����Ŀ¼
MySQL����:
- MySQL�ǿ�Դ��
- ֧�ִ������ݿ⡣���Դ���ӵ����ǧ������¼�Ĵ������ݿ�
- MySQL�������ڶ��ϵͳ,����֧�ֶ�������
- MySQL֧�ֶ���,�����Լ���Դ���������Լ���MySQL
MySQL���ܹ�
���ݿ����ṹ����Ϊ4��:���Ӳ㡢ҵ���������㡢�洢����㡢���ݴ洢��
- �ⲿ����
- ���Ӳ�
-
- �ṩ�ͻ��˺����ӷ���,���������û����ӡ��̴߳�������Ҫ���������
- ҵ����������
-
- SQL�ӿ�:�����û���SQL����,�������û���Ҫ��ѯ�Ľ��
-
- ������:SQL���������������֤,��������һ���ܳ��Ľű�,��SQL����ֽ�����ݽṹ,��������ṹ���ݵ���������,�Ժ��SQL���Ĵ��ݺʹ������ǻ�������ṹ,����ڷֽ�����в�������˵�����SQL����Ǵ���ġ�
-
- ��ѯ�Ż���:��SQL�����в�ѯ�Ż�,��ʹ�á�ѡȡ�CͶӰ�C���ӡ����Խ��в�ѯ��
-
- ����ͻ����:��ѯ���档�����ѯ���������еIJ�ѯ���,��ѯ���Ϳ���ֱ��ȥ��ѯ������ȡ���ݡ�����������������һϵ��С������ɡ���������桢��¼���桢Key���桢Ȩ�����
- �洢�����:���ݵĴ洢����ȡ,Ĭ����InnoDB
- ���ݴ洢��:�����ݴ洢��������,��Эͬ�洢��������ݽ��ж�д������
���ʽ�Ĵ洢����ܹ�����ѯ������������ϵͳ�����Լ����ݵĴ洢��ȡ����,���ּܹ����Ը���ҵ���������ѡ����ʵĴ洢���档
һ��SQL����ִ�й���
- Ӧ�ó��������ݿ����������һ������,Ȩ��У���������֤
- SQL�ӿڽ����û���SQL���
- ������������֤SQL���
- ��ѯ�Ż� ����SQL�������Ż�
- ִ����ִ�����,�Ӵ洢���淵������
1. ���ݿ�����,Ϊɶ��Ҫ���ݿ�?
���ݴ洢���ڴ�,��ȡ����,���Dz������ô洢��
���ݴ洢���ļ�,�������ñ���,������Ƶ����IO����,���ݶ�ȡ�����㡣
���ݴ洢�����ݿ�,�������ñ���,SQL����ѯ����Ч�ʸ�,�������ݷ��㡣
2. ���ݿ������ʽ
- ��һ��ʽ:ÿһ�ж������ٲ��
- �ڶ���ʽ:�ڵ�һ��ʽ�Ļ�����,����������ȫ����������,���������������е�һ����
- ������ʽ:�ڵڶ���ʽ�Ļ�����,��������ֻ����������,����������������������
2.1 ��ʽ���ŵ��ȱ��
�ŵ�
- �ظ����ݺ��ٻ���û��,�ĵ�����Ҳ����
- ��ͨ����С,���Ը��õط����ڴ���,ִ�в�����ȽϿ�
- �����ж����������ζ�ż����б�ʱ���ٵ�ʹ��DISTINCT����GROUP
ȱ��:��ʽ��ȱ��ͨ������Ҫ����
2.2 ����ʽ���ŵ��ȱ��
�ŵ�:���е����ݶ���һ�ű���,����Ҫ����
ȱ��:���Ƚϴ�,�������ݱȽ��鷳,���кܶ��ظ�������,ռ�õ��ڴ��Ƚ϶�
2.3 ���÷�ʽ���ͷ���ʽ��
�ڲ�ͬ�ı��д洢��ͬ���ض���
3. ���ݿ�����Ȩ�ı�
user��:��¼��������������������û���Ϣ
db��:��¼�����û����ڸ������ݿ�IJ���Ȩ����Ϣ
table_priv��:��¼���ݱ����IJ���Ȩ��
columns_priv��:��¼�����м��IJ���Ȩ��
host��:��db�����,�Ը����������ϵ����ݿ����Ȩ������ϸ�µĿ���
4. SQL����
4.1 SQL������
���ݶ������(DDL):drop,create,alter,truncate
���ݲ�������(DML):insert,delete,update
���ݲ�ѯ����(DQL):select
���ݿ�������(DCL):grant,remoke,commit,rollback
4.2 ����,��ѡ��,���� ���
- ����:�ڹ�ϵ����Ψһ��ʶһ��Ԫ������Լ���Ϊ����,����������һ������,Ҳ�����Ƕ�����������һ�𡣳���������ѡ����������
- ��ѡ��:��С����,û������Ԫ�صij���
- ����:Ψһ�Ҳ�Ϊ�յ�����,һ����ϵ��ֻ����һ������
- ���:һ����ϵ�д�����һ����������
4.3 ������ѯ
- ��������(CROSS JOIN)
SELECT * FROM A,B,C;����SELECT * FROM A CROSS JOIN B CROSS JOIN C#û���κι�������,����ǵѿ�����,�������ܴ�,û�����塣���صĽ�������б��������ij˻��� - ������(INNER JOIN)
����ʹ��������(INNER JOIN)SELECT * FROM A,B WHERE A.id=B.id����SELECT * FROM A INNER JOIN B ON A.id=B.id�����ͬʱ����ij�����������ݼ�¼�ļ���,INNER JOIN������дΪJOIN
�������ַ�Ϊ��ֵ����,����ֵ���Ӻ�������,�����Ӿ������ߵı������Լ� - ������(LEFT/RIGHT JOIN)
�����ӷ�Ϊ�����Ӻ������� -
- �������ֳ�Ϊ��������(LEFT OUT JOIN)����������е�������,�������������ұ���û��ƥ����,�������ұ��е��з��ؿ�ֵ��
-
- �������ֳ�Ϊ��������(RIGHT OUT JOIN)��ǡ���������෴,�����ұ��е�������,����ұ������������û��ƥ����,����������е��з��ؿ�ֵ��
- ���ϲ�ѯ(UNION��UNION ALL)
SELECT * FROM A UNION SELECT * FROM B
���ǰѶ�������������һ��,UNIONǰ�Ľ��Ϊ��,��Ҫע��������ϲ�ѯ������Ҫ���,��ͬ�ļ�¼�л�ϲ�,UNION ALL����ϲ��ظ��ļ�¼,UNION ALLЧ�ʸ���
- ȫ����(FULL JOIN)����������ұ��е������С���ij������һ����û��ƥ����,����һ���е��з��ؿ�ֵ��
4.4 �Ӳ�ѯ
- �Ӳ�ѯ�ǵ��е���,����ѯ��=,<,>�������
- �Ӳ�ѯ�Ƕ��е���,����ѯ��in
- �Ӳ�ѯ�Ƕ��ж���,��������where����,����select�Ӿ�����Ϊ�ӱ�
-- 1) ��ѯ��2011���Ժ���ְ��Ա����Ϣ
-- 2) ��ѯ���еIJ�����Ϣ,�������������е���Ϣ�ȶ�,�ҳ����в���ID��ȵ�Ա����
select * from dept d, (select * from employee where join_date > '2011-1-1') e where e.dept_id = d.id;
-- ʹ�ñ�����:
select d.*, e.* from dept d inner join employee e on d.id = e.dept_id where e.join_date > '2011-1-1'
