����: Grey
ԭ�ĵ�ַ:MySQLѧϰ�ʼ�
˵��
ע:�����е�SQL�������õ����ض�����,���ǻ���MySQL���ݿ⡣
һ��SQL��ִ������
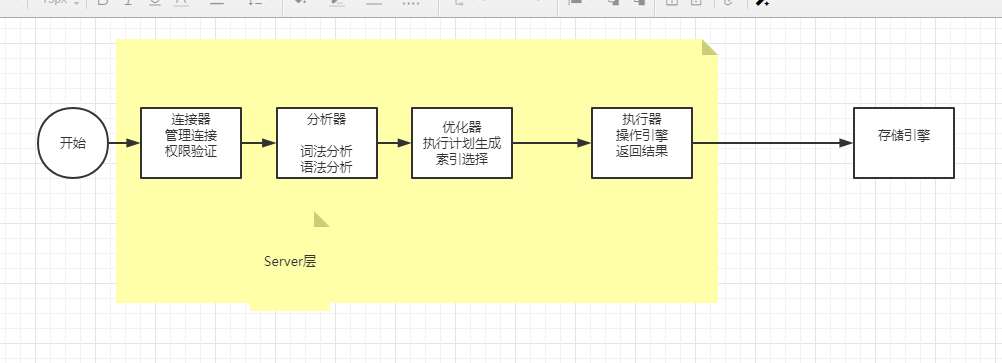
����Dz�ѯ���,������������ͼ,����Ǹ������,ͬ��Ҫ��������,ͬʱ���������������IJ�ѯ����������ա�������,��������ͨ���ʷ��������֪������һ��������䡣�Ż�������Ҫʹ�� ID ���������Ȼ��,ִ�����������ִ��,�ҵ���һ��,Ȼ����¡����ѯ���̲�һ������,�������̻��漰������Ҫ����־ģ��:redo log(������־)�� binlog(�鵵��־)
Redo Log VS BinLog
Redo Log���������־
ʹ����WAL����,��д��־,��д����,����һ����¼��Ҫ���µ�ʱ��,InnoDB ����ͻ��ȰѼ�¼д�� redo log(�۰�)����,�������ڴ�,���ʱ����¾�������ˡ�ͬʱ,InnoDB ��������ʵ���ʱ��,�����������¼���µ���������,�����������������ϵͳ�ȽϿ��е�ʱ����
redo log�ǹ̶���С��,��������һ��4���ļ�,ÿ���ļ���С1GB,��ô���Լ�¼4G��¼��
���� redo log,InnoDB �Ϳ��Ա�֤��ʹ���ݿⷢ���쳣����,֮ǰ�ύ�ļ�¼�����ᶪʧ,���������Ϊ crash-safe��
binlog��Server����־
- redo log �� InnoDB �������е�;binlog �� MySQL �� Server ��ʵ�ֵ�,�������涼����ʹ�á�
- redo log ��������־,��¼���ǡ���ij������ҳ������ʲô�ġ�;binlog ������־,��¼�����������ԭʼ��,���硰�� ID=2 ��һ�е� c �ֶμ� 1 ����redo log ��ѭ��д��,�ռ�̶�������;
- binlog �ǿ�����д��ġ�����д����ָ binlog �ļ�д��һ����С����л�����һ��,�����Ḳ����ǰ����־��
����,��������redo log,binlog������ȥ��,һ��ԭ����,redologֻ��InnoDB��,�������û�С���һ��ԭ����,redolog��ѭ��д��,���־ñ���,binlog�ġ��鵵���������,redolog�Dz��߱��ġ�
�����ύ
MySQL��ִ����θ��²�����ʱ��:
update T set c=c+1 where ID=2;
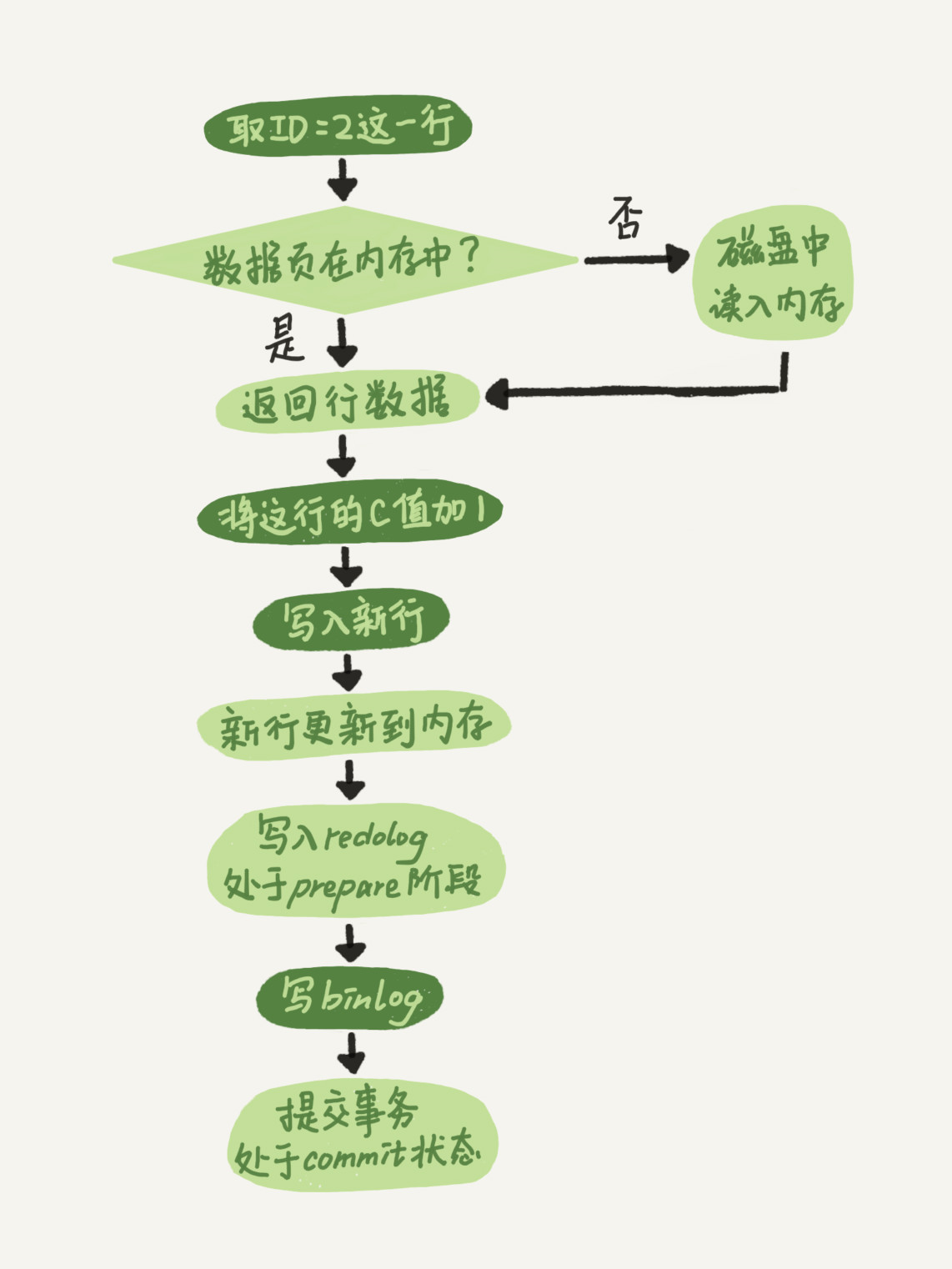
ͼƬ������:MySQLʵս45��
������������ͼ: ͼ��dzɫ���ʾ���� InnoDB �ڲ�ִ�е�,��ɫ���ʾ����ִ������ִ�еġ���������� redo log ��д��������������:prepare �� commit,�����"�����ύ"��
ΪʲôҪʹ�������ύ?��ǰ��� update ����������ӡ����赱ǰ ID=2 ����,�ֶ� c ��ֵ�� 0,�ټ���ִ�� update ����������д���һ����־��,�ڶ�����־��û��д���ڼ䷢���� crash,�����ʲô�����?
