�ڰ�װ��spark��
- ��spark-env.sh ��û�� ��ģ���ļ�����Ϊ������
��spark��װĿ¼�µ�conf�ҵ�spark-env.sh
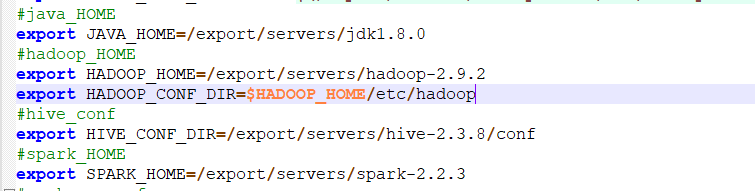
����HADOOP_HOME��HADOOP_CONF_DIR�������yarn-site.xml�ļ�����
- ��spark-defaults.conf
ͬ��conf�ļ������ҵ�spark-defaults.conf.template�ļ�����spark-defaults.conf
��������
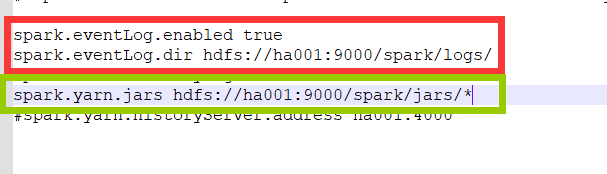
Ȼ��spark��װĿ¼�µ�jars�е��ļ� put��hdfs��ͼ��ָ��λ��

hdfs dfs -put ./jars/* /spark/jars/
��������Ŀ����spark����ʱ������hdfs������Ҫ��jar��,����java�������ݿ�Ҫ�õ�java-connecter-mysql.jar��
- spark on yarn �����ύ��ʽ
#��ǰĿ¼
#/export/servers/spark-2.2.3/
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode client \
--conf spark.driver.host=192.168.88.12 \
examples/jars/spark-examples_2.11-2.2.3.jar 10
�Cclass ��ȫ������
�Cmaster yarn ��ָʹ��yarn����
�Cdeploy-mode client*cluster* client�������ύ����Ļ����鿴���
clusterֻ����yarn�Ͽ����
�Cconf spark.driver.host=192.168.88.12 driver����������������IP��ַ�������ύ��������ĵ�ַ,�����ں�executors�Լ�������masterͨ�Ž��ս��
examples/jars/spark-examples_2.11-2.2.3.jar ���е�jar��
�����Dz���һ��demo����ͼ��Ϊspark�����Զ�����CPU���ڴ����Դ

����yarn-site.xml����