��, HBase ����
2.1 Hbase �������ܹ�
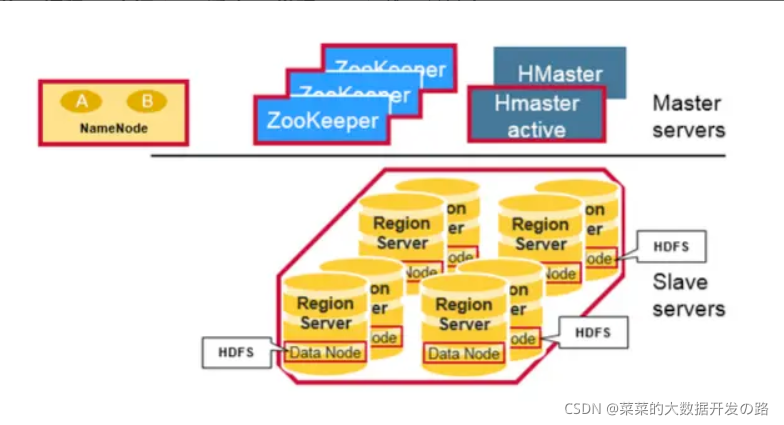
������, HBase�����������͵�Server��ɵ�����ʽ(master-slave)�ܹ�:
1. RegionServer (HRigionServer)
[����]
��HDFS��, DataNode����洢ʵ������, RegionServer��Ҫ������Ӧ�û�������, ��HDFS��д����; �����ڷֲ�ʽ��Ⱥ��, RegionServerһ��������DataNode��������, ʵ�����ݵı�����;
[�����ܽ�]
RegionServer ά��Master���������Region:1.ֱ�Ӵ���Client����ЩRegion��IO����;
2.ˢдMemStore��HDFS��;
3.ͬʱ�������й����б�úܴ��Region����split����;
4.����Գ����ļ�������ֵ��store�ļ�����Compact ����;
2. HBase Mater(HMaster)
[����]
�ڷֲ�ʽ��Ⱥ��, HMaster������ͨ�������� HDFS��NameNode��, HMaster ͨ��Zookeeper �����ⵥ�����, �ڼ�Ⱥ�п����������HMaster, ��Zookeeper��ѡ�ٻ����ܹ���֤ͬʱֻ��һ��HMaster����Active״̬, ������HMaster�����ȱ���״̬;
[�����ܽ�]
HMaster ��Ҫ�������Region�Ĺ�������
- �����û��Ա�����ɾ�IJ����****(DDL);
- ����RegionServer�����ؾ���, ƽ��Region�ڷֲ�ʽϵͳ�еķֲ�, ������Region����Ƭ������Ƴ�;
- ����RegionServer�Ĺ���ת��;
��չ:

3. Zookeeper
[����]
[�����ܽ�]
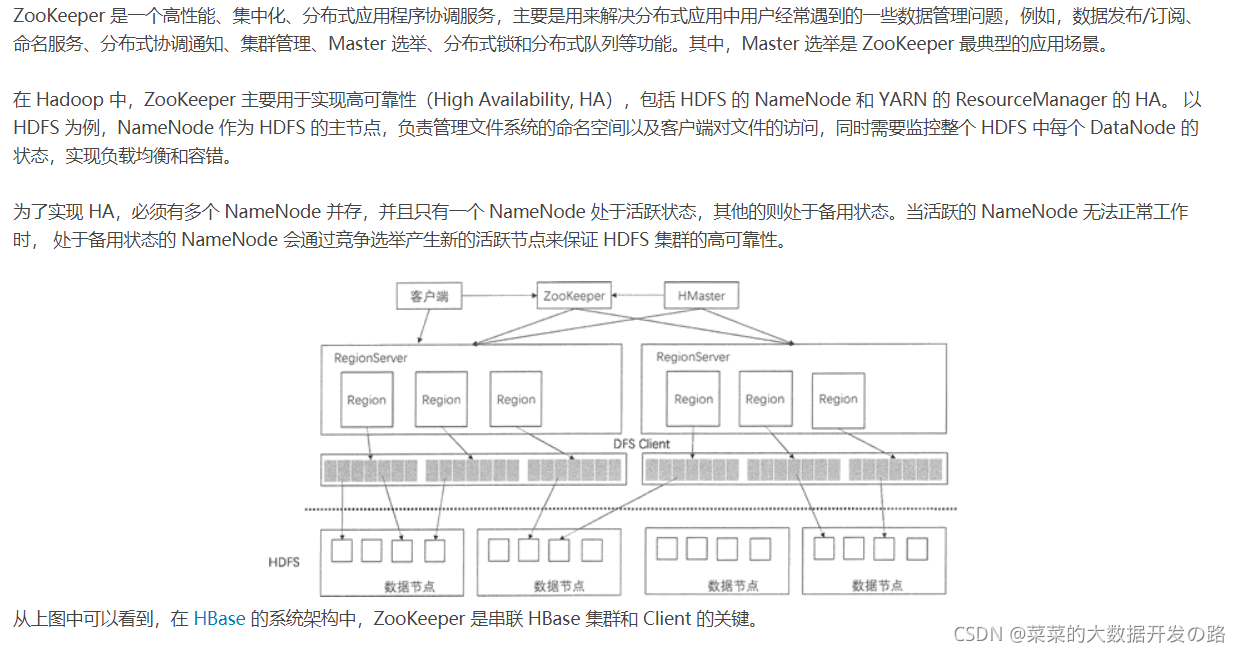
HBase����ZooKeeperά����Ⱥ�з�������״̬��Э���ֲ�ʽϵͳ�Ĺ���
- Masterѡ��:
- ͬHDFS��HA����һ��, HBase��Ⱥ��Ҳ�ж��HMaster����, ͨ������ѡ�ٻ��Ʊ�֤ͳһʱ��ֻ��һ��HMaster ���ڻ�Ծ״̬, һ����� HMaster��ʹ��, ��ӱ���master�ڵ���ѡ��һ������, ��֤��Ⱥ�ĸ߿�����(HA-hign avbility)
