课题背景

经过一学期的大数据导论学习后,我们突然接到了结业大作业――进行一次大数据分析项目的通知。
刚刚学习了一些大纲类型的知识的我们自然是不知所措的,经过资料查阅后我们决定通过虚拟机搭建Hadoop集群进行伪分布式计算完成该项目。
然后就开始了安装了20次虚拟机的折磨之路本来打算录视频全程教程的,奈何时间紧迫,只能写一个博客帮助学弟学妹少走弯路
文中环境:
- Hadoop-v3.3.1
- JDK-8u202-linux-x64(1.8.202)
- CentOS-7-2009
我对Hadoop的理解
鄙人知识浅薄,这部分还在写
Hadoop 安装与配置
Ⅰ 环境搭建
-
虚拟机环境:VMWare Workstation 16 Player
- 选择该软件的原因有
- 普适性强:网络上有很多相关资料可供查阅
- 免费:支持正版!苦逼大学生自然是用不起企业级的Pro版本的~~(如果家境优渥可以考虑一下)~~
- 该软件的问题:没有虚拟网络编辑器,DHCP动态分配可能导致后续网段不稳定
- 选择该软件的原因有
-
系统选择:CentOS 7 64-bit
- CentOS,大家的选择!稳定又轻量!而且还免费!
- 安装的时候可以选择最小安装,毕竟安一个桌面没啥用
-
安装步骤
虚拟机安装
- 在VMWare Player(以下简称Player)中新建一个虚拟机,在选项中选择“稍后安装”
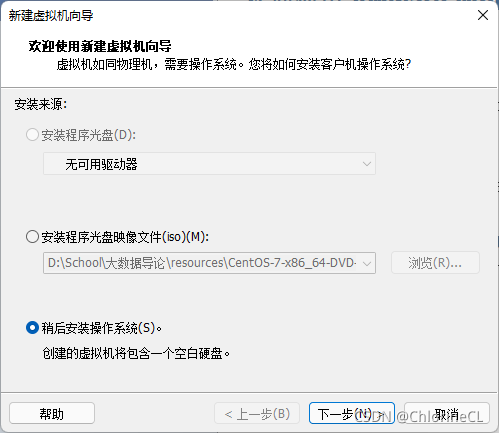
【如果此时选择直接安装会默认安装桌面GUI,会占用大量资源且没有作用当然如果你电脑强到可以随便霍霍当我没说】
- 在VMWare Player(以下简称Player)中新建一个虚拟机,在选项中选择“稍后安装”
-
一路下一步,命名和路径自己选择,硬件都用默认的就可以【此处仅针对课题的需求,实际需求请根据自己的需要自定义】
-
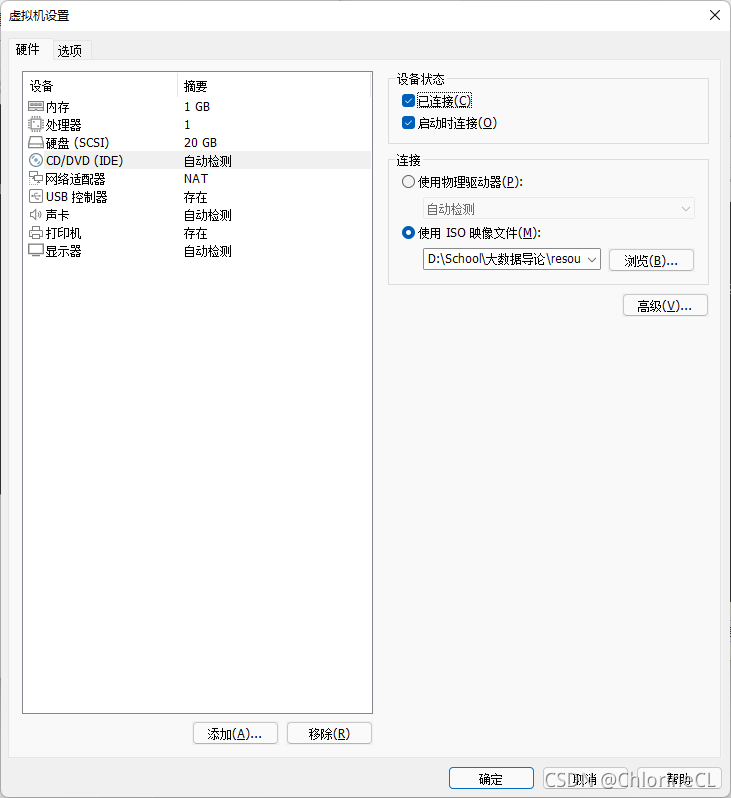
创建完毕后进入虚拟机,在左上角选择 Player》可移动设备》CD/DVD》设置
在弹出窗口中,勾选已连接并打开下载的系统镜像
CentOS国内下载镜像(THU镜像站)
随便找一个你喜欢的版本下就行:Index of /centos/
安装系统
