????????Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。 以下是Elasticsearch单个文档的写入简单流程。
1、数据写入的简单流程
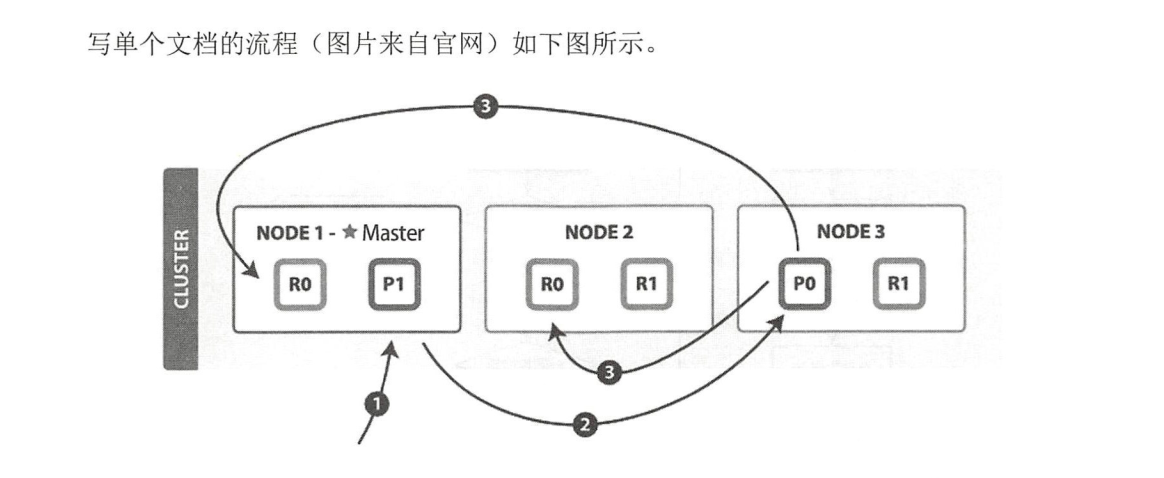
以下是写单个文档所需的步骤:
1、客户端向 NODE I 发送写请求。
2、检查Active的Shard数。
3、NODEI 使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片 0 的主分片位于 NODE3 ,因此请求被转发到 NODE3 上。
4、NODE3 上的主分片执行写操作 。 如果写入成功,则它将请求并行转发到 NODE I 和
NODE2 的副分片上,等待返回结果 。当所有的副分片都报告成功, NODE3 将向协调节点报告
成功,协调节点再向客户端报告成功 。
5、在客户端收到成功响应时 ,意味着写操作已经在主分片和所有副分片都执行完成。
2、索引与分片的关系
分片是一个底层的 工作单元,一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎,文档不会跨分片存储。
索引与分片的关系图:

3、数据写入详细流程

1、将document写入内存buffer缓存中,同时写入到translog中
2、每隔一秒钟,buffer中的数据被写入新的segment file,
3、同时进入os cache,此时index segment file被打开并供search使用,
4、buffer被清空
5、重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
6、当translog长度达到一定程度的时候,commit操作发生
? (6-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
? (6-2)buffer被清空
? (6-3)一个commit ponit被写入磁盘,标明了所有的index segment
? (6-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
7、现有的translog被清空,创建一个新的translog