4.4 ����Լ��
- NOT NULL
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY:����Ԥ���ƻ���֮�����ӵĶ���,Ҳ�ܷ�ֹ�Ƿ����ݲ��������,��������ָ����Ǹ�������һ�е�ֵ֮һ
- CHECK:���ڿ����ֶεķ�Χ
drop,delete,truncate������
| delete | truncate | delete | |
|---|---|---|---|
| ���� | DML | DDL | DDL |
| �ع� | �ɻع� | ���ɻع� | ���ɻع� |
| ɾ������ | ���ṹ����,ɾ�����е�ȫ�����߲��������� | ���ṹ����,ɾ�����е��������� | ���ṹ�Ѳ���,ɾ�����е�ȫ������ |
| ɾ���ٶ� | ��,����ɾ�� | �� | ��� |
5. ���ݿ�����ݸ�ʽ
��������
��������:tinyint,smallint,mediumint,int,bigint,�ֱ����1�ֽ�,2�ֽ�,3�ֽ�,4�ֽں�8�ֽڵ���������,�����Լ���unsigned���ԡ�
�������Ϳ��Ա�ָ������,ֻ��Ӱ����ʾ�ַ��ĸ���,��������ֵ�ĺϷ���Χ
bit:bit[(M)] : λ�ֶ����͡�M��ʾÿ��ֵ��λ��,��Χ��1��64�����M������,Ĭ��Ϊ1
bit�ֶΰ�ASCII����ʾ
������
С������:float(4�ֽ�,�洢���8λʮ������),double(8�ֽ�,�洢���18λʮ������),decimal(���65λ��)��
decimal�ܴ洢��BIGINT���������,�ܴ洢��ȷ��С����
decimalÿ4���ֽڴ�9λ,decimal(18,9),ǰ��9λ��4���ֽ�,С������һ���ֽ�,С�����9λ��4���ֽ�
��������
��������:year,date,time,datetime,timestamp
timestamp(4�ֽ�)
datetime(8�ֽ�)
CHAR��VARCAHR
�ı�����������:char,varchar,text,blob
char(len):len���255
varchar(len):len���65535,��1-3���ַ�������¼���ݳ���,��Ч�ֽ�����65532,��utf8��һ���ַ�ռ3���ֽ�,���len= 65532/3=21844(windowsʵ��21842,linux��21844),���������gbk,һ���ַ�ռ2���ֽ�,65532/2=32766(ʵ��32764)��
varchar��char������
char���ص�
- char��ʾ�����ַ���,�����ǹ̶���;
- ����������ݵij���С��char�Ĺ̶�����ʱ,���ÿո����;
- ��Ϊ���ȹ̶�,���Դ�ȡ�ٶ�Ҫ��varchar��ܶ�,�����ܿ�50%,������Ϊ�䳤�ȹ̶�,���Ի�ռ�ݶ���Ŀռ�,�ǿռ任ʱ�������;
- �ո��ʾռλ��
- ����char��˵,����ܴ�ŵ��ַ�����Ϊ255,�ͱ�����
varchar���ص�
- varchar��ʾ�ɱ䳤�ַ���,�����ǿɱ��;
- ����������Ƕ,�Ͱ��ն���洢;
- varchar�ڴ�ȡ������char�෴,����ȡ��,��Ϊ���Ȳ��̶�,���������,��ռ�ݶ���Ŀռ�,��ʱ�任�ռ������;
- �ո�һ���ַ��洢
- ����varchar��˵,����ܴ�ŵ��ַ�����Ϊ65532
��֮,������ܽǶ�(char����)�ͽ�ʡ���̿ռ�Ƕ�(varchar��С),����������������������ݿ��������������
varchar(50),50���
�����50���ַ�,varcahr(50)��varchar(200)�д�š�hello����ռ�ռ�һ��,�������������ǻ����ĸ����ڴ�,��Ϊorder by col����fixed_length����col���ȡ�����MySQL�汾��50��ʾ�ֽ���,���ڱ�ʾ�ַ���
�ı�ѡ�����
- ���ھ��������������˵,CHAR��VARCHAR����,��ΪCHAR�����ײ�����Ƭ��
- ���ڷdz��̵���,CHAR��VARCHAR�ڴ洢�ռ��ϸ���Ч�ʡ���ΪVARCAHR��Ҫһ����¼���ȵĶ����ֽڡ�
- ʹ��ʱҪע��ֻ������Ҫ�Ŀռ�,������������������ʱ�����ĸ����ڴ档��ΪMySQLͨ�������̶���С���ڴ���������ڲ�ֵ��
- ��������ʹ��TEXT/BLOB����,��ѯʱ��ʹ����ʱ��,�������ص����ܿ�������ʹ��MyISAM������ʱ��,������ò�ʹ��BLOB,��һ�����ɾ������õ�BLOB�ֶεĵط���ʹ��SUBSTRING(column,length)����ֵת�����ַ���,�����Ϳ���ʹ���ڴ���ʱ��,���ǽ�ȡ�ij��Ȳ��ܹ���,������ij�����ƻὫ�ڴ���ʱ��ת��ΪMyISAM������ʱ��
ENUMö��
ENUM���� ���泣�õ��ַ�������,�����б�ֵ������ѹ����1��2���ֽ���,���ڲ��Ὣÿ��ֵ���б��е�λ�ñ���Ϊ����,��.frm�ļ��б��桰���֨C�ַ�������ӳ���ϵ�����������ڲ��洢������������
MySQL�洢IP��ַ
create table IP(addr int unsigned);
insert into IP values(INET_ATON(��192.168.0.1��));
select INET_NTOA(addr) from IP;
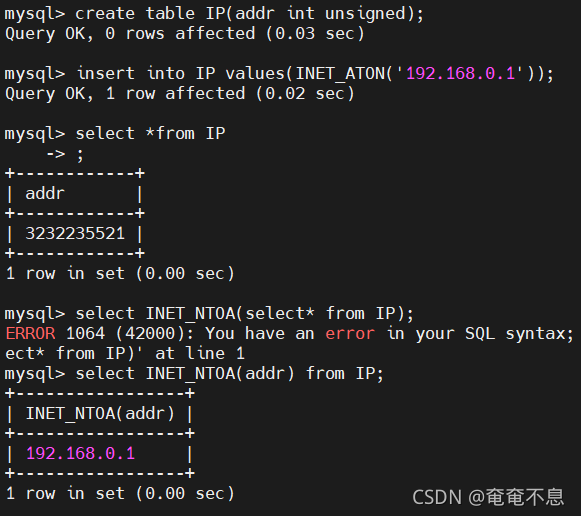
����
������һ�����ݽṹ,ʵ�����������ݽṹ��B��,B+��,hash����InnoDBĬ��ʹ��B+�����������ݿ����м�¼������ָ�����ļ�����ʽ�洢�ڴ����ϡ�
����ÿ�δӴ��̶�ȡ16K,��ȡ16K����32������,����512�ֽ�,������ֵ��(id int(8�ֽ�),��ַ(8�ֽ�)),512/16=32,ÿһ���������Դ洢32����ֵ��,
����һ�δ���IO,1�����ڵ�,31���ڶ���ڵ�,31*32=992 �м�¼,��Ҫ���Ǿ۴�������
���������ٽ�,�˷ѿռ�(��һ��B+��),��������(�������ݵ�ʱ����Ҫȥά������)
������������������,��ͨ�����ؽ��лر���ѯ,���Ƿ������������ǡ�
������int����char?���char�Ƚ�С,������char�Ͻ�,һ����int�Ͻ�����,B+����ÿ����Ҷ�ӽڵ㶼Ҫ�洢����ֶ�,����ֶ�Խ��,һ��IO��ȡ�Ľڵ��Խ��,��ô���B+����Խ��,����ÿ���ڵ�ռ���ڴ�ռ�Ҳ��Ƚϴ�,��������Ƚϴ�Ļ�������IO����
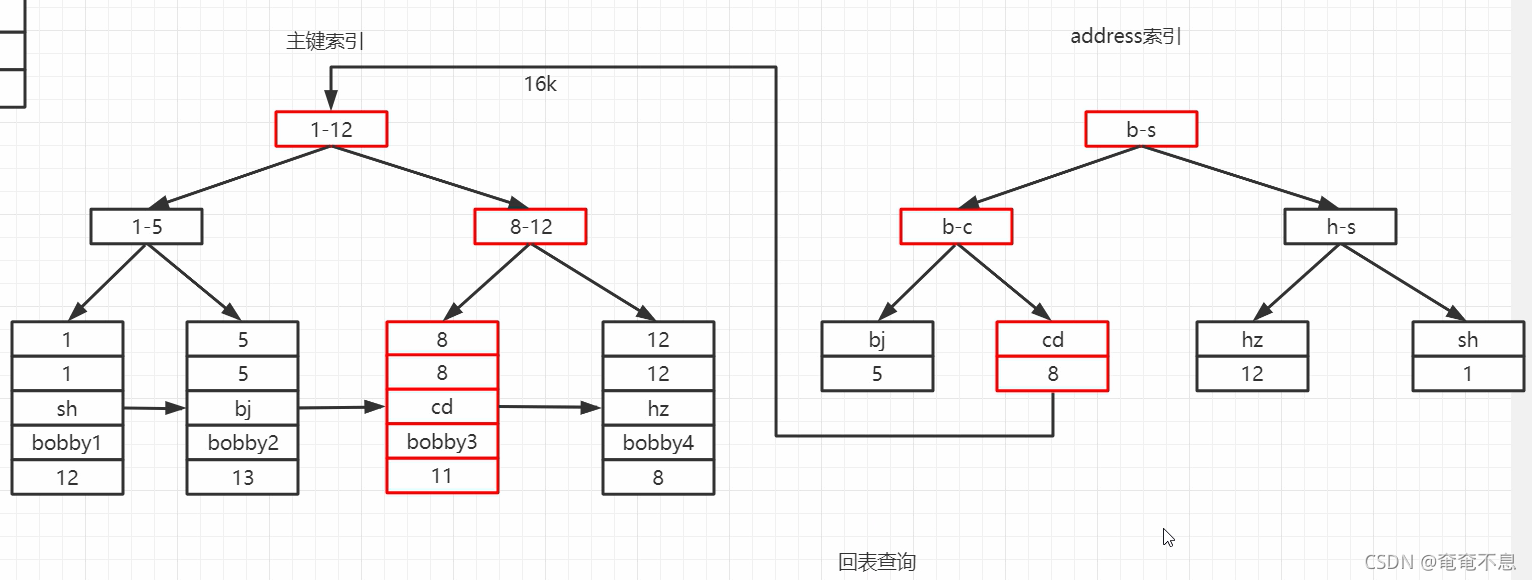
B+��������۴�������������ʱ����Ҫ���лر���ѯ
�ۼ���������������������,����Ϊ
- ��InnoDB��,���������������,������������ͱ���Ϊ�۴�����,
- û������ʱ��ѡ���һ��Ψһ�ǿ������������۴�����,
