前言
本文主要介绍Kafka的基本概念,包括:Kakfa的定义、Kafka的架构、Kafka的特点等。在 大数据之Kafka(下)中会介绍有关Kafka的数据生产、消费以及分区的相关知识。
一、消息队列
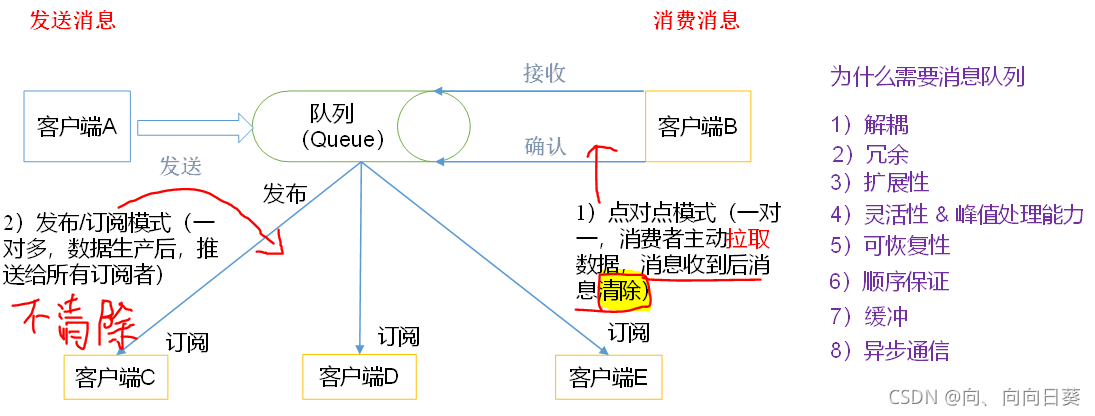
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
??点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
??发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
二、Kafka定义
??Kafka一般用来缓存数据; Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。

注意:
(1)无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
(2)kafka可以保证一个分区数据的顺序,因为一个分区的数据是一个队列,但是无法保证整个topic的顺序;因为当一个topic的数据过多时,需要对topic进行分区,但是不同的分区在消费的时候不一定是按照顺序消费的,所以kafka不能保证整个topic的顺序。
三、Kafka架构详解
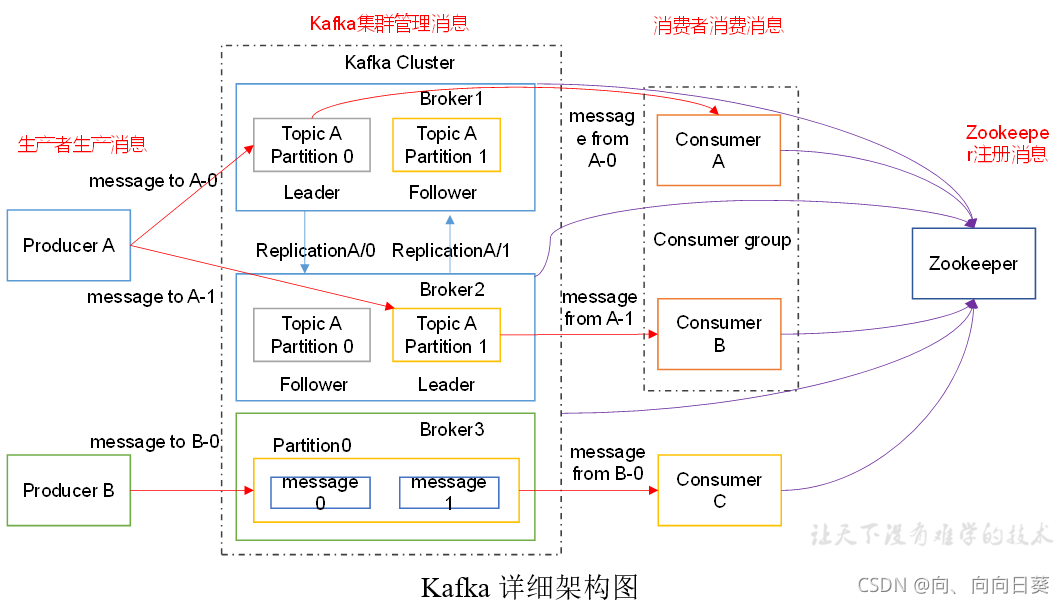
(1)kafka集群有多台机器,目的就是为了增加负载;每一台机器就是一个broker;
(2)生产者生产消息的时候,如果消息量过多,用同一台机器进行接收的话压力太大,引入分区partition 的概念,将数据分解放在不同的分区中,提高负载。
(3)不同的消息要进行分类,也就是不同的topic,因为不同的消费者会关心不同的数据。
(4)避免机器宕机导致数据丢失,必须对数据进行备份。源文件是leader,副本是follower;注意在kafka中读和写都是针对leader来说的,也就是说消费者消费的时候只消费leader中的数据,除非leader挂掉了,follower才有可能成为leader。
