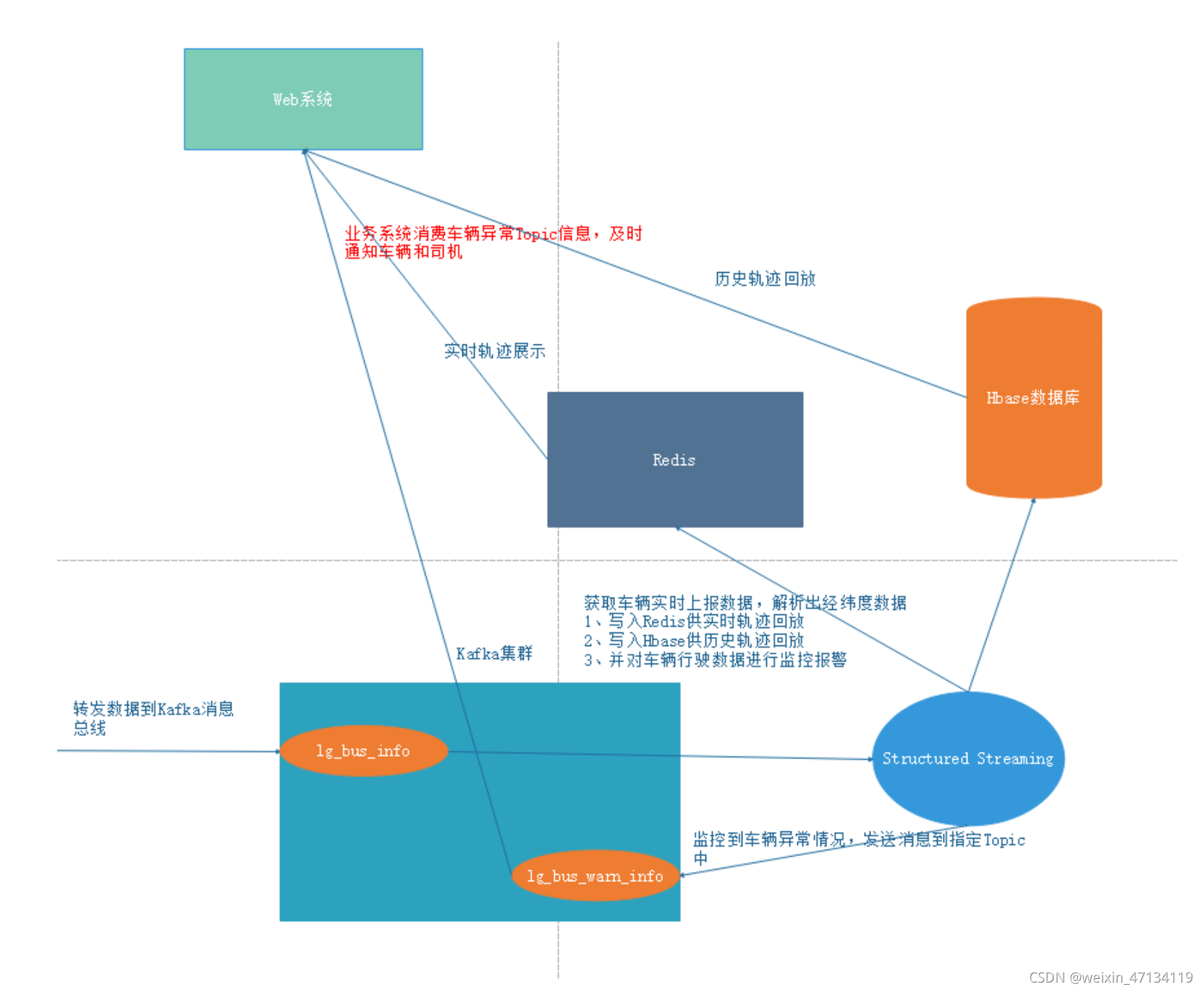
车辆监控
文章目录
第一节 Structured Streaming
1.1 Structured Streaming发展历史
1.1.1 Spark Streaming