-
选择Install CentOS 7
-
选择中文(最下面)
- 点安装位置然后点右上角完成

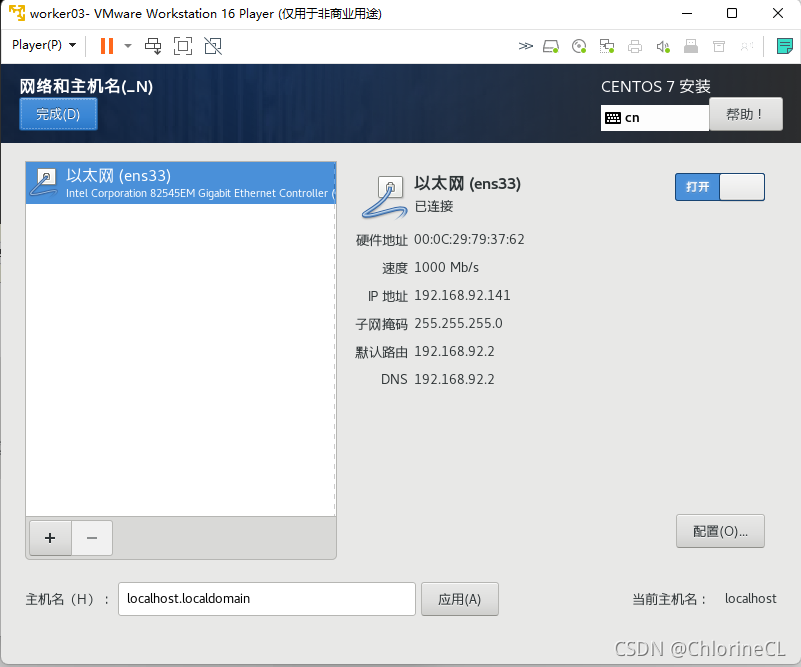
- 点下面的 网络和主机名,然后打开网络
- 开始安装,然后点ROOT用户,并输入密码,之后等待安装完成后点击右下角的重启按钮
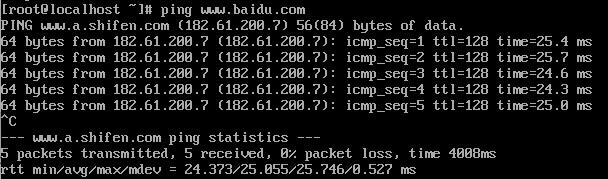
- 进入系统后用 root 账户登录(注意Linux终端输入密码是没有占位符提示的)
- 安装ifconfig来查询IP(cent OS最小安装是不包含net-tools的)
yum search ifconfig #在线查询与ifconfig相关的软件包yum install net-tools.x86_64 -y #安装查询到的软件包(这里应该是你查到的包名)-y表示全部同意ifconfig #查询IP地址如果出现连接超时可通过ping命令查询网络,按ctrl+c退出ping
ping www.baidu.com
-
通过XShell进行远程终端控制虚拟机【此步为可选,以下操作都可以直接通过虚拟机操作,但Xshell好用而且免费啊~】
-
XShell安装:省略,直接百度XShell就行
-
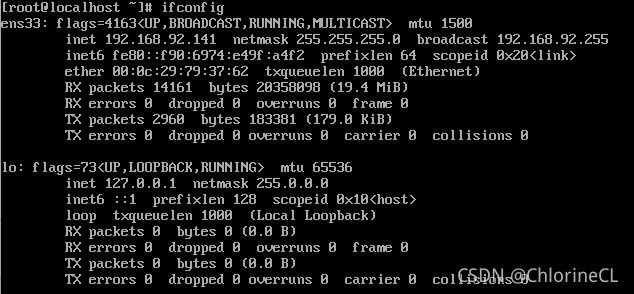
获取ifconfig获得的ip地址:下图中 inet
-
点击新建
-
自己命名会话,主机改成刚刚inet得到的IP地址
-
点接受并保存(一次性接受以后每次都会让你确认)
-
后续窗口输入刚刚设定的root账户和密码
-
出现下述界面表示连接成功
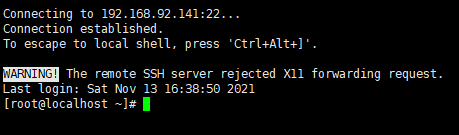
-
- 点安装位置然后点右上角完成
配置 Linux 系统:每台虚拟机都需要设置
-
关闭防火墙:防火墙会阻止结点之间的连接
`systemctl stop firewalld` `systemctl disable firewalld`

- 设置主机名并重启(也可以所有都配置完了再重启)
hostnamectl set-hostname NAME #此处NAME自己取
- 修改hosts:方便通过主机名登录,避免每次都敲IP