-
��д redo log ��д binlog�������� redo log д��,binlog ��û��д���ʱ��,MySQL �����쳣��������������ǰ��˵����,redo log д��֮��,ϵͳ��ʹ����,��Ȼ�ܹ������ݻָ�����,���Իָ�����һ�� c ��ֵ�� 1���������� binlog ûд��� crash ��,��ʱ�� binlog �����û�м�¼�����䡣���,֮����־��ʱ��,�������� binlog �����û��������䡣Ȼ����ᷢ��,�����Ҫ����� binlog ���ָ���ʱ��Ļ�,����������� binlog ��ʧ,�����ʱ��ͻ�������һ�θ���,�ָ���������һ�� c ��ֵ���� 0,��ԭ���ֵ��ͬ��
-
��д binlog ��д redo log������� binlog д��֮�� crash,���� redo log ��ûд,�����ָ��Ժ����������Ч,������һ�� c ��ֵ�� 0������ binlog �����Ѿ���¼�ˡ��� c �� 0 �ij� 1�������־������,��֮���� binlog ���ָ���ʱ��Ͷ���һ���������,�ָ���������һ�� c ��ֵ���� 1,��ԭ���ֵ��ͬ��
���Կ���,�����ʹ�á������ύ��,��ô���ݿ��״̬���п��ܺ���������־�ָ������Ŀ��״̬��һ�¡�
redo log ���ڱ�֤ crash-safe ������innodb_flush_log_at_trx_commit ����������ó� 1 ��ʱ��,��ʾÿ������� redo log ��ֱ�ӳ־û������̡���������ҽ��������ó� 1,�������Ա�֤ MySQL �쳣����֮�����ݲ���ʧ��
sync_binlog ����������ó� 1 ��ʱ��,��ʾÿ������� binlog ���־û������̡����������Ҳ���������ó� 1,�������Ա�֤ MySQL �쳣����֮�� binlog ����ʧ��
����DDL
DDL ��Ӣ��ȫ���� Data Definition Language,���������ݶ������ԡ������������ݿ�Ľṹ�����ݱ��Ľṹ���� DDL ��,���dz��õĹ�������ɾ��,�ֱ��Ӧ�������� CREATE��DROP �� ALTER��
��Ҫע�����:��ִ�� DDL ��ʱ��,����Ҫ COMMIT,�Ϳ������ִ������
�������
���������utf8_general_ci,�����Դ�Сд�����С�
�������Ϊutf8_bin,�����Դ�Сд���С�
DISTINCT
DISTINCT��ʵ�ǶԺ���������������Ͻ���ȥ��
SELECT DISTINCT attack_range, name FROM heros
��ʵ�Ƕ�(attack_range,name)������ȥ�ء�
Լ�����ؽ��������
�����ڲ�ѯ������,���ǿ���Լ�����ؽ��������,ʹ�� LIMIT �ؼ��֡�
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5
�ڲ�ͬ�� DBMS ��ʹ�õĹؼ��ֿ��ܲ�ͬ���� MySQL��PostgreSQL��MariaDB �� SQLite ��ʹ�� LIMIT �ؼ���,������Ҫ�ŵ� SELECT ��������档����� SQL Server �� Access,��Ҫʹ�� TOP �ؼ���,����:
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
����� DB2,ʹ��FETCH FIRST 5 ROWS ONLY�����Ĺؼ���:
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
����� Oracle,����Ҫ���� ROWNUM ��ͳ������:
SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC
��Ҫ˵������,�����������ȡ����ǰ 5 ��������,Ȼ���ٰ��� hp_max �Ӹߵ��͵�˳���������, �������д:
SELECT name, hp_max FROM (SELECT name, hp_max FROM heros ORDER BY hp_max) WHERE ROWNUM <=5
�ͱ�ʾ��ִ�в�ѯ���,�������˽���е�ǰ������
WHERE����� AND �� OR���ȼ�
WHERE �Ӿ���ͬʱ���� AND �� OR ��������ʱ��,����Ҫ���ǵ�ִ�е��Ⱥ�˳��,Ҳ��������������ִ�е����ȼ���һ����˵ () ���ȼ����,������ȼ��� AND,Ȼ���� OR��
SQL�е������淶
MySQL �� Linux �Ļ�����,���ݿ��������������������ϸ����ִ�Сд��,���ֶ����Ǻ��Դ�Сд�ġ�
�� MySQL �� Windows �Ļ�����ȫ�������ִ�Сд��
SQL��д��һ���淶:
- ���ݿ��������������������ֶ������ֶα����ȶ�Сд
- SQL�����֡��������������ȶ���д
- ���ݱ����ֶ����Ƽ������»�������
- SQL�������ԷֺŽ�β
COUNT(�ֶ�) , COUNT(*) �� COUNT(1)
COUNT(�ֶ�)������ֶ�ֵֵΪNULL��������,��COUNT( * )��COUNT(1)ֻ��ͳ����������,����ij���ֶ��Ƿ�ΪNULL��
AVG��MAX��MIN�Ⱦۼ��������Զ�����ֵΪNULL�������С�
�����Ӳ�ѯ�ͷǹ����Ӳ�ѯ
���������Ӳ�ѯ�Ƿ�ִ�ж��,�Ӷ����Ӳ�ѯ����Ϊ�����Ӳ�ѯ�ͷǹ����Ӳ�ѯ���Ӳ�ѯ�����ݱ��в�ѯ�����ݽ��,���������ݽ��ִֻ��һ��,Ȼ��������ݽ����Ϊ����ѯ����������ִ��,��ô�������Ӳ�ѯ�����ǹ����Ӳ�ѯ��ͬ��,����Ӳ�ѯ��Ҫִ�ж��,������ѭ���ķ�ʽ,�ȴ��ⲿ��ѯ��ʼ,ÿ�ζ������Ӳ�ѯ���в�ѯ,Ȼ���ٽ�����������ⲿ,����Ƕ��ִ�з�ʽ�ͳ�Ϊ�����Ӳ�ѯ
һ���ǹ����Ӳ�ѯ������:
SELECT player_name, height FROM player WHERE height = (SELECT max(height) FROM player)
һ�������Ӳ�ѯ������:
SELECT player_name, height, team_id FROM player AS a WHERE height > (SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id)
(NOT) EXISTS�Ӳ�ѯ
SELECT player_id, team_id, player_name FROM player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
IN VS EXISTS
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc)
ʵ�����ڲ�ѯ������,�����Ƕ� cc �н��������������,���ǻ���Ҫ�жϱ� A �ͱ� B �Ĵ�С�����������ӵ���,�� A ָ���� player ��,�� B ָ���� player_score ��������� A �ȱ� B ��,��ô IN �Ӳ�ѯ��Ч��Ҫ�� EXIST �Ӳ�ѯЧ�ʸ�,��Ϊ��ʱ B ��������� cc �н���������,��ô IN �Ӳ�ѯ��Ч�ʾͻ�Ƚϸߡ�ͬ��,����� A �ȱ� B С,��ôʹ�� EXISTS �Ӳ�ѯЧ�ʻ����,��Ϊ���ǿ���ʹ�õ� A ���ж� cc �е�����,�����ô� B �н��� cc �еIJ�ѯ��
�� A С�� B ʱ,�� EXISTS����Ϊ EXISTS ��ʵ��,�൱�����ѭ��,ʵ�ֵ���������:
for i in A
for j in B
if j.cc == i.cc then ...
