hadoop集群机架感知 -副本存储节点选择策略
官方解释
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
If the replication factor is greater than 3, the placement of the 4th and following replicas are determined randomly while keeping the number of replicas per rack below the upper limit (which is basically (replicas - 1) / racks + 2).
对于常见情况,当复制因子为3时,HDFS的放置策略是,如果写入程序位于数据节点上,则将一个副本放在本地计算机上,否则放在随机数据节点上,另一个副本放在不同(远程)机架中的节点上,最后一个副本放在同一远程机架中的不同节点上。此策略减少了机架间写入流量,这通常会提高写入性能。机架故障的几率远远小于节点故障的几率;此策略不影响数据可靠性和可用性保证。但是,它确实减少了读取数据时使用的聚合网络带宽,因为一个数据块只放在两个唯一的机架中,而不是三个。使用此策略,文件的副本不会均匀分布在机架上。三分之一的副本位于一个节点上,三分之二的副本位于一个机架上,另外三分之一均匀分布在其余机架上。此策略在不影响数据可靠性或读取性能的情况下提高了写入性能。
如果复制因子大于3,则随机确定第4个及以下副本的位置,同时保持每个机架的副本数量低于上限(基本上是(副本- 1) /机架+ 2)。
如下图:
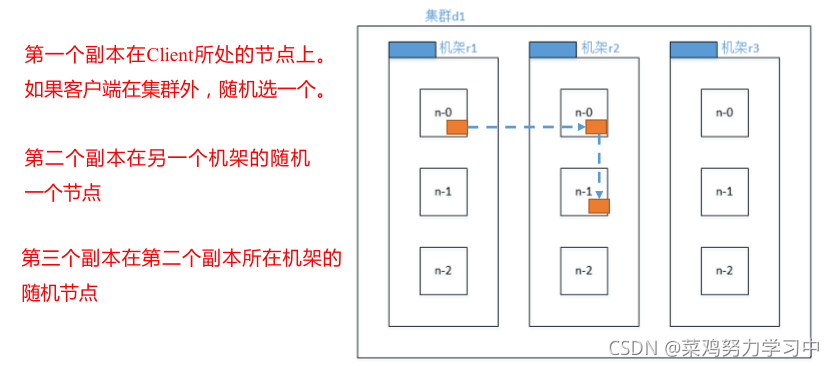
# 源码路径
hadoop-hdfs-project\hadoop-hdfs
\src\main\java\org\apache\hadoop\hdfs
\server\blockmanagement
可查看源码BlockPlacementPolicyDefault.java 在该类中查找 chooseTargetInOrder 方法。