����Ŀ¼
GlusterFS�ֲ�ʽ�ļ�ϵͳ
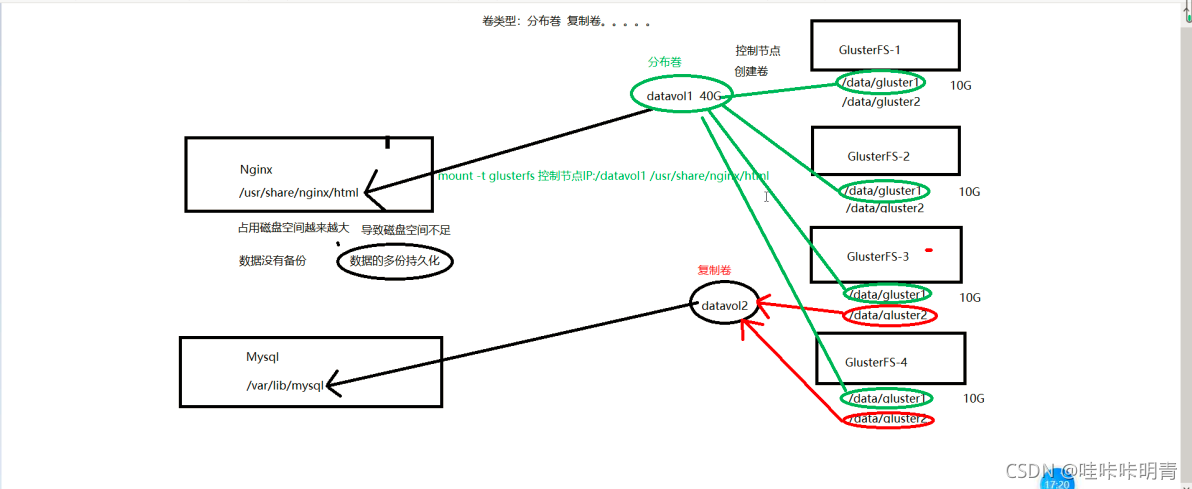
GlusterFS���
��Դ�ֲ�ʽ�ļ�ϵͳ
PB������
�߿�����
��/���
�����ļ�ϵͳ������
? GlusterFS(GNU ClusterFile System)��һ��ȫ�ԳƵĿ�Դ�ֲ�ʽ�ļ�ϵͳ,��νȫ�Գ���ָGlusterFS���õ��Թ�ϣ�㷨,û�����Ľڵ�,���нڵ�ȫ��ƽ�ȡ�GlusterFS���÷���,�ȶ��Ժ�,�����ɴﵽPB������,��ǧ���ڵ㡣
? 2011�걻��ñ�չ�,֮���Ƴ��˻���GlusterFS��Red Hat Storage Server,���������KVM���������ԡ�������ΪKVM�洢image�洢��Ⱥ,Ҳ����ΪLB��HA�ṩ�洢��
GlusterFS����:
Brick
Volume
Fuse
VFS
Glusterd
GlusterFS��Ҫ����:
ȫ�ԳƼܹ�
֧�ֶ��־�����(����RAID0/1/5/10/01)
֧�־������ѹ��
֧��NFS
֧��SMB
֧��Hadoop
֧��Openstack
֧��kubernetes
GlusterFS��Ҫ����:
brick: GlusterFS�Ļ�����Ԫ,�Խڵ������Ŀ¼��ʽչ�֡�
Volume: ��� bricks ��������
Metadata: Ԫ����,���������ļ���Ŀ¼�ȵ���Ϣ��
Self-heal: ���ں�̨���м�⸴�������ļ���Ŀ¼�IJ�һ���Բ������Щ��һ�¡�
GlusterFS Server: ���ݴ洢������,�����GlusterFs�洢��Ⱥ�Ľڵ㡣
GlusterFS Client: ʹ��GlusterFS�洢�������ķ�����,����KVM��Openstack��LB RealServer��HA node��
������
5̨�����(��Ȼ���Ը���ڵ�)
����ϵͳ IP ������
Centos7.4 192.168.62.203 node1
Centos7.4 192.168.62.204 node2
Centos7.4 192.168.62.135 node3
Centos7.4 192.168.62.166 node4
���л����رշ���ǽ
systemctl stop firewalld && setenforce 0
ͬ��ʱ����Ҫ
yum -y install ntp //ʱ����� ������
[root@mysql-1 ~]# vim /etc/ntp.conf //�������������ӽ�ȥ
ѡȡһ������ͬ������
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
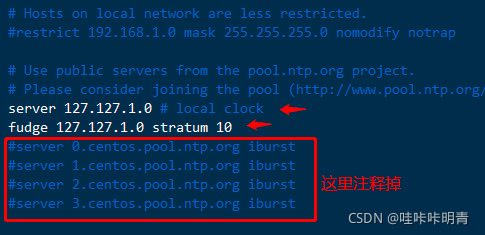
[root@node1 ~]# systemctl restart ntpd
����3̨�ͻ���ͬ��ʱ��:
[root@node2 ~]# yum -y install ntp
[root@node2 ~]# ntpdate node1

�ֱ�����������:
[root@192 ~]# hostnamectl set-hostname node1
[root@192 ~]# hostnamectl set-hostname node2
[root@192 ~]# hostnamectl set-hostname node3
[root@192 ~]# hostnamectl set-hostname node4
���ý���,���л���:
[root@192 yum.repos.d]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.62.131 node01
192.168.62.231 node02
192.168.62.168 node03
192.168.62.166 node04
��װglusterfs����(��������)
����������Ҫ������,�ص�
yum install centos-release-gluster glusterfs-server samba rpcbind -y