spark streaming这种构建在微批处理上的流计算引擎,比较突出的问题就是处理延时较高(无法优化到秒以下的数量级),以及无法支持基于event_time的时间窗口做聚合逻辑。
在这段时间,流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年google发表了TheDataflow Model的论文。
https://yq.aliyun.com/articles/73255
1.1.2 Dataflow模型
1、核心思想
对无边界,无序的数据源,允许按数据本身的特征进行窗口计算,得到基于事件发生时间的有序结果,并能在准确性、延迟程度和处理成本之间调整。
2、四个维度
抽象出四个相关的维度,通过灵活地组合来构建数据处理管道,以应对数据处理过程中的各种复杂的场景
what 需要计算什么
where 需要基于什么时间(事件发生时间)窗口做计算
when 在什么时间(系统处理时间)真正地触发计算
how 如何修正之前的计算结果
论文的大部分内容都是在说明如何通过这四个维度来应对各种数据处理场景。
3、相关概念
在现实场景中,从一个事件产生,到它被数据分析系统收集到,要经过非常复杂的链路,这本身就会存在一定的延时,还会因为一些特殊的情况加剧这种情况。比如基于移动端APP的用户行为数据,会因为手机信号较差、没有wifi等情况导致无法及时发送到服务端系统。面对这种时间上的偏移,数据处理模型如果只考虑处理时间,势必会降低最终结果的正确性。
-
事件时间和处理时间
event_time,事件的实际发生时间
process_time,处理时间,是指一个事件被数据处理系统观察/接收到的时间 -
窗口
除了一些无状态的计算逻辑(如过滤,映射等),经常需要把无边界的数据集切分成有限的数据片以便于后续聚合处理(比如统计最近5分钟的XX等),窗口就应用于这类逻辑中,常见的窗口包括:
sliding window,滑动窗口,除了窗口大小,还需要一个滑动周期,比如小时窗口,每5分钟滑动一次。
fixed window,固定窗口,按固定的窗口大小定义,比如每小时、天的统计逻辑。固定窗口可以看做是滑动窗口的特例,即窗口大小和滑动周期相等。
sessions,会话窗口,以某一事件作为窗口起始,通常以时间定义窗口大小(也有可能是事件次数),发生在超时时间以内的事件都属于同一会话,比如统计用户启动APP之后一段时间的浏览信息等。 -
总结
论文中远不止这些内容,还有很多编程模型的说明和举例,感兴趣的同学可以自行阅读。
https://yq.aliyun.com/articles/73255
除了论文,google还开源了Apache Beam项目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。国内使用的更多的是后面要学习的Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink收购了
1.2 Structured Streaming
1.2.1 介绍
官网地址
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
也许是对Dataflow模型的借鉴,也许是英雄所见略同,spark在2.0版本中发布了新的流计算的API,Structured Streaming/结构化流。
- Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,你可以使用静态数据批处理一样的方式来编写流式计算操作。并且支持基于event_time的时间窗口的处理逻辑。
- Structured Streaming会以一种增量的方式来执行这些操作,并且持续更新结算结果。
- 可以使用Scala、Java、Python或R中的DataSet/DataFrame API来表示流聚合、事件时间窗口、流到批连接等。
- Structured Streaming会通过checkpoint和预写日志等机制来实现Exactly-Once语义。
简单来说,对于开发人员来说,根本不用去考虑是流式计算,还是批处理,只要使用同样的方式来编写计算操作即可,Structured Streaming提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑更多细节
1.2.2 API
1.Spark Streaming 时代 -DStream-RDD
Spark Streaming 采用的数据抽象是DStream,而本质上就是时间上连续的RDD,对数据流的操作就是针对RDD的操作

2.Structured Streaming 时代 - DataSet/DataFrame -RDD
Structured Streaming是Spark2.0新增的可扩展和高容错性的实时计算框架,它构建于Spark SQL引擎,把流式计算也统一到DataFrame/Dataset里去了。
Structured Streaming 相比于 Spark Streaming 的进步就类似于 Dataset 相比于 RDD 的进步

1.2.3 编程模型
● 编程模型概述
一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾。
- 用户可以使用 Dataset/DataFrame 函数式API或者 SQL 来对这个动态数据源进行实时查询。每次查询在逻辑上就是对当前的表格内容执行一次 SQL 查询。
- 什么时候执行查询则是由用户通过触发器(Trigger)来设定时间(毫秒级)。用户既可以设定执行周期让查询尽可能快地执行,从而达到实时的效果也可以使用默认的触发。
一个流的输出有多种模式,
- 可以是基于整个输入执行查询后的完整结果,complete
- 也可以选择只输出与上次查询相比的差异,update
- 或者就是简单地追加最新的结果。append
这个模型对于熟悉 SQL 的用户来说很容易掌握,对流的查询跟查询一个表格几乎完全一样,十分简洁,易于理解
● 核心思想

Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.这样用户就可以用静态结构化数据的批处理查询方式进行流计算,如可以使用SQL对到来的每一行数据进行实时查询处理;
●应用场景
Structured Streaming将数据源映射为类似于关系数据库中的表,然后将经过计算得到的结果映射为另一张表,完全以结构化的方式去操作流式数据,这种编程模型非常有利于处理分析结构化的实时数据;
●WordCount图解
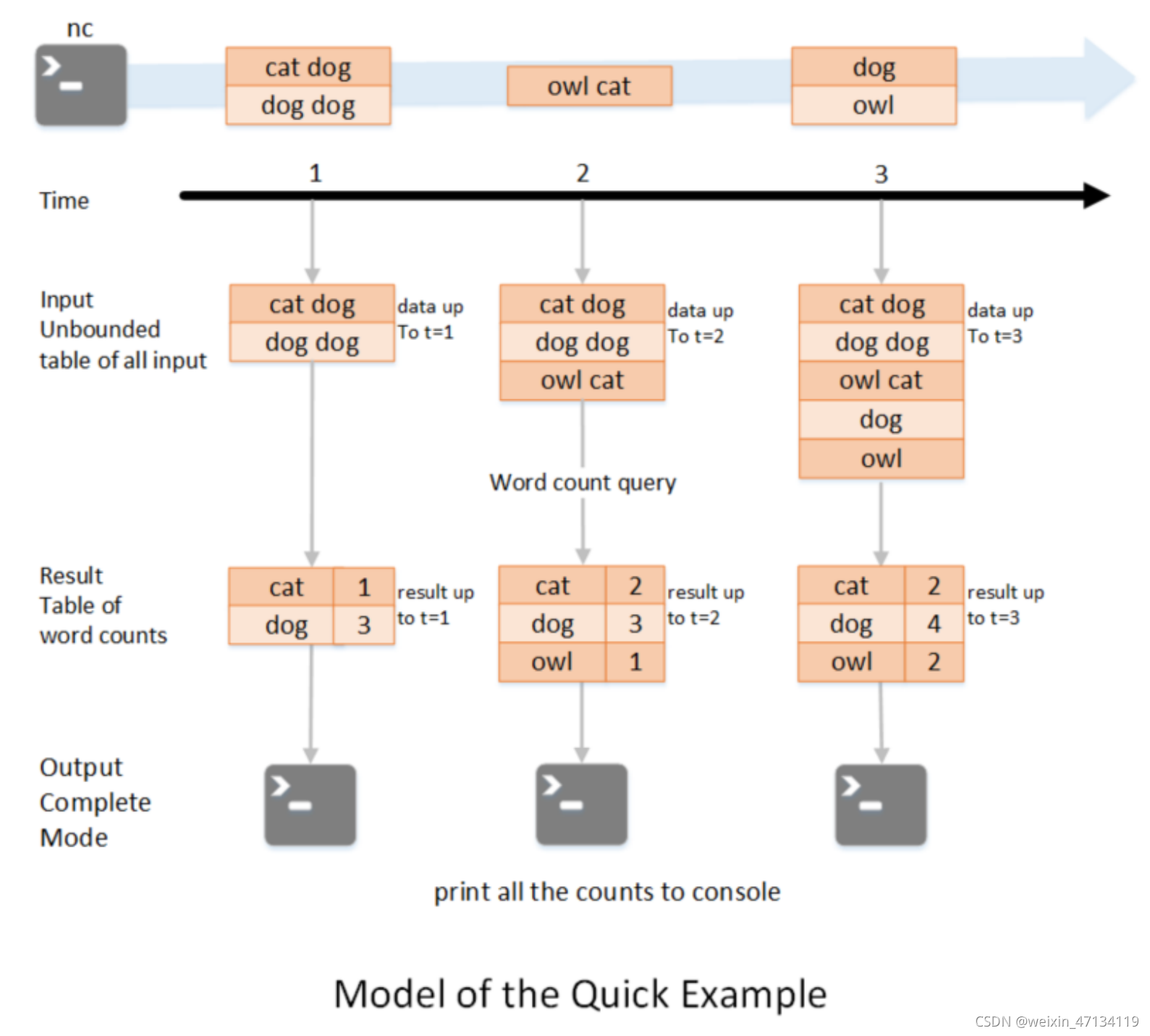
如图所示,
第一行表示从socket不断接收数据,
第二行是时间轴,表示每隔1秒进行一次数据处理,
第三行可以看成是之前提到的“unbound table",
第四行为最终的wordCounts是结果集。
当有新的数据到达时,Spark会执行“增量"查询,并更新结果集;
该示例设置为Complete Mode,因此每次都将所有数据输出到控制台;
1.在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此我们可以得到第1秒时的结果集cat=1=dog=3,并输出到控制台;
2.当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执行wordcount查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
3.当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和"owl",执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;
1.3 Structured Streaming
1.3.1 Source
Socket source (for testing): 从socket连接中读取文本内容。
Kafka source: 从Kafka中拉取数据,与0.10或以上的版本兼容,后面单独整合Kafka
- Socket
导入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lagou</groupId>
<artifactId>bus_monitor1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 指定仓库位置,依次为aliyun、cloudera-->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<spark.version>2.4.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- bind to the packaging phase -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建scala.object
package com.lg.test
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 使用结构化流实现从socket读取数据实现单词统计
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1 获取sparksession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName(WordCount.getClass.getName).getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2 接收socket数据
val df: DataFrame = spark.readStream
.option("host", "linux121")
.option("port", 9999)
.format("socket")
.load()
//3 处理数据,接收一行数据,按照空格进行切分
//转为ds
import spark.implicits._
val ds: Dataset[String] = df.as[String]
val wordDs: Dataset[String] = ds.flatMap(_.split(" "))
//4 使用dsl风格语句执行聚合统计
val res: Dataset[Row] = wordDs.groupBy("value").count().sort($"count".desc)
//输出
res.writeStream.format("console") //输出到控制台
.outputMode("complete") //指定输出模式,全部数据的计算结果
.trigger(Trigger.ProcessingTime(0)) //0尽可能快的触发
.start() //启动
.awaitTermination()
}
}
运行程序
yum install -y nc
nc -lk 9999

1.3.2 计算
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述官网示例代码
case class DeviceData(device: String, deviceType: String, signal: Double, time:DateTime)
val df: DataFrame = ...
val ds: Dataset[DeviceData] = df.as[DeviceData]
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
1.3.3 输出
计算结果可以选择输出到多种设备并进行如下设定
1.output mode:以哪种方式将result table的数据写入sink
2.format/output sink的一些细节:数据格式、位置等。
3.query name:指定查询的标识。类似tempview的名字
4.trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据
5.checkpoint地址:一般是hdfs上的目录。注意:Socket不支持数据恢复,如果设置了,第二次启动会报错 ,Kafka支持
1、output mode