vi /etc/hosts #调用vi编辑器
-
进入编辑器后按i键,下方的提示会变为 -编辑模式-
-
通过方向键进行移动,除了不能使用数字小键盘和鼠标操作和其他文本编辑器相同
-
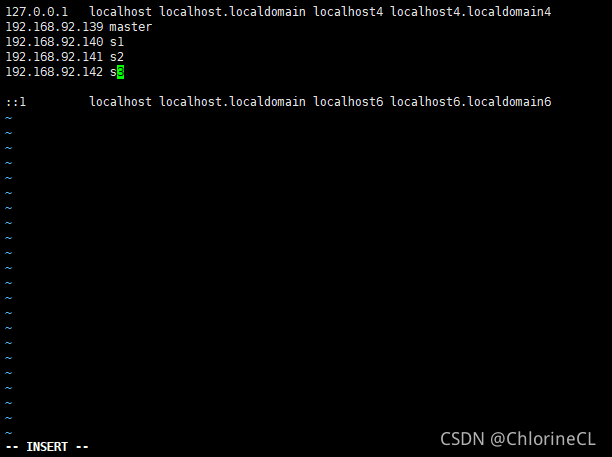
在hosts中应录入你所有虚拟机结点的IP和你取的名字(名字尽量和设置的主机名相同)
-
录入完后按ESC,然后输入:wq(可以自行百度了解更多vim命令)
-
后期你也可以在一台主机上配置完hosts后通过scp复制到其他主机上
-
定义完成后可以通过相同的ping主机名方法检查是否设置成功和连通
- 配置ssh登录
ssh-keygen -b 1024 -t rsa #在本机生成密钥和公钥,一路回车即可
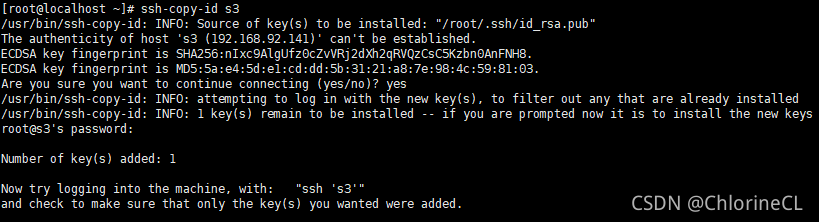
ssh-copy-id HOST-NAME #HOST-NAME是你在hosts中定义的主机名,也可以直接输入IP
- copy-id命令需要根据提示输入root密码
- 在本机copy-id将本机公钥发送给目标机器,表示可以从本机免密登录目标机器
- 根据需要我们只需要配置主机到每个从机、自身到自身的免密登录即可
- 设置密钥访问权限
chmod 600 /root/.ssh/authorized_keys #可以自己百度chmod命令说明
Ⅱ Hadoop 配置
【只用在主机配置,从机复制即可】
下载连接
? Hadoop-3.3.1 THU 下载地址:hadoop-3.3.1.tar.gz
? Java 官方下载地址【请下载jdk8的linux版本 *.tar.gz】:jdk downlowds
JAVA配置
-
安装rz包:方便从宿主机传文件到虚拟机,也可以通过FTP软件实现
但我感觉rz会快一点-
安装命令
yum search rzyum install lrzsz.x86_64 -y -
调用命令
rz #上传文件到当前目录sz FILE-NAME #下载这个文件到宿主机 -
注意:不要使用rz上传除了单文件外的任何文件(包括文件夹和多个文件),这可能导致文件系统错乱
被这样搞坏了好多个虚拟机呜呜 -
如果你改了名字没有重启一定要重启来再用rz,会报错的!