(5)kafka中只有消费者组的概念,哪怕这个组只有一个消费者。整个组是一个整体,彼此之间数据共享,即组内消费者彼此之间数据不一样,但是整合起来是一个完整的topic(例如:一个消费者组有三个消费者A,B,C,A和B分别读取了一半数据,那么C就可以什么都不用干,等着就行)。一般来说消费者的数量和分区数量一致。
四、Kafka的特点
4.1 Kafka的写入方式
??producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
4.2 Kafka的零复制
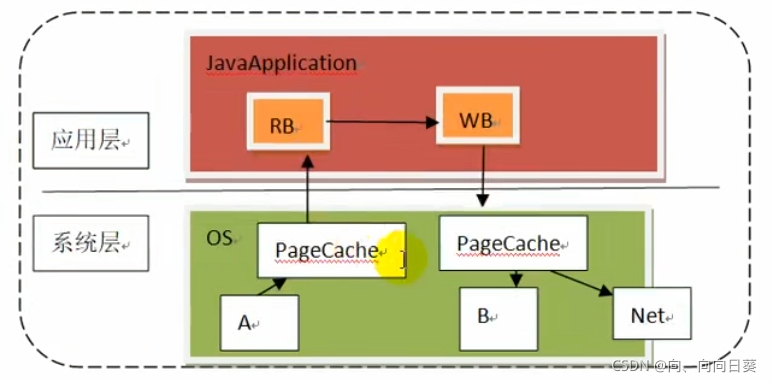
??一般的,从一台主机向网络中传输数据,需要有系统层的操作系统将数据复制到pageCache中,再由JavaApplication中的readBuffer流读入,将数据给到WriteBuffer中,再写回到os的pageCache中,最后将数据传输到网络中,此时数据被复制了四次。如果有10个消费者,总共复制40次;
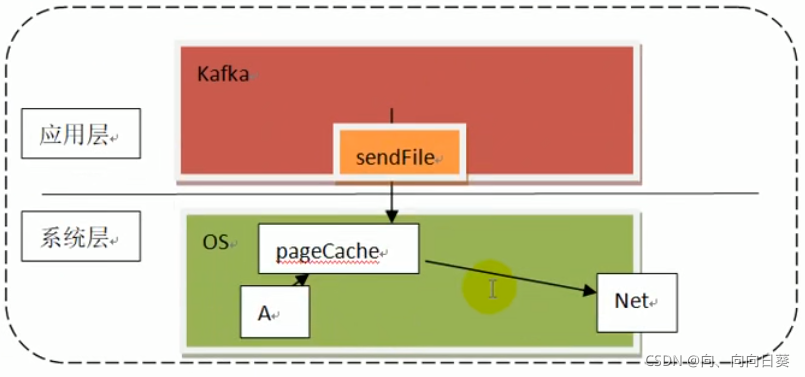
??在kafka中,系统层不需要将数据创传输到应用层,而是由kafka发送一个系统层的消息告诉操作系统这个数据应该发送到哪里去,由操作系统直接发送。此时数据复制了2次。如果有10个消费者,总共复制11次(pageCache中的数据复制一次就可以一直存在)
4.3 Kafka顺写日志、分段日志

??Kafka按照顺序将数据写入到日志文件中比如第一个日志文件000000000000.log存储了10条数据就存满了,那么就会出现第二个日志文件,且偏移量是10,即000000000010.log,如果消费者需要从第十二条数据继续消费,那么不需要读入所有的文件,只需要从第二个日志文件的第二条继续读即可。
总结
??本文主要介绍了Kafka的基本概念,包括:Kakfa的定义、Kafka的架构、Kafka的特点等。在 大数据之Kafka(下)中会介绍有关Kafka的数据生产、消费以及分区的相关知识,如果有不足之处或者表述不当的地方欢迎大家指正。