每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
这里有三种输出模型:
1.Append mode:默认模式,新增的行才输出,每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。
例如,仅查询select,where,map,flatMap,filter,join等会支持追加模式。不支持聚合
2.Complete mode: 所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
3.**Update mode:**更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自Spark2.1.1起可用),不支持排序
2、output sink
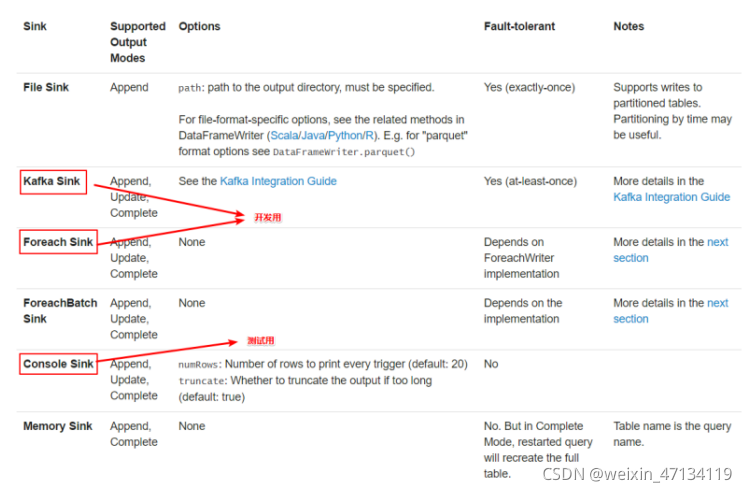
File sink - Stores the output to a directory.支持parquet文件,以及append模式
writeStream .format("parquet") **// can be "orc", "json", "csv", etc.**
.option("path", "path/to/destination/dir")
.start()
Kafka sink - Stores the output to one or more topics in Kafka.
writeStream .format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
writeStream .foreach(...) .start()
Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
writeStream .format("console") .start()
Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both,Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
writeStream .format("memory") .queryName("tableName") .start()
●官网示例代码
// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF
.writeStream
.format("console")
.start()
// Write new data to Parquet files
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // interactively query in-memorytable
1.4 Structured Streaming整合Kafka
1.4.1 官网介绍
http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
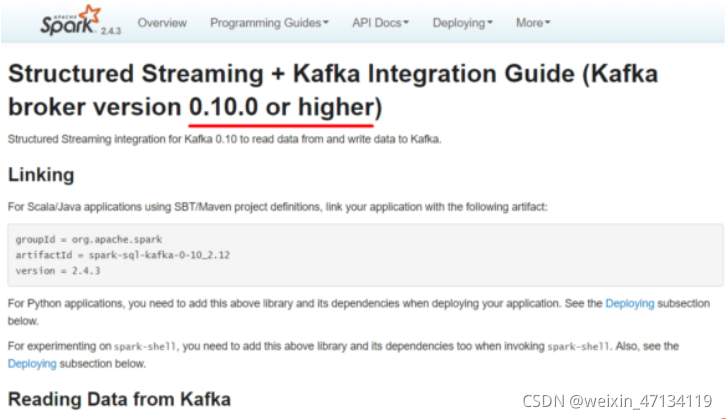
●Creating a Kafka Source for Streaming Queries
// Subscribe to 1 topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
// Subscribe to a pattern
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
●Creating a Kafka Source for Batch Queries
// Subscribe to 1 topic defaults to the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics, specifying explicit Kafka offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""")
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern, at the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
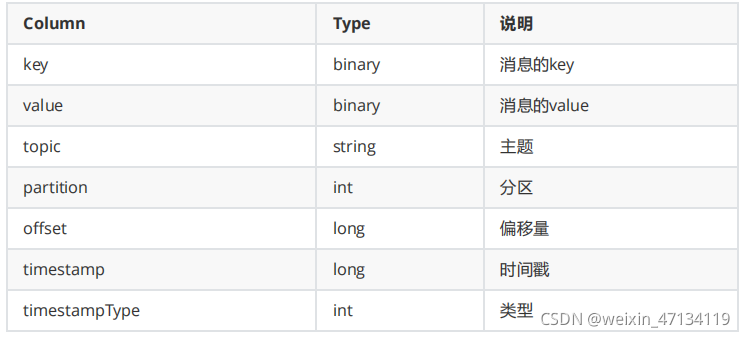
●注意:读取后的数据的Schema是固定的,包含的列如下:
●注意:下面的参数是不能被设置的,否则kafka会抛出异常:
- group.id:kafka的source会在每次query的时候自定创建唯一的group id
- auto.offset.reset :为了避免每次手动设置startingoffsets的值,structured streaming在内部消费时会自动管理offset。这样就能保证订阅动态的topic时不会丢失数据。startingOffsets在流处理时,只会作用于第一次启动时,之后的处理都会自动的读取保存的offset。
- key.deserializer,value.deserializer,key.serializer,value.serializer 序列化与反序列化,都是ByteArraySerializer
- enable.auto.commit:Kafka源不支持提交任何偏移量

1.4.2 准备工作
启动kafka
新建一个spark_kafka主题

向topic中生产数据
[root@linux122 ~]# kafka-console-producer.sh --broker-list linux122:9092 --topic spark_kafka
[root@linux122 ~]# kafka-console-consumer.sh --bootstrap-server linux122:9092 --topic spark_kafka --from-beginning


代码实现
package com.lg.test
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 使用结构化流读取kafka中的数据
*/
object StructuredKafka {
def main(args: Array[String]): Unit = {
//1 获取sparksession
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName(StructuredKafka.getClass.getName)
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
//2 定义读取kafka数据源
val kafkaDf: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "linux122:9092")
.option("subscribe", "spark_kafka")
.load()
//3 处理数据
val kafkaValDf: DataFrame = kafkaDf.selectExpr("CAST(value AS STRING)")
//转为ds
val kafkaDs: Dataset[String] = kafkaValDf.as[String]
val kafkaWordDs: Dataset[String] = kafkaDs.flatMap(_.split(" "))
//执行聚合
val res: Dataset[Row] =
kafkaWordDs.groupBy("value").count().sort($"count".desc)
//4 输出
res.writeStream
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
}
}