- û�к��ʵ�Ψһ����ʱ,InnoDB�ڲ�������һ������������Ϊ�ۼ�����,�������������һ��6�ֽڵ���,�����ݲ��������
- ����������������Զ�������,�����˲�������еľ۴������������⡣�۴������������Ȼ�ᵼ�´�Χ���ݵ������ƶ�,�˴�������IO�������ĺܴ�����۴�����������,Ҳ�ᵼ���������̵��ƶ�,���ǻ����page����,����Ƭ����������Ҳ��Ӧ���ľ۴�������
��α���ر���ѯ
��������
�����������������ǵ�һ����ط���
alter table table_name add index ��idx_name_age�� (name,age);
��������
���Ҫ��ѯ��ÿ���ֶζ�����������,��ô�����ֱ�����������в�ѯ���������ԭʼ����,ֻҪ��һ���ֶ�û�н�������Ҳ�����ȫ��ɨ��,��ͽ������������ǡ���select��ֻд��Ҫ�IJ�ѯ�ֶ�,�����������ǵĸ��ʡ�
���������ݽṹ
B���������ڲ��ڵ��ż���ֵ,��Ƶ�����ʵĽڵ���ڿ������ڵ㴦���Դ������ȵ����ݵķ���Ч�ʡ�
B+������
ÿ����Ҷ�ӽڵ�洢���ٸ�Ԫ��,��һ��IO��ȡ���ٵ��������Լ�ÿ���ڵ�ռ�õĿռ��С����
B+���ĸ߶�������,һ��Ҳ��3-4��
B+�����B�����ŵ�:
- B����ÿ���ڵ㶼�洢�˼���ֵ,��B+����Ҷ�ӽڵ�ֻ����˼�,ֵ��������Ҷ�ӽڵ����档������һ�㶼�Ǻܴ��,������һ���Խ����е�����ȫ����ȡ���ڴ���,Ҫ�����εĶ�ȡ,��B+���ķ�Ҷ�ӽڵ�ֻ�洢�˼�,һ���Ծ��ܶ�ȡ���������,������IO��д����,��IO��д������Ӱ����������Ч�ʵ�������ء�
- B���ʺ��������,B+���ʺ����������˳�����,B��Ԫ�ر���Ч�ʵ���,��B+��Ҷ�ӽڵ���ָ��������,ֻ����Ҷ�ӽڵ�Ϳ���ʵ���������ı���
- B+���IJ�ѯЧ�ʸ����ȶ�,ÿ�β�ѯ����Ҫ�Ӹ��ڵ��ߵ�Ҷ�ӽڵ�,��ѯЧ���൱��B���IJ�ѯ�൱����һ�ζ��ֲ���,�����ҵ���Ҷ�ӽڵ�ͷ�����
- ��ɾ��¼ʱB+�����¸���,B+��Ҷ�ӽڵ�������йؼ���,���������������ṹ�洢,�������Ժܺõ������ɾЧ��
hash
- hash��ֵ���ʺܿ�,���Dz�֧�ַ�Χ��ѯ��˳���ѯ
- hashÿ�ζ�������лر���ѯ
- ��ij����ֵ�д����ظ�ʱ,�����hash��ͻ,����Ч��
- hash���ܽ���ģ��ƥ���Լ���������������ǰƥ��,hash�����IJ���Ԥ����
��������
- ��������
��֤Ψһ��,�ֶ�Ӧ�ö�
������ʽ:
- ��������ʱ�����ֶε����ֱ��ָ��primary key
- ��������ʱ�������primary key(�ֶ���)
- alter table ���� add primary key(�ֶ���)
���������ص�:һ�ű�ֻ����һ����������,�ǿղ����ظ�,һ������Ϊ������id
- Ψһ����
������ʽ:���������������ķ�ʽ����,ֻ�ǰ�Primary key ����unique
Ψһ�����ص�:һ�ű������ж��Ψһ����,�����ظ����ǿ���Ϊ��,���ָ����not null���Կ��Եȼ�������
- ��ͨ����
������ʽ:
- �ڱ���������index(�ֶ���)
- alter table ���� add index(�ֶ���)
- create index index_name on table_name(�ֶ���)
Ψһ��������ͨ�������ֶ������Զ��,��������������
CREATE INDEX�ɶԱ�������ͨ������UNIQUE������(����,���ܴ���PRIMARY KEY����)
- ȫ������
��MySQL��ʹ��ȫ������,�洢�������ʹ��MyISAM,���Dz�֧������,��������Ľ���ȫ�ļ���,����ʹ��sphinx�����İ�(coreseek)
alter table table_name add fulltext(�ֶ���)
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (��database��);
InnoDB��MyISAM������
| InnoDB | MyISAM | |
|---|---|---|
| ���� | ֧������,����ȫ | ����ȫ,��֧������ |
| �� | ֧���м��� | ֻ֧�ֱ����� |
| ȫ������ | ��֧��ȫ������ | ֧��ȫ������ |
| �洢�ṹ | frm����ṹ,���ݺ����������idb | ÿ�ű��洢�������ļ���,frm����ṹ,myd������,myi������ |
| ������ | һ������������� | ������,count(*)��Ҫȫ��ɨ�� |
| hash���� | ֧�� | ��֧�� |
| �������� | innodb�Ǿ۴�����,����������Ҷ�ӽ��洢��������(��Ч),������������Ҷ�ӽ��洢������������������,��������������ܸ�Ч | �Ǿ۴�����,Ҷ�ӽ��洢�������ݵ�ַ,��Ҫ��һ��Ѱַ�õ����� |
���÷�Χ
û���ر������,һ��Ĭ��innodb��
MyISAM:Ч�ʿ�,������С��Ӧ��,��ƽ̨���ܺ�(�����洢���ļ�����ʽ),������select�����(���ٴ洢�ͼ�����������ȫ������,��֤��ѯ�ٶ��㹻��),��д���������
InnoDB:֧������,���update delete��Щ�����Ƚ϶�,��������,��֤����������
innodb������Ĵ�����
- ���뻺��
- ����д
- ����Ӧhash����
- Ԥ��
����
������һ��DML������,��Щ�����������һ���������,��һ��DML���Ҫô�ɹ�,Ҫôʧ��,��һ�����塣
�����ACID����
- ԭ���� Atomicity,������Ӧ����С��ִ�е�λ,���ɷָ�,�����ִ�н��Ҫô�ɹ�Ҫôʧ��
- һ���� Consistency,����ִ�еĽ�������һ��һ����״̬ת������һ��һ���Խ���������ݿ�ֻ���������ύ�ɹ���״̬ʱ,���ݿ��һ����״̬�����ϵͳ���з����ж�,����ij��������δ��ɶ������ж�,��δ��ɵ��������ύ�����ݿ���,��ʱ�����ݿ�ʹ���һ�ֲ���ȷ��(��һ��)��״̬,������ݿ��һ��������ԭ���Ա�֤�ġ�
- ������ Isolation,���������ִ�л�������,�κ������ڲ��IJ�����������������˵���Ǹ����
- �־��� Durability,����һ���ɹ��ύ,�����ݿ������ĸı䶼Ҫ��¼�����ô洢��
���������Ե�����
���
����1����������,����2��ȡ�˸��º������,������1����ijЩԭ��ع���,����2��ȡ�����ݾ������
�����ظ���
����1��ȡ������,��ʱ�����������������������������,����1�ٴζ�ȡ��ʱ���������Ѿ���һ����
�ö�
��������1�����ݽ�����ͳ�ƻ���ȫ���Եĸ���,����2��ʱ��������һ���µ�����,����1�ٴ����鿴��ʱ��ͻᷢ��ͳ�ƽ����һ��������һ������û�б�����,��������˻þ�һ��
����ĸ������
| ���뼶�� | ��� | �����ظ��� | �ö� |
|---|---|---|---|
| ��ȡδ�ύ | �� | �� | �� |
| ��ȡ���ύ | �� | �� | �� |
| ���ظ��� | �� | �� | �� |
| �ɴ��л� | �� | �� | �� |
��
�����ݿ��в��������ʱ��,����ά���������ݴ���Ļ��ơ�
�����������ȷ�
������
ҳ����
���
SQL�Ż�
��ζ�λ��Чsql���,�Կ��ܵ�Ч��ԭ�����Ų�,�ȴ���������,�������û������,�������ݷ���,���Ѳ�ѯ��,����һЩ�ض������Ż�������
ִ�мƻ�
���ڲ�ѯ���,����Ҫ���Ż���ʽ����ʹ������,ִ�мƻ�������ʾ���ݿ��������SQL����ִ�е���ϸ���
- id:��ʾһ����ѯ�и����Ӳ�ѯ��ִ��˳��,idԽ��Խ�ȱ�ִ��,id��ͬʱִ��˳���������;idΪnullʱ��ʾһ�������,����Ҫʹ������ѯ,��������UNION�Ȳ�ѯ�����
- select_type:ÿ���Ӳ�ѯ�IJ�ѯ����
- type:�����ֶ�
-
- ALL ɨ��ȫ��
-
- index ��������,���������ļ�ȫɨ��
-
- range ����������
-
- ref ʹ�÷�Ψһ������������,��ͨ����
-
- consts:���������һ��ƥ����
-
- ea_ref��join��ѯ��ʹ��PRIMARY KEY ������UNIQUE NOT NULL��������
- possible_keys:����ʹ�õ�������
- key:ʵ��ʹ�õ�����
- key_length:��������,�ڲ���ʧ���ȵ������,ԽСԽ��
- rows:��ʾ����Ľ������Ŀ,������һ��ȷ��ֵ
- ref
- extra
-
- using index
-
- using where
-
- using where,using index
-
- using index
�����ӳٹ��������Ӳ�ѯ�Ż������ҳ������
SELECT a.* FROM ��1 a, (select id from ��1 where ���� LIMIT 100000,20 ) b where a.id=b.id
����ѯ��־
ʹ��
show variables like ��slov_query_log��
�鿴����ѯ��־�Ƿ���,�����OFF,����ʹ��
set GLOBAL slow_query_log = on
������,������datadir�²���һ��xxx-slow.log���ļ�
���ٽ�ʱ��,��λ��
set long_query_time=0.5
ʵ��ʱӦ�ôӳ�ʱ�����õ��̵�ʱ��,����������SQL�Ż���
�鿴��־,һ��SQL�������������õ��ٽ�ʱ��ͻᱻ��¼��xxx-slow.log��
����ѯ���Ż�
����ѯ���Ż�����Ҫ����������ԭ����ʲô,��û����������?load�˲���Ҫ������?����������̫��?