�� B С�� A ʱ�� IN,��Ϊʵ�ֵ���������:
for i in B
for j in A
if j.cc == i.cc then ...
�ĸ���С�����ĸ���������,A ��С���� EXISTS,B ��С���� IN��
����һЩ�Ӳ�ѯ�Ĺؼ���:EXISTS��IN��ANY��ALL �� SOME
����
һ���ĺ�������:Leetcode 177. Nth Highest Salary
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N = N - 1;
RETURN (
SELECT DISTINCT Salary FROM Employee GROUP BY Salary
ORDER BY Salary DESC LIMIT 1 OFFSET N
);
END
Employee����������:
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
��������:
SELECT getNthHighestSalary(3);
���:
+------------------------+
| getNthHighestSalary(3) |
+------------------------+
| 100 |
+------------------------+
�洢����
DELIMITER //
CREATE PROCEDURE `add_num`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END //
DELIMITER ;
����
CALL add_num(10);
��һ������
CREATE PROCEDURE `get_hero_scores`(
OUT max_max_hp FLOAT,
OUT min_max_mp FLOAT,
OUT avg_max_attack FLOAT,
s VARCHAR(255)
)
BEGIN
SELECT MAX(hp_max), MIN(mp_max), AVG(attack_max) FROM heros WHERE role_main = s INTO max_max_hp, min_max_mp, avg_max_attack;
END
����
CALL get_hero_scores(@max_max_hp, @min_max_mp, @avg_max_attack, 'սʿ');
SELECT @max_max_hp, @min_max_mp, @avg_max_attack;
���ʹ���α�
CREATE PROCEDURE `calc_hp_max`()
BEGIN
-- ���������α�ı���
DECLARE hp INT;
-- ������������
DECLARE hp_sum INT DEFAULT 0;
-- ����������־����
DECLARE done INT DEFAULT false;
-- �����α�
DECLARE cur_hero CURSOR FOR SELECT hp_max FROM heros;
-- ָ���α�ѭ������ʱ�ķ���ֵ
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
OPEN cur_hero;
read_loop:LOOP
FETCH cur_hero INTO hp;
-- �ж��α��ѭ���Ƿ����
IF done THEN
LEAVE read_loop;
END IF;
SET hp_sum = hp_sum + hp;
END LOOP;
CLOSE cur_hero;
SELECT hp_sum;
END
�����ӵ�һ������
CREATE PROCEDURE `alter_attack_growth`()
BEGIN
-- ���������α�ı���
DECLARE temp_id INT;
DECLARE temp_growth, temp_max, temp_start, temp_diff FLOAT;
-- ����������־����
DECLARE done INT DEFAULT false;
-- �����α�
DECLARE cur_hero CURSOR FOR SELECT id, attack_growth, attack_max, attack_start FROM heros;
-- ָ���α�ѭ������ʱ�ķ���ֵ
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
OPEN cur_hero;
FETCH cur_hero INTO temp_id, temp_growth, temp_max, temp_start;
REPEAT
IF NOT done THEN
SET temp_diff = temp_max - temp_start;
IF temp_growth < 5 THEN
IF temp_diff > 200 THEN
SET temp_growth = temp_growth * 1.1;
ELSEIF temp_diff >= 150 AND temp_diff <=200 THEN
SET temp_growth = temp_growth * 1.08;
ELSEIF temp_diff < 150 THEN
SET temp_growth = temp_growth * 1.07;
END IF;
ELSEIF temp_growth >=5 AND temp_growth <=10 THEN
SET temp_growth = temp_growth * 1.05;
END IF;
UPDATE heros SET attack_growth = ROUND(temp_growth,3) WHERE id = temp_id;
END IF;
FETCH cur_hero INTO temp_id, temp_growth, temp_max, temp_start;
UNTIL done = true END REPEAT;
CLOSE cur_hero;
END
�Զ��ύ(autocommit)
set autocommit =0; //�ر��Զ��ύ
set autocommit =1; //�����Զ��ύ
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;
BEGIN;
INSERT INTO test SELECT '����';
COMMIT;
BEGIN;
INSERT INTO test SELECT '�ŷ�';
INSERT INTO test SELECT '�ŷ�';
ROLLBACK;
SELECT * FROM test;
"�ŷ�"������¼,������ݿ�δ�����Զ��ύ,�����,����������Զ��ύ,��ڶ������ŷɡ������ع�������,���ǵ�һ�����ŷɡ�������Ȼ����롣
completion_type
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;
SET @@completion_type = 1;
BEGIN;
INSERT INTO test SELECT '����';
COMMIT;
INSERT INTO test SELECT '�ŷ�';
INSERT INTO test SELECT '�ŷ�';
ROLLBACK;
SELECT * FROM test;
MySQL �� completion_type ��������� 3 �ֿ���:
-
completion=0,����Ĭ�������Ҳ����˵������ִ�� COMMIT ��ʱ����ύ����,��ִ����һ������ʱ,����Ҫ����ʹ�� START TRANSACTION ���� BEGIN ��������
-
completion=1,���������,�������ύ�����,�൱��ִ���� COMMIT AND CHAIN,Ҳ���ǿ���һ����ʽ����,���������ύ����֮��Ὺ��һ����ͬ���뼶�������)��
-
completion=2,��������� COMMIT=COMMIT AND RELEASE,Ҳ���ǵ������ύ��,���Զ���������Ͽ����ӡ�
��������
���(Dirty Read)
��������������û���ύ�����ݡ�
�����ظ���(Nnrepeatable Read)
��ij���ݽ��ж�ȡ,�������ζ�ȡ�Ľ����ͬ,Ҳ����˵û�ж�����ͬ�����ݡ�������Ϊ������������������ͬʱ�������Ļ�ɾ����
�ö�(Phantom Read)