�������ʧ��,��glusterfs��yumԴ�����ļ�

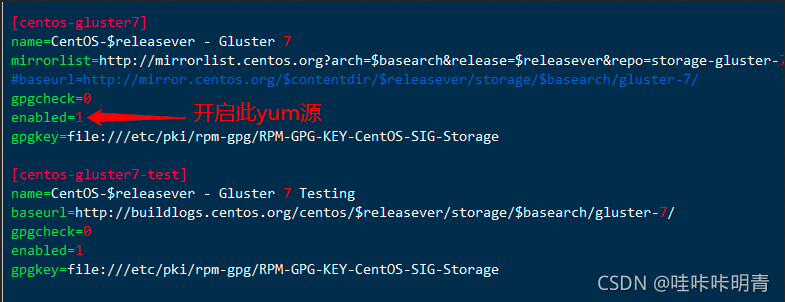
���нڵ�������������Ϊ��������
[root@node1 ~]# systemctl start glusterd.service
[root@node1 ~]# systemctl enable glusterd.service
 ## ����Glusterfs��Ⱥ
## ����Glusterfs��Ⱥ
���ӽڵ�Ĺ��̾��Ǵ�����Ⱥ�Ĺ���,��node01һ̨�ϲ����Ϳ���,����Ҫ���ӱ��ڵ�
[root@node1 yum.repos.d]# gluster peer probe node02
peer probe: success.
[root@node1 yum.repos.d]# gluster peer probe node03
peer probe: success.
[root@node1 yum.repos.d]# gluster peer probe node04
�鿴״̬
[root@node1 yum.repos.d]# gluster peer status
Number of Peers: 3
Hostname: node02
Uuid: c5c38696-787b-48f9-a4b8-9a38d0cef54f
State: Peer in Cluster (Connected)
Hostname: node03
Uuid: 5cf46129-304a-48c4-b354-4b7f661ed3bb
State: Peer in Cluster (Connected)
Hostname: node04
Uuid: 2d325694-953c-45c6-a284-68816c9e9cdc
State: Peer in Cluster (Connected)
�Ӽ�Ⱥ��ɾ���ڵ�
[root@node1 yum.repos.d]# gluster peer detach node04
All clients mounted through the peer which is getting detached need to be remounted using one of the other active peers in the trusted storage pool to ensure client gets notification on any changes done on the gluster configuration and if the same has been done do you want to proceed? (y/n) y
peer detach: success
[root@node1 yum.repos.d]# gluster peer status
Number of Peers: 2
Hostname: node02
Uuid: c5c38696-787b-48f9-a4b8-9a38d0cef54f
State: Peer in Cluster (Connected)
Hostname: node03
Uuid: 5cf46129-304a-48c4-b354-4b7f661ed3bb
State: Peer in Cluster (Connected)
��������
[root@node1 ~]# gluster peer probe node04 //�������ӻ���
glusgerfs��������*
��������:����,����,��ϣ��Ȼ����������Ϻ���������ͬʱʹ��,�ܹ���������7��,�°�Ļ��������
�ֲ���
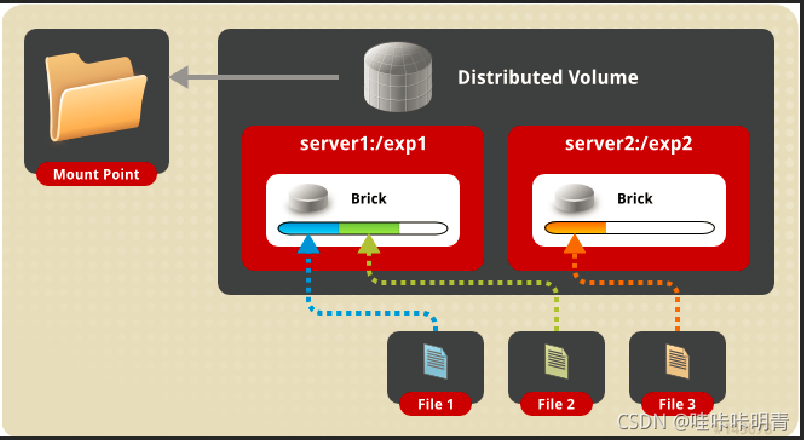
�ֲ���
�ֲ���Ҳ��Ϊ��ϣ��,����ļ��ڶ�� brick ��ʹ�ù�ϣ�㷨����洢��
��ϣ�������븺�ؾ���(ʵ���ϲ��Ǻܾ���),���Ὣ���������ݷֳɼ�������,�ֱ�洢��ÿһ��brick��
Ӧ�ó���: ����С�ļ�
�ŵ�: ��/д���ܺ�
ȱ��: ����洢�����������,���ݽ���ʧ
�������ݷ���
����server�ڵ�ֱ�/data0/glusterĿ¼,��νbrick��λ��,���ڴ洢����
mkdir -pv /data0/gluster
