ЮФеТФПТМ
1ЁЂkafkaИХЪі
дкДѓЪ§ОнДІРэЪБКђ,Ъ§ОнашвЊДгвЛИігІгУГЬађДЋЪфЕНСэвЛИігІгУГЬађ,ЯћЯЂЯЕЭГИКд№ДІРэетЯюЪТЮёЁЃKafka ЪЧвЛИіЗжВМЪНЕФ,жЇГжЖрЗжЧјЁЂЖрИББО,Лљгк Zookeeper ЕФЗжВМЪНЯћЯЂСїЦНЬЈЁЃkafkaЛљгкЗЂВМ-ЖЉдФ(pub-pub)ФЃЪН,ПЩвдДІРэДѓСПЕФЪ§Он,ЪЪгУгкРыЯпКЭдкЯпЯћЯЂЯћЗбЁЃ
- ПЩППад - KafkaЪЧЗжВМЪН,ЗжЧј,ИДжЦКЭШнДэЕФЁЃ
- ПЩРЉеЙад - KafkaЯћЯЂДЋЕнЯЕЭГЧсЫЩЫѕЗХ,ЮоашЭЃЛњЁЃ
- ФЭгУад - KafkaЪЙгУЗжВМЪНЬсНЛШежО,етвтЮЖзХЯћЯЂЛсОЁПЩФмПьЕиБЃСєдкДХХЬЩЯ,вђДЫЫќЪЧГжОУЕФЁЃ
- адФм - KafkaЖдгкЗЂВМКЭЖЉдФЯћЯЂЖМОпгаИпЭЬЭТСПЁЃ МДЪЙДцДЂСЫаэЖрTBЕФЯћЯЂ,ЫќвВБЃГжЮШЖЈЕФадФмЁЃ
вЛАуЕФЯћЯЂЯЕЭГжївЊгаСНжжФЃЪН:ЕуЖдЕуФЃЪНКЭЗЂВМЖЉдФФЃЪН:
- ЕуЖдЕуЯћЯЂЯЕЭГ:вЛИіЛђепЖрИіЯћЗбепПЩвдЯћКФЖгСажаЕФЯћЯЂ,ЕЋЪЧЯћЯЂзюЖржЛФмБЛвЛИіЯћЗбепЯћЗб,вЛЕЉгавЛИіЯћЗбепНЋЦфЯћЗбЕє,ЯћЯЂОЭДгИУЖгСажаЯћЪЇЁЃ(гаЕуРрЫЦгкЖЉЕЅДІРэЯЕЭГ)
- ЗЂВМЖЉдФЯћЯЂЯЕЭГ:ЯћЯЂЩњВњеп(ЗЂВМ)НЋЯћЯЂЗЂВМЕНtopicжа,ЭЌЪБгаЖрИіЯћЯЂЯћЗбеп(ЖЉдФ)ЯћЗбИУЯћЯЂЁЃКЭЕуЖдЕуЗНЪНВЛЭЌ,ЗЂВМЕНtopicЕФЯћЯЂЛсБЛЫљгаЖЉдФепЯћЗбЁЃ(гаЕуРрЫЦгкЖЉдФЙЋжкКХ)
2ЁЂkafkaМмЙЙ
kafkaЛљДЁПђМмШчЭМЫљЪО,жївЊПЩвдЗжЮЊЩњВњеп(producer)ЁЂЯћЗбеп(consumer),kafkaМЏШКЁЃkafkaМЏШКЪЧЗжВМЪНЯЕЭГ,УПвЛИіserverБЛГЦЮЊвЛИіbrokerЁЃkafkaжаЯћЯЂЪЧвдtopicЮЊЕЅЮЛ,ЭЌвЛРрЯћЯЂБЛЗЂЫЭЕНЭЌвЛИіtopicжа,УПИіtopicОпгаЖрИіЗжЧј,ВЂЧвЖдгІзХЖрИіИББО,УПИіЗжЧјЖдгІзХДХХЬЩЯвЛИіЮФМў,ИУЮФМўЪЙгУЦЋвЦСП(offset)РДБъМЧвЛЬѕЯћЯЂЁЃОпЬхЕФМмЙЙаХЯЂгЩЯТЭМКЭНщЩмЮФзжзщГЩЁЃ
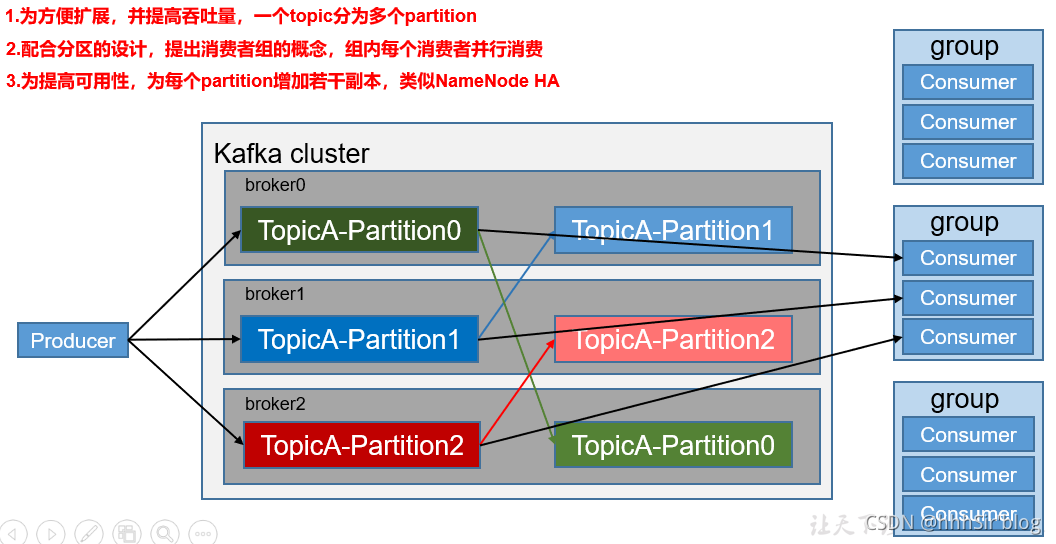
(1)Producer :ЯћЯЂЩњВњеп,ОЭЪЧЯђkafka brokerЗЂЯћЯЂЕФПЭЛЇЖЫ;
(2)Consumer :ЯћЯЂЯћЗбеп,Яђkafka brokerШЁЯћЯЂЕФПЭЛЇЖЫ;
(3)Consumer Group (CG):ЯћЗбепзщ,гЩЖрИіconsumerзщГЩЁЃЯћЗбепзщФкУПИіЯћЗбепИКд№ЯћЗбВЛЭЌЗжЧјЕФЪ§Он,вЛИіЗжЧјжЛФмгЩвЛИіЯћЗбепЯћЗб;ЯћЗбепзщжЎМфЛЅВЛгАЯьЁЃЫљгаЕФЯћЗбепЖМЪєгкФГИіЯћЗбепзщ,МДЯћЗбепзщЪЧТпМЩЯЕФвЛИіЖЉдФепЁЃ
(4)Broker :вЛЬЈkafkaЗўЮёЦїОЭЪЧвЛИіbrokerЁЃвЛИіМЏШКгЩЖрИіbrokerзщГЩЁЃвЛИіbrokerПЩвдШнФЩЖрИіtopicЁЃ
(5)Topic :ПЩвдРэНтЮЊвЛИіЖгСа,ЩњВњепКЭЯћЗбепУцЯђЕФЖМЪЧвЛИіtopic;
(6)Partition:ЮЊСЫЪЕЯжРЉеЙад,вЛИіЗЧГЃДѓЕФtopicПЩвдЗжВМЕНЖрИіbroker(МДЗўЮёЦї)ЩЯ,вЛИіtopicПЩвдЗжЮЊЖрИіpartition,УПИіpartitionЪЧвЛИігаађЕФЖгСа;