第二节 轨迹数据处理
使用结构化流消费kafka中数据,解析经纬度数据,分别写入Redis支持实时轨迹查询,写入Hbase中支持历史轨迹回放。
2.1 安装Redis
1、下载redis安装包
#linux123服务器执行以下命令下载redis安装包
mkdir -p /opt/lagou/softwares
mkdir -p /opt/lagou/servers
cd /opt/lagou/softwares
wget http://download.redis.io/releases/redis-3.2.8.tar.gz
2、解压redis压缩包
cd /opt/lagou/softwares
tar -zxvf redis-3.2.8.tar.gz -C ../servers/
3、安装运行环境
yum -y install gcc-c++
yum -y install tcl
4、编译安装
cd /opt/lagou/servers/redis-3.2.8/
yum reinstall binutils -y
make MALLOC=libc
make && make install
5、修改redis配置文件
修改redis配置文件
cd /opt/lagou/servers/redis-3.2.8/
mkdir -p /opt/lagou/servers/redis-3.2.8/logs
mkdir -p /opt/lagou/servers/redis-3.2.8/redisdata
vim redis.conf
bind linux123
daemonize yes
pidfile /var/run/redis_6379.pid
logfile "/opt/lagou/servers/redis-3.2.8/logs/redis.log"
dir /opt/lagou/servers/redis-3.2.8/redisdata
6、启动redis
#启动redis
cd /opt/lagou/servers/redis-3.2.8/src
redis-server ../redis.conf
注:之前安装过,启动如下
[root@linux121 ~]# cd /usr/redis/bin
[root@linux121 bin]# ./redis-server redis.conf
7、连接redis客户端
cd /opt/lagou/servers/redis-3.2.8/src
redis-cli -h linux121
2.2 轨迹数据写入Redis
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
RedisWriter
package com.lg.monitor
import com.lg.bean.BusInfo
import org.apache.spark.sql.ForeachWriter
import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
object RedisWriter {
private val config = new JedisPoolConfig
//设置最大连接
config.setMaxTotal(20)
//设置空闲连接
config.setMaxIdle(10)
private val jedisPool = new JedisPool(config, "linux121", 6379, 1000)
//从连接池中获取jedis对象
def getConnection = {
jedisPool.getResource
}
}
/**
* 写入redis的writer
*/
class RedisWriter extends ForeachWriter[BusInfo] {
var jedis: Jedis = _
//开启连接
override def open(partitionId: Long, epochId: Long): Boolean = {
jedis = RedisWriter.getConnection
true
}
//处理数据
override def process(value: BusInfo): Unit = {
//把数据写入redis ,kv形式
val lglat: String = value.lglat //经度
val deployNum = value.deployNum //纬度
jedis.set(deployNum, lglat)
}
//释放连接
override def close(errorOrNull: Throwable): Unit = {
jedis.close()
}
}
BusInfo
package com.lg.bean
//接收各个字段
case class BusInfo(
deployNum: String,
simNum: String,
transportNum: String,
plateNum: String,
lglat: String,
speed: String,
direction: String,
mileage: String,
timeStr: String,
oilRemain: String,
weights: String,
acc: String,
locate: String,
oilWay: String,
electric: String
)
object BusInfo {
def apply(msg:String): BusInfo = {
//获取一条消息,按照逗号切分,准备各个字段数据然后获取businfo对象
val arr: Array[String] = msg.split(",")
BusInfo(
arr(0),
arr(1),
arr(2),
arr(3),
arr(4),
arr(5),
arr(6),
arr(7),
arr(8),
arr(9),
arr(10),
arr(11),
arr(12),
arr(13),
arr(14)
)
}
}
RealTimeProcess
package com.lg.monitor
import com.lg.bean.BusInfo
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 使用结构化流读取kafka中的数据
*/
object RealTimeProcess {
def main(args: Array[String]): Unit = {
//1 获取sparksession
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName(RealTimeProcess.getClass.getName)
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
//2 定义读取kafka数据源
val kafkaDf: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "linux122:9092,linux123:9092")
.option("subscribe", "lg_bus_info")
.load()
//3 处理数据
val kafkaValDf: DataFrame = kafkaDf.selectExpr("CAST(value AS STRING)")
//转为ds
val kafkaDs: Dataset[String] = kafkaValDf.as[String]
//解析出经纬度数据,写入redis
//封装为一个case class方便后续获取指定字段的数据
val busInfoDs: Dataset[BusInfo] = kafkaDs.map(BusInfo(_)).filter(_ != null)
//把经纬度数据写入redis
busInfoDs.writeStream
.foreach(new RedisWriter)
.outputMode("append")
.start()
.awaitTermination()
}
}
测试发送数据DataClient
package com.lg.collect;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class DataClient {
//调配编号
static String[] deployArr = {"316d5c75-e860-4cc9-a7de-ea2148c244a0",
"32102c12-6a73-4e03-80ab-96175a8ee686",
"a97f6c0d-9086-4c68-9d24-8a7e89f39e5a",
"adfgfdewr-5463243546-4c68-9d24-8a7e8",
};
//sim卡号
static String[] simArr = {"1111", "2222", "3333", "4444"};
//道路运输证
static String[] transpotNumArr = {"ysz11111", "ysz22222","ysz333333","ysz44444"};
//车牌号
static String[] plateNumArr = {"京A-11111", "京A-22222", "京A-33333", "京A-44444"};
//时间static
static String[] timeStrArr = {"1594076827", "1594076527", "1594076327"};
//经纬度
static String[] lglatArr = {"116.437355_39.989739",
"116.382306_39.960325",
"116.623784_40.034688",
"116.32139_39.81157",
"116.45551_39.944381",};
//速度
static String[] speedArr = {"50", "60", "70", "80"};
//方向
static String[] directionArr = {"west", "east", "south", "north"};
//里程
static String[] mileageArr = {"6000", "7000", "8000", "9000"};
//剩余油量
static String[] oilRemainArr = {"20", "30", "70", "80"};
//载重质量
static String[] weightsArr = {"500", "1000", "2000", "3000"};
//ACC开关
static String[] accArr = {"0", "1"};
//是否定位
static String[] locateArr = {"0", "1"};
//车辆油路是否正常
static String[] oilWayArr = {"0", "1"};
//车辆电路是否正常
static String[] electricArr = {"0", "1"};
/**
* @param url
* @param msg
* @return
*/
public static String httpPost(String url, String msg) {
String returnValue = "这是默认返回值,接口调用失败";
CloseableHttpClient httpClient = HttpClients.createDefault();
ResponseHandler<String> responseHandler = new BasicResponseHandler();
try {
//第一步:创建HttpClient对象
httpClient = HttpClients.createDefault();
//第二步:创建httpPost对象
HttpPost httpPost = new HttpPost(url);
//第三步:给httpPost设置JSON格式的参数
StringEntity requestEntity = new StringEntity(msg, "utf-8");
requestEntity.setContentEncoding("UTF-8");
httpPost.setEntity(requestEntity);
//第四步:发送HttpPost请求,获取返回值
httpClient.execute(httpPost, responseHandler);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpClient.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//第五步:处理返回值
return returnValue;
}
public static void main(String[] args) throws InterruptedException {
String url = "http://linux123/log/lg_bus_info";
int n = 100;
final Random rd = new Random();
while (n > 0) {
//拼接信息
final StringBuilder sb = new StringBuilder();
sb.append(deployArr[rd.nextInt(deployArr.length)]).append(",");
sb.append(simArr[rd.nextInt(simArr.length)]).append(",");
sb.append(transpotNumArr[rd.nextInt(transpotNumArr.length)]).append(",");
sb.append(plateNumArr[rd.nextInt(plateNumArr.length)]).append(",");
sb.append(lglatArr[rd.nextInt(lglatArr.length)]).append(",");
sb.append(speedArr[rd.nextInt(speedArr.length)]).append(",");
sb.append(directionArr[rd.nextInt(directionArr.length)]).append(",");
sb.append(mileageArr[rd.nextInt(mileageArr.length)]).append(",");
sb.append(timeStrArr[rd.nextInt(timeStrArr.length)]).append(",");
sb.append(oilRemainArr[rd.nextInt(oilRemainArr.length)]).append(",");
sb.append(weightsArr[rd.nextInt(weightsArr.length)]).append(",");
sb.append(accArr[rd.nextInt(accArr.length)]).append(",");
sb.append(locateArr[rd.nextInt(locateArr.length)]).append(",");
sb.append(oilWayArr[rd.nextInt(oilWayArr.length)]).append(",");
sb.append(electricArr[rd.nextInt(electricArr.length)]);
httpPost(url, sb.toString());
TimeUnit.SECONDS.sleep(1);
n--;
}
}
}
使用DataClient发送数据到Kafka,启动RealTimeProcess
[root@linux121 bin]# redis-cli -h linux121
linux121:6379> keys *
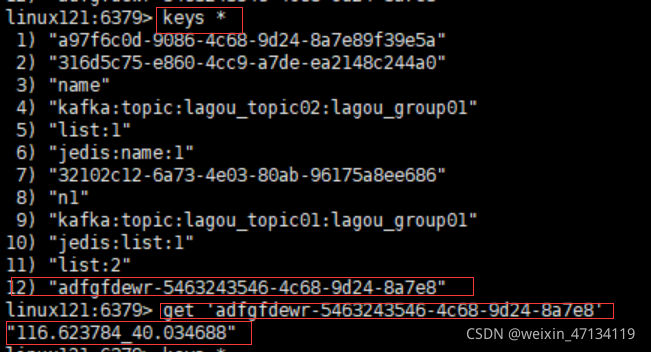
116.623784_40.034688就是经纬度数据
2.3 轨迹数据写入Hbase
创建表
create 'htb_gps','car_info'
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
HbaseWriter
package com.lg.monitor
import com.lg.bean.BusInfo
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Put, Table}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.ForeachWriter
object HbaseWriter {
//hbase中的connection本身底层已经使用了线程池,而且connection是线程安全的,可以全局使用一个,
//但是对admin,table需要每个线程使用一个
def getHtable(): Table = {
//获取连接
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("hbase.zookeeper.quorum", "linux122,linux123")
val conn: Connection = ConnectionFactory.createConnection(conf)
//hbase表名:htb_gps
val table: Table = conn.getTable(TableName.valueOf("htb_gps"))
table
}
}
class HbaseWriter extends ForeachWriter[BusInfo] {
var table: Table = _
override def open(partitionId: Long, epochId: Long): Boolean = {
table = HbaseWriter.getHtable()
true
}
override def process(value: BusInfo): Unit = {
//rowkey:调度编号+车牌号+时间戳
var rowkey = value.deployNum + value.plateNum + value.timeStr
val put = new Put(Bytes.toBytes(rowkey))
val arr: Array[String] = value.lglat.split("_")
//经度
put.addColumn(
Bytes.toBytes("car_info"),
Bytes.toBytes("lng"),
Bytes.toBytes(arr(0))
)
//维度
put.addColumn(
Bytes.toBytes("car_info"),
Bytes.toBytes("lat"),
Bytes.toBytes(arr(1))
)
table.put(put)
}
override def close(errorOrNull: Throwable): Unit = {
table.close()
}
}
改造RealTimeProcess 将经纬度数据写入hbase中

