首先是要进行连接的两张表,这里是以 .txt文件的形式来保存表的数据,分别是students.txt和score.txt
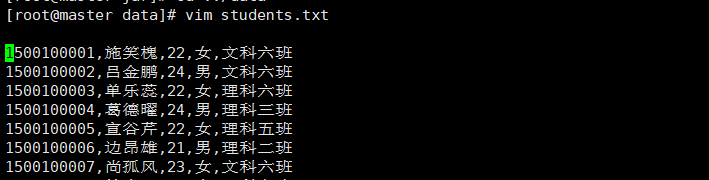
students文件的格式举例
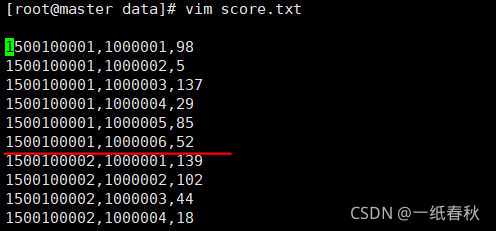
score文件的格式举例
students文件中,一个 id 对应一行学生信息
score文件中,一个id对应多行的学科成绩,因为科目不同
reduce side join
现在需求是输出学生的信息,以及学生的各科成绩总和
mapreduce代码为
package Demo.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import sun.management.FileSystem;
import java.io.IOException;
import java.util.ArrayList;
//求取每个学生的总分
public class joinDemo {
public static class JoinMapper extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
InputSplit inputSplit = context.getInputSplit();
FileSplit fs = (FileSplit)inputSplit;
String filename = fs.getPath().getName();
if(filename.contains("students.txt")){
String line = value.toString();
String[] split = line.split(",");
String id = split[0];
String info = "$"+value;
context.write(new Text(id),new Text(info));
}else{
String line = value.toString();
String[] split = line.split(",");
String id = split[0];
String score = split[2];
context.write(new Text(id),new Text(score));
}
}
}
public static class JoinReducer extends Reducer<Text,Text,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String student = "";
ArrayList<Integer> scores = new ArrayList<Integer>();
int sum = 0;
for (Text val : values) {
String value = val.toString();
if(value.startsWith("$")){
student = value.substring(1);
}else{
scores.add(Integer.parseInt(value));
}
}
for (Integer score : scores) {
sum += score;
}
context.write(new Text(student),new IntWritable(sum));
}
}
public static void main(String args[]) throws Exception{
Job job = Job.getInstance();
job.setJobName("joinMapReduce");
job.setJarByClass(joinDemo.class);
//配置map端
job.setMapperClass(JoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//配置reduce端
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定输入输出文件路径
Path input1 = new Path("hdfs://master:9000/data/students.txt");
Path input2 = new Path("hdfs://master:9000/data/score.txt");
FileInputFormat.addInputPath(job,input1);
FileInputFormat.addInputPath(job,input2);
Path output = new Path("hdfs://master:9000/output");
FileOutputFormat.setOutputPath(job,output);
//启动
job.waitForCompletion(true);
}
}
结果为
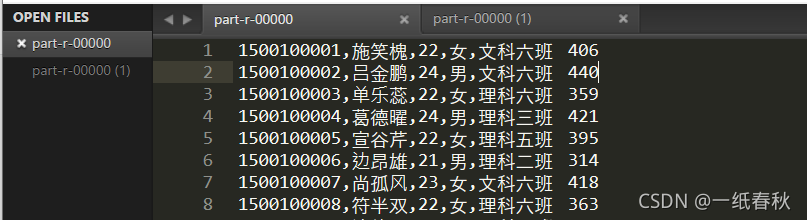
因为要给出班级中每个同学的成绩总和,数据分开放在students文件(学生信息)和score文件(各科成绩,一个学生id对应多个科目,一个科目对应一个成绩)中
这里的students和score文件没有被切分,并且都存放在一个node节点中,于是用
Path input1 = new Path("/students.txt");
FileInputFormat.addInputPath(job,input1);
Path input2 = new Path("/score.txt");
FileInputFormat.addInputPath(job,input2);
这样的方式将两个文件输入到一个map端,然后分别被送入两个mapTask,map端结束后有两种键值对被传入到reduce端
students文件进行mapTask端处理后的 < id,学生信息>
scores文件进行mapTask端处理后的 < id,语文成绩>, < id,数学成绩>,< id,英语成绩>
不同的键值对只要key值相同就会被传入同一个reduceTask,所以同一个学生的学生信息和各科成绩会被传入同一个reduceTask里面,但reduce端要能够分清学生信息和各科成绩,才能够对各科成绩计算总和,并且将学生信息作为key值,成绩总和作为value值作为reduce端的输出结果
因此在map端给学生信息也就是value值前面加上一个前缀 ,这里是使用 “ $ ”作为学生信息的前缀。在reduce端进行判断时,如果前缀为" # "则判断value值为学生信息,否则为单科成绩,将单科成绩放入arraylist列表中,最后对列表进行遍历求和
但是像上面那样不能被称为是 map side join,因为并没有在map端将学生信息和成绩信息进行join表连接,让同一个学生的学生信息和成绩连接在一起。上面的主要难点是按照 id 将学生信息和各科成绩都当作value值传入reduce端后,reduce端如何区分学生信息和各科成绩,实际上传输的数据量并没有减少
上面这种方式叫做 reduce side join,主要思想就是在map端读取多个文件,然后产生多种键值对,这些键值对的 key值相同,value值不同,为了在reduce端能够区分这些键值对,于是在map端对不同文件中的数据打上标签。然后reduce端再对数据进行聚合或者join连接
这种reduce side join是非常低效的,因为在shuffle阶段要进行大量的数据传输
map side join
真正的map side join 是要在map端完成join操作,将学生信息和成绩合并在一起当作key值,不需要经过redue端,直接写到hdfs里面
但这样会遇到一个问题,将学生信息和成绩合并在一起的前提是,两部分的 id相同才能进行合并,也就是join操作需要相同的key值、
所以需要具有相同 id 的学生信息和成绩进入同一个mapTask里面,比如id为1001的学生信息和id为1001的成绩进入一个mapTask
但是现在假设一下
students文件被切分成 block1 和 block2,block1存放id为1001的学生信息,block2存放id为1002的学生信息,block1存储在 node1 ,block2存储在 node2
socre文件被切分变成 block3 和 block4,block3存放id为1001的各科成绩,block4存放id为1002的各科成绩,block3存储在 node2 ,block4存储在 node1
这样我们写mapreduce在主方法里面设置输入文件路径的时候,只能设置students和score文件的位置,这个students和scores文件对应的是整个mapreduce而言的,相当于 students.txt,scores.txt――> mapreduce ――> 结果文件,实际上四个block块会分别进入一个mapTask里面,每个mapTask会根据我们编写mapreduce的map类代码,对自己的要处理的inputsplit文件进行相应的处理。整个Map端会有多个maptask。在默认情况下,一个block对应一个inputsplit,一个inputsplit对应一个mapTask
所以id为1001的学生信息(block1)和id为1001的各科成绩(block3)会分别进入两个mapTask,不在一个mapTask里面就不能进行map端的join连接,还是要靠相同的id然后传入reduce端
这种情况就是同一个key对应的字段可能位于不同map中
相对于reduce side join,map side join更加高效,但是要特定的场景才能使用,即有两个待连接表,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。具体运行的时候,先将小表放入内存中,每个MapTask的内存中都会有一个小表的数据。然后map函数只需要遍历大表,每次map函数会处理大表的一行数据,按照这一行数据的 key值到内存中的小表,找到小表相同key值对应的行,然后进行join操作,将两行内容按照key值进行连接
――――――――――――――――――――――――――――――――――――――――――
理论部分结束,现在来看一下具体的代码是怎么实现的
需求是:按照 id 将students文件里面的学生信息与 score文件里面的各科成绩进行连接
mapreduce代码为
package Demo.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class MapJoin {
public static class joinMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
//使用hashmap存储小表student里面的内容
HashMap<String,String> students = new HashMap<String, String>();
/**
* 使用setup来读取小表数据
* 将students作为小表,score作为大表,因为score的体积
* setup在 mapTask 之前执行,并且每次都会执行
* 所以每个mapTask的内存中都存在一份小表的数据
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取文件系统的操作对象,通过这个对象来获取小表的数据
FileSystem fs = FileSystem.get(context.getConfiguration());
Path path = new Path("/data/students.txt");
FSDataInputStream open = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(open));
String line;
while((line=br.readLine())!=null){
//把小表数据读取到内存,也就是放入HashMap中
//因为HashMap被创建后停留在内存中,然后随着程序的结束而消失
students.put(line.split(",")[0],line);
}
}
//students文件只会在每个mapTask之前被读取一次
//下面的这个map函数每次会读取score文件中的一条数据,也就是一行内容来处理
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//map端用来处理大表,也就是score.txt
String line = value.toString();
String[] split = line.split(",");
String id = split[0];
String stu = students.get(id);
String str = stu+","+split[2];
context.write(new Text(str),NullWritable.get());
}
}
public static void main(String args[]) throws Exception{
Job job = Job.getInstance();
job.setJobName("mapsidejoin");
job.setJarByClass(MapJoin.class);
//配置map端
job.setMapperClass(joinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//指定输入输出文件路径
Path input2 = new Path("/data/score.txt");
FileInputFormat.addInputPath(job,input2);
Path output = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
if(fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
//启动
job.waitForCompletion(true);
}
}
结果为
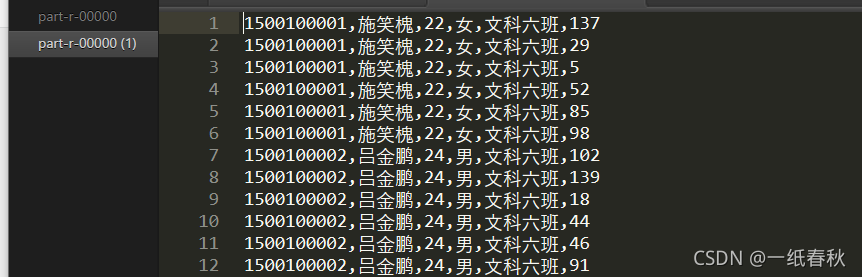
这里就是定义一个存留在内存中的HashMap,然后将students表的id作为key值,将students的一行内容作为value值存储在HashMap中,相当于存储在内容中。
Map函数根据score文件的每一行的id,通过get方法获取students文件的对应的行,然后拼接在一起,按照key值写入到hdfs中。