- �ڵ�һ��HMaster���ӵ�ZooKeeperʱ�ᴴ��Ephemeral�ڵ�(Ĭ��:/hbasae/master)����ʾActive��HMaster,���ӽ�����HMaster�������Ephemeral�ڵ�
- �ݴ�����:
- ��HBase����ʱ, ÿ��RegionServer�ڼ��뼯Ⱥʱ����Ҫ��Zookeeper�н���ע��, ����һ��״̬�ڵ�, Zookeeper��ʱʱ���ÿ��RegionServer��״̬, ͬʱHMaster �������Щע���RegionServer;
- ��ij��RegionServer �ҵ���ʱ��, Zookeeper ����Ϊһ��ʱ����ղ�������������Ϣ��ɾ����RegionServer ��Ӧ��״̬�ڵ�, ���һ��HMaster ���ͽڵ�ɾ����֪ͨ, ��ʱHMaster��֪��Ⱥ��ij���ڵ�Ͽ�, ���������������ڵ㿪���ݴ�����;
- Region ״̬����:
- HBase ��Ⱥ�� Region �ᾭ�������䶯, ԭ�������ϵͳ����ת��, ������, ������Region���зֺͺϲ�, ֻҪRegion�����仯, ����Ҫ�ü�Ⱥ�����нڵ�֪��, ��������ijЩ�����Ե��쳣; ����HBase��Ⱥ, �൱���Region ���������HMaster��״̬�����Ļ�, HMaster �ĸ��������, ����ֻ������Zookeeper��Ⱥ�����;
- Region Ԫ���ݵĹ���:
- ��HBase��Ⱥ��, Region Ԫ���ݱ��洢��Mete����, ÿ�οͻ��˷����µ�����ʱ, ��Ҫ��ѯMeta������ȡRegion��λ��;
- �� Region �����仯ʱ,����,Region ���ֹ��ƶ������и��ؾ�����ƶ��� Region ���ڵ� RegionServer ���ֹ��ϵ�,���ܹ�ͨ�� ZooKeeper ����֪����һ�仯,��֤�ͻ����ܹ������ȷ�� Region Ԫ������Ϣ��
- �ṩMeta���Ĵ洢λ��:
- ��HBase��Ⱥ��, ���ݿ�ı���Ϣ, ������Ϣ������洢��Ϣ������Ԫ����, ��Щԭ���ݴ洢��Meta����, ��Meta����λ�������Zookeeper���ṩ;
��չ: ʲô��Meta Table?