//把经纬度数据写入Hbase中
busInfoDs.writeStream
.foreach(new HbaseWriter)
.outputMode("append")
.start()
.awaitTermination()
启动hbase
start-hbase.sh
运行RealTimeProcess,然后运行DataClient发送数据

2.4 轨迹数据写入Mysql
创建表
DROP TABLE IF EXISTS `htb_gps`;
CREATE TABLE `htb_gps` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`lglat` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`deployNum` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 57 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
xml,加载jdbc驱动
<!--mysql驱动依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
MysqlWriter
package com.lg.monitor
import java.sql.{Connection, DriverManager, PreparedStatement}
import com.lg.bean.BusInfo
import org.apache.spark.sql.ForeachWriter
class MysqlWriter(url: String, username: String, password: String) extends ForeachWriter[BusInfo] with Serializable {
// 准备连接对象
var connection: Connection = _ // 设置sql
var preparedStatement: PreparedStatement = _ // 用于打开数据库连接
override def open(partitionId: Long, version: Long): Boolean = {
// 获取链接
connection = DriverManager.getConnection(url, username, password)
//获取链接无误返回True
true
}
// 用于更新/插入数据到mysql
override def process(value: BusInfo): Unit = {
val lglat: String = value.lglat //经度
val deployNum = value.deployNum //纬度
println("lglat:" + lglat + "\tdeployNum:" + deployNum)
//REPLACE INTO:表示如果表中没有数据这插入,如果有数据则替换
//注意:REPLACE INTO要求表有主键或唯一索引
val sql = "REPLACE INTO `htb_gps` ( `lglat`, `deployNum`) VALUES ( ?, ?)"
// val sql = "INSERT INTO t_word (id, word, count) VALUES (null,?,?) ON DUPLICATE KEY UPDATE count = ?"
val prepareStatement: PreparedStatement = connection.prepareStatement(sql)
// 设置字段
prepareStatement.setString(1, lglat)
prepareStatement.setString(2, deployNum)
//prepareStatement.setInt(3, count)
// 执行
prepareStatement.executeUpdate()
}
// 关闭数据库连接
override def close(errorOrNull: Throwable): Unit = {
if (connection != null) {
connection.close()
}
if (preparedStatement != null) {
preparedStatement.close()
}
}
}
改造RealTimeProcess 将经纬度数据写入mysql中