(7)Replica:ИББО,ЮЊБЃжЄМЏШКжаЕФФГИіНкЕуЗЂЩњЙЪеЯЪБ,ИУНкЕуЩЯЕФpartitionЪ§ОнВЛЖЊЪЇ,ЧвkafkaШдШЛФмЙЛМЬајЙЄзї,kafkaЬсЙЉСЫИББОЛњжЦ,вЛИіtopicЕФУПИіЗжЧјЖМгаШєИЩИіИББО,вЛИіleaderКЭШєИЩИіfollowerЁЃ
(8)leader:УПИіЗжЧјЖрИіИББОЕФЁАжїЁБ,ЩњВњепЗЂЫЭЪ§ОнЕФЖдЯѓ,вдМАЯћЗбепЯћЗбЪ§ОнЕФЖдЯѓЖМЪЧleaderЁЃ
(9)follower:УПИіЗжЧјЖрИіИББОжаЕФЁАДгЁБ,ЪЕЪБДгleaderжаЭЌВНЪ§Он,БЃГжКЭleaderЪ§ОнЕФЭЌВНЁЃleaderЗЂЩњЙЪеЯЪБ,ФГИіfollowerЛсГЩЮЊаТЕФleaderЁЃ
ВЙГфСНЕу:
- ЗжЧјКЭЗжВМЪН:вЛИі topic ЖдгІЕФЖрИі partition ЗжЩЂДцДЂЕНМЏШКжаЕФЖрИі broker ЩЯ,ДцДЂЗНЪНЪЧвЛИі partition ЖдгІвЛИіЮФМў,УПИі broker ИКд№ДцДЂдкздМКЛњЦїЩЯЕФ partition жаЕФЯћЯЂЖСаДЁЃ
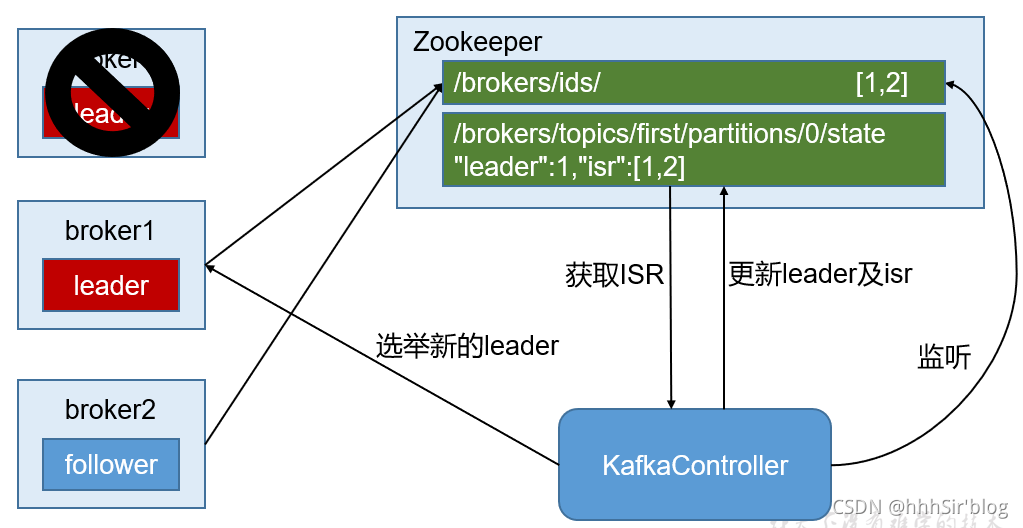
- ИББО:kafkaПЩвдХфжУИББОЮФМўЕФЪ§СП,ЖдгкЖрИіИББОЮФМў,УПИі partition бЁОйвЛИіbroker зїЮЊЁАleaderЁБ,гЩ leader ИКд№ЫљгаЖдИУЗжЧјЕФЖСаД,ЦфЫћ server зїЮЊ follower жЛашвЊМђЕЅЕФгы leader ЭЌВН,БЃГжИњНјМДПЩЁЃШчЙћдРДЕФ leader ЪЇаЇ,ЛсжиаТбЁОйгЩЦфЫћЕФ follower РДГЩЮЊаТЕФ leaderЁЃНгЯТРДНщЩмвЛЯТСНжжИББОбЁОйЛњжЦ:
kafkaжаbrokerЕФleaderбЁОйЛњжЦ:
ЁЄ
brokerжаЕФleader(controller leader):brokerЦєЖЏЪБ,ЖМДДНЈвЛИіkafka ControllerЖдЯѓ,ЕЋЪЧМЏШКжажЛФмгавЛИіleaderЖдЭтЬсЙЉЗўЮё,етаЉУПИіНкЕуЩЯЕФKafkaControllerЛсдкжИЖЈЕФzookeeperТЗОЖЯТДДНЈСйЪБНкЕу,жЛгаЕквЛИіГЩЙІДДНЈЕФНкЕуЕФKafkaControllerВХПЩвдГЩЮЊleader,ЦфгрЕФЖМЪЧfollowerЁЃЕБleaderЙЪеЯКѓ,ЫљгаЕФfollowerЛсЪеЕНЭЈжЊ,дйДЮОКељдкИУТЗОЖЯТДДНЈНкЕуДгЖјбЁОйаТЕФleaderЁЃ
ЁЄKafkaЕФLeaderбЁОйЪЧЭЈЙ§дкzookeeperЩЯДДНЈ/controllerСйЪБНкЕуРДЪЕЯжleaderбЁОй,ВЂдкИУНкЕужааДШыЕБЧАbrokerЕФаХЯЂ {ЁАversionЁБ:1,ЁБbrokeridЁБ:1,ЁБtimestampЁБ:ЁБ1512018424988ЁБ} РћгУZookeeperЕФЧПвЛжТадЬиад,вЛИіНкЕужЛФмБЛвЛИіПЭЛЇЖЫДДНЈГЩЙІ,ДДНЈГЩЙІЕФbrokerМДЮЊleader,МДЯШЕНЯШЕУддђ,leaderвВОЭЪЧМЏШКжаЕФcontroller,ИКд№МЏШКжаЫљгаДѓаЁЪТЮёЁЃ ЕБleaderКЭzookeeperЪЇШЅСЌНгЪБ,ЖдгІЕФController PathЛсздЖЏЯћЪЇ(вђЮЊЫќЪЧephemeral Node),ДЫЪБИУWatchБЛfire,ЫљгаЁАЛюЁБ зХЕФBrokerЖМЛсШЅОКбЁГЩЮЊаТЕФController (ДДНЈаТЕФController Path),ЕЋЪЧжЛЛсгавЛИіОКбЁГЩЙІ(етЕу ZookeeperБЃжЄ)ЁЃОКбЁГЩЙІепМДЮЊаТЕФLeader,ОКбЁЪЇАмепдђжиаТдкаТЕФController PathЩЯзЂВсWatchЁЃвђЮЊZookeeperЕФWatchЪЧвЛДЮадЕФ, БЛfireвЛДЮжЎКѓМДЪЇаЇ,ЫљвдашвЊжиаТзЂВс
