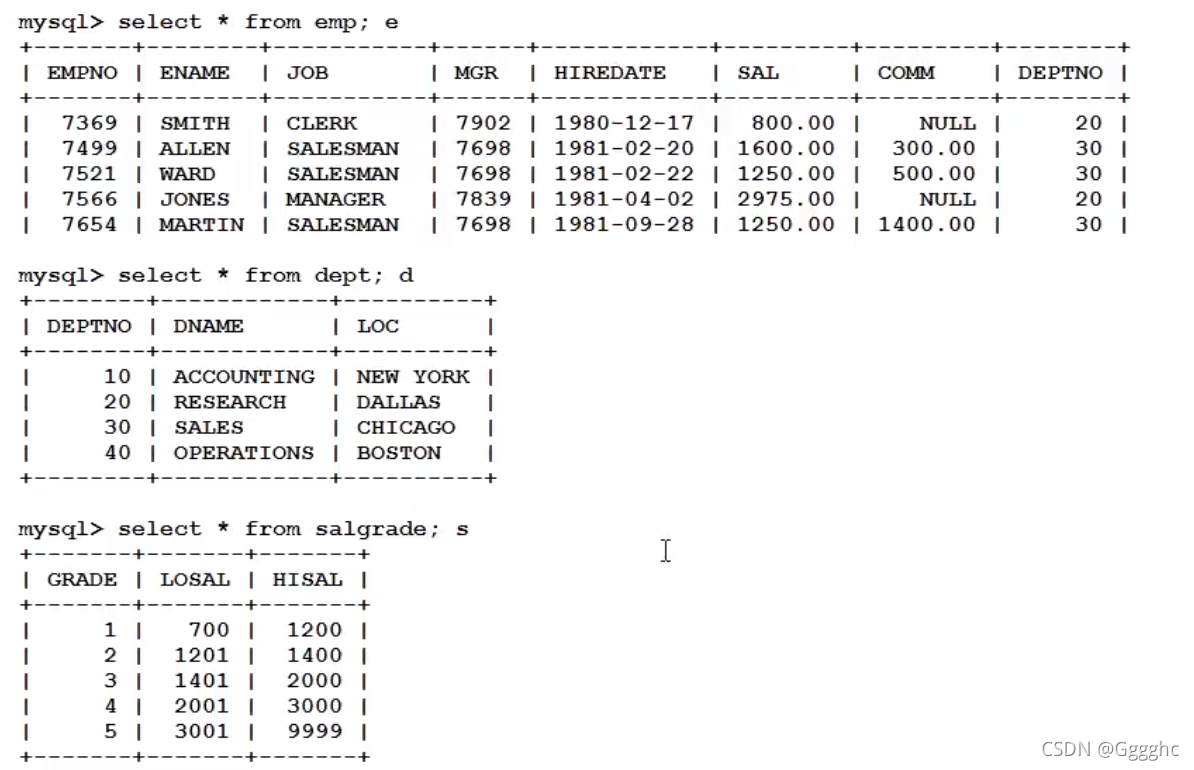
Mysql
表:
dept

emp
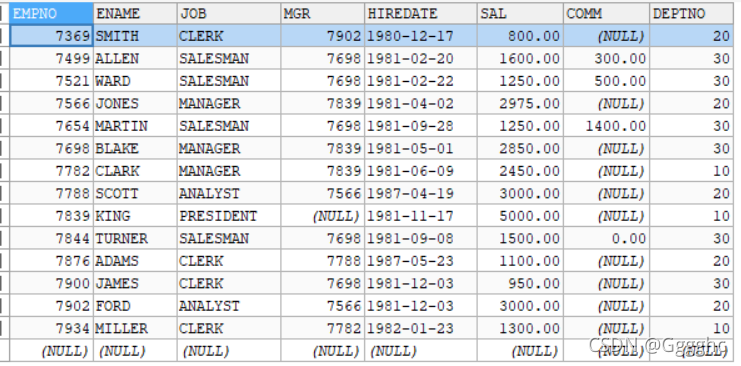
salgrade

1. 分组函数(多行处理函数)
-
多行处理函数的特点:输入多行,最终输出一行。
-
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
注意:分组函数在使用的时候,必须先分组再使用,如果没有分组,默认整张表为一组
-
分组函数使用时要注意哪些?
- 分组函数自动忽略null,不需要提前对null进行处理
- 分组函数中count(*) 和 count(具体字段)有什么区别?
- count(具体字段):表示统计该字段下所有不为null的元素的总数
- count(*):统计表当中的总行数。(只要有一行数据就count++)
- 分组函数不能直接使用在where子句中
- 所有的分组函数可以组合起来一起用
2. 分组查询(重要)
2.1 group by
-
selecy ... from ... group by ... -
将之前的关键字顺序组合,执行顺序为
select ... from ... where ... group by ... order by ...
-
为什么分组函数不能直接使用在where后面?
-
分组函数在使用的时候必须先分组
-
select sum(sal) from emp;为什么可以?
因为select 在group by之后执行
-
-
找出每个工作岗位的最高工资和?
-
思路:按照工作岗位分组,然后对工资求和
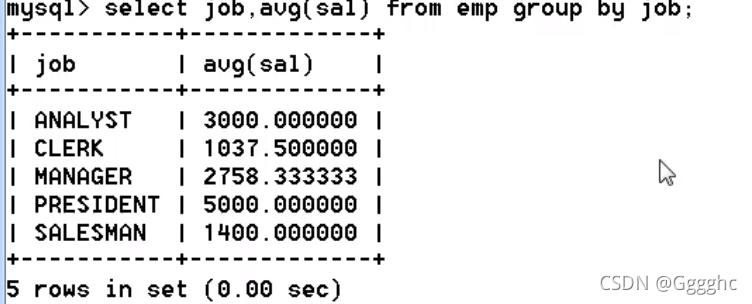
select job,sum(sal) from emp group by job;
-
-
找出每个部门的最高工资
- 思路:按照部门编号分组,求每一组的最大值
select deptno,max(sal) from emp group by deptno;
-
找出每个部门,不同工作岗位的最高工资
- 思路:两个字段联合成一个字段看
select deptnp,job,max(sal) from emp group by deptno,job;
2.2 having
使用having可以对分完组的数据再一次过滤,having不能代替where,必须和group by 联合使用
-
找出每个部门的最高薪资,要求显示最高薪资大于3000
思路1:1.找出最高薪资,按照部门编号分组,求每一组最大值 2.再找大于3k
select
deptno,max(sal)
from
emp
group by
deptno
having
max(sal) > 3000;
<--以上sql语句,执行效率比较低!-->
? 思路2:先将大于3k 的都找到,再分组
优化策略:优先使用where
select
deptno,max(sal)
from
emp
where
sal > 3000
group by
deptno;
-
where没办法的情况,找出每个部分平均薪资,要求显示平均薪资高于2500的
思路:1.找出部门平均薪资 2.在找高于2500
select
deptno,avg(sal)
from
emp
group by
deptno
having avg
(sal)>2500;s
2.3 select 语句总结
执行顺讯:from -> where -> group by -> having -> select -> order by
从某张表中查询数据,先经过where条件筛选出有价值的数据,对有价值的数据进行分组,再使用having继续筛选。
-
找出每个岗位的平均薪资,要求显示平均薪资大于1500,除MANAGER之外,要求按照平均薪资降序
思路:
select job,avg(sal) as avgsal from emp where job <> 'MANAGER' group by job having avg(sal) > 1500; order by avgsal desc;
3. distinct 关键字
-
把查询结果取出重复记录
注意:原表数据不会被修改,只是查询结果去重。
-
distinct只能出现在所有字段的最前方
4. 连接查询
4.1 什么是连接查询
从一张表单独查询,称为单表查询。
跨表查询,多张表联合起来查询数据,被称为连接查询。
4.2 表连接的分类方式
- 内连接:
- 等值连接
- 非等值连接
- 自连接
- 外连接:
- 左外连接(左连接)
- 右外连接(右链接)
- 全连接
4.3 怎么避免笛卡尔积现象?
当两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数,是两张表条数的乘积,这种现象被称为笛卡尔积现象。
连接时加条件,满足这个条件的记录被筛选出来就可以避免笛卡尔积现象。
-
查询每个员工所在的部门名称
select ename,dname from emp,dept where emp.deptno = dept.deptno // 最终查询结果条数为14,但是匹配次数还是56,只不过是4选1 //表起别名 select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno
4.4 内连接
4.4.1 等值连接
-
查询每个员工所在部门名称,显示员工名和部门名
// SQL92语法 select e.name,d.name from emp e,dept d where e.deptnp = d.deptno // SQL99语法 // inner 可以省略,带着inner可读性更好 select e.ename,d.dname from emp e inner join dept d on e.deptno = d.deptno; // 条件是等量关系SQL99优点:表连接的条件是独立的,链接之后,如果还需要进一步筛选,再往后继续添加where
4.4.2 非等值连接
-
找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级
select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;// 条件不是等量关系
4.4.3 自连接
- 查询员工的上级领导,要求显示员工名和领导名
技巧:一张表看成两张表,emp a 员工表,emp b 领导表
select
a.ename as '员工名', b.ename as '领导名'
from
emp a
join
emp b
on
a.mgr = b.empno;
4.5 外连接
-
找出员工的部门名
// 内连接 select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno; // 内连接的特点:完成能够匹配上这个条数的数据查询出来// 外连接(右外连接) select e.ename,d.dname from emp e right outer join // outer可以省略 dept d on e.deptno = d.deptno; // 左外连接 select e.ename,d.dname from dept d left join emp e on e.deptno = d.deptno;right:表示将join关键字右边的这张表看成主表,主要是为了将这张表的数据全部查询出来,捎带着关联查询左边的表
在外连接当中,两张表连接,产生主次关系
内连接,两张表平等,没有主次
思考:外连接的查询结果条数一定是 大于等于 内连接的查询条数
-
查询每个员工的上级领导,要求显示所有员工的名字和领导名
select a.ename as '员工名', b.ename as '领导名' from emp a left join emp b on a.mgr = b.empnp;内连接14条,外连接15条,有KING
4.6 多表查询
语法:
select
...
from
a
join
b
on
a和b的连接条件
join
c
on
a和c的连接条件
join
d
on
a和d的连接条件
一条SQL中内连接和外连接可以混合,都可以出现。
- 找出每个员工的部门名称以及工资等级,要求显示员工名、部门名、薪资、薪资等级
select
e.ename,e.sal,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno = d.deptnp
join
salgrade s
on
e.sal between s.losal and s.hisal;
-
找出每个员工的部门名称以及工资等级还有上级领导,要求显示员工名、领导名、部门名、薪资、薪资等级
select e.ename,e.sal,d.dname,s.grade from emp e join dept d on e.deptno = d.deptnp join salgrade s on e.sal between s.losal and s.hisal left join // 必须加left外连接,内连接不显示空值,会少一条数据 emp m on e.mgr = m.empno;
5. 子查询
- 什么是子查询?
- select语句中嵌套select语句,被嵌套的称为子查询
5.1 where子句中的子查询
-
找出比最低工资高的员工姓名和工资
思路:1.查询最低工资 2.找出大于最低的 3.合并前两条语句
select ename,sal from emp where sal > (select min(sal) from emp);
5.2 from子句中的子查询
注意:from后面的子查询,可以将子查询的查询结果当做一张临时表
-
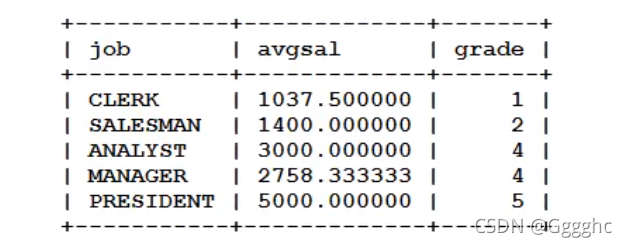
找出每个岗位的平均工资的薪资等级
思路:
1.找出平均工资(按照岗位分组求平均值)
2.把以上的查询结果当做一张真实存在的表 t,查询工资等级表 s
3.t表和s表进行表连接,条件:t表avg(sal) between s.losal and s.hisal
select
t.*,s.grade
from
(select job,avg(sal) as avgsal from emp group by job) t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;
5.3 select后面出现的子查询(了解)
-
找出每个员工的部门名称,要求显示员工名,部门名
select e.ename,(select d.dname from dept d where e.deptno = d.deptno) as dname from emp e;