����volume,�ڿ��ƽڵ��ϲ���
[root@node1 yum.repos.d]# gluster
Welcome to gluster prompt, type 'help' to see the available commands.
gluster> volume create datavol1 transport tcp node01:/data0/gluster/data1 node02:/data0/gluster/data1 node03:/data0/gluster/data1 node04:/data0/gluster/data1 force
volume create: datavol1: success: please start the volume to access data
����volume
��ΪĬ���Ƿֲ���(��ϣ��),���Ծ�������û��ָ��,datavol1 ���volumeӵ��4��brick,�ֲ���4��peer�ڵ�
gluster> volume start datavol1
volume start: datavol1: success
�鿴����Ϣ
gluster> volume info datavol1
Volume Name: datavol1
Type: Distribute
Volume ID: 45ca6286-f622-4902-b10d-ccc38febe137
Status: Started
Snapshot Count: 0
Number of Bricks: 4
Transport-type: tcp
Bricks:
Brick1: node01:/data0/gluster/data1
Brick2: node02:/data0/gluster/data1
Brick3: node03:/data0/gluster/data1
Brick4: node04:/data0/gluster/data1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
�鿴��״̬
gluster> volume status datavol1
ɾ����
��Ҫ��ǰֹͣ������
gluster> volume stop datavol1 //ֹͣ
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: datavol1: success
gluster> volume delete datavol1 //ɾ��
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: datavol1: success
��̨�������Ϊ�ͻ���,ȥ����
[root@node4 ~]# mount -t glusterfs node01:/datavol1 /mnt
[root@node4 ~]# touch /mnt/fenbu1.txt #��������䵽ij���ڵ���
================================================================
ȥ�����ڵ�鿴,��һ���ֲ����ĸ��ڵ�
[root@node1 ~]# ls /data0/gluster/data1/
fenbu1.txt
[root@node4 ~]# touch /mnt/fenbu2.txt
ȥ�����ڵ�鿴,����������node3�ڵ��Ϸ���
[root@node3 ~]# ls /data0/gluster/data1/
fenbu2.txt
������volume��״̬��Ϣ,���Կ�����ÿһ���ڵ�������һ��volume��,gluster���Զ���������صĽ���,Port�������Ķ˿ڡ���ʹ��psȥ�鿴��ʱ���ʱ����3������:
glusterd #��������
glusterfsd #brick����,��Ϊ������ֻ��һ��brick
glusterfs #Ĭ��������nfs��Э�����,�ǿ��Թرյ�
������һ���ڵ��ϻ�������ͬ�Ľ��̡�
�������ݺ�����
������
ע��:����֮ǰ���ݻ��Զ�Ǩ��
[root@node1 glusterfs]# ls /data0/gluster/data1
fenbu1.txt