kafkaжаpartition leaderЕФбЁОй
ЁЄ
partition leader:ИКд№ИУЗжЧјЪ§ОнЕФЖСаД,leaderЕФбЁОйгЩcontroller leaderжДааЁЃОпЬхЕФВйзїЮЊ
1ЁЂДгZookeeperжаЖСШЁЕБЧАЗжЧјЕФЫљгаISR(in-sync replicas)МЏКЯЁЃ(ISRНЋдкЯТЮФНщЩм)
2ЁЂЕїгУХфжУЕФЗжЧјбЁдёЫуЗЈбЁдёЗжЧјЕФleaderЁЃ
KafkaЛсдкZookeeperЩЯеыЖдУПИіTopicЮЌЛЄвЛИіГЦЮЊISR(in-sync replica,вбЭЌВНЕФИББО)ЕФМЏКЯ,ИУМЏКЯжаЪЧвЛаЉЗжЧјЕФИББОЁЃжЛгаЕБетаЉИББОЖМИњLeaderжаЕФИББОЭЌВНСЫжЎКѓ,kafkaВХЛсШЯЮЊЯћЯЂвбЬсНЛ,ВЂЗДРЁИјЯћЯЂЕФЩњВњепЁЃШчЙћетИіМЏКЯгадіМѕ,kafkaЛсИќаТzookeeperЩЯЕФМЧТМЁЃШчЙћФГИіЗжЧјЕФLeaderВЛПЩгУ,KafkaОЭЛсДгISRМЏКЯжабЁдёвЛИіИББОзїЮЊаТЕФLeaderЁЃЯдШЛЭЈЙ§ISR,kafkaашвЊЕФШпгрЖШНЯЕЭ,ПЩвдШнШЬЕФЪЇАмЪ§БШНЯИпЁЃМйЩшФГИіtopicгаf+1ИіИББО,kafkaПЩвдШнШЬfИіЗўЮёЦїВЛПЩгУЁЃ

2.1 ЙЄзїСїГЬ
НВЭъЩЯУцЕФМмЙЙ,ЯждкПДПДЯћЯЂОпЬхдѕУДДЋЪфЕФ,жївЊНщЩмЩњВњЙ§ГЬКЭЯћЗбЙ§ГЬЁЃ
(1)ЩњВњЙ§ГЬ
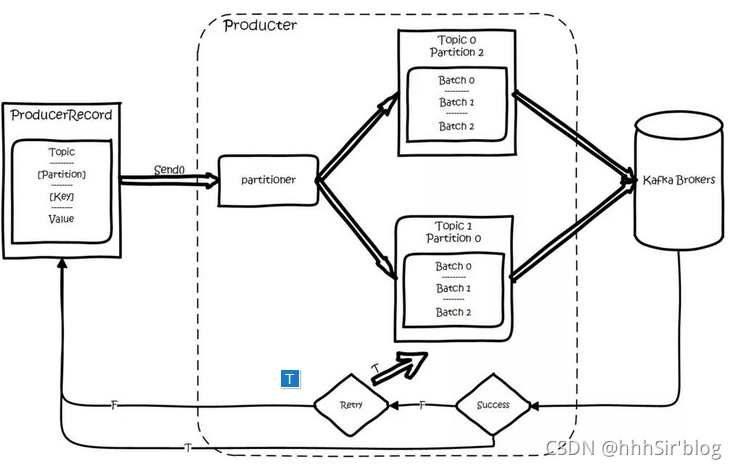
вЛЬѕЯћЯЂПЩвдгаЫФИіВЮЪ§:topicЁЂpartitionЁЂkeyКЭvalue,ЦфжаkeyКЭpartitionЪЧПЩбЁЕФЁЃвЛЬѕМЧТМашвЊНјааађСаЛЏ,ЗХШыЗЂЫЭЖгСажаЁЃЩњВњепproducerНЋКЭtopicЯТЫљгаЕФpartition leaderБЃГжsocketСЌНг,ЯћЯЂЭЈЙ§producerжБНгЭЈЙ§topicЗЂЫЭЕНbroker,Цфжаpartition leaderЕФЮЛжУзЂВсдкzookeeperжа, producerзїЮЊzookeeper client,вбОзЂВсСЫwatchМрЬ§partition leaderЕФБфИќЪТМў,вђДЫПЩвдзМШЗЕижЊЕРЫЪЧЕБЧАЕФleaderЁЃproducer ЖЫВЩгУвьВНЗЂЫЭ:НЋЖрЬѕЯћЯЂднЧвдкПЭЛЇЖЫ buffer Ц№РД,ВЂНЋЫћУЧХњСПЕФЗЂЫЭЕН broker,аЁЪ§Он IO ЬЋЖр,ЛсЭЯТ§ећЬхЕФЭјТчбгГй,ХњСПбгГйЗЂЫЭЪТЪЕЩЯЬсЩ§СЫЭјТчаЇТЪЁЃ
дйЫЕвЛЯТpartitionЕФзщГЩ:
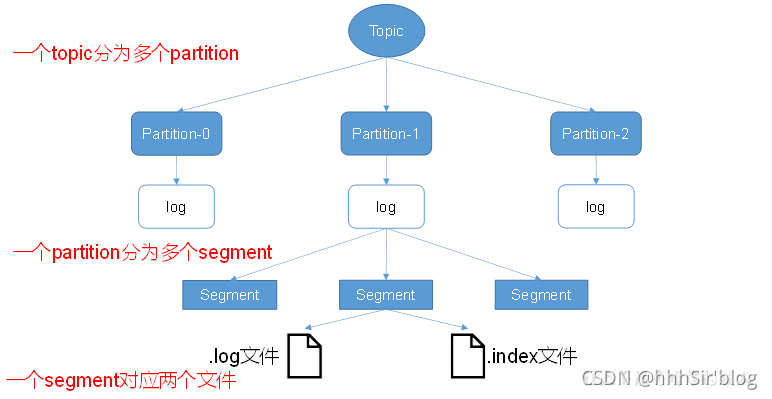
topicЪЧТпМЩЯЕФИХФю,ЖјpartitionЪЧЮяРэЩЯЕФИХФю,УПИіpartitionЖдгІгквЛИіlogЮФМў,ИУlogЮФМўжаДцДЂЕФОЭЪЧproducerЩњВњЕФЪ§ОнЁЃProducerЩњВњЕФЪ§ОнЛсБЛВЛЖЯзЗМгЕНИУlogЮФМўФЉЖЫ,ЧвУПЬѕЪ§ОнЖМгаздМКЕФoffsetЁЃЯћЗбепзщжаЕФУПИіЯћЗбеп,ЖМЛсЪЕЪБМЧТМздМКЯћЗбЕНСЫФФИіoffset,вдБуГіДэЛжИДЪБ,ДгЩЯДЮЕФЮЛжУМЬајЯћЗбЁЃ
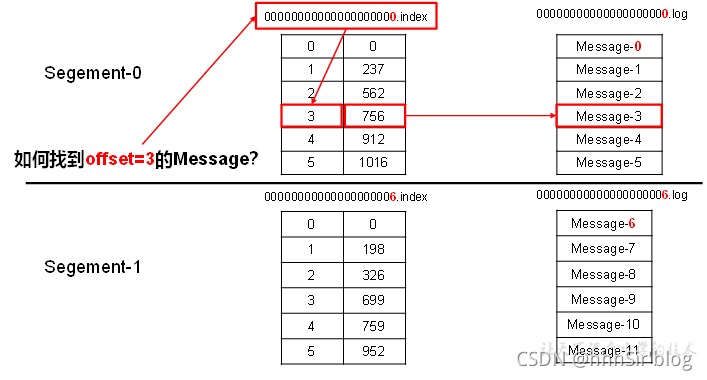
