安装分布式的Hadoop集群的环境
准备工作:在安装分布式的Hadoop集群之前需要我们准备好若干台能够连接到网络的虚拟机,采用ifconfig命令可以查看该虚拟机的IP,最好通过apt命令安装vim编辑器方便修改配置文件。
1.安装JDK
找到对应的JDK的安装包,我安装的是JDK1.8_162版本的,如果大家需要的话,我会整理我用到的软件上传到网盘分享给大家。
cd /usr/local
sudo mkdir jvm #创建/usr/local/jvm目录用来存放JDK文件
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/local/jvm #把JDK文件解压到/usr/local/jvm目录下之后采用vim编辑器 ,编辑该用户的环境变量文件,添加JDK目录到环境变量中(注意需要在每台虚拟机上都配置JAVA环境)
vim ~/.bashrc##打开该用户的环境变量
#########在文件末尾添加如下的内容
export JAVA_HOME=/usr/local/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc#使得新更改的内容立即生效之后可以使用如下命令查看是否安装成功,若出现了Java的版本号则成功安装,否则的话检查前些步骤哪里有问题。
java -version
###若出现如下信息,证明安装成功
hadoop@ubuntu:~$ java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)2.配置 ssh无密码登录本机和访问集群的机器
首先为了便于区分集群中的机器,需要修改其在shell环境中显示的主机名,在各台虚拟机中都执行如下的命令,在master主机中添加master,在slave01节点添加slave01.......,然后重启虚拟机即可看见终端发生变化。
sudo vim /etc/hostname 修改集群中虚拟机的/etc/hosts文件,将主机名与IP对应。添加如下的配置:
修改集群中虚拟机的/etc/hosts文件,将主机名与IP对应。添加如下的配置:
127.0.0.1 localhost
10.13.0.33 master
10.13.0.34 slave01
10.13.0.35 slave02
10.13.0.36 slave03
10.13.0.37 slave04?检查是否可以登陆到本机,执行ssh localhost命令,若登陆失败的话需要安装openssh-server服务并且生成ssh密钥(若登陆成功的话跳过此步骤)
sudo apt-get openssh-server
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#若提示authorized_keys文件不存在时,需要自己创建一个这样的空白文件,该命令是将ssh密钥添加到authorized_keys文件中的。在保证了集群中的主机都可以连接到本地的localhost后,还需要让master主机免密登录到slave节点 ,执行如下命令将master主机生成的密钥传送给每台slave主机。
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave03:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave04:/home/hadoop/
#scp命令是ssh协议传输文件的,其格式为:scp 待传输的文件 目标主机的用户名@目标主机的IP:目标主机存储位置 成功执行以上命令后,可以到每台的slave节点上执行 ls ~命令可以查看到master主机传输的id_rsa.pub文件,随后需要将master主机的密钥添加到各自的节点上 ,在每台slave机器上执行如下命令即可:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub在这里提醒一下,一定要保证master节点和slave节点的登录的用户名一致,不一致的话会导致后续产生一些问题。这样就可以在master主机实现了免密登录到各台slave节点,执行如下命令即可登录到其他节点:
ssh slave01
exit#退出该连接3.安装Hadoop2.7.1
我实验环境使用的Hadoop的版本比较低,是2015年发布的2.7.1版本的Hadoop。我想Hadoop2.X版本的安装以及配置的步骤相差不大,大家有兴趣的话可以安装一下较新版本的Hadoop,这里我就不再尝试了。我们依旧选择将Hadoop安装在/usr/local/目录下,如果获取了Hadoop的安装包的话就执行如下的命令在master节点上进行解压缩(无需在slave节点上做操作)。
sudo tar -zxf ~/下载/hadoop-2.7.1.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.1/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改hadoop文件夹的所有者随后编辑~/.bashrc文件,添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin随后执行source ~/.bashrc使环境变量生效。
4.Hadoop集群配置
Hadoop的配置文件都在/usr/local/hadoop/etc/hadoop目录下面,我们需要先修改slaves,添加如下内容:
slave01
slave02
slave03
slave04修改core-site.xml文件,最终内容如下所示:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>修改hdfs-site.xml文件,最终内容如下所示,其中3代表着是在hdfs上面有多少份数据的备份:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>?修改mapred-site.xml(复制mapred-site.xml.template,再修改文件名),最终内容如下所示:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml文件,最终内容如下图所示:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property><!--接下来两个变量是防止因为资源不足而杀死yarn进程的-->