-
-
上传本地jdk包和hadoop包到虚拟机
-
使用tar命令解压两个包
tar -xzvf FILE.tar.gz #可以自己搜一下tar命令的用法【可以使用ls命令看看目录里有啥,蓝色的就是文件夹啦】

-
配置环境变量:免得后面再改一次就放在hadoop部分一起配置了
Hadoop配置
-
进入配置文件夹
cd /root/hadoop-3.3.1/etc/hadoop #这里hadoop-3.3.1是你自己的文件夹的名字 -
挨个用vim修改配置文件
yum install vim-enhanced.x86_64 -y #这里推荐装一个vim包会舒服一点需要修改的配置文件都列在下面了【添加在的标签里!】
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdtmp</value>
</property>hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
以下不是必须配置
<property>
<name>dfs.namenode.rpc-address</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdtmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdtmp/data<value>
</property>mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> -
修改启动脚本
- etc/hadoop/hadoop-env.sh
- 找到JAVA_HOME这个选项(默认是被注释的)
- 修改为你解压的JAVA的绝对路径(偷懒用环境变量可能会报错)
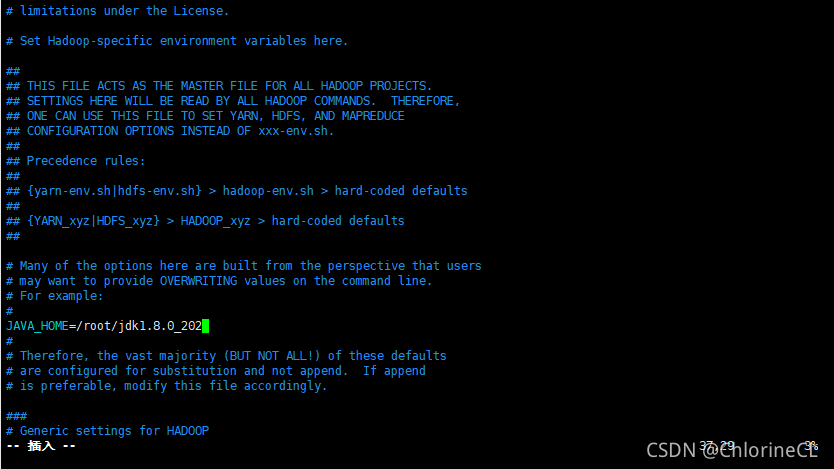
- etc/hadoop/hadoop-env.sh
-
cd到hadoop根目录下的sbin文件夹,在以下文件的开头添加下面的语句
start-dfs.sh,stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.sh,stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
-
修改etc/hadoop/workers文件【hadoop2.x版本为slaves 3.x版本为workers】
- 添加你所有的主机名到其中(hosts中定义的),也可以输入IP
- 一定要删除自带的项目
-
修改环境变量
-
进入环境变量文件
vim /root/.bash_profile -
添加下述配置:按照你自己的目录进行修改【可以自己百度环境变量的语法】
export JAVA_HOME=/root/jdk1.8.0_202
export HADOOP_HOME=/root/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH. -
刷新环境变量
source /root/.bash_profile
-
-
创建临时文件目录:记住刚刚core-site.xml中的hadoop.tmp.dir指定的目录
- 以文中的目录为例
- 切换到root目录
cd ~ - 创建文件夹
mkdir hdtmp
-
重新启动虚拟机后配置就完成了!
-
复制到其他虚拟机
-
复制命令:可以直接复制整个文件夹,配置了ssh免密登录后不需要输入密码
scp -r FILE root@HOST-NAME: DIR -
需要复制的文件有
- jdk 目录:必须
- hadoop 目录:必须
- .bash_profile:不复制可以自己设定
- hosts:不复制可以自己设定(但是需要确保囊括了所有主机)
-
Hadoop实战演练
-
测试Hadoop安装情况:分别输入hadoop,java,若没有出现无法识别说明配置成功
-
格式化Hadoop
-
只能在你指定的主机进行格式化(通常命名为master),格式化后该节点称为namenode,负责任务的分配
-
切记只能格式化一次,如果不清空临时文件就再次格式化会导致clusterID不相同,dataNode和nameNode无法连接的情况
-
格式化命令:
hadoop namenode -format -
如果要重置集群(重新格式化),需要删除每个节点hadoop目录下的log文件夹和指定的hdtmp文件夹
-
-
Hadoop 集群!启动!