���� A ����������ѯ�õ��� N ������,����ʱ���� B ���Ļ��������� M ���������� A ��ѯ����������,���������� A �ٴν��в�ѯ��ʱ���ֻ��� N+M ������,�����˻ö���
SQL-92 ���������� 4 �ָ��뼶���������Щ�쳣�����
��Щ���뼶���ܽ�����쳣������±���ʾ:
| ��� | �����ظ��� | �ö� | |
|---|---|---|---|
| ��δ�ύ(READ UNCOMMITTED) | ���� | ���� | ���� |
| �����ύ(READ COMMITTED) | ��ֹ | ���� | ���� |
| ���ظ���(REPEATABLE READ) | ��ֹ | ��ֹ | ���� |
| �ɴ��л�(SERIALIZABLE | ��ֹ | ��ֹ | ��ֹ |
- ��δ�ύ,Ҳ������������δ�ύ������,��������²�ѯ�Dz���ʹ������,���ܻ��������������ظ������ö��������
- �����ύ,����ֻ�ܶ����Ѿ��ύ������,���Ա�������IJ���,���� RDBMS �г�����Ĭ�ϸ��뼶��(����˵ Oracle �� SQL Server),�������Ҫ���ⲻ���ظ������ö�,����Ҫ������ SQL ��ѯ��ʱ���д�������� SQL ���
- ���ظ���,��֤һ����������ͬ��ѯ���������β�ѯ�õ������ݽ����һ�µ�,���Ա��ⲻ���ظ��������,��������ö���MySQL Ĭ�ϵĸ��뼶����ǿ��ظ�����
- �ɴ��л�,��������д��л�,Ҳ������һ�������а���˳��ִ��,�ɴ��л��������ĸ���ȼ�,���Խ�������ȡ�����п��ܳ��ֵ��쳣���,������������ϵͳ�IJ����ԡ�
��ʵ����,���ݿ�����ᴴ��һ����ͼ,���ʵ�ʱ������ͼ�������Ϊ��
�ڡ����ظ��������뼶����,�����ͼ������������ʱ������,������������ڼ䶼�������ͼ��
�ڡ����ύ�����뼶����,�����ͼ����ÿ�� SQL ��俪ʼִ�е�ʱ���ġ�
����δ�ύ�����뼶����ֱ�ӷ��ؼ�¼�ϵ�����ֵ,û����ͼ����;
�����л������뼶����ֱ���ü����ķ�ʽ�����Ⲣ�з��ʡ�
���ǿ��Կ����ڲ�ͬ�ĸ��뼶����,���ݿ���Ϊ��������ͬ�ġ�Oracle ���ݿ��Ĭ�ϸ��뼶����ʵ���ǡ����ύ��,��˶���һЩ�� Oracle Ǩ�Ƶ� MySQL ��Ӧ��,Ϊ��֤���ݿ���뼶���һ��,��һ��Ҫ�ǵý� MySQL �ĸ��뼶������Ϊ�����ύ����
�鿴���뼶��
SHOW VARIABLES LIKE 'transaction_isolation';
���ø��뼶��
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
����MVCC
��汾�������Ƽ���,��ͨ�������еĶ���汾������ʵ�����ݿ�IJ�������,����˵����˼����DZ������ݵ���ʷ�汾���������ǾͿ���ͨ���Ƚϰ汾�ž��������Ƿ���ʾ����,��ȡ���ݵ�ʱ����Ҫ����Ҳ���Ա�֤����ĸ���Ч����
ͨ�� MVCC ���ǿ��Խ�����¼�������:
-
��д֮������������,ͨ�� MVCC �����ö�д�������,����������д,д��������,�����Ϳ���������������������
-
�����������ĸ��ʡ�������Ϊ MVCC �������ֹ����ķ�ʽ,��ȡ����ʱ������Ҫ����,����д����,Ҳֻ������Ҫ���С�
-
���һ���Զ������⡣һ���Զ�Ҳ����Ϊ���ն�,�����Dz�ѯ���ݿ���ij��ʱ���Ŀ���ʱ,ֻ�ܿ������ʱ���֮ǰ�����ύ���µĽ��,�����ܿ������ʱ���֮�������ύ�ĸ��½����
ʹ��������������ʵ��:
- ����汾��
- �м�¼��������
- Undo Log
InnoDB ��,MVCC ��ͨ�� Undo Log + Read View �������ݶ�ȡ,Undo Log ��������ʷ����,�� Read View ����������жϵ�ǰ�汾�������Ƿ�ɼ�����Ҫ˵������,�ڸ��뼶��Ϊ�����ύ(Read Commit)ʱ,һ�������е�ÿһ�� SELECT ��ѯ�����ȡһ�� Read View��
���ֻö���ԭ�����ڶ����ύ�������,InnoDB ֻ���ü�¼��(Record Locking)������Ҫ������ InnoDB ���������ķ�ʽ:��¼��:��Ե����м�¼����������϶��(Gap Locking):����������סһ����Χ(����֮��Ŀ�϶),����������¼���������ü�϶���ķ�ʽ���Է�ֹ�ö�����IJ�����Next-Key ��:��������סһ����Χ,ͬʱ������¼����,�൱�ڼ�϶�� + ��¼��,���Խ���ö������⡣�ڸ��뼶��Ϊ���ظ���ʱ,InnoDB ����� Next-Key ���Ļ���,�����ǽ���ö����⡣
Ϊʲô���龡����Ҫʹ�ó�����
��������ζ��ϵͳ�������ں��ϵ�������ͼ��������Щ������ʱ���ܷ������ݿ�������κ�����,������������ύ֮ǰ,���ݿ������������õ��Ļع���¼�����뱣��,��ͻᵼ�´���ռ�ô洢�ռ䡣�� MySQL 5.5 ����ǰ�İ汾,�ع���־�Ǹ������ֵ�һ����� ibdata �ļ����,��ʹ�����������ύ,�ع��α�����,�ļ�Ҳ�����С��
���˶Իع��ε�Ӱ��,������ռ������Դ,Ҳ�����Ͽ������⡣
�� information_schema ��� innodb_trx ������в�ѯ������,��������������,���ڲ��ҳ���ʱ�䳬�� 60s ������
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
һ��һ�� VS һ��һ��
��һ��һ����ģʽ��,��������ҪӦ��һ��� binlog������,��ÿ�� 0 ����һ��ȫ������,��Ҫ�ָ���һ������������ 23 ��ı��ݡ�һ��һ��������ҪӦ��һ�ܵ� binlog �ˡ�
�������ݿ����
��ͼ������20ح������˼�����ݿ���ŵ�ʱ��,������Щά�ȿ���ѡ��?
���ڸ��ַ�ʽ
1NF ָ�������ݿ���е��κ����Զ���ԭ���Ե�,�����ٷ֡�
2NF ָ�����ݱ���ķ������Զ�Ҫ��������ݱ��ĺ�ѡ������ȫ������ϵ����ν��ȫ������ͬ�ڲ�������,Ҳ���Dz��ܽ�������ѡ����һ��������,����������ȫ�����ԡ�
һ��û������ 2NF ������,
һ����Ա������ player_game,���������Ա��š����������䡢������š�����ʱ��ͱ������ص�����,
�����ѡ����������Ϊ:(��Ա���,�������),
���ǿ���ͨ����ѡ�����������µĹ�ϵ:
(��Ա���, �������) �� (����, ����, ����ʱ��, ��������,�÷�)
���������ϵ˵����Ա��źͱ�����ŵ���Ͼ�������Ա�����������䡢����ʱ�䡢�����ص�ñ����ĵ÷����ݡ�
����������ݱ�������ڶ���ʽ,��Ϊ���ݱ��е��ֶ�֮�仹���������µĶ�Ӧ��ϵ:
(��Ա���) �� (����,����)
(�������) �� (����ʱ��, ��������)
Ҳ����˵��ѡ���е�ij���ֶξ����˷������ԡ�
�����쳣:���������Ҫ����һ���µı���,������ʱ��û��ȷ���μӵ���Ա����˭,��ô��û�����롣
ɾ���쳣:�����Ҫɾ��ij����Ա���,���û�е�������������Ļ�,�ͻ�ͬʱ�ѱ�����Ϣɾ������
�����쳣:������ǵ�����ij��������ʱ��,��ô���ݱ����������������ʱ�䶼��Ҫ���е���,����ͻ����һ������ʱ�䲻ͬ�������
3NF ������ 2NF ��ͬʱ,���κη������Զ������������ں�ѡ����Ҳ����˵���ܴ��ڷ������� A �����ڷ������� B,�������� B �����ں�ѡ�������������:
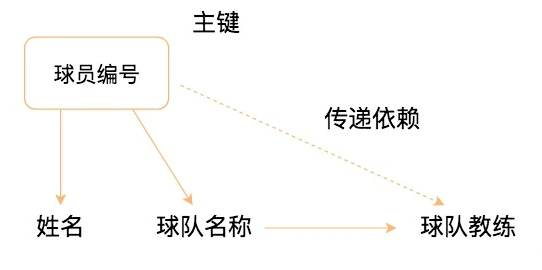
���ܿ�����Ա��ž������������,ͬʱ������ƾ��������������,������������������ͻᴫ����������Ա���,��˲����� 3NF ��Ҫ��
��������
����ģ��
Hash����
������ֻ�е�ֵ��ѯ�ij���,��Ϊ���������,��������Χ��ѯ���ٶ��Ǻ����ġ�
��������
���������ڵ�ֵ��ѯ�ͷ�Χ��ѯ�����е����ܾͶ��dz�����, ������������ֻ�����ھ�̬�洢����
����������
��ѯ���Ӷ���:O(log(N)) ,��Ҫ�����������ƽ���������Ϊ���������֤,���µ�ʱ�临�Ӷ�Ҳ�� O(log(N))���������ж���,Ҳ�����ж�档���������ÿ���ڵ��ж������,����֮��Ĵ�С��֤�����ҵ�����������������Ч����ߵ�,����ʵ���ϴ���������ݿ�洢ȴ����ʹ�ö���������ԭ����,������ֹ�����ڴ���,��Ҫд�������ϡ����������һ��һ�� 100 ��ڵ��ƽ�������,���� 20��һ�β�ѯ������Ҫ���� 20 �����ݿ顣�ڻ�еӲ��ʱ��,�Ӵ��������һ�����ݿ���Ҫ 10 ms ���ҵ�Ѱַʱ�䡣Ҳ����˵,����һ�� 100 ���еı�,���ʹ�ö��������洢,��������һ���п�����Ҫ 20 �� 10 ms ��ʱ��,�����ѯ���湻���ġ�Ϊ����һ����ѯ�����ٵض�����,�ͱ����ò�ѯ���̷��ʾ����ٵ����ݿ顣��ô,���ǾͲ�Ӧ��ʹ�ö�����,����Ҫʹ�á�N �桱��������,��N �桱���еġ�N��ȡ�������ݿ�Ĵ�С��
B����B+��
�ȿ����β�ѯ��Ϊ�˾����ܿ����������,����ϣ�������ܵĽ�������������ݴ洢���ڴ��С�b����һ���ص�,ÿһ�㶼��洢����������,��ἷѹ�������õ��ڴ�ռ�,�Ӷ�������������io����������,���ֻ����ֵ��ѯ�Ļ�,���������Dz���hash�����ġ� ���,��ϵ���ݿ��л������ʹ�÷�Χ��ѯ�������ѯ��,����ijʱ�䷶Χ�ڵ��û��������ݡ���Χ��ѯ,���ֲ�ѯ���ص��ǻ����ʹ������,�Ƚ�,���ؽ��Ҳ�����Ƕ����� ���ʹ��b���Ļ�,��Ҫʹ���������,��Ϊ���ݽڵ㲻��ͬһ����,��Ƶ������io,�Ӷ����������ٶ��½�������b+����,���е����ݽڵ㶼��Ҷ�ӽڵ�,�����Ҷ�ӽڵ�֮��Ҳ����������,��˻��Լioʱ�䡣����,b+�������Ͼͱ�b��Ҫ�졣 ��ʵ,b+����ҪӦ���ڹ�ϵ�����ݿ��С�Ҳ��ʹ��b�������������ݿ�,����mangodb��
MySQL �� InnoDB �洢���滹�и�������Ӧ Hash �������Ĺ���,���ǵ�ij������ֵʹ�÷dz�Ƶ����ʱ��,������ B+ �������Ļ������ٴ���һ�� Hash ����,������ B+ ��Ҳ�߱��� Hash �������ŵ�
�����ķ���
�����Ϸ�:��ͨ����,Ψһ����,��������,ȫ������
����������Ҷ�ӽڵ������������ݡ��� InnoDB ��,��������Ҳ����Ϊ�۴�����(clustered index)��������������Ҷ�ӽڵ�������������ֵ���� InnoDB ��,����������Ҳ����Ϊ��������(secondary index)��
ʲô�ǻر�,ʲô�Ǹ�������?(ID����������,k����ͨ����)
�������� select * from T where ID=500,��������ѯ��ʽ,��ֻ��Ҫ���� ID ��� B+ ��;
�������� select * from T where k=5,����ͨ������ѯ��ʽ,����Ҫ������ k ������,�õ� ID ��ֵΪ 500,�ٵ� ID ����������һ�Ρ�������̳�Ϊ�ر���
���ִ�е������ select ID from T where k between 3 and 5,��ʱֻ��Ҫ�� ID ��ֵ,�� ID ��ֵ�Ѿ��� k ����������,��˿���ֱ���ṩ��ѯ���,����Ҫ�ر���Ҳ����˵,�������ѯ����,���� k �Ѿ��������ˡ����ǵIJ�ѯ����,���dz�Ϊ����������
����֤���������Ψһ��ʶ��Ҳ����˵,����и�������֤�Ų�ѯ������Ϣ������,����ֻҪ������֤���ֶ��Ͻ����������ˡ����ٽ���һ��(����֤�š�����)����������,�Dz����˷ѿռ�?���������һ����Ƶ����,Ҫ�������������֤�Ų�ѯ��������,��������������������ˡ��������������Ƶ�������õ���������,������Ҫ�ر������м�¼,��������ִ��ʱ�䡣
�����ṹ��:�ۼ�����(˳��)�ͷǾۼ�����(��˳��),����������������������
�ֶ��Ϸ�:��һ��������������(����ƥ��ԭ��)
-
�ۼ�������Ҷ�ӽڵ�洢�ľ������ǵ����ݼ�¼,�Ǿۼ�������Ҷ�ӽڵ�洢��������λ�á��Ǿۼ���������Ӱ�����ݱ��������洢˳��
-
һ����ֻ����һ���ۼ�����,��Ϊֻ����һ������洢�ķ�ʽ,�������ж���Ǿۼ�����,Ҳ���Ƕ������Ŀ¼�ṩ���ݼ�����
-
ʹ�þۼ�������ʱ��,���ݵIJ�ѯЧ�ʸ�,����������ݽ��в���,ɾ��,���µȲ���,Ч�ʻ�ȷǾۼ������͡�
ʲôʱ������,ʲôʱ��Ӧ�ô�������?
��������
- �ֶ�Ψһ
- WHEREƵ����ѯ
- ����GROUP BY����ORDER BY����
- DISTINCT�ֶ�
���ʺϵ����
- Ƶ�����µ��ֶ�
- �ظ����ݱȽ϶���ֶ�
- WHERE�ò������ֶ�
InnoDB �� T,�����Ҫ�ؽ����� k,������� SQL ��������ôд:
alter table T drop index k;
alter table T add index(k);
�����Ҫ�ؽ���������,Ҳ������ôд:
alter table T drop primary key;
alter table T add primary key(id);
����,�ؽ����� k �������Ǻ�����,���Դﵽʡ�ռ��Ŀ�ġ�����,�ؽ������Ĺ��̲�������������ɾ���������Ǵ�������,���Ὣ�������ؽ�����������ִ�����������Ļ�,��һ�����Ͱ����ˡ����������,���������������� : alter table T engine=InnoDB��
����һ����Щ������Ӧ��ʹ����������,����Щ�����²�Ӧ��?
��������ÿ�β���һ���¼�¼,�����Ӳ���,�����漰��Ų��������¼,Ҳ���ᴥ��Ҷ�ӽڵ�ķ��ѡ�
����ҵ�������ֶ�������,�����������ױ�֤�������,����д���ݳɱ���Խϸߡ�
���˿���������,�����ԴӴ洢�ռ�ĽǶ�������
������ı���ȷʵ��һ��Ψһ�ֶ�,�����ַ������͵�����֤��,��Ӧ��������֤��������,�����������ֶ���������?