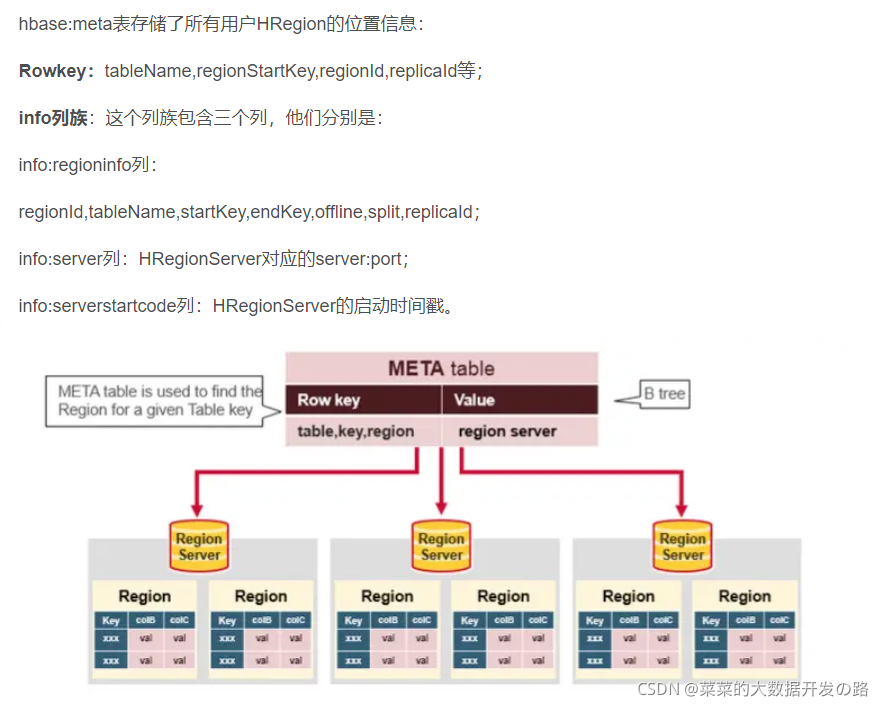
Meta Table(hbase:meta),���洢�˼�Ⱥ�������û�HRegion��λ����Ϣ,��ZooKeeper�Ľڵ���(/hbase/meta-region-server)�洢����ֱ�������Meta Table��λ��,�������Meta Table����ǰ��-ROOT- Tableһ���Dz���split�ġ�����,�ͻ����ڵ�һ�η����û�Table�����̾ͱ����:
1. �ͻ��˴�zk�л�ȡ����meta table��λ����Ϣ,֪��meta table���������ĸ�region server,���ڿͻ��˻������λ����Ϣ;
2. client���ѯ�������meta table���ض���region server,��ѯmeta table��Ϣ,��table�л�ȡ�Լ���Ҫ���ʵ�row key���ڵ�region���ĸ�region server�ϡ�
3. �ͻ���ֱ�ӷ���Ŀ��region server,��ȡ��Ӧ��row
ע:�ͻ��Ỻ����Щλ����Ϣ,Ȼ���ڶ�����ֻ�ǻ��浱ǰRowKey��Ӧ��HRegion��λ��,��������һ��Ҫ���RowKey����ͬһ��HRegion��,����Ҫ������ѯhbase:meta���ڵ�HRegion,Ȼ������ʱ�������,�ͻ��˻����λ����ϢԽ��Խ��,�����ڲ���Ҫ�ٴβ���hbase:meta Table����Ϣ,����ij��HRegion��Ϊ崻���Split���ƶ�,��ʱ��Ҫ���²�ѯ���Ҹ��»��档
�����:
- https://blog.csdn.net/weixin_33964094/article/details/92441365
- http://c.biancheng.net/view/6510.html
- https://segmentfault.com/a/1190000019959411
4. Q: �����������������һ������?
ÿ��Region Server ���ᴴ��һ��ephmeral �ڵ�, HMaster ������Щ�ڵ������ֿ��õ�Region Servers, ͬʱ��Ҳ������Щ�ڵ��Ƿ���ֹ���;
HMaster �ǻᾺ������ ephemeral �ڵ�,�� Zookeeper ����˭�ǵ�һ����Ϊ���� HMaster,��֤����ֻ��һ�� HMaster���HMaster(active HMaster) ��� Zookeeper ��������,�ǻHMaster (inactive HMaster) ����� active HMaster ���ܳ��ֵĹ��ϲ���ʱ����λ��
�����һ�� Region Server ���� HMaster ���ֹ��ϻ����ԭ���·�������ʧ��,������ Zookeeper �� session �ͻ����,��� ephemeral �ڵ�ͻᱻɾ������,�������Ǿͻ��յ������Ϣ��Active HMaster �������� region servers ���ߵ���Ϣ,Ȼ���ָ����ϵ� region server �Լ���������� region ���ݡ��� Inactive HMaster ���ĵ����� active HMaster ���ߵ���Ϣ,Ȼ�������߱�� active HMaster