KafkaВЩШЁСЫЗжЦЌКЭЫїв§ЛњжЦ,НЋУПИіpartitionЗжЮЊЖрИіsegmentЁЃУПИіsegmentЖдгІСНИіЮФМўЁЊЁЊЁА.indexЁБЮФМўКЭЁА.logЁБЮФМўЁЃетаЉЮФМўЮЛгквЛИіЮФМўМаЯТ,ИУЮФМўМаЕФУќУћЙцдђЮЊ:topicУћГЦ+ЗжЧјађКХЁЃР§Шч,firstетИіtopicгаШ§ИіЗжЧј,дђЦфЖдгІЕФЮФМўМаЮЊfirst-0,first-1,first-2ЁЃЁА.indexЁБЮФМўДцДЂДѓСПЕФЫїв§аХЯЂ,ЁА.logЁБЮФМўДцДЂДѓСПЕФЪ§Он,Ыїв§ЮФМўжаЕФдЊЪ§ОнжИЯђЖдгІЪ§ОнЮФМўжаmessageЕФЮяРэЦЋвЦЕижЗЁЃ
(2)ЯћЗбЙ§ГЬ
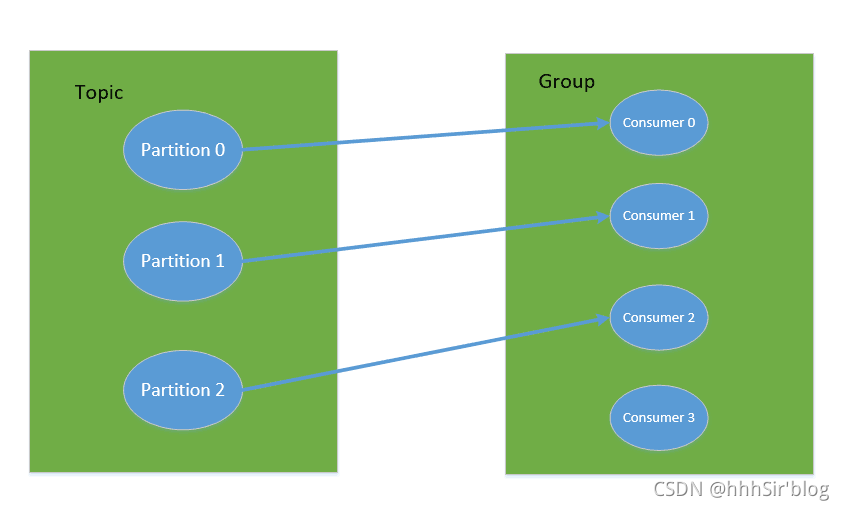
УПвЛИіЯћЗбепЪєгквЛИі consumer group,вЛИі group АќКЌЖрИі consumerЁЃЬиБ№ашвЊзЂвтЕФЪЧ:ЖЉдФ Topic ЪЧвдвЛИіЯћЗбзщРДЖЉдФЕФ,ЗЂЫЭЕН Topic ЕФЯћЯЂ,жЛЛсБЛЖЉдФДЫ Topic ЕФУПИі group жаЕФвЛИі consumer ЯћЗбЁЃШчЙћЫљгаЕФ Consumer ЖМОпгаЯрЭЌЕФ group,ФЧУДОЭЯёЪЧвЛИіЕуЖдЕуЕФЯћЯЂЯЕЭГ;ШчЙћУПИі consumer ЖМОпгаВЛЭЌЕФ group,ФЧУДЯћЯЂЛсЙуВЅИјЫљгаЕФЯћЗбепЁЃ
вЛИі Partition,жЛФмБЛЯћЗбзщРяЕФвЛИіЯћЗбепЯћЗб,ЕЋЪЧПЩвдЭЌЪББЛЖрИіЯћЗбзщЯћЗб,ЯћЗбзщРяЕФУПИіЯћЗбепЪЧЙиСЊЕНвЛИі partition ЕФ,вђДЫгаетбљЕФЫЕЗЈ:ЖдгквЛИі topic,ЭЌвЛИі group жаВЛФмгаЖргк partitions ИіЪ§ЕФ consumer ЭЌЪБЯћЗб,ЗёдђНЋвтЮЖзХФГаЉ consumer НЋЮоЗЈЕУЕНЯћЯЂЁЃЭЌвЛИіЯћЗбзщЕФСНИіЯћЗбепВЛЛсЭЌЪБЯћЗбвЛИі partitionЁЃ
дк kafka жа,ВЩгУСЫ pull ЗНЪН,МД consumer дкКЭ broker НЈСЂСЌНгжЎКѓ,жїЖЏШЅ pull(ЛђепЫЕ fetch )ЯћЯЂ,ЪзЯШ consumer ЖЫПЩвдИљОнздМКЕФЯћЗбФмСІЪЪЪБЕФШЅ fetch ЯћЯЂВЂДІРэ,ЧвПЩвдПижЦЯћЯЂЯћЗбЕФНјЖШ(offset)ЁЃ
partition жаЕФЯћЯЂжЛгавЛИі consumer дкЯћЗб,ЧвВЛДцдкЯћЯЂзДЬЌЕФПижЦ,вВУЛгаИДдгЕФЯћЯЂШЗШЯЛњжЦ,ПЩМћ kafka broker ЖЫЪЧЯрЕБЧсСПМЖЕФЁЃЕБЯћЯЂБЛ consumer НгЪежЎКѓ,ашвЊБЃДц Offset МЧТМЯћЗбЕНФФ,вдЧАБЃДцдк ZK жа,гЩгк ZK ЕФаДадФмВЛКУ,вдЧАЕФНтОіЗНЗЈЖМЪЧ Consumer УПИєвЛЗжжгЩЯБЈвЛДЮ,дк 0.10 АцБОКѓ,Kafka АбетИі Offset ЕФБЃДц,Дг ZK жаАўРы,БЃДцдквЛИіУћНа __consumer_offsets- topic ЕФ Topic жа,гЩДЫПЩМћ,consumer ПЭЛЇЖЫвВКмЧсСПМЖЁЃ
ЪТЪЕЩЯ,дкУПвЛИіЯћЗбепжаЮЈвЛБЃДцЕФдЊЪ§ОнЪЧoffset(ЦЋвЦСП)МДЯћЗбдкlogжаЕФЮЛжУ.ЦЋвЦСПгЩЯћЗбепЫљПижЦ:ЭЈГЃдкЖСШЁМЧТМКѓ,ЯћЗбепЛсвдЯпадЕФЗНЪНдіМгЦЋвЦСП,ЕЋЪЧЪЕМЪЩЯ,гЩгкетИіЮЛжУгЩЯћЗбепПижЦ,ЫљвдЯћЗбепПЩвдВЩгУШЮКЮЫГађРДЯћЗбМЧТМЁЃР§Шч,вЛИіЯћЗбепПЩвджижУЕНвЛИіОЩЕФЦЋвЦСП,ДгЖјжиаТДІРэЙ§ШЅЕФЪ§Он;вВПЩвдЬјЙ§зюНќЕФМЧТМ,Дг"Яждк"ПЊЪМЯћЗбЁЃ
2.2 ЩњВњеп
ЩЯУцЕФФкШнНЋkafkaМИИіСїГЬЖММђЕЅНщЩмСЫвЛЯТ,НгЯТРДЯъНтМИИіСїГЬдРэЁЃ
2.2.1 ЗжЧјВпТд
ЗжЧјЕФКУДІ:
- ЗНБудкМЏШКРЉеЙ,ПЩвдЬэМгЗжЧј,ЕЋЪЧВЛПЩвдМѕЩйЗжЧј
- ПЩвдЬсИпВЂЗЂ,ПЩвдвдpartitionРДНјааЖСаД
ЗжЧјЕФЗНЗЈ:
- жИУї partition ЕФЧщПіЯТ,жБНгНЋжИУїЕФжЕжБНгзїЮЊ partiton жЕ;
- УЛгажИУї partition жЕЕЋгаkey ЕФЧщПіЯТ,НЋ key ЕФ hash жЕгы topic ЕФ partition Ъ§НјааШЁгрЕУЕН partition жЕ;
- МШУЛга partition жЕгжУЛга key жЕЕФЧщПіЯТ,ЕквЛДЮЕїгУЪБЫцЛњЩњГЩвЛИіећЪ§(КѓУцУПДЮЕїгУдкетИіећЪ§ЩЯздді),НЋетИіжЕгыtopic ПЩгУЕФ partition змЪ§ШЁгрЕУЕН partition жЕ,вВОЭЪЧГЃЫЕЕФ round-robin ЫуЗЈЁЃ
2.2.2 Ъ§ОнПЩППадБЃжЄ
ЮЊБЃжЄproducerЗЂЫЭЕФЪ§Он,ФмПЩППЕФЗЂЫЭЕНжИЖЈЕФtopic,topicЕФУПИіpartitionЪеЕНproducerЗЂЫЭЕФЪ§ОнКѓ,ЖМашвЊЯђproducerЗЂЫЭack(acknowledgementШЗШЯЪеЕН),ШчЙћproducerЪеЕНack,ОЭЛсНјааЯТвЛТжЕФЗЂЫЭ,ЗёдђжиаТЗЂЫЭЪ§ОнЁЃетРяВЂВЛЪЧЫЕУЛгаЪеЕНackОЭвЛжБЕШД§,producerЪЧвЛИівьВНЗЂЫЭЕФЙ§ГЬВу,ЫќвЛжБдкЗЂЪ§Он,ЕЋЪЧШчЙћУЛгаЪеЕНack,ОЭЛсжиаТЗЂЫЭФЧЬѕУЛЪеЕНackЕФЪ§ОнЁЃ
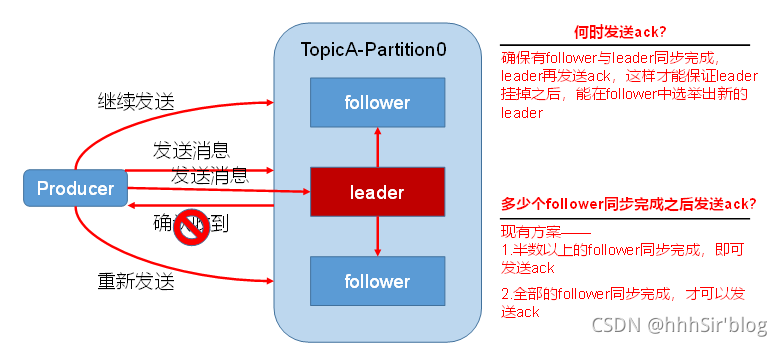
ЗЂЫЭackЕФВпТдШчЩЯЭМЫљЪО,kafkaбЁгУЕФЪЧШЋВПfollowerЭЌВНЭъГЩжЎКѓдйЗЂЫЭack,ЫфШЛетжжВпТдЭјТчбгГйБШНЯИп,ЕЋЪЧЭјТчбгГйЖдkafkaгАЯьБШНЯаЁЁЃ
LeaderЮЌЛЄСЫвЛИіЖЏЬЌЕФin-sync replica set (ISR),втЮЊКЭleaderБЃГжЭЌВНЕФfollowerМЏКЯЁЃЕБISRжаЕФfollowerЭъГЩЪ§ОнЕФЭЌВНжЎКѓ,leaderОЭЛсИјproducerЗЂЫЭackЁЃШчЙћfollowerГЄЪБМфЮДЯђleaderЭЌВНЪ§Он,дђИУfollowerНЋБЛЬпГіISR,ИУЪБМфуажЕгЩreplica.lag.time.max.msВЮЪ§ЩшЖЈЁЃLeaderЗЂЩњЙЪеЯжЎКѓ,ОЭЛсДгISRжабЁОйаТЕФleaderЁЃ
KafkaЮЊгУЛЇЬсЙЉСЫШ§жжПЩППадМЖБ№,гУЛЇИљОнЖдПЩППадКЭбгГйЕФвЊЧѓНјааШЈКт,бЁдёВЛЭЌЕФackХфжУ:
- 0:producerВЛЕШД§brokerЕФack,етвЛВйзїЬсЙЉСЫвЛИізюЕЭЕФбгГй,brokerвЛНгЪеЕНЛЙУЛгааДШыДХХЬОЭвбОЗЕЛи,ЕБbrokerЙЪеЯЪБгаПЩФмЖЊЪЇЪ§Он;
- 1:producerЕШД§brokerЕФack,partitionЕФleaderТфХЬГЩЙІКѓЗЕЛиack,ШчЙћдкfollowerЭЌВНГЩЙІжЎЧАleaderЙЪеЯ,ФЧУДНЋЛсЖЊЪЇЪ§Он;
- -1(all):producerЕШД§brokerЕФack,partitionЕФleaderКЭfollowerШЋВПТфХЬГЩЙІКѓВХЗЕЛиackЁЃЕЋЪЧШчЙћдкfollowerЭЌВНЭъГЩКѓ,brokerЗЂЫЭackжЎЧА,leaderЗЂЩњЙЪеЯ,ФЧУДЛсдьГЩЪ§ОнжиИДЁЃ
ШчЙћГіЯжСЫЙЪеЯ,БШШчfollowerЛђепleaderхДЛњСЫ,ИУдѕУДВйзїФи?

