һ����linux�spark����
1.����spark
spark�ٷ����ص�ַ:http://spark.apache.org/downloads.html ������ѡ��spark-3.1.2-bin-hadoop2.7�汾��
2.�ϴ�spark,����TDH�ͻ���
- �ϴ� spark-3.1.2-bin-hadoop2.7.tgz ��linux��/optĿ¼��
- ��manager����TDH�ͻ���,�ϴ���/optĿ¼��
- ��ѹspark��tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz
- ��ѹ�ͻ��ˡ�tar -xvf tdh-client.tar
3.����spark��������
- cd ${spark_home}/conf (ע:${spark_home}��/opt/spark-3.1.2-bin-hadoop2.7Ŀ¼)
- cp spark-env.sh.template spark-env.sh
- vim spark-env.sh
- ��ĩβ������������:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR=/opt/TDH-Client/conf/hdfs1
export YARN_CONF_DIR=/opt/TDH-Client/conf/yarn1
export HIVE_CONF_DIR=/opt/TDH-Client/conf/inceptor1
4.��sparkĬ������
- cd ${spark_home}/conf
- cp spark-defaults.conf.template spark-defaults.conf
- cp /etc/inceptor1/conf/inceptor.keytab ./
- klist -kt inceptor.keytab ,��¼��Principal
- vim spark-defaults.conf
- ��ĩβ������������:(ע:����Ⱥδ����ȫ,����Ҫ����spark.kerberos.keytab��spark.kerberos.principal����������)
spark.yarn.historyServer.address=tdh01:18080
spark.yarn.historyServer.allowTracking=true
spark.kerberos.keytab /opt/spark-3.1.2-bin-hadoop2.7/conf/inceptor.keytab
spark.kerberos.principal hive/tdh01@TDH
spark.executorEnv.JAVA_HOME /usr/java/jdk1.8.0_25
spark.yarn.appMasterEnv.JAVA_HOME /usr/java/jdk1.8.0_25
5.����hive-site.xml�ļ�
cp /opt/TDH-Client/conf/inceptor1/hive-site.xml ${spark_home}/conf/
6.����log4j.properties
- cd ${spark_home}/conf
- cp log4j.properties.template log4j.properties
7.����spark�еĿ�Դjar��
- �������15��hadoop���jar��,����1��zookeeper���jar��,����һ��guardian���jar��
- ��jar��:
hadoop-annotations-2.7.4.jar
hadoop-auth-2.7.4.jar
hadoop-client-2.7.4.jar
hadoop-common-2.7.4.jar
hadoop-hdfs-2.7.4.jar
hadoop-mapreduce-client-app-2.7.4.jar
hadoop-mapreduce-client-common-2.7.4.jar
hadoop-mapreduce-client-core-2.7.4.jar
hadoop-mapreduce-client-jobclient-2.7.4.jar
hadoop-mapreduce-client-shuffle-2.7.4.jar
hadoop-yarn-api-2.7.4.jar
hadoop-yarn-client-2.7.4.jar
hadoop-yarn-common-2.7.4.jar
hadoop-yarn-server-common-2.7.4.jar
hadoop-yarn-server-web-proxy-2.7.4.jar
zookeeper-3.4.14.jar
- ��jar��:
hadoop-annotations-2.7.2-transwarp-6.2.2.jar
hadoop-auth-2.7.2-transwarp-6.2.2.jar
hadoop-client-2.7.2-transwarp-6.2.2.jar
hadoop-common-2.7.2-transwarp-6.2.2.jar
hadoop-hdfs-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-app-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-common-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-core-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-jobclient-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-shuffle-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-api-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-client-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-common-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-server-common-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-server-web-proxy-2.7.2-transwarp-6.2.2.jar
zookeeper-3.4.5-transwarp-6.2.2.jar
federation-utils-guardian-3.1.3.jar
- jar���
/opt/TDH-Client/hyperbase/lib ---- 14��hadoop jar��
/opt/TDH-Client/hadoop/hadoop-yarn ---- 1��hadoop jar��
/opt/TDH-Client/hadoop/hadoop/lib ---- 1��zookeeper jar��
/opt/TDH-Client/inceptor/lib ---- 1��guardian jar��
����idea����spark����
1.�½�maven��Ŀ
2.��������maven����
spark�汾Ҫһ��,��3.1.2

3.�����
4.���
- Project Structure �C Artifacts
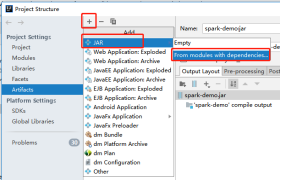
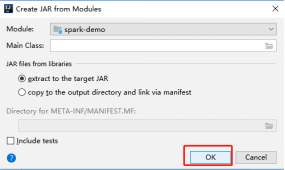
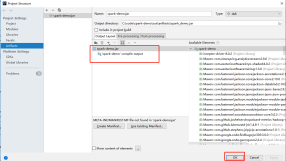
- Build �C Build Artifacts �C Build
- ��outĿ¼�¿��Կ�������õ�jar
5.������õ�jar�ϴ���{spark_home}��
������TDH��Ⱥ������spark����
1.localģʽ
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master local[3] --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
2.yarn-clientģʽ
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode client --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
3.yarn-clusterģʽ
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
�ġ�pycharm�pyspark��������
1.����spark����ѹ
��������spark��Ӧ�汾,��ѹ����ij��Ŀ¼����:C:\spark\spark-3.1.2-bin-hadoop2.7
2.�½�python����
�½�python����,ѡ��python�汾����ѡ�����python3.7�汾
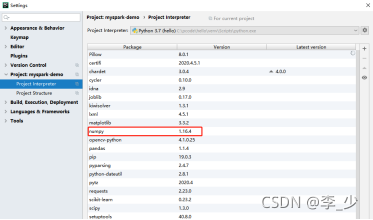
3.pycharm��������ص�����,����numpy��
4.�½�demo.py
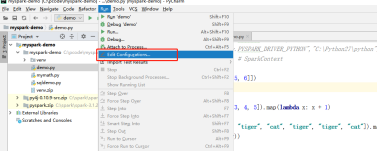
5.��Run-Edit Configurations.��ͼ���:
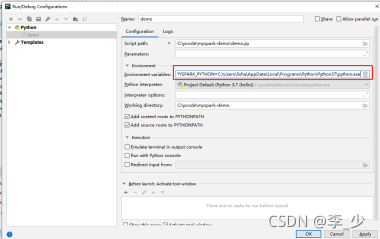
6.���û�������
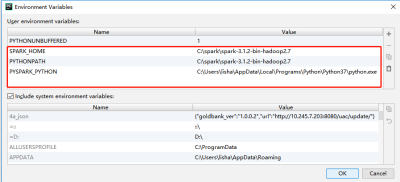
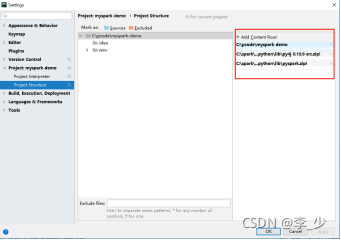
7.add content root
��Settings-perferences�е�project structure�е���ұߵġ�add content root��,����py4j-some-version.zip��pyspark.zip��(�������ļ�����C:\spark\spark-3.1.2-bin-hadoop2.7\python\lib��)��
8.��������,����run����
�塢�pyspark���л���
1.�ο���һ�½�
2.�貹��jar��
����TDH-Client/hadoop/hadoop/lib/jsch-0.1.54.jar ��{spark_home}/jarsĿ¼
����linux����python�����
1.���ذ�װanaconda
- a.�ٷ����ص�ַ:https://www.anaconda.com/download/#linux
- b.�ϴ���linux��������Ŀ¼��
- c.sh Anaconda3-2021.05-Linux-x86_64.sh
- d.һ·�س���yes
2.��anaconda���û�������
��/etc/profile�����������ݲ�source:
export PATH=$PATH:/root/anaconda3/bin
3.�����廪��condaԴ
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
4.���������
����ѡ��python3.7��1.16.4�汾��numpy
conda create --name py3env --quiet --copy --yes python=3.7 numpy=1.16.4
5.�鿴�´����������
/root/anaconda3/envsĿ¼��,���Կ������õ�py3env�ļ���,��python�����������������mymath.py������/root/anaconda3/envs/py3env/lib/python3.7Ŀ¼�¡�
6.ѹ�������,������{spark_home}Ŀ¼��
zip py3env.zip py3env/
cp py3env.zip /opt/spark-3.1.2-bin-hadoop2.7/
�ߡ���TDH��Ⱥ������pyspark����
1.localģʽ
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master local[2] /opt/spark-3.1.2-bin-hadoop2.7/demo.py
2.yarn-clientģʽ
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/py3env/bin/python
export PYSPARK_PYTHON=py3env/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode client --archives /opt/spark-3.1.2-bin-hadoop2.7/py3env.zip#py3env /opt/spark-3.1.2-bin-hadoop2.7/demo.py
3.yarn-clusterģʽ
export PYSPARK_DRIVER_PYTHON=py3env/py3env/bin/python
export PYSPARK_PYTHON=py3env/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --archives /opt/spark-3.1.2-bin-hadoop2.7/py3env.zip#py3env /opt/spark-3.1.2-bin-hadoop2.7/demo.py