����ÿ��������������Ҷ�ӽڵ��϶���������ֵ�����������֤��������,��ôÿ������������Ҷ�ӽڵ�ռ��Լ 20 ���ֽ�,�����������������,��ֻҪ 4 ���ֽ�,����dz�����(bigint)���� 8 ���ֽڡ���Ȼ,��������ԽС,��ͨ������Ҷ�ӽڵ��ԽС,��ͨ����ռ�õĿռ�Ҳ��ԽС��
����,�����ܺʹ洢�ռ䷽�濼��,�������������Ǹ�������ѡ��
��û��ʲô�����ʺ���ҵ���ֶ�ֱ������������?
������͵� KV ����������û����������,����Ҳ�Ͳ��ÿ�������������Ҷ�ӽڵ��С�����⡣��ʱ�����Ǿ�Ҫ���ȿ�����һ���ᵽ�ġ�����ʹ��������ѯ��ԭ��,ֱ�ӽ������������Ϊ����,���Ա���ÿ�β�ѯ��Ҫ������������
����ǰԭ��
��������ԭ��,�ڽ�������������ʱ��,��ΰ��������ڵ��ֶ�˳��?
��Ϊ����֧������ǰ,���Ե��Ѿ����� (a,b) �������������,һ��Ͳ���Ҫ������ a �Ͻ��������ˡ����,��һԭ����,���ͨ������˳��,������ά��һ������,��ô���˳������������Ҫ���ȿ��Dz��õġ�
��ô,����������ϲ�ѯ,���л��� a��b ���ԵIJ�ѯ��?��ѯ��������ֻ�� b �����,����ʹ�� (a,b) �������������,��ʱ���㲻�ò�ά������һ������,Ҳ����˵����Ҫͬʱά�� (a,b)��(b) ��������������ʱ��,����Ҫ���ǵ�ԭ����ǿռ��ˡ����������������������,name �ֶ��DZ� age �ֶδ�� ,���Ҿͽ����㴴��һ��(name,age) ������������һ�� (age) �ĵ��ֶ�������
��������ԭ��
�����������������(name, age)Ϊ�������������һ������:���������С����ֵ�һ��������,���������� 10 ��������к�������ô,SQL �������ôд��:
select * from tuser where name like '��%' and age=10 and ismale=1;
�� MySQL 5.6 ֮ǰ,ֻ�ܴ� ID3 ��ʼһ�����ر����������������ҳ�������,�ٶԱ��ֶ�ֵ��
�� MySQL 5.6 ��������������Ż�(index condition pushdown), ��������������������,�������а������ֶ������ж�,ֱ�ӹ��˵������������ļ�¼,���ٻر�������
ʲôʱ������ʧЧ
- �����ֶ�ʹ���˱���ʽ
- ʹ�ú���
- �� WHERE �Ӿ���,����� OR ǰ�������н���������,���� OR ���������û�н�������,��ô������ʧЧ��
- ������ʹ�� LIKE ����ģ����ѯ��ʱ��,ǰ�治���� %
- ����ԭ��
���ݿ��еĴ洢�ṹ
���ݿ�����洢�ռ�Ļ�����λ��ҳ(Page),һҳ�п��Դ洢���м�¼, InnoDB��ҳ��С�鿴
show variables like '%innodb_page_size%';
�����ڷ���ռ��ʱ��ᰴ��ҳΪ��λ�����з���,ͬһ������ͬһ���ҳ��ҳ֮�����˫������,����ҳ����,��¼֮����õĵ��������ķ�ʽ��
��(Extent)�DZ�ҳ��һ���Ĵ洢�ṹ,InnoDB ��,ҳ��СĬ���� 16KB, һ��������� 64 ��������ҳ������һ�����Ĵ�С��:
64*16KB=1MB��
��(Segment)��һ�����������,�����ڶ��в�Ҫ��������֮�������ڵġ��������ݿ��еķ��䵥λ,��ͬ���͵����ݿ�����Բ�ͬ�Ķ���ʽ���ڡ������Ǵ������ݱ���������ʱ��,�ͻ���Ӧ������Ӧ�Ķ�,���紴��һ�ű�ʱ�ᴴ��һ������,����һ������ʱ�ᴴ��һ�������Ρ�
���ռ�(Tablespace)��һ��������,���ռ�洢�Ķ����Ƕ�,��һ�����ռ��п�����һ��������,����һ����ֻ������һ�����ռ䡣���ݿ���һ���������ռ����,���ռ�ӹ����Ͽ��Ի���Ϊϵͳ���ռ䡢�û����ռ䡢�������ռ䡢��ʱ���ռ�ȡ��� InnoDB �д������ֱ��ռ������:
�������ռ�Ͷ������ռ䡣
����ǹ������ռ����ζ�Ŷ��ű�����һ�����ռ䡣
����Ƕ������ռ�,����ζ��ÿ�ű���һ�������ı��ռ�,Ҳ�������ݺ�������Ϣ���ᱣ�����Լ��ı��ռ��С������ı��ռ�����ڲ�ͬ�����ݿ�֮�����Ǩ�ơ�
show variables like 'innodb_file_per_table';
�������ݿ���
-- ÿ������ض��
show variables like 'innodb_buffer_pool_size'
-- ���Կ�����������
show variables like 'innodb_buffer_pool_instances'
-- ��ȡ��ѯҳ������
SHOW STATUS LIKE 'last_query_cost';
��������
-
�� WHERE ���������,�ҵ����е�ֵν���е�������,��������Ϊ����Ƭ�еĿ�ʼ��;
-
�� GROUP BY �� ORDER BY �е��м��뵽������;
-
�� SELECT �ֶ���ʣ����м��뵽����Ƭ�С�
�������ݿ��е���
�������Ȼ���
- ����
- ����(����,MySQL 5.5������Ԫ������)
- ȫ����
��ͬ�����ݿ�ʹ洢����֧�ֵ������Ȳ�ͬ,InnoDB �� Oracle ֧�������ͱ������� MyISAM ֻ֧�ֱ���,MySQL �е� BDB �洢����֧��ҳ���ͱ�����SQL Server ����ͬʱ֧��������ҳ���ͱ�����
ȫ�����ĵ���ʹ�ó�����,��ȫ��������ݡ��ٷ��Դ��������ݹ����� mysqldump���� mysqldump ʹ�ò����Csingle-transaction ��ʱ��,������֮ǰ�ͻ�����һ������,��ȷ���õ�һ������ͼ�������� MVCC ��֧��,��������������ǿ����������µġ�single-transaction ����ֻ���������еı�ʹ����������Ŀ⡣����еı�ʹ���˲�֧�����������,��ô���ݾ�ֻ��ͨ�� FTWRL �������������� DBA Ҫ��ҵ����Աʹ�� InnoDB ��� MyISAM ��ԭ��֮һ��
Ϊʲô��ʹ�� set global readonly=true �ķ�ʽ��?��Ҫ������ԭ��:
һ��,����Щϵͳ��,readonly ��ֵ�ᱻ������������,���������ж�һ����������DZ��⡣���,�� global �����ķ�ʽӰ�������,������ʹ�á�
����,���쳣�����������в��졣���ִ�� FTWRL ����֮�����ڿͻ��˷����쳣�Ͽ�,��ô MySQL ���Զ��ͷ����ȫ����,������ص������������µ�״̬����������������Ϊ readonly ֮��,����ͻ��˷����쳣,�����ݿ�ͻ�һֱ���� readonly ״̬,�����ᵼ�������ⳤʱ�䴦�ڲ���д״̬,���սϸߡ�
�����е� MDL ��,�����ִ�п�ʼʱ����,�������������������ͷ�,����ȵ����������ύ�����ͷš�
��ô��ΰ�ȫ�ظ�С�����ֶ�?