??? <name>yarn.nodemanager.pmem-check-enabled</name>
??? <value>false</value>
</property>
<property>
??? <name>yarn.nodemanager.vmem-check-enabled</name>
??? <value>false</value>
</property>
</configuration>
注:以上的配置文件只在master端进行配置,之后我们会复制到各个slave节点。如果在此之前跑过伪分布式的模式或者是local模式的话,在切换到集群模式之前,需要删除临时文件和日志文件
cd /usr/local/
rm -rf ./hadoop/tmp # 删除临时文件
rm -rf ./hadoop/logs/* # 删除日志文件完成后需要将位于~/目录下面的hadoop.master.tar.gz文件复制到所有的slave节点上,并进行解压操作,执行如下命令:
scp ./hadoop.master.tar.gz slave01:/home/hadoop
scp ./hadoop.master.tar.gz slave02:/home/hadoop
scp ./hadoop.master.tar.gz slave03:/home/hadoop
scp ./hadoop.master.tar.gz slave04:/home/hadoop在slave节点上执行如下命令:
sudo rm -rf /usr/local/hadoop/
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop至此我们需要搭建的Hadoop的分布式集群就搭建完毕了,接下来我们进行测试 ,在master端执行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format #非常值得注意的是,在Hadoop集群中有节点正在运行时不要进行namenode的格式化,否则会产生非常不好的影响,会导致master端的ID与slave端的ID不一致,导致HDFS启动不起来
sbin/start-all.sh在输出一些列的INFO之后,若未出现error,则证明成功启动了Hadoop集群。大多数会出现JAVA_HOME is not set 的字样,这时不要惊慌,先停止了Hadoop集群,使用vim编辑器打开位于/usr/local/hadoop/etc/hadoop/hadoop-env.sh文件,找到JAVA_HOME=${JAVA-HOME}修改为自己的java安装路径即可(每个节点上都需要此操作),如下图所示:
?这样保存以后再重新启动Hadoop集群就能够成功启动了。
这时我们可以运行jps命令来分别观察master端和slave端的正在运行的进程,正常情况下如下图: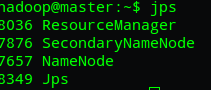

若出现了resourcemanager和nodemanager不存在的情况,建议关闭hadoop集群再重新启动一次看一下。
若出现了datanode经常性掉线的问题的话,建议看一下其他的博客,好像还挺常见的,大概率是多次格式化namenode节点导致的clusterID不一致导致的,可以查看master和slave节点位于hadoop安装目录下的tmp/dfs/下的name或者data文件夹下面的VERSSION文件,里面有clusterID,修改为一致就可以。但是我没有遇到过以上的问题,嘻嘻0.0。
再次强调一下,除了第一次格式化namenode之后不要随便进行namenode进行格式化操作,如果需要对namenode进行格式化时应该先停止Hadoop集群,并且删除Hadoop安装目录下的tmp和logs文件夹(在所有节点上都进行此步骤),再进行格式化。
5.Hadoop的一些常用的命令
1.启动关闭Hadoop集群
cd /usr/local/hadoop
sbin/start-all.sh #启动hadoop集群
sbin/stop-all.sh #关闭hadoop集群2.查看HDFS文件的使用情况,正常的话会出现如下图的信息:
#所有命令都需要在hadoop的安装目录下使用
hadoop dfsadmin -report #这样会显示HDFS集群的使用情况
如果以上所有信息都是0的话,就是HDFS异常了,查看日志文件来定位错误信息,具体问题具体分析。我之前是因为节点的用户名不一致导致了datanode连接不到master主机而导致的HDFS初始化失败,惨重的教训。
3.上传到HDFS中文件,以及读取位于HDFS中的文件
hdfs dfs -ls / #查看hdfs中位于/下的文件
hdfs dfs -mkdir /aaa #在hdfs中新建aaa文件夹
hadoop fs -put /usr/local/hadoop/README.md /aaa #上传位于本地的README.md文件到hdfs系统中的/aaa路径下
hadoop fs -ls /aaa #查看是否上传成功
file:///usr/local/Spark/data/graphx/followers.txt #这样的路径读取的是本地文件
hdfs:///usr/local/Spark/data/graphx/followers.txt #这样的路径读取的是存在hdfs中的文件
4.附上学习大数据学习的一个好用的网站,是厦门大学林子雨老师团队做的一些学习资料。大家可以上去学习一下,拓展一下自己的知识。好用的网站
写在本节最后的话,因为作者也是初学大数据不久的菜鸟,有很多东西也是靠自己不断地百度,查看博客得来的,也有部分问题未能得到妥善的解决,只是分享一下作者面临的诸多问题以及分享一下解决的经验。所以有同学在实验过程中遇到了不一样的问题时,欢迎各位在本文下面评论区留言,大家也可以互相讨论学习一下,我也会积极回复大家的问题的。祝愿大家在赵老师带的大数据原理与技术的课程中学到很多对自己有帮助的知识。