˵��ǰ��
? �������Ƶ�ڽ���Դ��,����������������Ժ������˴��,��ʦ�ں���ҡ�˺ü����Ҳ���,Ȼ��ͱ�������һ��ΰ����������ѧ���Լ���Դ�롭��
? ��ô����?�ǾͿ���!�ڿ�֮ǰ�һ������ٶ�����һ�¿�Դ��ĺô����·�Ϊ֪��ij����ԭ��
����Ϊʲô��Դ�롱
�ܶ���һ������һ���ĸ���:Դ���ڹ�����������?�ô�����?�ܳ�һ��ʱ������Ҳ������������,��Ϊ��Щ����û�³�Դ����˾�����װ,ֻ��Ϊ��������ǵıƸ���ѡ�
��Ϊʲô�һ�Ҫ��Դ����?һ�տ�ʼΪ������,����Ϊ�˽�������е�����,�ٺ������Ǹ���ϲ���ˡ�˵�ĺ��������н��˾���;˵��ί����Ǻ���(�ײ�����ôʵ�ֵ�);˵�IJ����ŵ��ǶԺںеĶ������õ�û��,���ô�;˵�ļ�ֱ�����������Ҽ�ֵ,Ϊ�˸��ߵ�н�ʴ���(����������ļ�����˵����Ǹ)��
Դ�������ǿ���ѧ���ܶණ��,ѧϰ���˸�Ч�Ĵ�����д��ѧϰ���˶����ģʽ������ʹ�á�ѧϰ���˶������ܹ��IJ���,�ȵȡ�����㻹���ҳ����еIJ���,��ô��ϲ��,��Ҫ������!��ʹ�ù�Ȼ��Ҫ,��֪��Ϊʲô��ôʹ��ͬ����Ҫ����ģ����ѧϰ,��ģ���д��¡�
��Դ�벻��Χ��(������������,����������ȥ),����������˲������,������˲����ȥ;�����ǿ������,��ᷢ��(���dz����,Ƥ!)���ڷ������,Դ��ĺ�������������!

��!��Դ��!��Դ��!
�˻�ģʽ
1.̽��ǰ������
һ������:
FileInputFormat ��InputFormat����ʵ����,ʵ����Ƭ��
TextInputFormat��FileInputFormat����ʵ����,ʵ�ֶ�ȡ������
��̽��һ��TextInputFormat��ô��ʵ���˶�ȡ���ݵ�����!
���µô��ύ��ҵ��ʼ˵�𡭡�
�Ժ�����ύ��ҵ���и���ŵ�˼·:�ύjob�C>Ȼ��->mapreduce���м�ʡ�����ɲ���(Ϊʲô��д��Ҷ��ö���)
���ύjob�ķ����ĵ�ע�����ҷ�������������İ�,��������ûѧӢ�����վ������!
/**
* Internal method for submitting jobs to the system.
��:ϵͳ�ύ�ļ����ڲ�������
*
* <p>The job submission process involves:
��:��ҵ�ύ�����漰��:
* <ol>
* <li>
* Checking the input and output specifications of the job.
��:�����ҵ�����������Ĺ��
* </li>
* <li>
* Computing the {@link InputSplit}s for the job.
��:������ҵ��������Ƭ��
* </li>
* <li>
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
��:�����Ҫ�Ļ�,Ϊ��ҵ�ķֲ�ʽ�������ñ�Ҫ�ļ�����Ϣ��
* </li>
* <li>
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
��:������ҵ��jar�������õ�hdfs��MapReduceϵͳ��Ŀ¼
* </li>
* <li>
* Submitting the job to the <code>JobTracker</code> and optionally
* monitoring it's status.
��:�ύ��ҵ��jobTracker(�������ҵ����)Ȼ���ѡ��������״̬��
����!���˼·���������������!
�ܽ�һ��:
-
��ҵ�ύ�����漰��: 1. **�����ҵ�����������Ĺ��** 2. **������ҵ��������Ƭ��** 3. **�����Ҫ�Ļ�,Ϊ��ҵ�ķֲ�ʽ�������ñ�Ҫ�ļ�����Ϣ��** 4. **������ҵ��jar�������õ�hdfs��MapReduceϵͳ��Ŀ¼** 5. **�ύ��ҵ��jobTracker(�������ҵ����)Ȼ���ѡ��������״̬��**
�����ǰѽ����Ŀ��۽�����Ƭ���ơ����������Ұ��ҡ�.�����ҵ���д��Ƭ�ĵط���,����writeSplits������

����������:
writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
�㻹��˵,ȷʵ���������������ǿ���6��7�л���û�����,������жϾ��ǿ���ʹ�õ�Mapper�Ǿɰ�Ļ����°��,��,�����߽�writeNewSplits����
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
����������ô����ѽ,�����һ��ǵõ�һ���Ǽ�������ļ��Ĺ��,�������Ҫ����������ô���ġ������߽�������job.getInputFormatClass������

��Ȼ���Ǹ��ӿڷ���,����Ҫ�������ҵ��������ʵ����,��˵����߿��ڵ�С�̵������ľ���ʵ����,����:

����֪�������ύ��job��map��reduce��,�����п��ܵ�����JobContext��ʵ�ַ���,��˵��ȥ
/**
* Get the {@link InputFormat} class for the job.
*
* @return the {@link InputFormat} class for the job.
*/
@SuppressWarnings("unchecked")
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
ע����ֻҪ���ڵ�ʮ�д�������,INPUT_FORMAT_CLASS_ATTR��ֵΪTextInputFormat.class,����,�����Dz�ָ�������ļ�����ʱ����,Ĭ�ϵĹ�����ı�������,��Ҳ����Ϊʲô�����ڶ��ļ���Mapreduce��ʱ����Ҫָ�����������ļ������!
��Ҳ��֤��ΪʲôTextInputFormat�����ȡ���ݵ�����!
����û��, ��ʵ����������̽��������!
2.̽��ing
̽��1�Ľ��ۻ��ǵ���?
FileInputFormat ��InputFormat����ʵ����,ʵ����Ƭ����
TextInputFormat��FileInputFormat����ʵ����,ʵ�ֶ�ȡ��������
��ô��ͨ�������ҵ�����ʵ����?����õ���!
�����Ǹ�С����,�����ҵ�InputFormat���������,����ͨ��(ALT+7)��ṹ����ķ���:
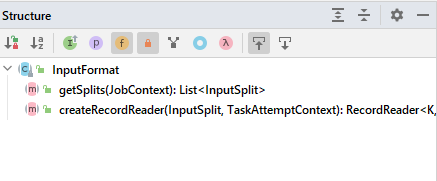
����������������ǡǡ����Ƭ(getSplits)�Ͷ�ȡ����(createRecordReader)������Ŀ��רһ��

�������̵�,�ҵ�����ʵ������-FileInputFormat��

��������?������!
����λע��!!!Դ������!!!
������2021��11��12��21:37:56,����ʲôʱ�����˯����?
Դ��
����λע��,����ע����С���Լ�������д��,��������Դ������д�ġ�
public List<InputSplit> getSplits(JobContext job) throws IOException {
//StopWtch�Dz�ʱ��λ,����������Ϊ��λ,���↑ʼ��ʱ,����β���ǿ��Թ۲쵽�ж�Ӧ��stop����,����ͳ�Ƹ��з�ʹ�õ�ʱ��,���ù�ע
StopWatch sw = new StopWatch().start();
/*�����������ϴ�ֵ��Ϊ��Ƭ����Сֵ,ǰ���ǹ̶�ֵ1,���߿�������,���û�����õĻ�ʹ��Ĭ��ֵ,������mapred-site.xml��"mapreduce.input.fileinputformat.split.minsize"
�鿴��,Ĭ��ֵΪ0��
*/
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//��Ƭ���ֵĬ��ΪLong���͵����߽�ֵ2**63-1,Ҳ����ͨ��"mapreduce.input.fileinputformat.split.maxsize"���á�
long maxSize = getMaxSplitSize(job);
// generate splits
//�½�һ��InputSplit���͵ļ����������������Ƭ����,Ҳ��splits��Ϊ�������ķ���ֵ
List<InputSplit> splits = new ArrayList<InputSplit>();
//ͨ��job�ṩ������·���õ���ǰĿ¼�������ļ�������
List<FileStatus> files = listStatus(job);
//����˼��,�����ļ���
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
//�����б����ļ�������
for (FileStatus file: files) {
//�����Ŀ¼�����Ǻ����ļ���������
if (ignoreDirs && file.isDirectory()) {
continue;
}
//��ȡ�ļ�·��
Path path = file.getPath();
//��ȡ�ļ������ݴ�С
long length = file.getLen();
//������ǿ��ļ�
if (length != 0) {
//BlockLocation[]�����������λ�á������鸱������������Ϣ�Լ�������Ԫ����(�������������ļ�ƫ���������ȡ��Ƿ���)
BlockLocation[] blkLocations;
//�ж�instanceof�����ʽ�������������ұ߲���Ԫ�Ƿ���ͬ�������ڼ̳й�ϵ
//����DZ����ļ�
if (file instanceof LocatedFileStatus) {
//��ȡ��λ����Ϣ
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
//�����Ǽ�Ⱥ�ļ�
FileSystem fs = path.getFileSystem(job.getConfiguration());
//��ȡ��λ����Ϣ
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
//�Ƿ����Ƭ,ͨ������ȷ��,������ļ�����ѹ����,�ᡣ
if (isSplitable(job, path)) {
//��ȡ���ݿ��С
long blockSize = file.getBlockSize();
//������Ƭ�Ĵ�С-->һ���������Զ���ǿ��С 128M
//�����ڲ�ͨ�� Ĭ�ϵ������Ƭֵ�����ݿ��С�Ľ�Сֵ ����С��Ƭ��С �ȽϵĽϴ�ֵ��Ϊ��Ƭ��С
/*��������
*protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
*/
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//���ļ���ʣ���С��ֵ
long bytesRemaining = length;
//�жϵ�ǰ�ļ���ʣ�������Ƿ�Ҫ������Ƭ����ʽ:bytesRemaining)/splitSize > SPLIT_SLOP
//���:�ļ�ʣ���С/��Ƭ�Ĵ�С �Ƿ�> split_slop(ֵΪ1.1) �����������ֵ>1.1�ͻ������,����ͽ�ʣ��������Ϊһ��Ƭ������Ŀ����Ϊ����ÿһ��MapTask���������ݸ��ӵľ��⡣
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//��ȡ��Ҫ�зֵĿ����ļ��е�ƫ����,�Ӵ˴���ʼ��
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//����һ����Ƭ�����뵽�����Ƭ�����������
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//�ļ�ʣ�����ݼ�ȥ����Ƭ�Ĵ�С
bytesRemaining -= splitSize;
}
//��������ж��ǽ������ļ�ʣ���С/��Ƭ�Ĵ�С <= split_slop(ֵΪ1.1) �����,Ҳ����˵ֻʣ�����һ�����,���ʱ���ٴ���һ��Ƭ�����ӵ���Ƭ����������б�����Ƭ��Բ�������
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
}
//�����else��Ӧ�����Ϸõ��Ƿ�����з�,���ܵĻ��ͻῪʼ��־����debug��Ϯ����
else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
//���������ļ����Ȳ�Ϊ0�������зֵ�������ִ�е�ֻ����һ����Ƭ����(��Ϊ�����з�˵�����ļ���С)
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
}
//�����Ӧ�����ļ�����Ϊ0�����
else {
//Create empty hosts array for zero length files
//����һ���յĶ�������
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
//���������ļ���������Ϊ����Դ
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
//ֹͣ��ʱ,����ӡ��Ƭ��Ŀ�ͻ���ʱ��
//�����зֺ�Ķ���
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
˵�ں���
���ڵ�ʱ����2021��11��12��23:30:42��
��һ�������̽��Դ��,���е�ϲ����������̽���ĸо�,һ��������һ��,���´��Լ��ܶ�εġ