(1)followerЙЪеЯ
followerЗЂЩњЙЪеЯКѓЛсБЛСйЪБЬпГіISR,Д§ИУfollowerЛжИДКѓ,followerЛсЖСШЁБОЕиДХХЬМЧТМЕФЩЯДЮЕФHW,ВЂНЋlogЮФМўИпгкHWЕФВПЗжНиШЁЕє,ДгHWПЊЪМЯђleaderНјааЭЌВНЁЃЕШИУfollowerЕФLEOДѓгкЕШгкИУPartitionЕФHW,МДfollowerзЗЩЯleaderжЎКѓ,ОЭПЩвджиаТМгШыISRСЫЁЃ
(2)leaderЙЪеЯ
leaderЗЂЩњЙЪеЯжЎКѓ,ЛсДгISRжабЁГівЛИіаТЕФleader,жЎКѓ,ЮЊБЃжЄЖрИіИББОжЎМфЕФЪ§ОнвЛжТад,ЦфгрЕФfollowerЛсЯШНЋИїздЕФlogЮФМўИпгкHWЕФВПЗжНиЕє,ШЛКѓДгаТЕФleaderЭЌВНЪ§ОнЁЃ
зЂвт:етжЛФмБЃжЄИББОжЎМфЕФЪ§ОнвЛжТад,ВЂВЛФмБЃжЄЪ§ОнВЛЖЊЪЇЛђепВЛжиИДЁЃ
2.2.3 Exactly Onceгявх
ACKВЛЭЌМЖБ№ЖдгІВЛЭЌЕФЪ§ОнЗЂЫЭМЖБ№:
- At Least Onceгявх:НЋЗўЮёЦїЕФACKМЖБ№ЩшжУЮЊ-1,ПЩвдБЃжЄProducerЕНServerжЎМфВЛЛсЖЊЪЇЪ§ОнЁЃ
- At Most Onceгявх:НЋЗўЮёЦїACKМЖБ№ЩшжУЮЊ0,ПЩвдБЃжЄЩњВњепУПЬѕЯћЯЂжЛЛсБЛЗЂЫЭвЛДЮЁЃ
- Exactly Onceгявх:Ъ§ОнвЊЧѓВЛжиИДвВВЛЖЊЪЇ
0.11АцБОЕФKafka,в§ШыСЫвЛЯюжиДѓЬиад:УнЕШадЁЃЫљЮНЕФУнЕШадОЭЪЧжИProducerВЛТлЯђServerЗЂЫЭЖрЩйДЮжиИДЪ§Он,ServerЖЫЖМжЛЛсГжОУЛЏвЛЬѕЁЃУнЕШадНсКЯAt Least Onceгявх,ОЭЙЙГЩСЫKafkaЕФExactly OnceгявхЁЃМД:At Least Once + УнЕШад = Exactly Once
вЊЦєгУУнЕШад,жЛашвЊНЋProducerЕФВЮЪ§жаenable.idompotenceЩшжУЮЊtrueМДПЩЁЃKafkaЕФУнЕШадЪЕЯжЦфЪЕОЭЪЧНЋдРДЯТгЮашвЊзіЕФШЅжиЗХдкСЫЪ§ОнЩЯгЮЁЃПЊЦєУнЕШадЕФProducerдкГѕЪМЛЏЕФЪБКђЛсБЛЗжХфвЛИіPID,ЗЂЭљЭЌвЛPartitionЕФЯћЯЂЛсИНДјSequence NumberЁЃЖјBrokerЖЫЛсЖд<PID, Partition, SeqNumber>зіЛКДц,ЕБОпгаЯрЭЌжїМќЕФЯћЯЂЬсНЛЪБ,BrokerжЛЛсГжОУЛЏвЛЬѕЁЃ
ЕЋЪЧPIDжиЦєОЭЛсБфЛЏ,ЭЌЪБВЛЭЌЕФPartitionвВОпгаВЛЭЌжїМќ,ЫљвдУнЕШадЮоЗЈБЃжЄПчЗжЧјПчЛсЛАЕФExactly OnceЁЃ
2.3 ЯћЗбеп
2.3.1 ЯћЗбЗНЪН
consumerВЩгУpull(Р)ФЃЪНДгbrokerжаЖСШЁЪ§ОнЁЃ
pullФЃЪНВЛзужЎДІЪЧ,ШчЙћkafkaУЛгаЪ§Он,ЯћЗбепПЩФмЛсЯнШыбЛЗжа,вЛжБЗЕЛиПеЪ§ОнЁЃеыЖдетвЛЕу,KafkaЕФЯћЗбепдкЯћЗбЪ§ОнЪБЛсДЋШывЛИіЪБГЄВЮЪ§timeout,ШчЙћЕБЧАУЛгаЪ§ОнПЩЙЉЯћЗб,consumerЛсЕШД§вЛЖЮЪБМфжЎКѓдйЗЕЛи,етЖЮЪБГЄМДЮЊtimeoutЁЃ
2.3.2 ЗжЧјЗжХфВпТд
вЛИіconsumer groupжагаЖрИіconsumer,вЛИі topicгаЖрИіpartition,ЫљвдБиШЛЛсЩцМАЕНpartitionЕФЗжХфЮЪЬт,МДШЗЖЈФЧИіpartitionгЩФФИіconsumerРДЯћЗбЁЃЦфжагаСНИіВпТд:roundrobinКЭrange
- round robin:ТжбЏЕїЖШ
- range:ЪзЯШЖдЭЌвЛИі topic РяУцЕФЗжЧјАДееађКХНјааХХађ,ВЂЖдЯћЗбепАДеезжФИЫГађНјааХХађЁЃМйШчЯждкга 10 ИіЗжЧј,3 ИіЯћЗбеп,ХХађКѓЕФЗжЧјНЋЛсЪЧ0,1,2,3,4,5,6,7,8,9;ЯћЗбепХХађЭъжЎКѓНЋЛсЪЧC1-0,C2-0,C3-0ЁЃЭЈЙ§ partitionsЪ§/consumerЪ§ РДОіЖЈУПИіЯћЗбепгІИУЯћЗбМИИіЗжЧјЁЃ
2.3.3 offsetЕФЮЌЛЄ
гЩгкconsumerдкЯћЗбЙ§ГЬжаПЩФмЛсГіЯжЖЯЕчхДЛњЕШЙЪеЯ,consumerЛжИДКѓ,ашвЊДгЙЪеЯЧАЕФЮЛжУЕФМЬајЯћЗб,ЫљвдconsumerашвЊЪЕЪБМЧТМздМКЯћЗбЕНСЫФФИіoffset,вдБуЙЪеЯЛжИДКѓМЬајЯћЗбЁЃ
Kafka 0.9АцБОжЎЧА,consumerФЌШЯНЋoffsetБЃДцдкZookeeperжа,Дг0.9АцБОПЊЪМ,consumerФЌШЯНЋoffsetБЃДцдкKafkaвЛИіФкжУЕФtopicжа,ИУtopicЮЊ__consumer_offsets,етИіжїЬтЕФжївЊзїгУОЭЪЧЯћЗбепДЅЗЂжиЦНКтКѓМЧТМЦЋвЦЪЙгУЕФ,ЯћЗбепУПДЮЯђетИіжїЬтЗЂЫЭЯћЯЂ,е§ГЃЧщПіЯТВЛДЅЗЂжиЦНКт,етИіжїЬтЪЧВЛЦ№зїгУЕФ,ЕБДЅЗЂжиЦНКтКѓ,ЯћЗбепЭЃжЙЙЄзї,УПИіЯћЗбепПЩФмЛсЗжЕНЖдгІЕФЗжЧј,етИіжїЬтОЭЪЧШУЯћЗбепФмЙЛМЬајДІРэЯћЯЂЫљЩшжУЕФЁЃ
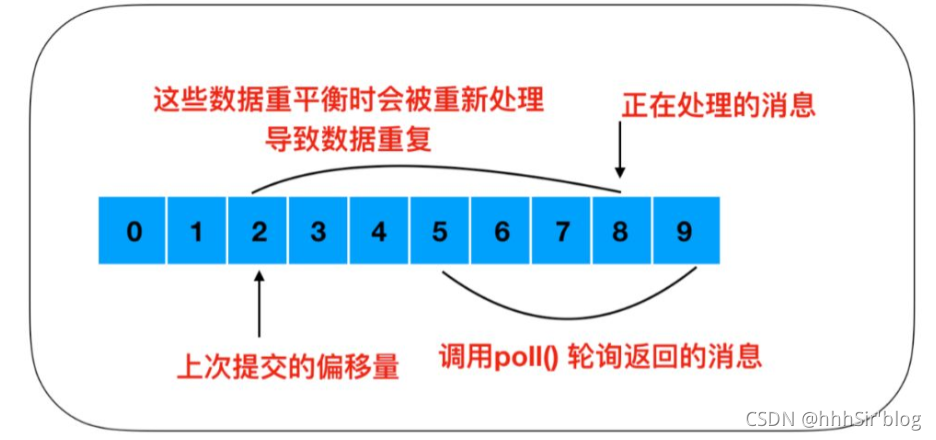
- ШчЙћЬсНЛЕФЦЋвЦСПаЁгкПЭЛЇЖЫзюКѓвЛДЮДІРэЕФЦЋвЦСП,ФЧУДЮЛгкСНИіЦЋвЦСПжЎМфЕФЯћЯЂОЭЛсБЛжиИДДІРэ;
- ШчЙћЬсНЛЕФЦЋвЦСПДѓгкзюКѓвЛДЮЯћЗбЪБЕФЦЋвЦСП,ФЧУДДІгкСНИіЦЋвЦСПжаМфЕФЯћЯЂНЋЛсЖЊЪЇЁЃ
етИіЦЋвЦСПЕФЬсНЛЗНЪНга:
- здЖЏЬсНЛ:зюМђЕЅЕФЗНЪНОЭЪЧШУЯћЗбепздЖЏЬсНЛЦЋвЦСПЁЃШчЙћ enable.auto.commit БЛЩшжУЮЊtrue,ФЧУДУПЙ§ 5s,ЯћЗбепЛсздЖЏАбДг poll() ЗНЗЈТжбЏЕНЕФзюДѓЦЋвЦСПЬсНЛЩЯШЅЁЃЬсНЛЪБМфМфИєгЩ auto.commit.interval.ms ПижЦ,ФЌШЯЪЧ 5sЁЃгыЯћЗбепРяЕФЦфЫћЖЋЮївЛбљ,здЖЏЬсНЛвВЪЧдкТжбЏжаНјааЕФЁЃЯћЗбепдкУПДЮТжбЏжаЛсМьВщЪЧЗёЬсНЛИУЦЋвЦСПСЫ,ШчЙћЪЧ,ФЧУДОЭЛсЬсНЛДгЩЯвЛДЮТжбЏжаЗЕЛиЕФЦЋвЦСПЁЃ
- ЬсНЛЕБЧАЦЋвЦСП:Аб auto.commit.offset ЩшжУЮЊ false,ПЩвдШУгІгУГЬађОіЖЈКЮЪБЬсНЛЦЋвЦСПЁЃЪЙгУ commitSync() ЬсНЛЦЋвЦСПЁЃетИі API ЛсЬсНЛгЩ poll() ЗНЗЈЗЕЛиЕФзюаТЦЋвЦСП,ЬсНЛГЩЙІКѓТэЩЯЗЕЛи,ШчЙћЬсНЛЪЇАмОЭХзГівьГЃЁЃcommitSync() НЋЛсЬсНЛгЩ poll() ЗЕЛиЕФзюаТЦЋвЦСП,ШчЙћДІРэЭъЫљгаМЧТМКѓвЊШЗБЃЕїгУСЫ commitSync(),ЗёдђЛЙЪЧЛсгаЖЊЪЇЯћЯЂЕФЗчЯе,ШчЙћЗЂЩњСЫдкОљКт,ДгзюНќвЛХњЯћЯЂЕНЗЂЩњдкОљКтжЎМфЕФЫљгаЯћЯЂЖМНЋБЛжиИДДІРэЁЃ
- вьВНЬсНЛ:вьВНЬсНЛ commitAsync() гыЭЌВНЬсНЛ commitSync() зюДѓЕФЧјБ№дкгквьВНЬсНЛВЛЛсНјаажиЪд,ЭЌВНЬсНЛЛсвЛжТНјаажиЪдЁЃ
- ЭЌВНКЭвьВНзщКЯЬсНЛ:вЛАуЧщПіЯТ,еыЖдХМЖћГіЯжЕФЬсНЛЪЇАм,ВЛНјаажиЪдВЛЛсгаЬЋДѓЕФЮЪЬт,вђЮЊШчЙћЬсНЛЪЇАмЪЧвђЮЊСйЪБЮЪЬтЕМжТЕФ,ФЧУДКѓајЕФЬсНЛзмЛсгаГЩЙІЕФЁЃЕЋЪЧШчЙћдкЙиБеЯћЗбепЛђдйОљКтЧАЕФзюКѓвЛДЮЬсНЛ,ОЭвЊШЗБЃЬсНЛГЩЙІЁЃвђДЫ,дкЯћЗбепЙиБежЎЧАвЛАуЛсзщКЯЪЙгУcommitAsyncКЭcommitSyncЬсНЛЦЋвЦСПЁЃ
- ЬсНЛЬиЖЈЕФЦЋвЦСП:ЯћЗбепAPIдЪаэЕїгУ commitSync() КЭ commitAsync() ЗНЗЈЪБДЋШыЯЃЭћЬсНЛЕФ partition КЭ offset ЕФ map,МДЬсНЛЬиЖЈЕФЦЋвЦСПЁЃ
2.4 ИпаЇЖСаДЪ§Он
ИпаЇЖСаДЪ§ОнЕФдвђ:
- ЫГађаДДХХЬ:ЭЌбљЕФДХХЬ,ЫГађаДФмЕНЕН600M/s,ЖјЫцЛњаДжЛга100k/s
- гІгУpagecache:KafkaЪ§ОнГжОУЛЏЪЧжБНгГжОУЛЏЕНPagecacheжа,ГфЗжРћгУЫљгаЕФПеЯаФкДцЁЃ
- СуПНБДММЪѕ:ЫљЮНЕФСуПНБДЪЧжИНЋЪ§ОнжБНгДгДХХЬЮФМўИДжЦЕНЭјПЈЩшБИжа,ЖјВЛашвЊОгЩгІгУГЬађжЎЪжЁЃСуПНБДДѓДѓЬсИпСЫгІгУГЬађЕФадФм,МѕЩйСЫФкКЫКЭгУЛЇФЃЪНжЎМфЕФЩЯЯТЮФЧаЛЛЁЃ
2.5 zookeeperдкkafkaжазїгУ
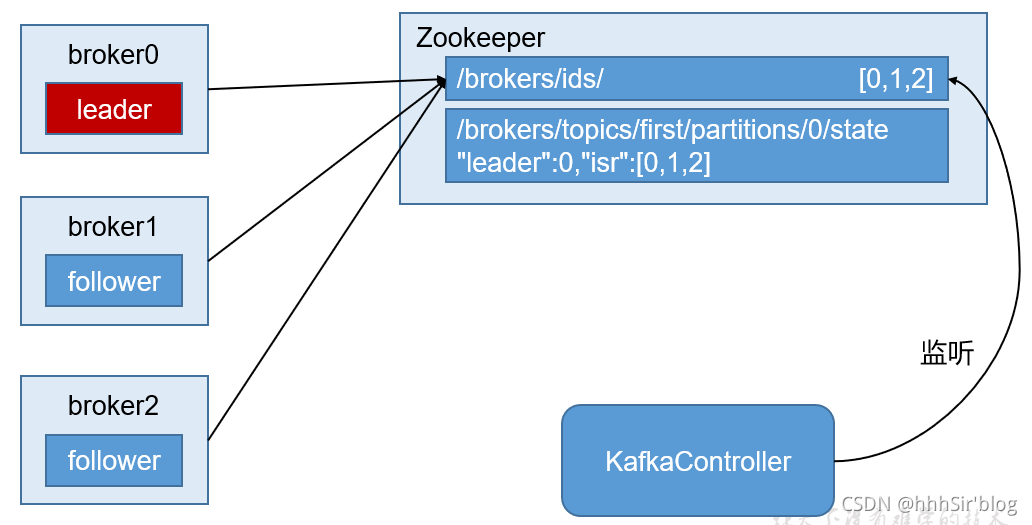
KafkaМЏШКжагавЛИіbrokerЛсБЛбЁОйЮЊController,ИКд№ЙмРэМЏШКbrokerЕФЩЯЯТЯп,ЫљгаtopicЕФЗжЧјИББОЗжХфКЭleaderбЁОйЕШЙЄзїЁЃControllerЕФЙмРэЙЄзїЖМЪЧвРРЕгкZookeeperЕФЁЃ

kafkaжаХфжУЕФИїЯюФПТМ,гУгкаЕїconsumerКЭbrokerЁЃЯТЭМОЭЪЧleaderЪЇаЇжЎКѓ,kafkaжаzookeeperПижЦбЁОйЕФЙ§ГЬЁЃдРэдкЩЯУцвбОНВЙ§СЫЁЃ
2.6 kafkaЪТЮё
KafkaДг0.11АцБОПЊЪМв§ШыСЫЪТЮёжЇГжЁЃЪТЮёПЩвдБЃжЄKafkaдкExactly OnceгявхЕФЛљДЁЩЯ,ЩњВњКЭЯћЗбПЩвдПчЗжЧјКЭЛсЛА,вЊУДШЋВПГЩЙІ,вЊУДШЋВПЪЇАмЁЃ
2.6.1 ProducerЪТЮё
ЮЊСЫЪЕЯжПчЗжЧјПчЛсЛАЕФЪТЮё,ашвЊв§ШывЛИіШЋОжЮЈвЛЕФTransaction ID,ВЂНЋProducerЛёЕУЕФPIDКЭTransaction IDАѓЖЈЁЃетбљЕБProducerжиЦєКѓОЭПЩвдЭЈЙ§е§дкНјааЕФTransaction IDЛёЕУдРДЕФPIDЁЃ
ЮЊСЫЙмРэTransaction,Kafkaв§ШыСЫвЛИіаТЕФзщМўTransaction CoordinatorЁЃProducerОЭЪЧЭЈЙ§КЭTransaction CoordinatorНЛЛЅЛёЕУTransaction IDЖдгІЕФШЮЮёзДЬЌЁЃTransaction CoordinatorЛЙИКд№НЋЪТЮёЫљгааДШыKafkaЕФвЛИіФкВПTopic,етбљМДЪЙећИіЗўЮёжиЦє,гЩгкЪТЮёзДЬЌЕУЕНБЃДц,НјаажаЕФЪТЮёзДЬЌПЩвдЕУЕНЛжИД,ДгЖјМЬајНјааЁЃ
2.6.2 ConsumerЪТЮё
ЩЯЪіЪТЮёЛњжЦжївЊЪЧДгProducerЗНУцПМТЧ,ЖдгкConsumerЖјбд,ЪТЮёЕФБЃжЄОЭЛсЯрЖдНЯШѕ,гШЦфЪБЮоЗЈБЃжЄCommitЕФаХЯЂБЛОЋШЗЯћЗбЁЃетЪЧгЩгкConsumerПЩвдЭЈЙ§offsetЗУЮЪШЮвтаХЯЂ,ЖјЧвВЛЭЌЕФSegment FileЩњУќжмЦкВЛЭЌ,ЭЌвЛЪТЮёЕФЯћЯЂПЩФмЛсГіЯжжиЦєКѓБЛЩОГ§ЕФЧщПіЁЃ
ШчЙћЯыЭъГЩConsumerЖЫЕФОЋзМвЛДЮадЯћЗб,ФЧУДашвЊkafkaЯћЗбЖЫНЋЯћЗбЙ§ГЬКЭЬсНЛoffsetЙ§ГЬзідзгАѓЖЈЁЃДЫЪБЮвУЧашвЊНЋkafkaЕФoffsetБЃДцЕНжЇГжЪТЮёЕФздЖЈвхНщжЪжа(БШШчmysql)ЁЃетВПЗжжЊЪЖЛсдкКѓајЯюФПВПЗжЩцМАЁЃ
Нсгя
ШчЙћЯждкКмУдУЃ,гаКмЖрИібЁдё,ФЧОЭбЁвЛИіЯШМсГжзпЯТШЅАЩЁЃ