spark
Spark ����ģʽ
���½����ڸ�������ģʽ������� Spark Ӧ��.
������Ҫ���� Spark
1.������ַ http://spark.apache.org/
2.�ĵ��鿴��ַ https://spark.apache.org/docs/2.1.1/
3.���ص�ַ https://archive.apache.org/dist/spark/
Ŀǰ���°汾Ϊ 2.4.4, ���ǵ�������ҵʹ�����������Ȼѡ�� 2.1.1 ��ѧϰ. ����2.x.x �İ汾�����.
Local ģʽ
Local ģʽ����ָ��ֻ��һ̨������������� Spark.
ͨ�����ڲ��Ե�Ŀ����ʹ�� Local ģʽ, ʵ�ʵ����������в���ʹ�� Local ģʽ.
��ѹ Spark ��װ��
�Ѱ�װ���ϴ���/opt/software/��, ����ѹ��/opt/module/Ŀ¼��
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module
Ȼ���Ƹոս�ѹ�õ���Ŀ¼, ������Ϊspark-local:
cp -r spark-2.1.1-bin-hadoop2.7 spark-local
���йٷ���PI�İ���
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
ע��:
?������shell��ʹ�õ�zsh, ����Ҫ��local[2]��������:��local[2]��
˵��:
?ʹ��spark-submit������Ӧ�ó���.
?�:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
�C�Cmaster ָ�� master �ĵ�ַ,Ĭ��Ϊlocal. ��ʾ�ڱ�������.
�C�Cclass ���Ӧ�õ������� (�� org.apache.spark.examples.SparkPi)
?�Cdeploy-mode �Ƿ���������� worker�ڵ�(cluster ģʽ) ������Ϊһ�����ؿͻ��� (client ģʽ) (default: client)
?�Cconf: ����� Spark ��������, ��ʽkey=value. ���ֵ�����ո�,���Լ�����"key=value"
?application-jar: ����õ�Ӧ�� jar,��������. ��� URL �ڼ�Ⱥ��ȫ�ֿɼ��� ����hdfs:// �����洢ϵͳ, ����� file:// path, ��ô���еĽڵ��path������ͬ����jar
?application-arguments: ����main()�����IJ���
?�Cexecutor-memory 1G ָ��ÿ��executor�����ڴ�Ϊ1G
?�Ctotal-executor-cores 6 ָ������executorʹ�õ�cpu����Ϊ6��
?�Cexecutor-cores ��ʾÿ��executorʹ�õ� cpu �ĺ���
?���� Master URL ��˵��

��ע: Ҳ����ʹ��run-examples������
bin/run-example SparkPi 100
ʹ�� Spark-shell
Spark-shell �� Spark �������ṩ�Ľ���ʽ�����(������ Scala �� REPL)
�������� Spark-shell ��ʹ�� Spark ��ͳ���ļ��и������ʵ�����.
����1: ���� 2 ���ı��ļ�
mkdir input
cd input
touch 1.txt
touch 2.txt
�ֱ��� 1.txt �� 2.txt ������һЩ����.
����2: �� Spark-shell
bin/spark-shell
����3: �鿴���̺�ͨ�� web �鿴Ӧ�ó����������
����4: ���� wordcount ����
sc.textFile("input/").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect
����5: ��¼hadoop201:4040�鿴��������
�ύ����
Spark ͨ�����м�������
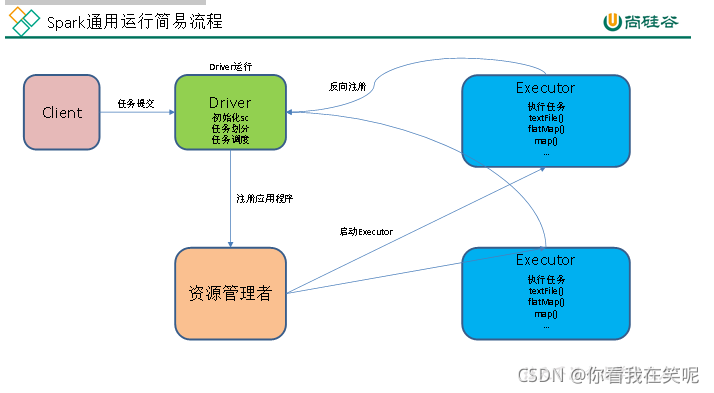
wordcount �������̷���:
 1.textFile(��input��):��ȡ�����ļ�input�ļ�������;
1.textFile(��input��):��ȡ�����ļ�input�ļ�������;
2.flatMap(.split(" ")):ѹƽ����,���տո�ָ����һ������ӳ���һ��������;
3.map((,1)):��ÿһ��Ԫ�ز���,������ӳ��ΪԪ��;
4.reduceByKey(+):����key��ֵ���оۺ�,���;
5.collect:�������ռ���Driver��չʾ��
Spark ���ĸ������
Master
Spark ������Դ����ϵͳ�� Leader���ƹ���������Ⱥ����Դ��Ϣ,������ Yarn ����е� ResourceManager,��Ҫ����:
1.���� Worker,�� Worker �Ƿ���������;
2.Master �� Worker��Application �ȵĹ���(���� Worker ��ע�Ტ�������е�Worker,���� Client �ύ�� Application,���ȵȴ��� Application ����Worker �ύ)��
Worker
Spark ������Դ����ϵͳ�� Slave,�ж����ÿ�� Slave �ƹ������ڽڵ����Դ��Ϣ,������ Yarn ����е� NodeManager,��Ҫ����:
1.ͨ�� RegisterWorker ע�ᵽ Master;
2.��ʱ���������� Master;
3.���� Master ���͵� Application ���ý��̻���,������ ExecutorBackend(ִ�� Task �������ʱ����)
driver program(��������)
ÿ�� Spark Ӧ�ó�����һ����������, ����������Ѳ��в�����������Ⱥ��.
����������� Spark Ӧ�ó����е�������, �����˷ֲ�ʽ���ݼ���Ӧ���ڼ�Ⱥ��.
��ǰ���wordcount��������, spark-shell �������ǵ���������, �������ǿ��������м��������κ���Ҫ�IJ���, Ȼ����������.
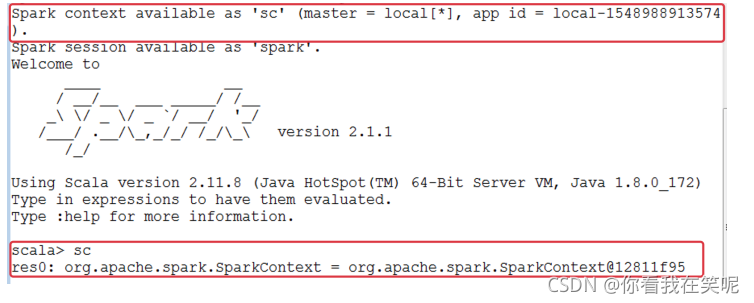
��������ͨ��SparkContext���������� Spark, SparkContext�����൱��һ���� Spark ��Ⱥ������.
�� spark-shell ��, ���Զ�����һ��SparkContext����, ���������������Ϊsc.
executor(ִ����)
SparkContext����һ���ɹ����ӵ���Ⱥ������, �Ϳ��Ի�ȡ����Ⱥ��ÿ���ڵ��ϵ�ִ����(executor).
ִ������һ������(������: ExecutorBackend, ������ Worker �ڵ���), ����ִ�м����ΪӦ�ó���洢����.
Ȼ��, Spark �ᷢ��Ӧ�ó������(����:jar��)��ÿ��ִ����. ���, SparkContext����������ִ������ʼִ�г���.

RDDs(Resilient Distributed Dataset) ���Էֲ�ʽ���ݼ�
һ��ӵ����SparkContext����, �Ϳ���ʹ���������� RDD ��. ��ǰ���������, ���ǵ���sc.textFile(��)��������һ�� RDD, ��ʾ�ļ��е�ÿһ���ı�. ���ǿ��Զ���Щ�ı������и��ָ����IJ���.
�ڵڶ����ֵ�SparkCore��, �����ص����ѧϰ RDD.
cluster managers(��Ⱥ������)
Ϊ����һ�� Spark ��Ⱥ�����м���, SparkContext����������ӵ����ּ�Ⱥ������(Spark��s own standalone cluster manager, Mesos or YARN).
��Ⱥ�����������Ӧ�ó��������Դ.
רҵ�����б�


Standalone ģʽ
����һ���� Master + Slave ���ɵ� Spark ��Ⱥ,Spark �����ڼ�Ⱥ�С�
���Ҫ�� Hadoop �е� Standalone ������. ����� Standalone ��ָֻ�� Spark ���һ����Ⱥ, ����Ҫ���������Ŀ��.������� Yarn �� Mesos ��˵��.
���� Standalone ģʽ
����1: ���� spark, ������Ϊspark-standalone
cp -r spark-2.1.1-bin-hadoop2.7 spark-standalone
����2: ���������ļ�Ŀ¼conf, ����spark-evn.sh
cd conf/
cp spark-env.sh.template spark-env.sh
��spark-env.sh�ļ���������������:
SPARK_MASTER_HOST=hadoop201
SPARK_MASTER_PORT=7077 # Ĭ�϶˿ھ���7077, ����ʡ�Բ���
����3: �� slaves �ļ�, ���� worker �ڵ�
cp slaves.template slaves
��slaves�ļ���������������:
hadoop201
hadoop202
hadoop203
����4: �ַ�spark-standalone
����5: ���� Spark ��Ⱥ
sbin/start-all.sh
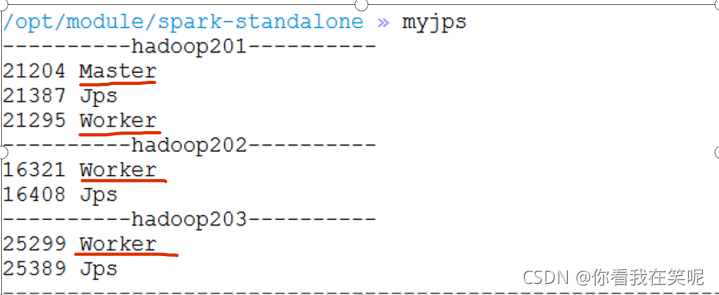
��������������
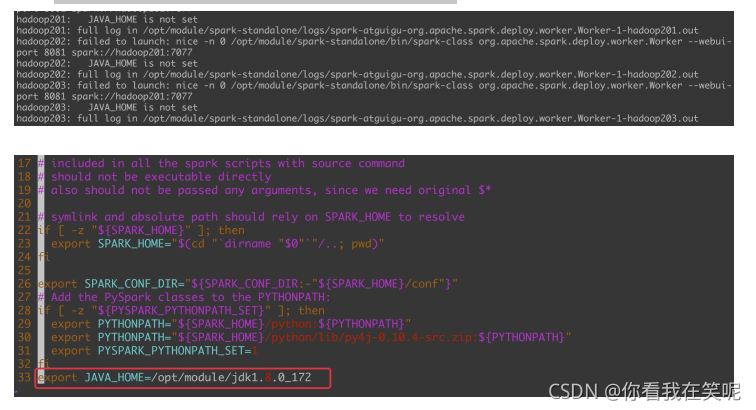
?���������ʱ��:JAVA_HOME is not set, ����sbin/spark-config.sh��������JAVA_HOME��������. ��Ҫ���Ƿַ��ĵ��ļ�
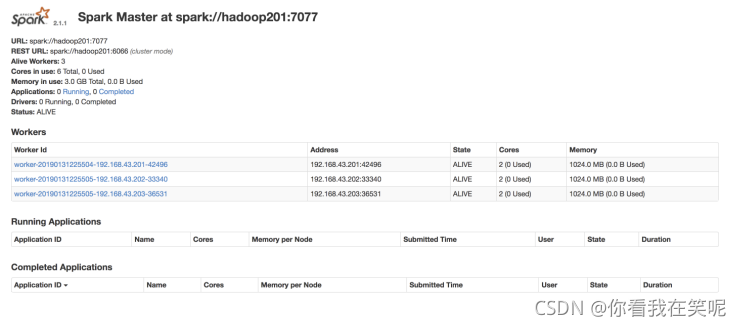
����6: ����ҳ�в鿴 Spark ��Ⱥ���
��ַ: http://hadoop201:8080
 ### ʹ�� Standalone ģʽ���м��� PI �ij���
### ʹ�� Standalone ģʽ���м��� PI �ij���
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop201:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
