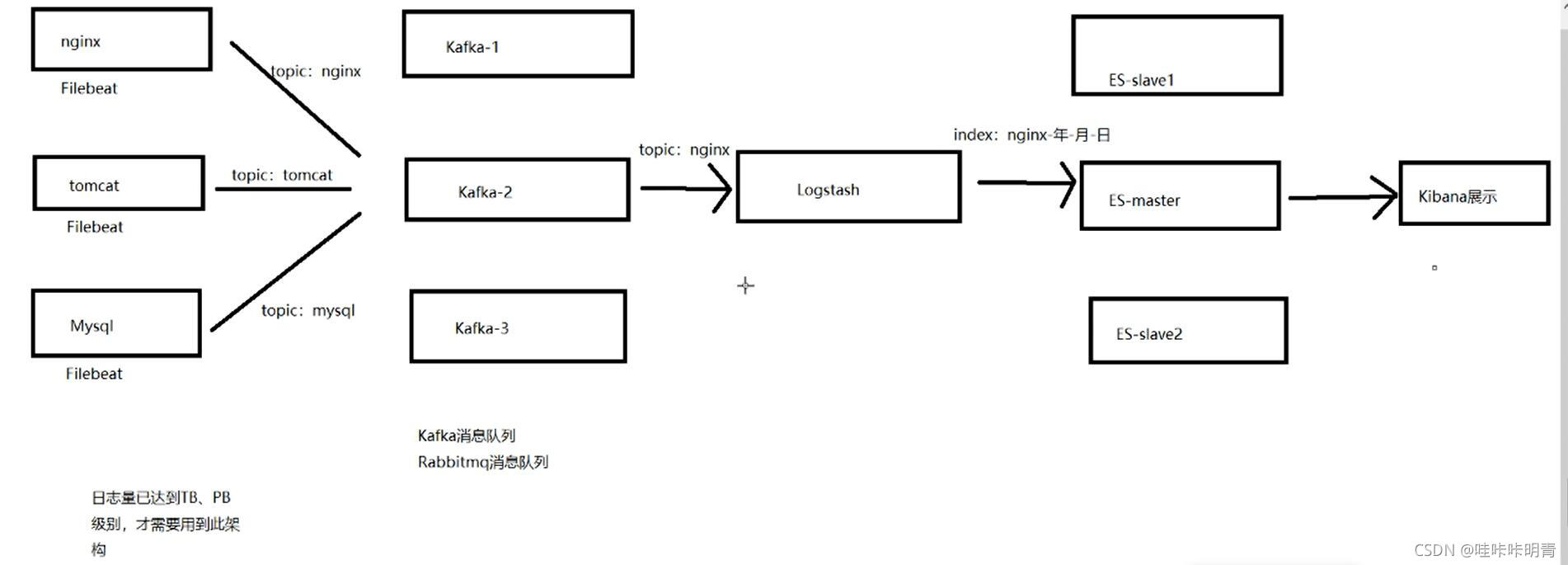
Filebeat安装在要收集日志的应用服务器中,Filebeat收集到日志之后传输到kafka中,logstash通过kafka拿到日志,在由logstash传给后面的es,es将日志传给后面的kibana,最后通过kibana展示出来。
系统类型:Centos7.5
节点IP:192.168.246.234,192.168.246.231、192.168.246.235
软件版本:jdk-8u121-linux-x64.tar.gz、kafka_2.11-2.1.0.tgz
示例节点:172.16.246.231
由于我这里做实验,就没有使用那么太台服务器
我使用的是三台,就是上面俩篇上面文章使用的机器 稍微给你们总结一下
第一台机器上面有 es 服务
第二台机器上面有 head logstash nginx 服务
第三台机器上面有 kafka 服务
安装配置jdk8
使用的三台机器上面,每一个都要配置java环境 三台全部
(1)Kafka、Zookeeper(简称:ZK)运行依赖jdk8
tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
设置环境变量
echo '
JAVA_HOME=/usr/local/jdk1.8.0_121
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
source /etc/profile #刷新一下
2.安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
配置相互解析―三台机器
[root@es-2-zk-log ~]# vim /etc/hosts
192.168.246.234 mes-1
192.168.246.231 es-2-zk-log
192.168.246.235 es-3-head-kib
(1)安装
这个包第一篇有介绍怎么下载,去官网找
[root@es-2-zk-log ~]# tar xzvf kafka_2.11-2.1.0.tgz -C /usr/local/
(2)配置
第一台机器
[root@mes-1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
[root@mes-1 ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties #添加如下配置
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.246.231:2888:3888 #kafka集群IP:Port
server.2=192.168.246.234:2888:3888
server.3=192.168.246.235:2888:3888
#创建data、log目录
[root@es-2-zk-log ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@es-2-zk-log ~]# echo 2 > /opt/data/zookeeper/data/myid
第二台机器
[root@es-2-zk-log ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
[root@es-2-zk-log ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.246.231:2888:3888
server.2=192.168.246.234:2888:3888
server.3=192.168.246.235:2888:3888
#创建data、log目录
[root@es-2-zk-log ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@es-2-zk-log ~]# echo 2 > /opt/data/zookeeper/data/myid
第三台机器
[root@es-3 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
[root@es-3-head-kib ~]# vim /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.246.231:2888:3888
server.2=192.168.246.234:2888:3888
server.3=192.168.246.235:2888:3888
#创建data、log目录
[root@es-3-head-kib ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
[root@es-3-head-kib ~]# echo 3 > /opt/data/zookeeper/data/myid
配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower连接并同步到Leader的初始化连接时间,当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
三台都配置好如下图

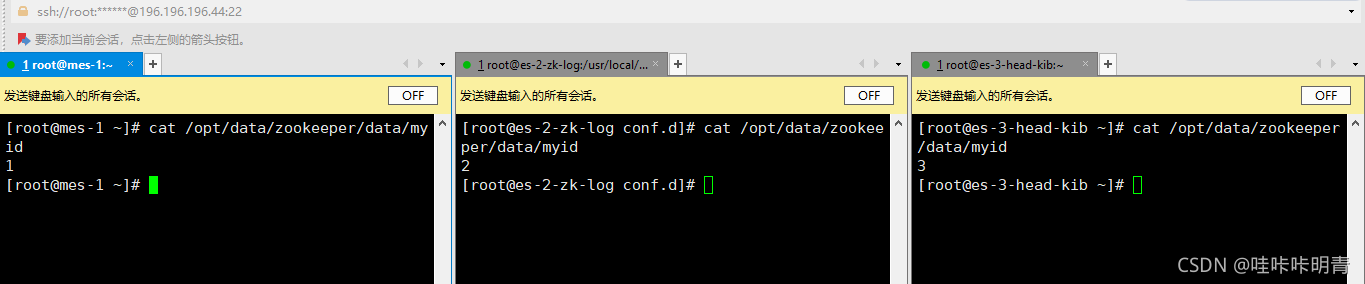
配置Kafka
(1)配置 同样三台全部配置 ,注意id 不要写错顺序拉
第一台机器
[root@mes-1 ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@mes-1 ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties #在最后添加
broker.id=1
listeners=PLAINTEXT://192.168.246.231:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.246.231:2181,192.168.246.234:2181,192.168.246.235:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
创建 日志存放目录
[root@mes-1 ~]# mkdir -p /opt/data/kafka/logs
第二台机器
[root@es-2-zk-log ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@es-2-zk-log ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties
broker.id=2
listeners=PLAINTEXT://192.168.246.234:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.246.231:2181,192.168.246.234:2181,192.168.246.235:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
创建 日志存放目录
[root@mes-1 ~]# mkdir -p /opt/data/kafka/logs
第三台机器
[root@es-3-head-kib ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/server.properties
[root@es-3-head-kib ~]# vim /usr/local/kafka_2.11-2.1.0/config/server.properties
broker.id=3
listeners=PLAINTEXT://192.168.246.235:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.246.231:2181,192.168.246.234:2181,192.168.246.235:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
创建 日志存放目录
[root@mes-1 ~]# mkdir -p /opt/data/kafka/logs
配置项含义:
#每个server需要单独配置broker id,如果不配置系统会自动配置。
broker.id
#监听地址,格式PLAINTEXT://IP:端口。
listeners
#处理网络请求的线程数量,也就是接收消息的线程数。
num.network.threads
#消息从内存中写入磁盘是时候使用的线程数量。
num.io.threads
#发送套接字的缓冲区大小
socket.send.buffer.bytes
#当消息的尺寸不足时,server阻塞的时间,如果超时,
#消息将立即发送给consumer
socket.receive.buffer.bytes
服务器将接受的请求的最大大小(防止OOM)
socket.request.max.bytes
日志文件目录。
log.dirs
#topic在当前broker上的分片个数
num.partitions
#用来设置恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir
offsets.topic.replication.factor
#超时将被删除
log.retention.hours
#日志文件中每个segment的大小,默认为1G
log.segment.bytes
#上面的参数设置了每一个segment文件的大小是1G,那么
#就需要有一个东西去定期检查segment文件有没有达到1G,
#多长时间去检查一次,就需要设置一个周期性检查文件大小
#的时间(单位是毫秒)
log.retention.check.interval.ms
#ZK主机地址,如果zookeeper是集群则以逗号隔开
zookeeper.connect
#连接到Zookeeper的超时时间。
zookeeper.connection.timeout.ms
三台都配置好如下图

4、其他节点配置
只需把配置好的安装包直接分发到其他节点,Kafka的broker.id和listeners就可以了。
启动、验证ZK集群
在三个节点依次执行: 每台机器都启动一下
[root@mes-1 ~]# cd /usr/local/kafka_2.11-2.1.0/
[root@mes-1 kafka_2.11-2.1.0]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
(2)验证
查看端口
[root@mes-1 ~]# netstat -lntp | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 1226/java
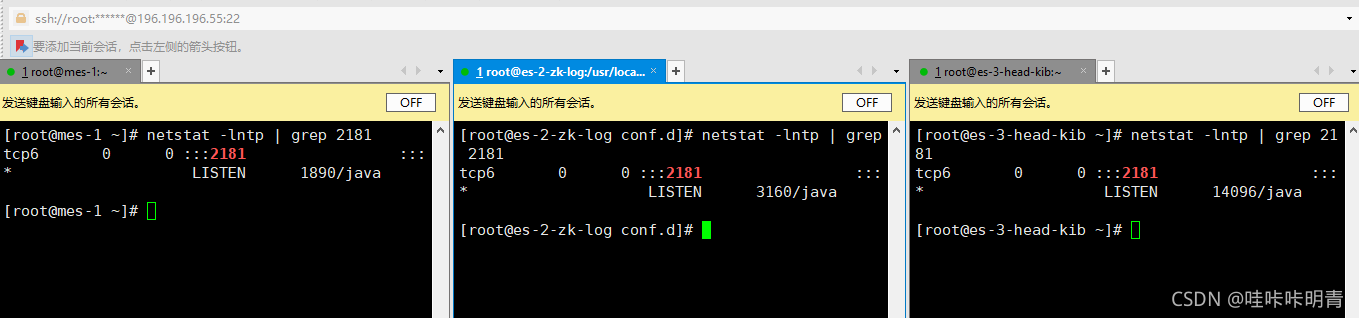
启动、验证Kafka
在三个节点依次执行: 三台全部启动
[root@mes-1 ~]# cd /usr/local/kafka_2.11-2.1.0/
[root@mes-1 kafka_2.11-2.1.0]# nohup bin/kafka-server-start.sh config/server.properties &
(2)验证
在192.168.246.231上创建topic
[root@es-2-zk-log kafka_2.11-2.1.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic "testtopic".
在246.235上面查询192.168.246.231上的topic
[root@es-3-head-kib kafka_2.11-2.1.0]# bin/kafka-topics.sh --zookeeper 192.168.246.231:2181 --list
testtopic
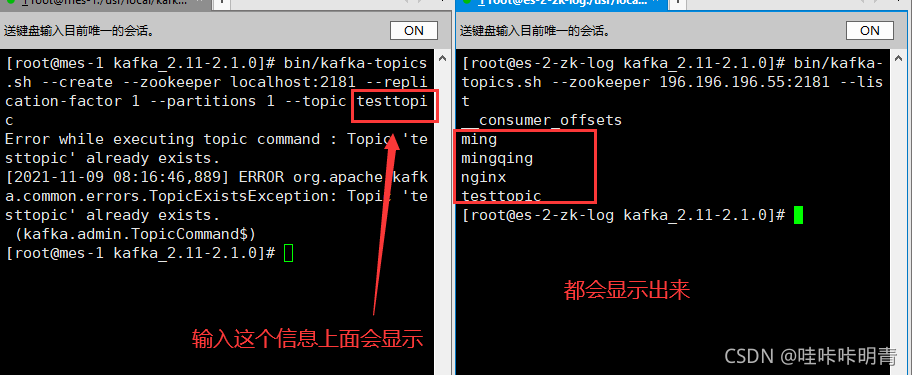
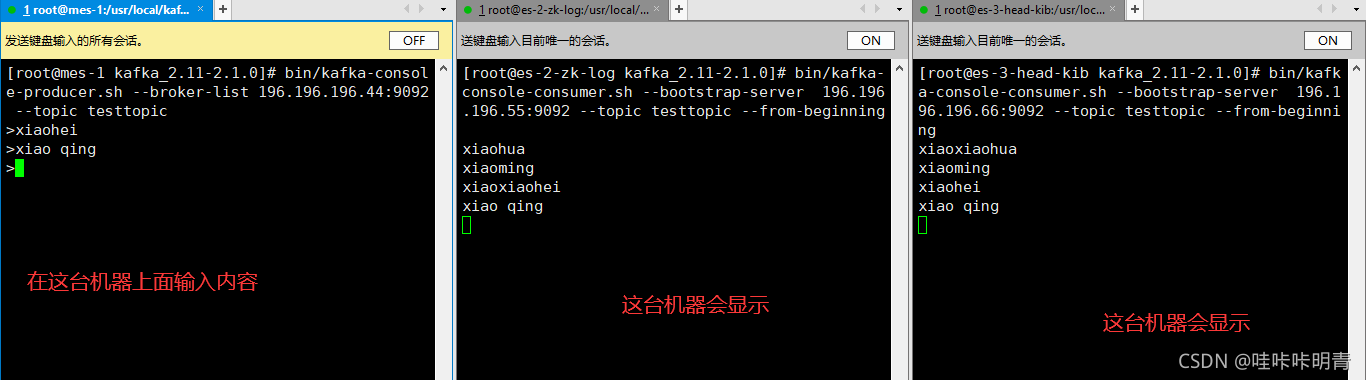
模拟消息生产和消费
发送消息到192.168.246.231
[root@mes-1 kafka_2.11-2.1.0]# bin/kafka-console-producer.sh --broker-list 192.168.246.231:9092 --topic testtopic
>hello
从192.168.246.234接受消息
[root@es-2-zk-log kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.246.234:9092 --topic testtopic --from-beginning
hello
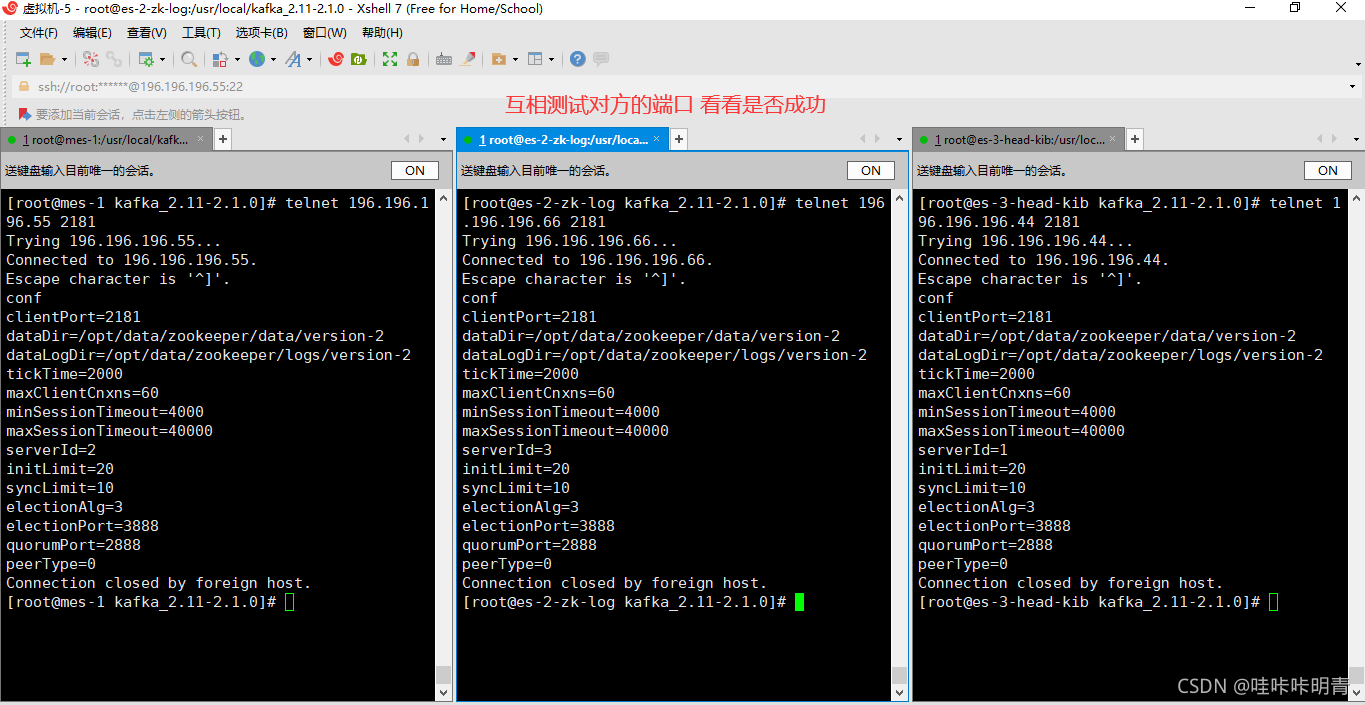
终极测试方法企业常用
经常拿来测试一个端口是否被占用 或者是有没有成功
yum -y install telnet
使用方法 telnet 加对方ip 加对方端口号 conf 有的可以有的不可以
kafka没有问题之后,回到logstash服务器:
我这里没有开一台新机器,我使用的是我的196.196.196.55 机器 上篇文章做实验有
#安装完kafka之后的操作:
[root@es-2-zk-log ~]# cd /usr/local/logstash-6.5.4/etc/conf.d/
[root@es-2-zk-log conf.d]# cp input.conf input.conf.bak
[root@es-2-zk-log conf.d]# vim input.conf
input {
kafka { #指定kafka服务
type => "nginx_log"
codec => "json" #通用选项,用于输入数据的编解码器
topics => "nginx" #这里定义的topic
decorate_events => true #此属性会将当前topic、group、partition等信息也带到message中
bootstrap_servers => "192.168.246.234:9092, 192.168.246.231:9092, 192.168.246.235:9092"
}
}
启动 logstash
这里 我是做实验,你可以选择这里启动,会占用很多的内存,我是做完之后启动的这个
[root@es-2-zk-log conf.d]# cd /usr/local/logstash-6.5.4/
[root@es-2-zk-log logstash-6.5.4]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &
Filebeat
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
- 1.Packetbeat(搜集网络流量数据)
- 2.Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。)
- 3.Filebeat(搜集文件数据)
- 4.Winlogbeat(搜集 Windows 日志数据)
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
**由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。**后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,我这里是你想监控那台服务器上面的web 日志,就安装,我也是安装的第二台机器上面
(1)下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.4-linux-x86_64.tar.gz
(2)解压
[root@es-3-head-kib ~]# tar xzvf filebeat-6.5.4-linux-x86_64.tar.gz -C /usr/local/
[root@es-3-head-kib ~]# cd /usr/local/
[root@es-3-head-kib local]# mv filebeat-6.5.4-linux-x86_64 filebeat
[root@es-3-head-kib local]# cd filebeat/
(3)修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
[root@es-3-head-kib filebeat]# mv filebeat.yml filebeat.yml.bak
[root@es-3-head-kib filebeat]# vim filebeat.yml
filebeat.prospectors:
- input_type: log #指定输入的类型
paths:
- /var/log/nginx/*.log #日志的路径
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
output.kafka:
hosts: ["192.168.246.234:9092","192.168.246.231:9092","192.168.246.235:9092"] #kafka服务器
topic: 'nginx' #输出到kafka中的topic
注释:
这里需要注意的是,我的第二台机器上面的nginx日志格式更改了,如果你的日志格式没有更改需要去更改一下
下面三行配置,只针对于收集json格式的日志,如收集的不是json格式,可以擦除
json.keys_under_root: true #keys_under_root可以让字段位于根节点,默认为false
json.add_error_key: true #将解析错误的消息记录储存在error.message字段中
json.message_key: log #message_key是用来合并多行json日志使用的
Filebeat 6.0 之后一些配置参数变动比较大,比如 document_type 就不支持,需要用 fields 来代替等等。
启动
[root@es-3-head-kib filebeat]# nohup ./filebeat -e -c filebeat.yml &
[root@es-3-head-kib filebeat]# tail -f nohup.out
2019-08-04T16:55:54.708+0800 INFO kafka/log.go:53 kafka message: client/metadata found some partitions to be leaderless
2019-08-04T16:55:54.708+0800 INFO kafka/log.go:53 client/metadata retrying after 250ms... (2 attempts remaining)
...
验证kafka是否生成topic
[root@es-3-head-kib filebeat]# cd /usr/local/kafka_2.11-2.1.0/
[root@es-3-head-kib kafka_2.11-2.1.0]# bin/kafka-topics.sh --zookeeper 192.168.246.231:2181 --list
__consumer_offsets
nginx #已经生成topic
testtopic
可以这个时候启动 启动 logstash 时间较长 稍等一起
现在我们去编辑logstach连接kafka的输出文件
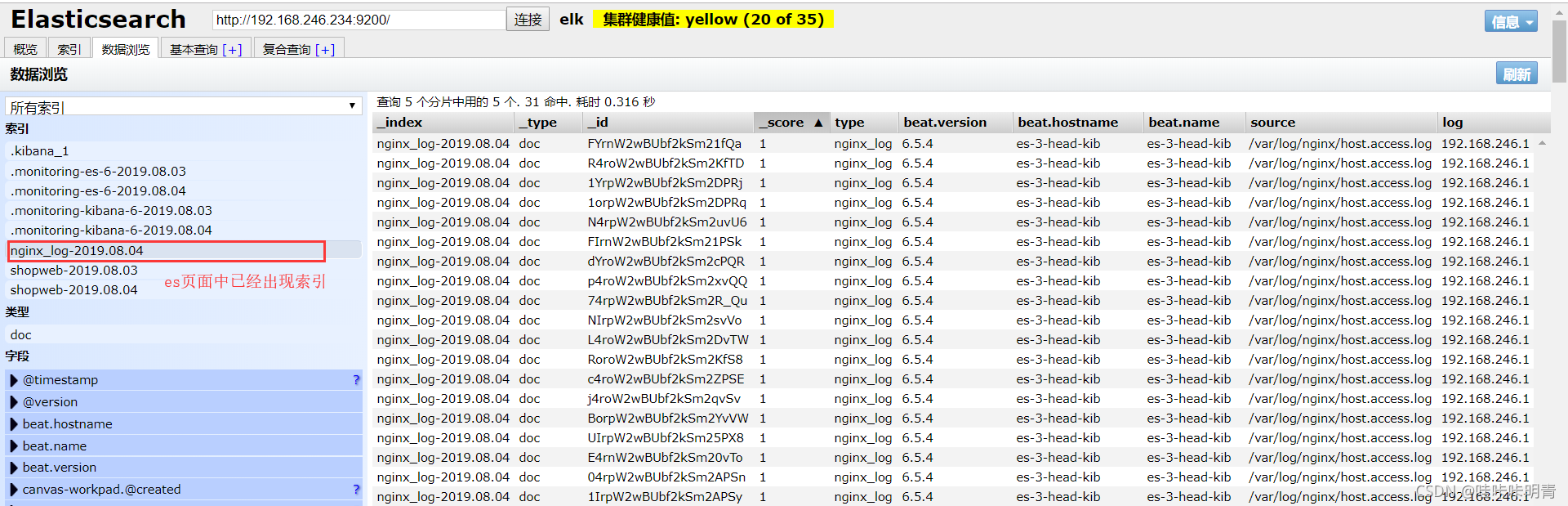
配置完kafka之后查看
http://196.196.196.55:9100/
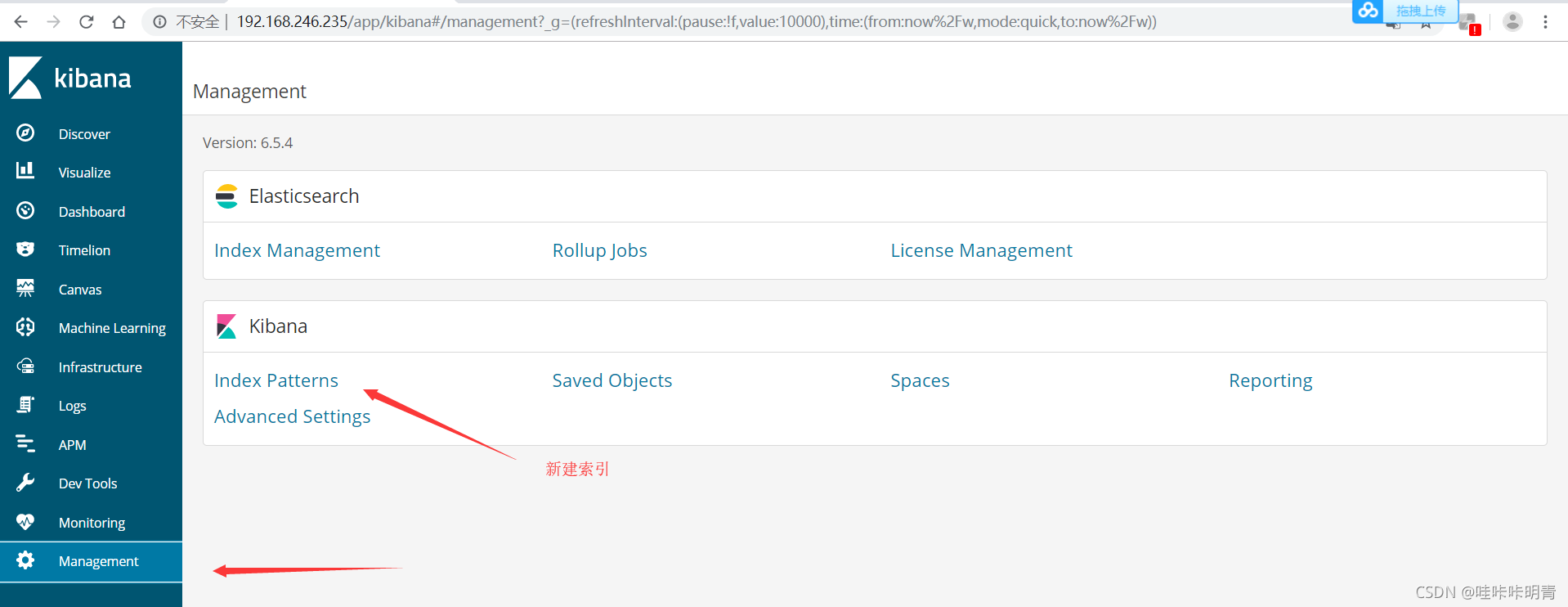
登录到kibana
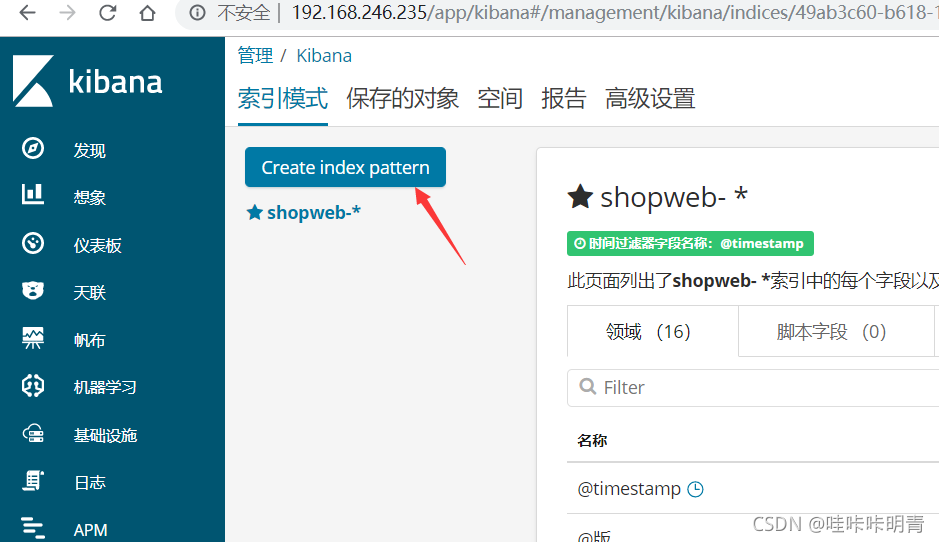


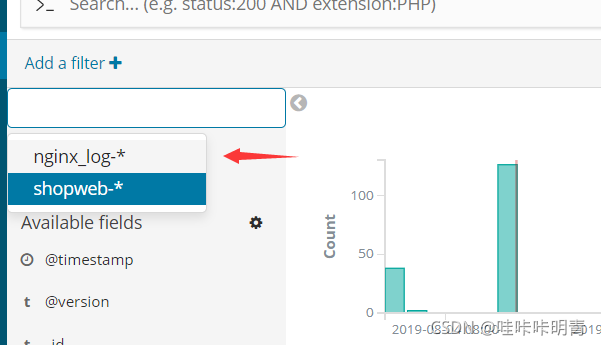
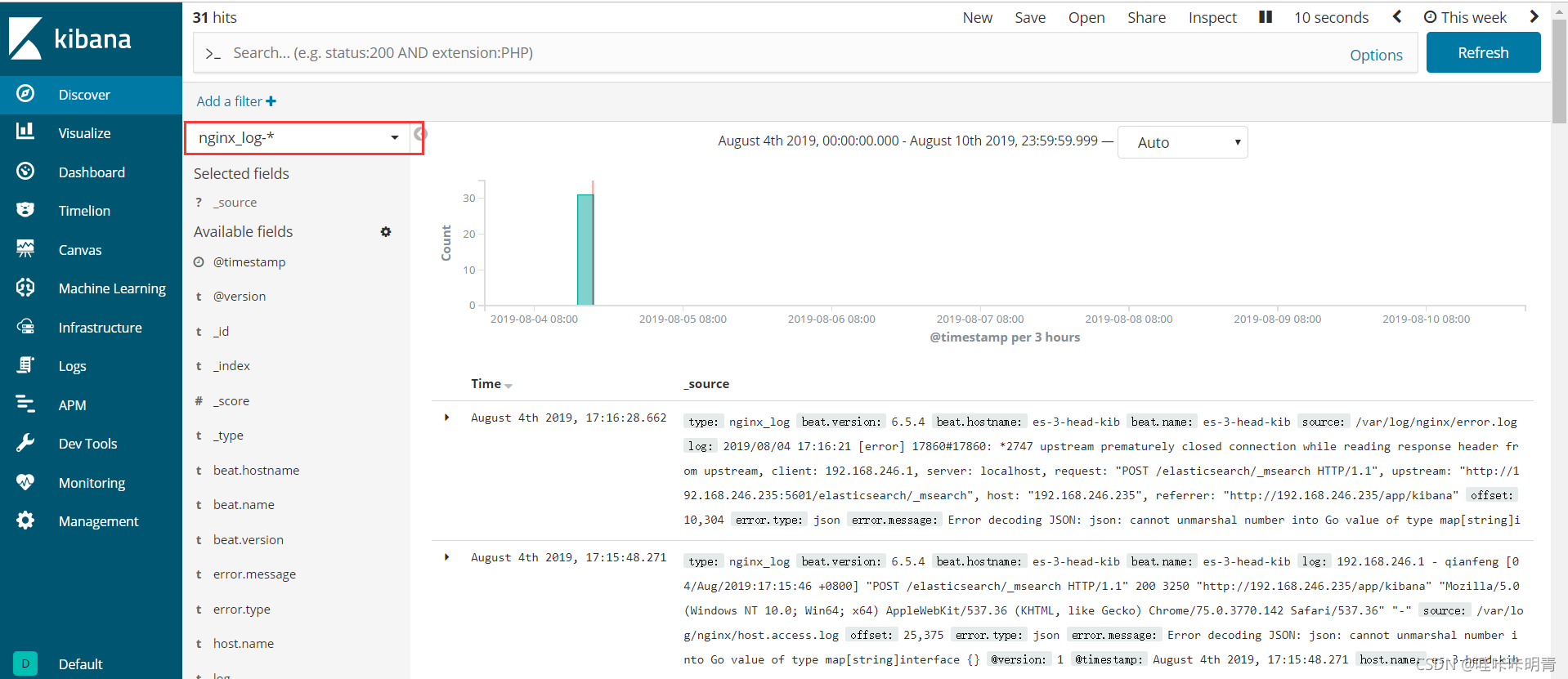
配置文件详细解释
https://blog.csdn.net/gamer_gyt/article/details/59077189
用于测试
bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.246.231:9200"]} }'
ELK终极版
编写博客不易,请留下的你爱心,和收藏