2.2 RegionServer�����
- HRegionServer�������HRegion,��WAL(HLog)��BlockCache��MemStore��HFile��ɡ�
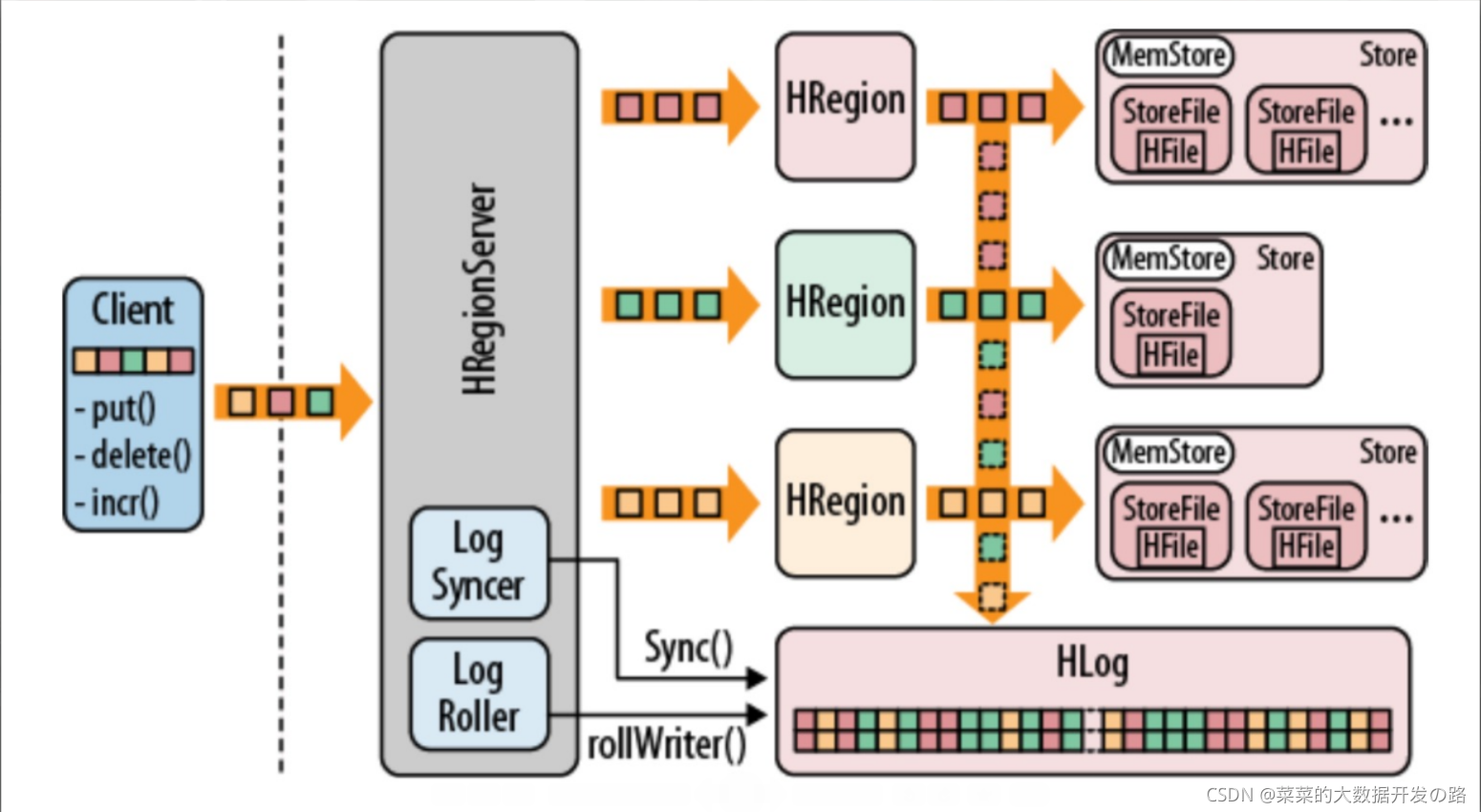
- WAL
HBase��Write Ahead Log (WAL)�ṩ��һ�ָ߲������־û�����־������طŻ��ơ�ÿһ��ҵ�����ݵ�д�����(PUT / DELETE)ִ��ǰ,���������WAL�С�
��������Ҫ�� MemStore ��������ˢд�� HFile,�������ݱ������ڴ��л��кܸߵ�
���ʵ������ݶ�ʧ,Ϊ�˽���������,������¼����д��һ������ Write-Ahead logfile ���ļ�
��,Ȼ����д�� MemStore �С�������ϵͳ���ֹ��ϵ�ʱ��,���ݿ���ͨ�������־�ļ���
���� (HBase��WAL��ʵ������HLog)
-
�������:
����,�ͻ��˳�ʼ��һ�����ܶ����ݸĶ��IJ���,��put(Put),delete(Delete) �� incrementColumnValue()����Щ������������װ��һ��KeyValue����ʵ����,ͨ��RPC ���÷���HRegionServer(�������������)�� һ���ﵽһ����С,HRegionServer ���䷢��HRegion�����������,���ݻ����Ȼᱻд��WAL,֮��д��ʵ�ʴ�����ݵ�MemStore�С���MemStore����һ����С,���߾���һ��ʱ���,���ݽ����첽��д���ļ�ϵͳ��
- MemStroe
- д����,���� HFile �е�����Ҫ���������,�����������ȴ洢�� MemStore ��,�ź����,�ȵ���ˢдʱ��(memStore�Ĵ�С�ﵽһ����ֵ(Ĭ��128MB))�Ż�ˢд�� HFile,ÿ��ˢд�����γ�һ���µ� HFile��
- StoreFile
- memStore�ڴ��е�����д���ļ������StoreFile,����ʵ�����ݵ������ļ�,
- StoreFile �� HFile ����ʽ�洢�� HDFS �ϡ�ÿ�� Store ����һ������ StoreFile(HFile),
- ������ÿ�� StoreFile �ж�������ġ�
- HFile
HBase��KeyValue���ݵĴ洢��ʽ,HFile��Hadoop�� �����Ƹ�ʽ�ļ�,ʵ����StoreFile���Ƕ�Hfile������������װ,��StoreFile�ײ����HFile
Store: ÿ��Region��ÿ���д��ڵײ�洢Ϊһ��Hfile��
��������:
https://www.cnblogs.com/qingyunzong/p/8692430.html
2.3 HBase �� ���
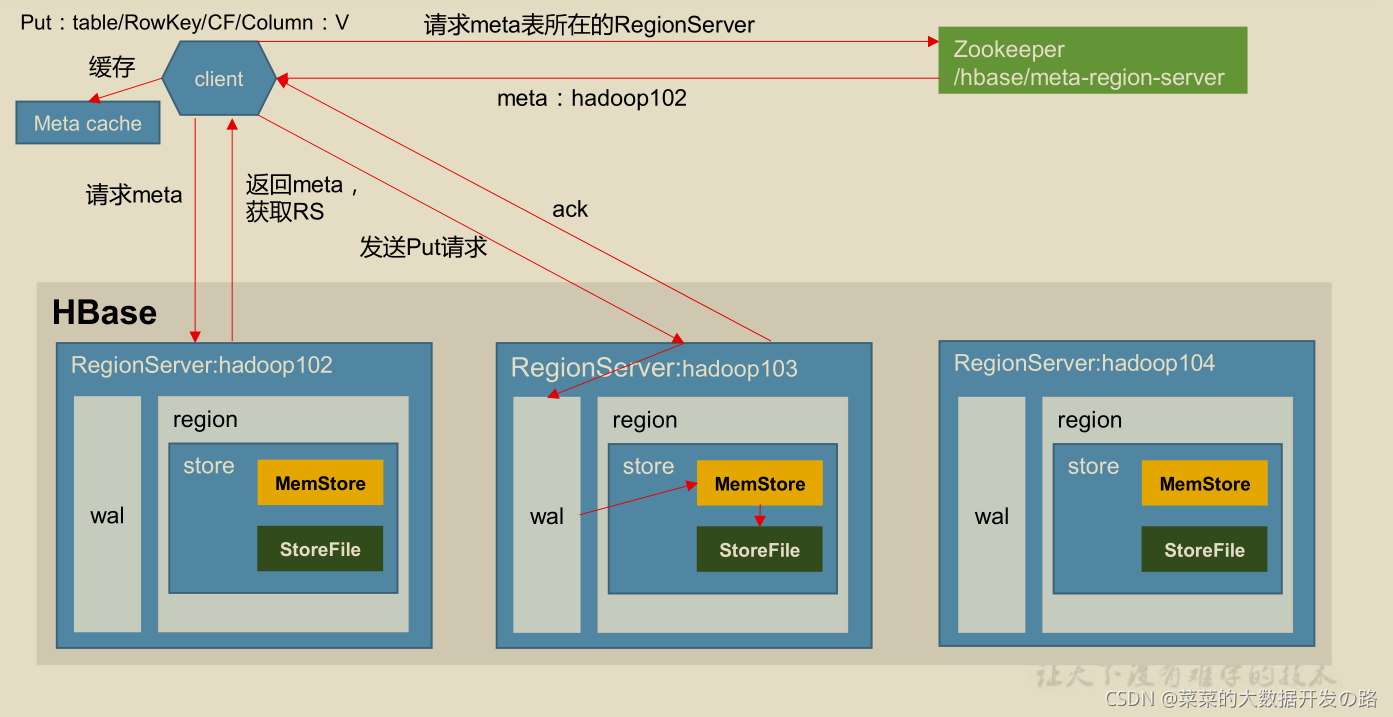

client�C>zk�C>regionserver�C>region�C>�ӵ�wal�C>memstore�C>ack�C>flush
2.3.1 MemStore Flush ����
2.4 HBase �Ķ�����
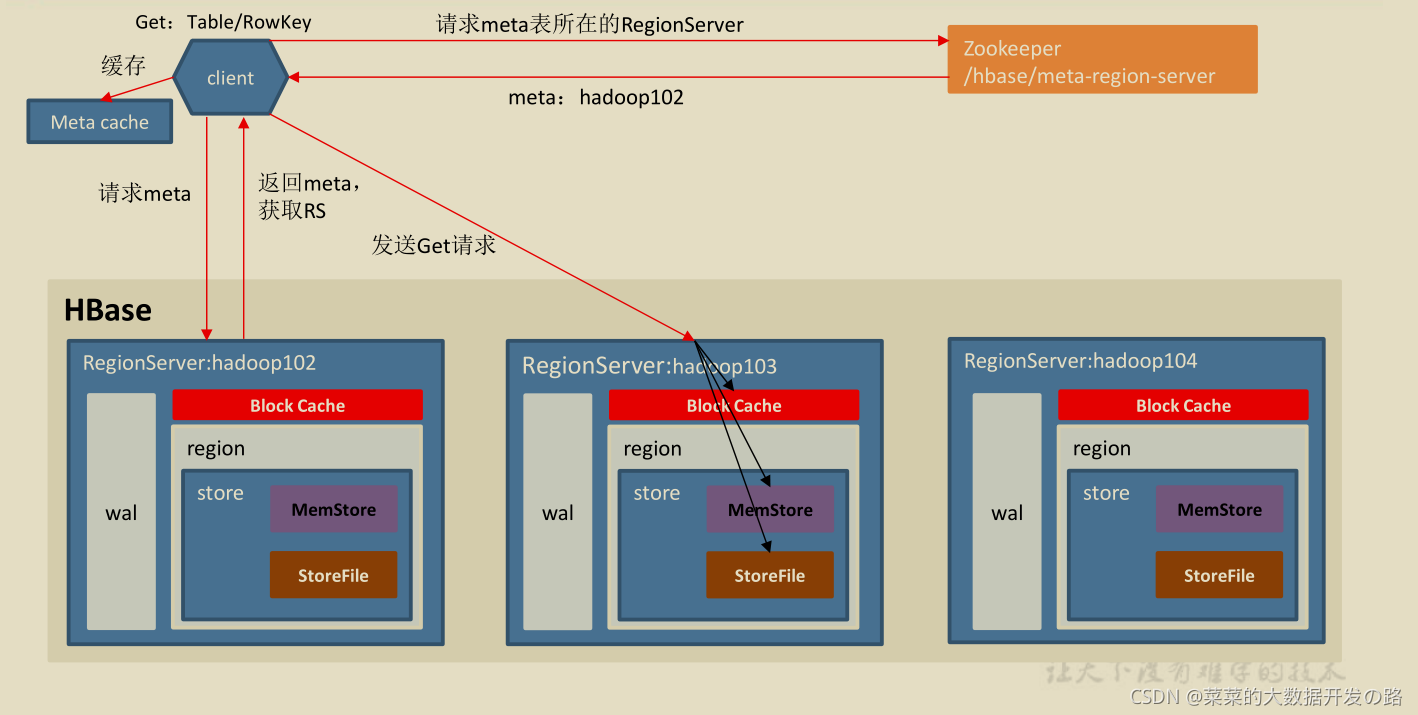

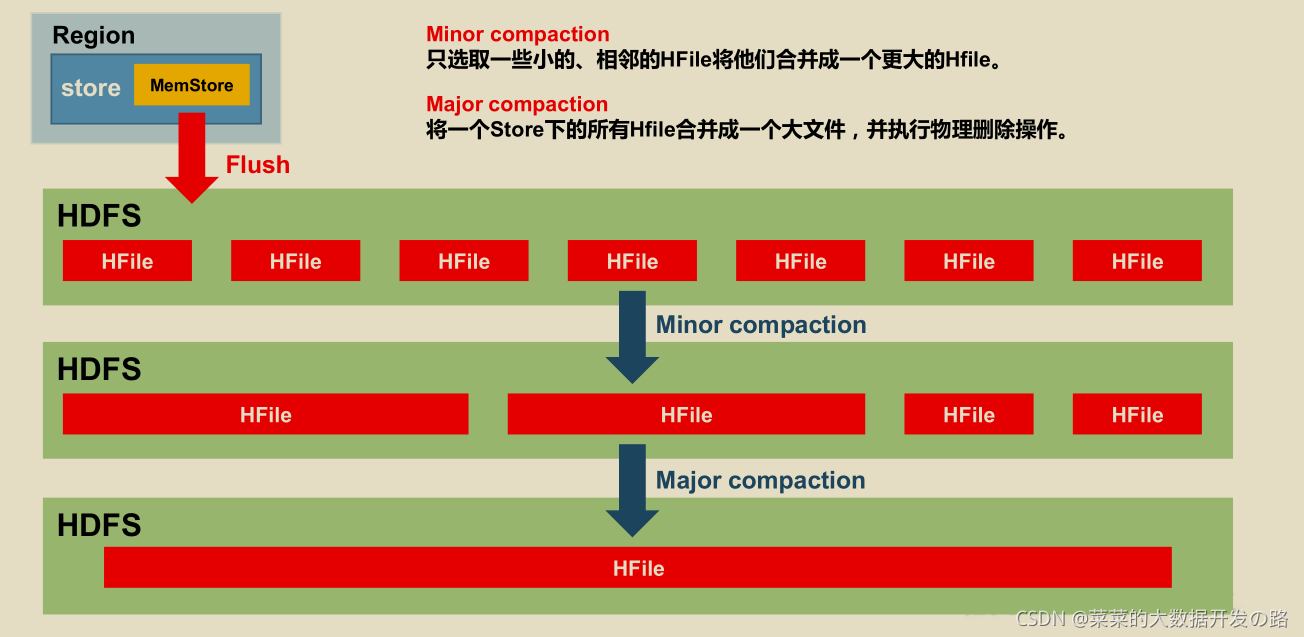
2.4.1 StoreFile Compaction
- ����memstore ÿ��ˢд��������һ���µ�HFile, ��ͬһ���ֶεIJ�ͬ�汾(timestamp)�Ͳ�ͬ����(put/delete) �п��ܻ�ֲ��ڲ�ͬ��HFile��, ��˲�ѯʱ��Ҫ�������е�HFile.
- Ϊ������HFile �ĸ���, �Լ����������ں�ɾ��������, �����StoreFile Compaction;
HFile ��compaction ��Ϊ����, �ֱ���
Minor Compactiomn��Major Compaction,
- Minor Compaction (��С�C> �ϴ�, ��ɾ��), �Ὣ�ٽ������ɸ���С��HFile �ϲ���һ���ϴ��HFile, �������������ں�ɾ��������;
- Major Compaction (���ШC>��, ��ɾ��)�Ὣһ��Store �µ����е�HFile �ϲ���һ����HFile, ���һ����������ں�ɾ��������;