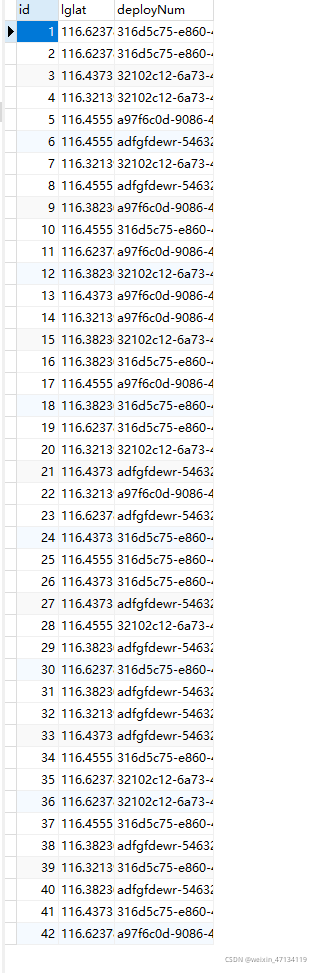
运行RealTimeProcess,然后运行DataClient发送数据,结果如下

MySQL表中写入了如下数据
第三节 异常检测
监听剩余油量小于百分之三十的运输车辆
写入Kafka
RealTimeProcess添加如下代码

//实现对车辆异常情况的监测
val warnInfoDs = busInfoDs.filter(
info => {
val remain: String = info.oilRemain
remain.toInt < 30 //剩余油量小于30%
}
)
//写入到kafka另外一个主题,由web系统监听,然后推送警告信息到车载客户单
//写出的ds/df中必须有一个列名叫做value
warnInfoDs
.withColumn("value", new Column("deployNum"))
.writeStream
.format("kafka")
.option("checkpointLocation", "./ck") //ck目录一般选择是hdfs目录
.option("kafka.bootstrap.servers", "linux122:9092,linux123:9092")
.option("topic", "lg_bus_warn_info")
.start()
.awaitTermination()
启动RealTimeProcess ,DataClient发送数据
[root@linux123 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic lg_bus_warn_info --from-beginning

