1.创建一个大表
create database 昵称mark01;
2.切换到nicmark01大表当中去
use nicmark01
3.创建一个表格(table)

create table student;
4.创建student表中的内容
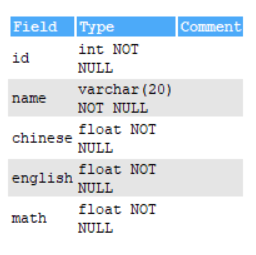
create table student(
id int;
name varchar(20)
chinese float
english float
math float);
默认的engine为innodb,默认的charset是utf8
5.输入表格内容
insert into student value(1,'name',80,80,80),(2,'name2',90,90,90)....
这里的value中的数据顺序要与create表的顺序一致
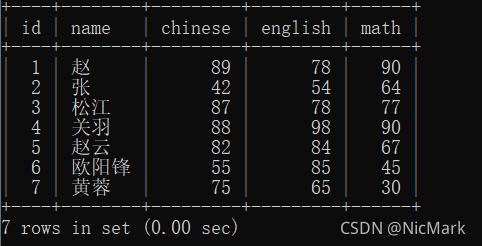
6.展示表格内容
select * from student;
展示某一列的话,则如下
select math from student;
8.按数学成绩降序排列
select * from student order by math desc;
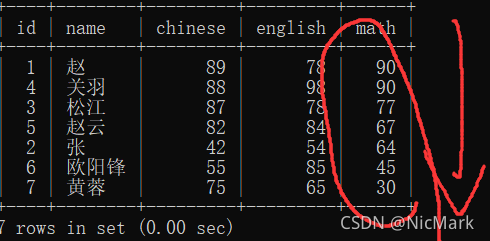
排序默认为升序排序.
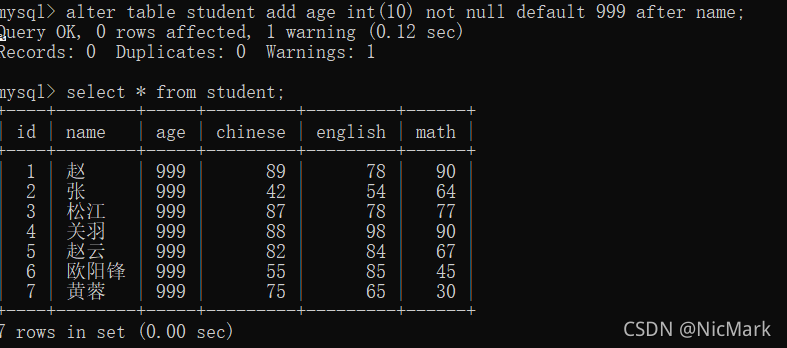
9.插入一个新列
alter table student add age int(10) not null default 999 after name;
修改某一个列的长度
alter table student modify name varchar(88) not null default '';
删除一个列
alter table student drop age;
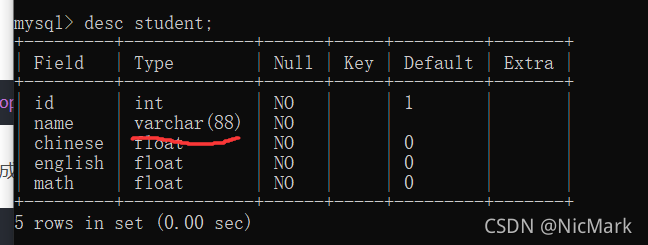
然后我们来看一下表的构成
desc student;
10.字符串函数
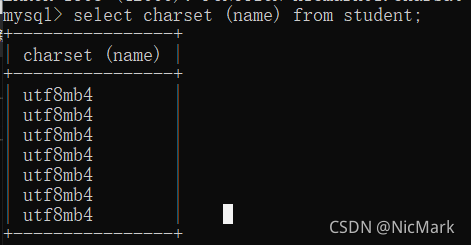
我们看一下某一列的编码方式
select charset(name) from student;
然后我们如果说想要通过字符串拼接两个列输出的话,就这样子
select concat(name+'的语文成绩是'+chinese) from student;
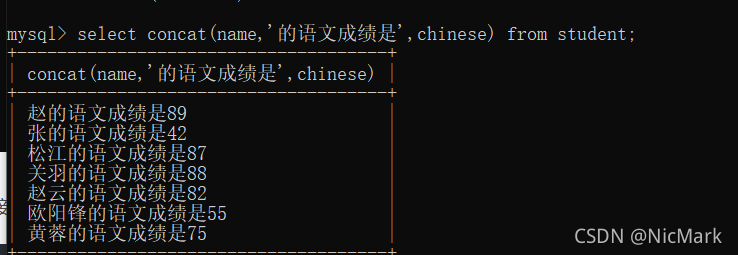
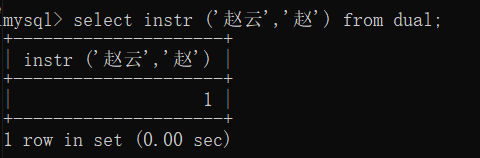
如果我们想查询某个字符或者某个字符串在整个字符串的起始位置,则如下
select instr('赵云','赵') from dual;
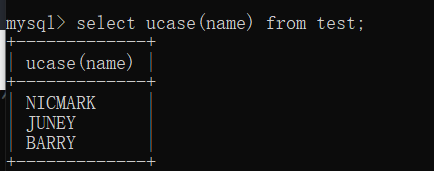
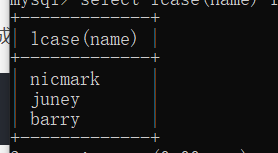
如果我们想将某个字符串统统转换成大写/小写,则可以用ucase/lcase函数
select ucase(name) from test;
select lcase(name) from test;
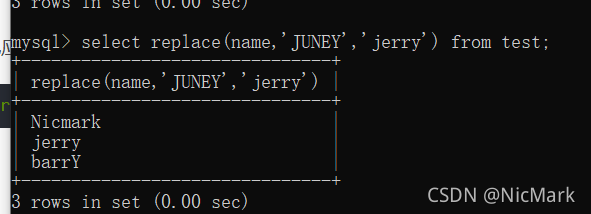
然后我们发现juney录错名字了!他应该叫jerry,那么我们可以用replace函数
select replace(name,'JUNEY','jerry') from test;
(原数据表是大写的)- -
我们尝试比较下…字符串的大小~~
strcmp函数
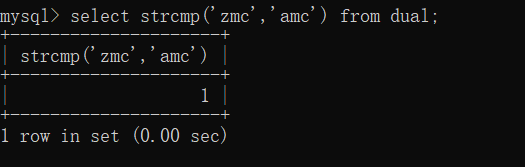
select strcmp('zmc','zmc1hsaa') from dual;

那如果说我们比较zmc与amc呢?结果便是如此
再想想,要是比较zmc与znc呢?
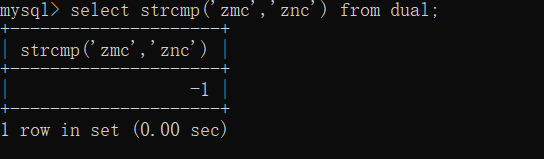
所以啊我们发现,这个字符的比较,是按照ASCII码值按位比较
这不🈲让我回想起来数电的数值比较器・・・・・・
要是我们想让某个字符串只显示某个范围区间的内容呢?于是我们的substring函数登场了
select substring(name,1,2) from student;
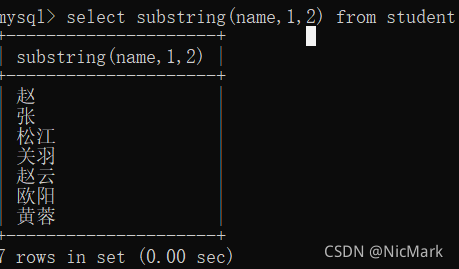
区间[1,2]。
暂时就这些,剩下的继续跟进学习
~~