- 启动集群
start-all.sh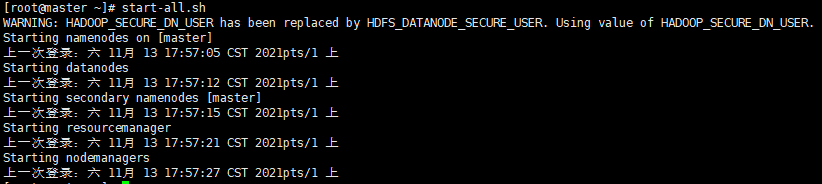
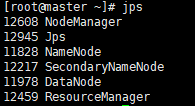
- 检查主机启动情况
jps
- 检查从机启动情况
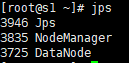
- 如果运行状态和截图一致,说明启动成功惹!
- 启动集群
-
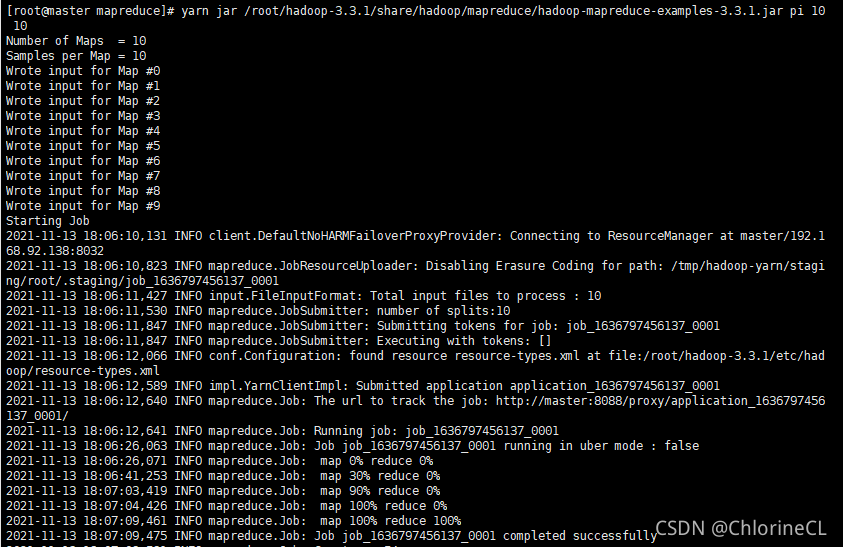
运行一个测试算例吧!
- hadoop内置了很多测试算例(可以自己百度看一看有哪些),存放在share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 中
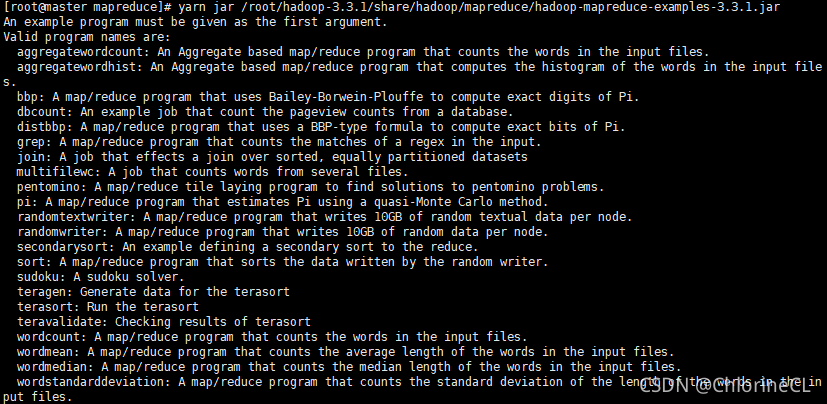
- 调用一个内置的PI算例
yarn jar /root/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
-
开头的命令yarn表示集群模式,hadoop表示单机模式,一般就用yarn
-
jar表示执行后面路径的jar文件
-
pi表示指定上面那么多算例中的pi算例
-
10 10表示计算精度
-
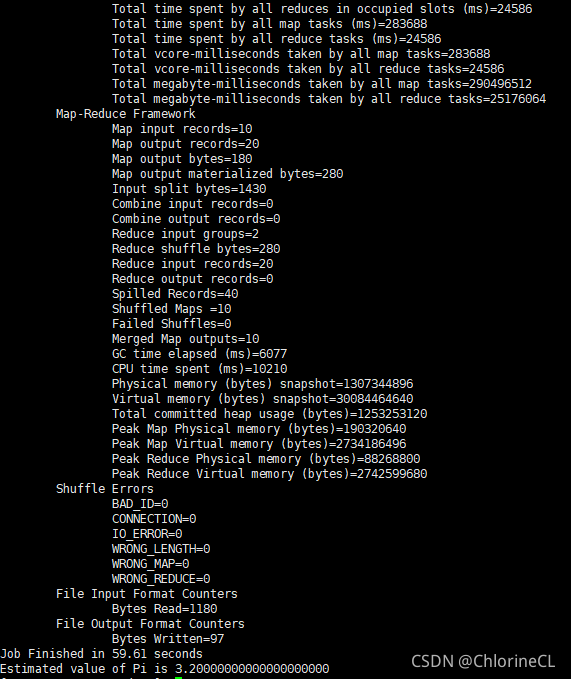
若终端返回如下图结果表示集群正式搭建成功
终于成功了,想起曾经的苦逼过程我都要写泪目了
- 来!试试看HDFS和WordCount!
-
HDFS的理解:详见上面的理解部分或者自己百度
-
HDFS是Hadoop的文件格式,和yarn的资源分配一同提供了一个多节点的集群化计算平台,说人话就是hadoop用hdfs(文件管理系统)和yarn(资源分配系统)将很多个计算机虚拟成了一个计算机来方便运算
-
刚刚我们的pi算例调用了yarn进程,利用mapreduce将一个运算任务分配给了所有结点(map)最后统合起来(reduce)【严格地来说yarn的工作原理不是简单的分配任务】,但是没有调用hdfs(至少看起来没有),所以现在我们的wordcount示例就用hdfs试一试
-
-
HDFS操作命令:HDFS的默认路径也是/root,我们也可以使用绝对路径(独立于任何机器的本地目录)
hdfs dfs -mkdir DIR在对应路径创建目录hdfs dfs -cat DIR读取对应路径的文件hdfs dfs -ls DIR列举对应目录的文件hdfs dfs -put FILE DIR上传文件到对应目录hdfs dfs -get DIR下载对应目录的文件到本地目录 -
试着运行wordcount算例
自己在任意本地目录新建或者上传一个文本文件(任何文本文件都行)
hdfs dfs -mkdir wctest
hdfs dfs -put test wctesttest是你自己的文本文件
yarn jar /root/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount wctest/test wctest/test.outputwctest/test.output是输出的目录 -
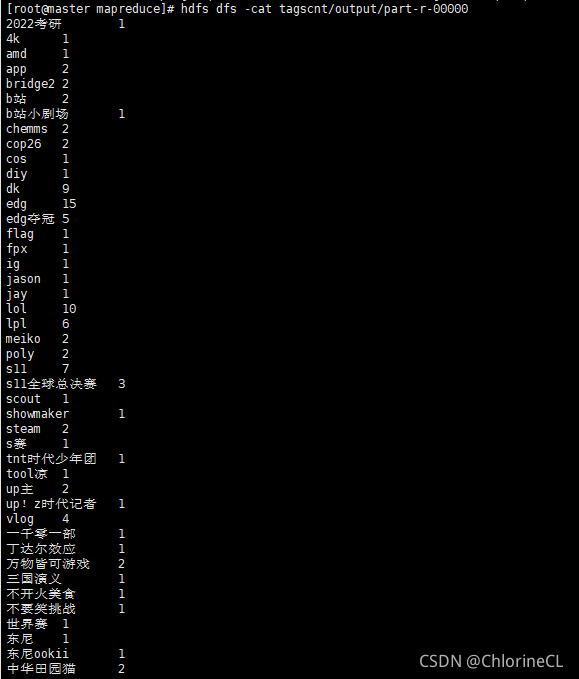
运行结果:运行完毕后在test.output会生成如下文件

-
_SUCCESS是空文件,表示运算成功
-
part-r-00000是运行结果的文件,可以使用
hdfs dfs -cat访问