[root@node3 ~]# ls /data0/gluster/data1/
fenbu2.txt fenbu3.txt
[root@node1 glusterfs]# gluster
gluster> volume remove-brick datavol1 node03:/data0/gluster/data1 start //����Ǩ��
gluster> volume remove-brick datavol1 node03:/data0/gluster/data1 status //�鿴Ǩ��״̬
gluster> volume remove-brick datavol1 node03:/data0/gluster/data1 commit //�ύ
gluster> volume info datavol1 //�ٴβ鿴״̬,�Ϳ�����node03��
����Ҳ���Զ�Ǩ�Ƶ������ڵ��brick��
[root@node1 glusterfs]# ls /data0/gluster/data1 //����ƶ���������
fenbu1.txt fenbu2.txt fenbu3.txt
[root@node3 mmm]# ls /data0/gluster/data1/ //���ǿյ���
[root@node3 mmm]#
��������
gluster> volume add-brick datavol1 node03:/data0/gluster/data1 force //����,���������Զ��ֲ���ȥ
gluster> volume info datavol1 //�ٴβ鿴����Ϣ,�ͻ���node03�ڵ�
�������¾���
����֮��,Ӧ������һ�����ݵ����¾���
gluster> volume rebalance datavol1 start
gluster> volume rebalance datavol1 status
gluster> volume rebalance datavol1 stop
���ƾ�
 `����ļ��ڶ��brick�ϸ��ƶ��,brick����ĿҪ����Ҫ���Ƶķ������,����brick�ֲ��ڲ�ͬ�ķ������ϡ�
`����ļ��ڶ��brick�ϸ��ƶ��,brick����ĿҪ����Ҫ���Ƶķ������,����brick�ֲ��ڲ�ͬ�ķ������ϡ�
���ƾ�������������Ҫָ����������,���ƾ�����ÿһ��brick�е����ݶ���һ����,����д�����ݵ���������,�൱raid1��
�������������һ��,��Ȼ������Ҳ����������.
Ӧ�ó���: �Կɿ��ԺͶ�����Ҫ��ߵij���
�ŵ�: �����ܺ�
ȱ��: д���ܲ�`
[root@node4 data1]# gluster
Welcome to gluster prompt, type 'help' to see the available commands.
�������ƾ�
gluster> volume create datavol2 replica 2 transport tcp node01:/data0/gluster/data2 node02:/data0/gluster/data2 force
����volume
gluster> volume start datavol2
�鿴volume״̬
gluster> volume status
�鿴����Ϣ
gluster> volume info datavol2
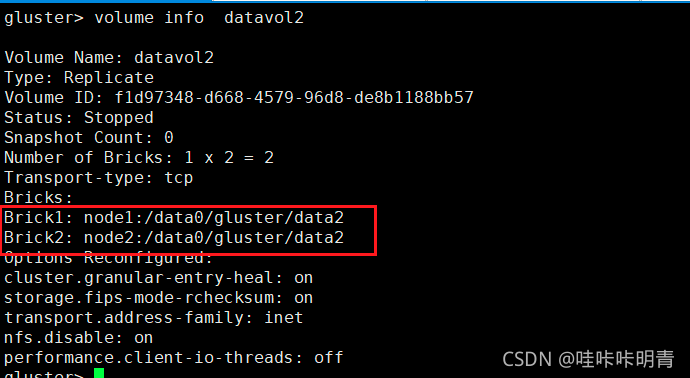
��Ҫ������Ҫ����
��������,�洢�ڵ��ͬ�����ƽڵ������,���ƽڵ㲻��ͬ���洢�ڵ������
[root@node3 data2]# mount -t glusterfs node01:/datavol2 /mnt
[root@node3 data2]# ls /mnt/
[root@node3 data2]# cd /mnt/
[root@node3 mnt]# touch d.txt
[root@node1 mnt]# ls /data0/gluster/data2/
d.txt
[root@node2 data2]# cd /data0/gluster/data2/
[root@node2 data2]# ls
d.txt