��������Ҫ���������,�����ύ,�ͻ�һֱռ�� MDL ������ MySQL �� information_schema ��� innodb_trx ����,����Բ鵽��ǰִ���е����������Ҫ�� DDL ����ı��պ��г�������ִ��,Ҫ��������ͣ DDL,���� kill ���������������һ����������������Ҫ����ı���һ���ȵ��,��Ȼ����������,��������������Ƶ��,���㲻�ò��Ӹ��ֶ�,�����ô����?��ʱ�� kill ����δ�ع���,��Ϊ�µ��������Ͼ����ˡ��Ƚ�����Ļ�����,�� alter table ��������趨�ȴ�ʱ��,��������ָ���ĵȴ�ʱ�������ܹ��õ� MDL д�����,�ò���Ҳ��Ҫ���������ҵ�����,�ȷ�����֮����Ա���� DBA ��ͨ�����������ظ�������̡�MariaDB �Ѿ��ϲ��� AliSQL ���������,������������Դ��֧Ŀǰ��֧�� DDL NOWAIT/WAIT n ������
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
���ǻ����Դ����ݿ�����ĽǶȶ������л��֡���������������
�ӹ�����:
LOCK TABLE product_comment READ;
����:
UNLOCK TABLE;
��������
LOCK TABLE product_comment WRITE;
����
UNLOCK TABLE;
������(Intent Lock),����˵���Ǹ�����һ����Ŀռ�ʾ�������Ƿ��Ѿ��Ϲ�����
���������Ҫ������ݱ���ijЩ��¼�Ĺ�����,����Ҫ�����ݱ�����������������ͬ��,������Ҫ������ݱ���ijЩ��¼��������,����Ҫ�����ݱ���������������������ʱ,��������������������Ѿ����������˱��е�ijЩ��¼,���ܶ�����������ȫ��ɨ�衣
�ӳ���Ա�ǶȻ���
- �ֹ���:ͨ���汾�Ż���ʱ���������
- ������:�����ݱ�����������ijֱ���̬��,��ͨ�����ݿ���������������ʵ��,�Ӷ���֤���ݲ����������ԡ�
-
��������漰�����,�����Ƚϸ���,��ô���Ծ���һ���������е���Դ,������������ȡ,�������Լ������������ĸ���;
-
���������Ҫ�������ݱ��еĴ�����,���ݱ��ֱȽϴ�,��ʱ���Բ����������ķ�ʽ,���罫�м�������Ϊ������,�Ӷ��������������ĸ���;
-
��ͬ������д�������ݱ�,����Լ�����ʱ���˳��,������ͬ��˳�����������ĸ��ʡ�
��Ȼ�����ݿ���,Ҳ��һЩ����Dz��ᷢ��������,��������ֹ����ķ�ʽ�������� MySQL MyISAM �洢������Ҳ�����������,������Ϊ MyISAM ����һ���Ի��ȫ������,�����Ļ�Ҫôȫ���������ִ��,Ҫô����Ҫȫ���ȴ���
ʹ�� MySQL InnoDB �洢����ʱ,Ϊʲô��ij����������������֮ǰ,�������ݱ�������������������?
��ΪҪ�����������������ҳ�����ݱ��Ѿ������Ϲ���������,��������������Ҫ��ȡ���ݱ���������ʱ��,ֻ��Ҫ�˽��Ƿ������Ѿ���ȡ��������ݱ����������������ɡ�������Ҫ����ȫ����ɨ��,��ʡʱ��,���Ч��!
�������������
������ϵͳ�в�ͬ�̳߳���ѭ����Դ����,�漰���̶߳��ڵȴ�����߳��ͷ���Դʱ,�ͻᵼ���⼸���̶߳��������ȴ���״̬,��Ϊ������
�����������ݿ��е������ٸ����ӡ���ʱ��,���� A �ڵȴ����� B �ͷ� id=2 ������,������ B �ڵȴ����� A �ͷ� id=1 ��������
���� A ������ B �ڻ���ȴ��Է�����Դ�ͷ�,���ǽ���������״̬��
�����������Ժ�,�����ֲ���:
- һ�ֲ�����,ֱ�ӽ���ȴ�,ֱ����ʱ�������ʱʱ�����ͨ������ innodb_lock_wait_timeout �����á�
- ��һ�ֲ�����,�����������,����������,�����ع����������е�ijһ������,������������Լ���ִ�С������� innodb_deadlock_detect ����Ϊ on,��ʾ������������� InnoDB ��,innodb_lock_wait_timeout ��Ĭ��ֵ�� 50s,��ζ��������õ�һ������,�����������Ժ�,��һ������ס���߳�Ҫ�� 50s �Żᳬʱ�˳�,Ȼ�������̲߳��п��ܼ���ִ�С�
�������߷�����˵,����ȴ�ʱ�������������ܵġ�����,�����ֲ�����ֱ�Ӱ����ʱ�����ó�һ����С��ֵ,���� 1s������������������ʱ��,ȷʵ�ܿ�Ϳ��Խ,�������������,���Ǽ����ȴ���?����,��ʱʱ������̫�̵Ļ�,����ֺܶ����ˡ�
����,������������ǻ���Ҫ���õڶ��ֲ���,��:�����������,���� innodb_deadlock_detect ��Ĭ��ֵ�������� on��������������ڷ���������ʱ��,���ܹ����ٷ��ֲ����д�����,������Ҳ���ж��⸺���ġ����������һ���������:ÿ��һ����������ʱ��,��Ҫ���������������߳���û�б�������ס,���ѭ��,����ж��Ƿ������ѭ���ȴ�,Ҳ�������������������������˵������������Ҫ����ͬһ�еij�����?ÿ�������ı���ס���߳�,��Ҫ�жϻ�������Լ��ļ��뵼��������,����һ��ʱ�临�Ӷ��� O(n) �IJ����������� 1000 �������߳�Ҫͬʱ����ͬһ��,��ô�������������� 100 ����������ġ���Ȼ���ռ��Ľ����û������,�������ڼ�Ҫ���Ĵ����� CPU ��Դ�����,��ͻῴ�� CPU �����ʺܸ�,����ÿ��ȴִ�в��˼�������������ķ���,����������һ��,��ô����������ȵ��и��µ��µ�����������?�����֢������,�������Ҫ�ķѴ����� CPU ��Դ��
һ�ַ�����:
�������ȷ�����ҵ��һ�������������,������ʱ���������ص����������ֲ�����������һ���ķ���,��Ϊҵ����Ƶ�ʱ��һ�㲻�����������һ�����ش���,�Ͼ�����������,�ͻع�,Ȼ��ͨ��ҵ������һ���û������,����ҵ������ġ����ص����������ζ�ſ��ܻ���ִ����ij�ʱ,����ҵ������ġ���һ��˼·�ǿ��Ʋ����ȡ���������ķ���,��ᷢ����������ܹ�����ס,����ͬһ��ͬʱ���ֻ�� 10 ���߳��ڸ���,��ô�������ijɱ��ܵ�,�Ͳ������������⡣һ��ֱ�ӵ��뷨����,�ڿͻ������������ơ�����,���ܿ췢�����������̫����,��Ϊ�ͻ��˺ܶࡣ�Ҽ���һ��Ӧ��,�� 600 ���ͻ���,������ʹÿ���ͻ��˿��Ƶ�ֻ�� 5 �������߳�,���ܵ����ݿ������Ժ�,��ֵ������Ҳ����Ҫ�ﵽ 3000�����,�����������Ҫ�������ݿ����ˡ���������м��,���Կ������м��ʵ��;�������Ŷ������� MySQL Դ�����,Ҳ�������� MySQL ���档����˼·����,������ͬ�еĸ���,�ڽ�������֮ǰ�Ŷӡ������� InnoDB �ڲ��Ͳ����д��������������ˡ�
��һ�ַ�����:
����Կ���ͨ����һ�иij����ϵĶ�������������ͻ��������ӰԺ�˻�Ϊ��,���Կ��Ƿ��ڶ�����¼��,���� 10 ����¼,ӰԺ���˻��ܶ������ 10 ����¼��ֵ���ܺ͡�����ÿ��Ҫ��ӰԺ�˻��ӽ���ʱ��,���ѡ����һ����¼���ӡ�����ÿ�γ�ͻ���ʱ��ԭ���� 1/10,���Լ������ȴ�����,Ҳ�ͼ������������� CPU ���ġ������������ȥ�������,����ʵ�������Ҫ����ҵ��������ϸ��ơ�����˻������ܻ����,������Ʊ��,��ô��ʱ�����Ҫ���ǵ�һ�����м�¼��� 0 ��ʱ��,����Ҫ���������
��ȫɾ��ǰ10000������
�����Ҫɾ��һ���������ǰ 10000 ������,���������ַ�����������:
��һ��,ֱ��ִ�� delete from T limit 10000;
������Խϳ�,��ռ������ʱ��ϳ�,�ᵼ�������ͻ��˵ȴ���Դʱ��ϳ���
�ڶ���,��һ��������ѭ��ִ�� 20 �� delete from T limit 500;
���л�ִ��,����Գ�������ֳɶ����Զ̵�����,��ÿ������ռ������ʱ����Խ϶�,�����ͻ����ڵȴ���Ӧ��Դ��ʱ��Ҳ�϶̡������IJ���,ͬʱҲ��ζ�Ž���Դ��Ƭʹ��(ÿ��ִ��ʹ�ò�ͬƬ�ε���Դ),������߲����ԡ�
������,�� 20 ��������ͬʱִ�� delete from T limit 500��
��Ϊ�Լ�����������,�Ӿ粢������
��������ĸ���
��������
CBO VS RBO
��һ���ǻ��ڹ�����Ż���(RBO,Rule-Based Optimizer),����������������ľ���,�����Dz����Ѿ���֤������Ч�ķ�ʽ��ͨ�����Ż�������Ƕ�����,���ж� SQL ��ѯ�������ֹ���,�Ͱ�����Ӧ�Ĺ������ƶ�ִ�мƻ�,ͬʱ��������ʽ����ȥ�����Բ��õĴ�ȡ·����
�ڶ����ǻ��ڴ��۵��Ż���(CBO,Cost-Based Optimizer),�������ݴ�������ģ��,����ÿ�����ܵ�ִ�мƻ��Ĵ���,Ҳ���� COST,����ѡ�������С����Ϊִ�мƻ�������� RBO ��˵,CBO �����ݸ�����,��Ϊ�����������ݱ��е�ͳ����Ϣ�����ж�,��Բ�ͬ�����ݱ�,��ѯ�õ���ִ�мƻ������Dz�ͬ��,����ƶ�������ִ�мƻ�Ҳ���������ݱ���ʵ�������
��������Ҫ��ס,SQL �����ϵ�����,��û��ָ��ִ�еķ�ʽ,������Ż����л���ڸ�����ϵĿ��ܡ�������Ҫͨ���Ż������ƶ����ݱ���ɨ�跽ʽ�����ӷ�ʽ�Լ�����˳��,�Ӷ��õ���ѵ� SQL ִ�мƻ���
���ܿ�����,RBO �ķ�ʽ������һ�������˾��,ƾ���Լ��ľ�����ѡ��� A �� B ��·������ CBO �������ֻ�����,ͨ����������,��ѡ����ѵ�ִ��·����
5.7.10 �汾֮��,MySQL �������������ݱ�,����涨�˸��ֲ���Ԥ���Ĵ���(Cost Value) ,���ǿ��Դ�mysql.server_cost��mysql.engine_cost�����ű��л����Щ����Ĵ���
���SQL����
- mysqldumpslow
- EXPLAIN �鿴ִ�мƻ�
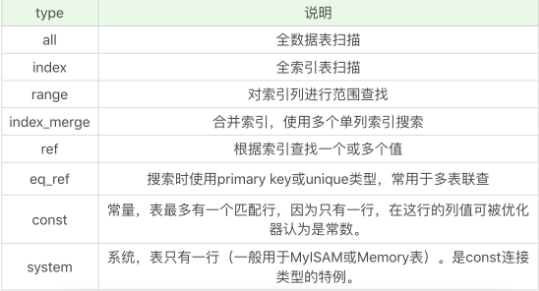
- SHOW PROFILE �鿴����
��β鿴ִ�мƻ�
����ͬ��ԭ��
�ᵽ����ͬ����ԭ��,���Ǿ���Ҫ�˽������ݿ��е�һ����Ҫ��־�ļ�,�Ǿ��� Binlog ��������־,����¼�˶����ݿ���и��µ��¼���ʵ��������ͬ����ԭ�����ǻ��� Binlog ��������ͬ���ġ�
�����Ӹ��ƹ�����,����� 3 ���߳�������,һ�������߳�,�����ӿ��̡߳���������־ת���߳�(Binlog dump thread)��һ�������̡߳����ӿ��߳����ӵ�ʱ��,������Խ���������־�����ӿ�,�������ȡ�¼���ʱ��,���� Binlog �ϼ���,��ȡ���֮��,�ٽ����ͷŵ����ӿ� I/O �̻߳����ӵ�����,�����ⷢ��������� Binlog����ʱ�ӿ�� I/O �߳̾Ϳ��Զ�ȡ������Ķ�������־ת���̷߳��͵� Binlog ���²���,���ҿ����������γ��м���־(Relay log)���ӿ� SQL �̻߳��ȡ�ӿ��е��м���־,����ִ����־�е��¼�,�Ӷ����ӿ��е����������Ᵽ��ͬ����
��ν�����Ӳ�һ������
- �첽����
- ��ͬ������
MySQL5.5 �汾֮��ʼ֧�ְ�ͬ�����Ƶķ�ʽ��ԭ�����ڿͻ����ύ COMMIT ֮��ֱ�ӽ�������ظ��ͻ���,���ǵȴ�������һ���ӿ���յ��� Binlog,����д�뵽�м���־��,�ٷ��ظ��ͻ��ˡ��������ĺô�������������ݵ�һ����,��Ȼ������첽������˵,���ٶ�������һ���������ӵ��ӳ�,����������д��Ч�ʡ��� MySQL5.7 �汾�л�������һ��rpl_semi_sync_master_wait_for_slave_count����,���ǿ��Զ�Ӧ��Ĵӿ�������������,Ĭ��Ϊ 1,Ҳ����˵ֻҪ�� 1 ���ӿ��������Ӧ,�Ϳ��Է��ظ��ͻ��ˡ�����������������,������������һ���Ե�ǿ��,��Ҳ����������ȴ��ӿ���Ӧ��ʱ�䡣
- �鸴��(MySQL 5.7.17 �Ժ� ,����Paxos)
MySQL�ı�����ָ�
��ʽ1:
innodb_force_recovery
��ʽ2: