hive���ú���
��Hive��,������Ҫ����������,һ�������ú���,һ�����û��Զ��庯����
�����鿴
show functions;
desc function functionName;
���ں���
1)��ǰϵͳʱ�亯��: current_date(). current_timestamp()��unix_timestamp()
-- ����1:current_date();
��ǰϵͳ���� ��ʽ:"yyyy-MM-dd"
-- ����2:current_timestomp();
��ǰϵͳʱ�ʴ�:��ʽ:"yyyy-MM-dd HH:mmm:ss.ms"
-- ����3: unix_timestamp();
��ǰϵͳʱ�����ʽ:����1970��1��1��0���������
2)����תʱ�������: unix_timestamp()
��ʽ: unix_timestamp([date[,pattern]])
����:
select unix_timestamp( '1970-01-01 0:0:0'); -- ���������ʱ���Ƕ�������ʱ��,����ֵ������������ߵ�ʱ����˵��
select unix_timestamp('1970-01-01 8:0:0') #0
-- �Զ����ʽ
select unix_timestamp('0:0:0 1970-01-01' ,"HH:mm:ss yyyy-MM-dd");
select unix_timestamp(current_date());
3)ʱ���ת���ں���: from_unixtime
�:from__unixtime(unix_time[,pattern])
����;
select from_unixtime(1574092800);
select from_unixtime(1574096401,'yyyy/MM/dd');
select from_unixtime(1574896401,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(0,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(-28800,"yyyy-MM-dd HH:mm:ss";
4)����ʱ����: datediff().months_between0
��ʽ: datediff(date1,date2) - Returns the number of days between date1 and date2
select datediff("2019-11-20","2019-11-01"); #����19
select datediff("2019-11-01","2019-11-19"); #����-18
��ʽ: months_between(date1,date2) - returns number of months between dates date1 and date2
select months_between( '2019-11-20','2019-11-01'); #����0.6 (����)
select months_between( '2019-10-30','2019-11-30'); #���� 1 (����)
select months_betweenC '2019-10-31','2019-11-30');
select months_between( '2019-11-00','2019-11-30');
5)����ʱ���������: year()�� month0��day0�� hour()��minute()�� second()
-- ����
select year(current_date);
select month(current_date);
select day(current_date);
select year(current_timestamp);
select month(current_timestamp);
select day(current_timestamp);
select hour(current_timestamp);
select minute(current_timestamp);
select second(current_timestamp);
select dayofmonth(current_date); #����������µĵڼ���
select weekofyear(current_date); #�����ǽ���ĵڼ���
6)���ڶ�λ����:last_day()��next_day()
-- ��ĩ:
select last_day(current_date)
-- ����
select next_day(current_date,'thursday') ; #��һ��thursday��ʲô����
7)���ڼӼ�����: date_addo.date_subo��add_months()
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,12;
select date_add('2019-12-10',1); #���� 2019-12-11
8)�ַ���ת����: to_date(
(�ַ�������Ϊ: yyyy-MM-dd��ʽ)
select to_date('2017-01-01 12:12:12');
9)����ת�ַ���(��ʽ��) ����: date_format
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(),'yyyyMMdd');
select date_format( '2017-21-01','yyyy-MM-dd HH:mm:ss');
�ַ�������
lower -- (תСд)
select lower('ABC');
upper -- (ת��д)
select upper('abc');
length -- (�ַ�������,�ַ���)
select length('abc');
concat -- (�ַ���ƴ��)
select concat('A','B','C'); # ABC
concat_ws -- (ָ���ָ���)
select concat_ws('-','a','b','c'); # a-b-c
substr-- (���Ӵ�)
select substr('abcde',3); # cde
select substr('abcde',2,3); # bc
split(str ,regex) -- �з��ַ���,�������顣
select split("a-b-c-d-e-f","-");
����ת������
cast(value as type) -- ����ת��
select cast("123" as int)+1;
��ѧ����
round -- ��������((42.3 ->42))
select round(42.3);
ceil -- ����ȡ��(42.3=>43)
select ceil(42.3);
floor -- ����ȡ��(42.3=>42)
select floor(42.3);
�������ú���
nvl(value ,default value):���valueΪnull,��ʹ��default value,����ʹ�ñ���value.
select if(1>2 ,ture,false); # ����false
select coalesce(1,2,3,4,5) # ���ص�һ����Ϊ�յ� ���ⷵ�� 1
select coalesce(NULL,2,3,4,5) # ���ⷵ�� 2
hive�Ĵ��ں���(�ص�)
���ں���over���
������һ���������:��ÿ�����ŵ�Ա����Ϣ�Լ����ŵ�ƽ�����ʡ���mysql�����ʵ����
SELECT emp.*,avg_sal
FROM emp
J0IN (
SELECT deptno
,round(AVG(ifnull(sal, 0))) AS avg_sal
FR0M emp
GROUP BY deptno
) t
ON emp.deptno = t.deptno
ORDER BY deptno;
select emp.*,(select avg(ifnull(sal,0)) from emp B where B.deptno = A.deptno) from emp A;
ͨ������������ǿ��Կ���,���Ҫ��ѯ��ϸ��¼�;ۺ�����,����Ҫ�������β�ѯ,�Ƚ��鷳�����ʱ��,����ʹ�ô��ں���,�᷽��ܶࡣ��ô���ں�����ʲô��?
-1)���ں��������������������ڷ���������һ�֡�
-2)��һ�����ڽ�����ӱ���ͳ������ĺ�����
-3)���ں��������ڼ���������ij��ֵ,���;ۺϺ����IJ�֮ͬ����:����ÿ���鷵�ض���,���ۺϺ�������ÿ����ֻ����һ�С���˵���ں��ʶ�ÿ����ϸ��¼��һ�����,���оۺ��v�ƵIJ�ѯ
-4)��������ָ���˷����������������ݴ��ڴ�С,������ݴ��ڴ�С���ܻ������еı仯���仯��
-5)���ں���һ�㲻����ʹ��
-6)���ں�����Ҳ���Է��������

������
������order.txt
���� �������� ��������
saml,2018-01-01,10
tomy,2018-01-02,15
saml,2018-02-03,23
��
-- 1.����order��:
create table if not exists t_order(
name string,
orderdata string,
cost int
)row format delimited fields terminated by ',';
-- 2.��������
load data local inpath "./root/order.txt" into table t_order;
����:��ѯÿ����������Ϣ,�Լ�����������
�C 1.��ʹ�ô��ں���
-- ��ѯ������ϸ
select * from t_order;
#��ѯ����
select count(*) from t_order;
�C 2.ʹ�ô��ں���:ͨ����ʽΪ���ú���+over()����
select *, count(*) over() from t_order;
-- ��ѯ���صĽ��
saml,2018-01-01,10 3
tomy,2018-01-02,15 3
saml,2018-02-03,23 3
ע��:
���ں��������ÿһ�����ݵ�.
���over��û��ָ������Ĭ�ϴ��ڴ�СΪȫ�������
����:��ѯ��2018��1�·ݹ�����Ĺ˿�����ϸ��������
select * ,count(*) over()
from t_order
where substring(orderdate,1,7) = '2018-01';
-- ��ѯ���صĽ��
saml,2018-01-01,10 2
tomy,2018-01-02,15 2
distribute by �Ӿ�
��over�����н��з���,��ijһ�ֶν��з���ͳ��,���ڴ�С����ͬһ��������м�¼
����:�鿴�˿͵Ĺ�����ϸ���¹����ܶ�
select name,orderdate,cost,sum(cost) over (distribute by month(orderdate))
from t_order;
saml,2018-01-01,10 33
tomy,2018-01-02,15 15
saml,2018-02-03,23 33
����:�鿴�˿͵Ĺ�����ϸ��ÿ���˿͵��¹����ܶ�
select name,orderdate,cost,sum(cost) over (distribute by name, month(orderdate))
from t_order;
saml,2018-01-01,10 33
tomy,2018-01-02,15 15
saml,2018-02-03,23 33
sort by �Ӿ�
sort by�Ӿ�������������ǿ������(ǿ��:��ʹ������ʱ,���ڻ����������б��)
����:�鿴�˿͵Ĺ�����ϸ��ÿ���˿͵��¹����ܶ�,���Ұ������ڽ�������
select name,orderdate,cost,
sum(cost) over (distribute by name, month(orderdate)
sort by orderdata desc)
from t_order;
saml,2018-01-01,10 10
saml,2018-02-03,23 33
saml,2018-02-03,53 86
tomy,2018-01-02,15 15
hive��window�Ӿ�
���Ҫ�Դ��ڵĽ������ϸ���ȵĻ���,��ô��ʹ��window�Ӿ�,�����������漸��
PRECEDING:��ǰ
FOLLOWING:����
CURRENT ROW:��ǰ��
UNBOUNDED:���,
UNBOUNDED PRECEDING:��ʾ��ǰ������,
UNBOUNDED FOLLOWING:��ʾ��������յ�
����:�鿴�˿͵�ĿǰΪֹ�Ĺ����ܶ�
select name,
t_order.orderdata,
cost,
sum(cost) over(partition by name order by orderdata rows between UNBOUNDED PRECEDING and current row) as allCount
from t_order;
����:��ÿ���˿�������ε������ܶ�
select name,orderdate,cost,
sum(cost) over(partition by name order by orderdata rows between 2 PRECEDING and current row)
from t_order;
Hive�������
NTILE
ntile ��Hive��ǿ���һ���������������Կ�����:������������ݼ���ƽ��������ָ��������(num)�����,��Ͱ�ŷ����ÿһ�С��������ƽ������,�����ȷ����С��ŵ�Ͱ,���Ҹ���Ͱ���ܷŵ�����������1��
����:
select name,orderdate,cost,
ntile(3) over(partition by name), #����name���з���,�ڷ����ڽ������г�3��
from t_order;



hive����������

������ stu_score.txt

create table if not exists stu_score(
userid int,
classno string,
score int
)
row format delimited
fields terminated by ' ';
local data inpath './root/stu_score.txt' overwrite into table stu_score;

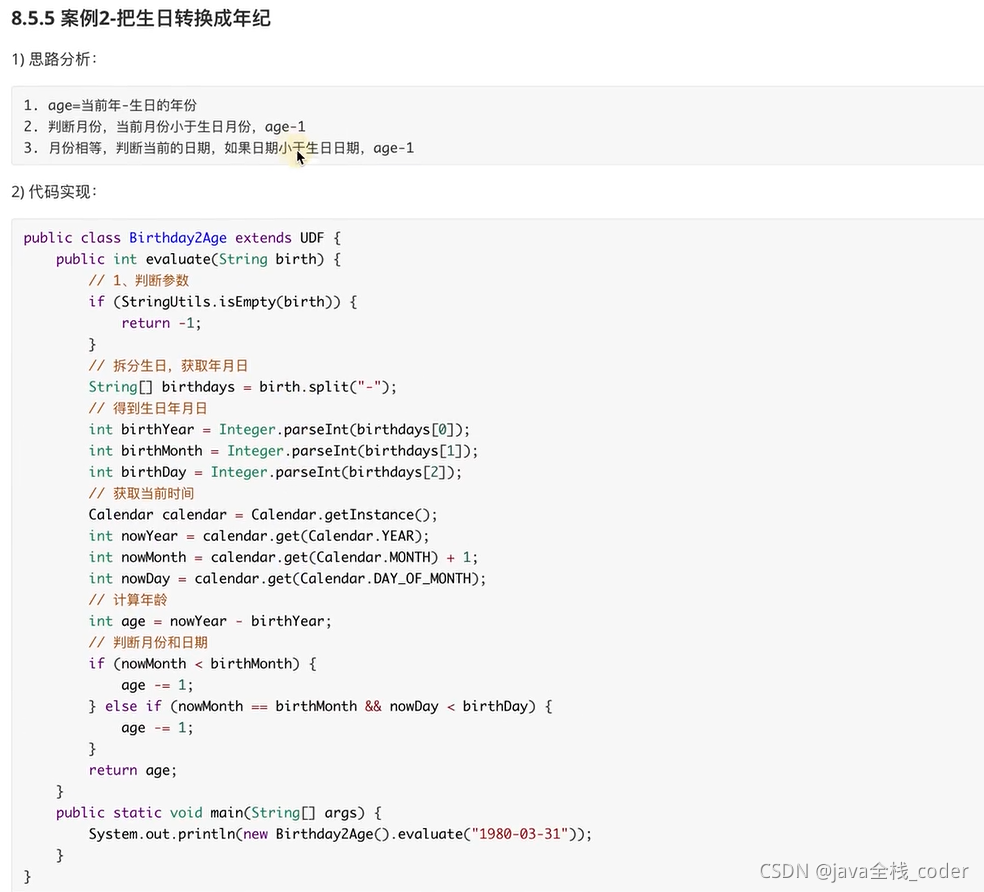
hive���Զ���UDF����
����

����
idea maven��ĿHiveFunction ��pom.xml��������maven��������
<property>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</property>
��� ConcatString
public class ConcatString extends UDF{
public String evaluate(String str){
return str+"!";
}
}
ע��
1.�̳�org.apache.hadoop.hive.al.exec.UDF
2.��дevaluate(),������������ɽӿڶ����,��Ϊ���ɽ��ܵIJ����ĸ���,�������Ͷ��Dz�ȷ���ġ�Hive����UDF ,���ܷ��ҵ��ͺ���������ƥ���evaluate()����
��һ��:�������(ֻ��Ե�ǰ��session��Ч)
��� ˫��package
HiveFunction-1.0.jar
�ϴ���ȥ
[root@tianqinglong01 ~]# mv HiveFunction-1.0.jar function.jar
# ����д�õ�UDF������ϴ���������,��jar�����ӵ�hive��classpath��
hive> add jar /root/function.jar
hive> create temporary function my_concot_str as 'com.qf.ConcatString'; #����һ���Զ������ʱ������
hive > show functions; # �鿴���Ǵ������Զ��庯��
hive > select my_concot_str("hello") # ʹ�ú��� ����hello!
# ɾ���Զ��庯��
hive> drop temporary function if exists my_concot_str;
�ڶ��ַ�ʽ:�����ļ�����(ֻҪ��hive����������������غ���)
1������д�õ��Զ������ϴ���������
2����hive�İ�װĿ¼�µ�binĿ¼�д���һ���ļ�,�ļ���Ϊ.hiverc
[root@tianqinglong01 hive]#vi ./bin/.hiverc
3�������Ӻ��������д�����ļ���
vi $HIVE_HOME/bin/.hiverc
add jar /root/function.jar
create temporary function my_concot_str as 'com.qf.ConcatString'; 4��ֱ������hive
jarһ�����libĿ¼��