- ���ȷ������,�Ƿ��д����������Ҫ���ֶ�
- ��������ִ�мƻ�,�鿴���ʹ�����������,֮������������������
- �������Ѿ��������Ż�,�Ϳ��Կ����Dz���������̫��,�Ӷ����Ƿֱ�������
-
- ˮƽ�ֱ�
-
- ��ֱ�ֱ�
ΪʲôҪ��������,����id����uuid
�����������������ű���Ψһ�Եı���,�趨������,�ں�����ɾ�IJ��ʱ����ܸ��ӿ��١�
�Ƽ�ʹ������ID,��innodb��,������������Ϊ�۴��������ڵ�,����������Ҷ�ӽ���ϰ�˳��洢��������ȫ�����ݡ�����ID�Ļ�,��������ֻ��Ҫ���ϵ��������;uuid�Ļ�,���ڵ�����ID��ԭ����ID��С��ȷ��,����ɴ�Χ�����������ƶ�,page����,����Ƭ���������,���վ��Dz��������½���
not null
nullֵ��ռ�и�����ڴ�
MVCC
����ACID��undo log,redo log
�����ݿ�
alter���,�����ݿ������Ҫָ���������ݿ���ַ���,У�����
alter database mytest charset=gbk;
ɾ�����ݿ�
drop database db_name;
ִ��ɾ��֮��Ľ��:
- ���ݿ��ڲ���������Ӧ�����ݿ�
- ��Ӧ�����ݿ��ļ��б�ɾ��,����ɾ��,��������ݱ�ȫ����ɾ
������ָ�
�鿴�������
��
show processlist
���������鿴����Щ�û����������ݿ�,������쳣�û����ܴ�����������ݿⱻ������
�鿴���ṹ
desc table_name;
������
create table users (
id int,
name varchar(20) comment ���û�����,
password char(32) comment ��������32λ��md5ֵ��,
birthday date comment �����ա�
) character set utf8 engine MyISAM;
�ڱ��в����¼
insert into users values(1,��a��,��b��,��1982-01-04��),(2,��b��,��c��,��1984-01-04��);
����������ͻ,����ʹ�ø��²���:insert into ���� values(ֵ�б�) on duplicate key update �ֶ�1=ֵ, �ֶ�2=ֵ
mysql�г��õ����ֲ������ݵ����:
insert into��ʾ��������,���ݿ��������,��������ظ��ᱨ��;
replace into��ʾ�����滻����,���������PrimaryKey,
����unique����,������ݿ��Ѿ���������,�����������滻,���û������Ч�����insert intoһ��;
insert ignore��ʾ,������Ѿ�������ͬ�ļ�¼,����Ե�ǰ������;
�����ֶ�
alter table users add assets varchar(100) comment ��ͼƬ·���� after birthday;
�ı�����name,���䳤�ȸ�Ϊ60
alter table users modify name varchar(60);
ɾ������ij���ֶ�
alter table users drop password;
�ı���
alter table users rename to emploee;
�������Ը���
alter table emploee change name xingming varchar(60);
���ֶ���Ҫ��������
ɾ����
drop table emploee;