写入hdfs
将上面./ck路径换为hdfs路径 hdfs://lgns/realtime ,报错如下

添加用户权限
System.setProperty("HADOOP_USER_NAME", "root")
需要导入hdfs-site.xml文件
hdfs-stie.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>dfs.namenode.hosts.provider.classname</name>
<value>org.apache.hadoop.hdfs.server.blockmanagement.CombinedHostFileManager</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.fencing.cloudera_manager.timeout_millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.ha.fencing.cloudera_manager_agent.url.namenode31</name>
<value>http://linux122:9000/fence/fence?name=hdfs-NAMENODE&host=linux122&port=8020</value>
</property>
<property>
<name>dfs.ha.fencing.cloudera_manager_agent.url.namenode136</name>
<value>http://linux123:9000/fence/fence?name=hdfs-NAMENODE&host=linux123&port=8020</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>lgns</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.lgns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.lgns</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>linux121:2181,linux122:2181,linux123:2181</value>
</property>
<property>
<name>dfs.ha.namenodes.lgns</name>
<value>namenode31,namenode136</value>
</property>
<property>
<name>dfs.namenode.name.dir.lgns.namenode31</name>
<value>file:///data/dfs/nn</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.lgns.namenode31</name>
<value>qjournal://linux121:8485;linux122:8485;linux123:8485/lgns</value>
</property>
<property>
<name>dfs.namenode.rpc-address.lgns.namenode31</name>
<value>linux122:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.lgns.namenode31</name>
<value>linux122:8022</value>
</property>
<property>
<name>dfs.namenode.http-address.lgns.namenode31</name>
<value>linux122:50070</value>
</property>
<property>
<name>dfs.namenode.https-address.lgns.namenode31</name>
<value>linux122:50470</value>
</property>
<property>
<name>dfs.namenode.name.dir.lgns.namenode136</name>
<value>file:///data/dfs/nn</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.lgns.namenode136</name>
<value>qjournal://linux121:8485;linux122:8485;linux123:8485/lgns</value>
</property>
<property>
<name>dfs.namenode.rpc-address.lgns.namenode136</name>
<value>linux123:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.lgns.namenode136</name>
<value>linux123:8022</value>
</property>
<property>
<name>dfs.namenode.http-address.lgns.namenode136</name>
<value>linux123:50070</value>
</property>
<property>
<name>dfs.namenode.https-address.lgns.namenode136</name>
<value>linux123:50470</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>supergroup</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.replication.min</name>
<value>1</value>
</property>
<property>
<name>dfs.replication.max</name>
<value>512</value>
</property>
<property>
<name>dfs.namenode.maintenance.replication.min</name>
<value>1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.image.transfer.timeout</name>
<value>60000</value>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>0</value>
</property>
<property>
<name>dfs.namenode.plugins</name>
<value></value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.service.handler.count</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.name.dir.restore</name>
<value>false</value>
</property>
<property>
<name>dfs.thrift.threads.max</name>
<value>20</value>
</property>
<property>
<name>dfs.thrift.threads.min</name>
<value>10</value>
</property>
<property>
<name>dfs.thrift.timeout</name>
<value>60</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999</value>
</property>
<property>
<name>dfs.namenode.invalidate.work.pct.per.iteration</name>
<value>0.32</value>
</property>
<property>
<name>dfs.namenode.replication.work.multiplier.per.iteration</name>
<value>10</value>
</property>
<property>
<name>dfs.namenode.replication.max-streams</name>
<value>20</value>
</property>
<property>
<name>dfs.namenode.replication.max-streams-hard-limit</name>
<value>40</value>
</property>
<property>
<name>dfs.namenode.avoid.read.stale.datanode</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.avoid.write.stale.datanode</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.stale.datanode.interval</name>
<value>30000</value>
</property>
<property>
<name>dfs.namenode.write.stale.datanode.ratio</name>
<value>0.5</value>
</property>
<property>
<name>dfs.namenode.safemode.min.datanodes</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.safemode.extension</name>
<value>30000</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>fs.permissions.umask-mode</name>
<value>022</value>
</property>
<property>
<name>dfs.encrypt.data.transfer</name>
<value>false</value>
</property>
<property>
<name>dfs.encrypt.data.transfer.algorithm</name>
<value>rc4</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.access.time.precision</name>
<value>3600000</value>
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>20000</value>
</property>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>20000</value>
</property>
<property>
<name>dfs.qjournal.prepare-recovery.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.accept-recovery.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.finalize-segment.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>20000</value>
</property>
<property>
<name>dfs.qjournal.get-journal-state.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.new-epoch.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
</configuration>
RealTimeProcess 最终代码
package com.lg.monitor
import com.lg.bean.BusInfo
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{Column, DataFrame, Dataset, Row, SparkSession}
/**
* 使用结构化流读取kafka中的数据
*/
object RealTimeProcess {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
//1 获取sparksession
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName(RealTimeProcess.getClass.getName)
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
//2 定义读取kafka数据源
val kafkaDf: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "linux122:9092,linux123:9092")
.option("subscribe", "lg_bus_info")
.load()
//3 处理数据
val kafkaValDf: DataFrame = kafkaDf.selectExpr("CAST(value AS STRING)")
//转为ds
val kafkaDs: Dataset[String] = kafkaValDf.as[String]
//解析出经纬度数据,写入redis
//封装为一个case class方便后续获取指定字段的数据
val busInfoDs: Dataset[BusInfo] = kafkaDs.map(BusInfo(_)).filter(_ != null)
//把经纬度数据写入redis
busInfoDs.writeStream
.foreach(new RedisWriter)
.outputMode("append")
.start()
//.awaitTermination()
//把经纬度数据写入Hbase中
busInfoDs.writeStream
.foreach(new HbaseWriter)
.outputMode("append")
.start()
//.awaitTermination()
//把经纬度数据写入Mysql
val MysqlWriter = new MysqlWriter("jdbc:mysql://linux123:3306/lg_logstic?characterEncoding=UTF-8", "root", "12345678")
busInfoDs.writeStream
.foreach(MysqlWriter)
.outputMode("append")
.trigger(Trigger.ProcessingTime(0))
.start()
//.awaitTermination()
//实现对车辆异常情况的监测
val warnInfoDs = busInfoDs.filter(
info => {
val remain: String = info.oilRemain
remain.toInt < 30 //剩余油量小于30%
}
)
//写入到kafka另外一个主题,由web系统监听,然后推送警告信息到车载客户单
//写出的ds/df中必须有一个列名叫做value
warnInfoDs
.withColumn("value", new Column("deployNum"))
.writeStream
.format("kafka")
.option("checkpointLocation", "hdfs://lgns/realtime") //ck目录一般选择是hdfs目录
.option("kafka.bootstrap.servers", "linux122:9092,linux123:9092")
.option("topic", "lg_bus_warn_info")
.start()
//.awaitTermination()
spark.streams.awaitAnyTermination()
}
}
打包上传


将bus_monitor1-1.0-SNAPSHOT-jar-with-dependencies.jar 重命名为bus_monitor.jar上传到linux123 ./monitor
提交任务
spark-submit --class com.lg.monitor.RealTimeProcess --master yarn --deploy-mode cluster --executor-memory 1G --num-executors 3 /root/monitor/bus_monitor.jar;
中止任务
yarn application -kill application_1602905611313_0048
报错信息
User class threw exception: com.fasterxml.jackson.databind.exc.MismatchedInputException: No content to map due to end-of-input
删除之前运行的ck目录(修改了代码之前目录的数据无法匹配所以报错)
数据可视化
参考logistics-front工程
启动生产者
kafka-console-producer --broker-list hadoop3:9092 --topic lg_bus_info
测试数据
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.372841_39.94876,70,north,7000,1594076127,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.376274_39.948299,70,north,7000,1594072527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.378763_39.948431,70,north,7000,1594073527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.382282_39.948562,70,north,7000,1594074527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.382883_39.948431,70,north,7000,1594075527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.386574_39.948496,70,north,7000,1594076527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.38872_39.948628,70,north,7000,1594076727,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.38872_39.94876,70,north,7000,1594076827,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393741_39.948957,70,north,7000,1594076927,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393784_39.949977,70,north,7000,1594071527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393805_39.950158,70,north,7000,1594072527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393741_39.951227,70,north,7000,1594073527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393698_39.951038,70,north,7000,1594074527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393988_39.952453,70,north,7000,1594075527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.393676_39.952551,70,north,7000,1594076527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.395168_39.955857,70,north,7000,1594077527,70,500,1,1,0,0
316d5c75-e860-4cc9-a7de-ea2148c244a0,4444,ysz11111,京A-11111,116.395157_39.957223,70,north,7000,1594078527,70,500,1,1,0,0