概述
良好的表结构设计是高性能的基石,应该根据系统将要执行的业务查询来设计,这往往需要权衡各种因素。糟糕的表结构设计,会浪费大量的开发时间,严 重延误项目开发周期,让人痛苦万分,而且直接影响到数据库的性能,并需要花费大量不必要的优化时间,效果往往还不怎么样。
在数据库表设计上有个很重要的设计准则,称为范式设计。
三范式
范式来自英文 Normal Form,简称 NF。要想设计―个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求 得严格。满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
第一范式
1NF,是对属性的原子性约束,要求属性具有原子性,不可再分解。
第一范式强调数据表的原子性,是其他范式的基础。例如下表:

name-age 列具有两个属性,一个 name,一个 age, 不符合第一范式,把它拆分成两列:

上表就符合第一范式关系。但日常生活中仅用第一范式来规范表格是远远不够的,依然会存在数据冗余过大、删除异常、插入异常、修改异常的问题,此时 就需要引入规范化概念,将其转化为更标准化的表格,减少数据依赖。
实际上,1NF 是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如 SQL Server,Oracle,MySQL 中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在 RDBMS 中已经存在的数据表,一定是符合 1NF 的。
第二范式
2NF,是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。通常在实现来说,需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。也就是说要求表中只具有一个业务主键,而且第二范式(2NF)要求实体的属性完全依赖于主关键字。
所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
有两张表:订单表,产品表。
假如一个订单包含多个产品,用如下方式表示:
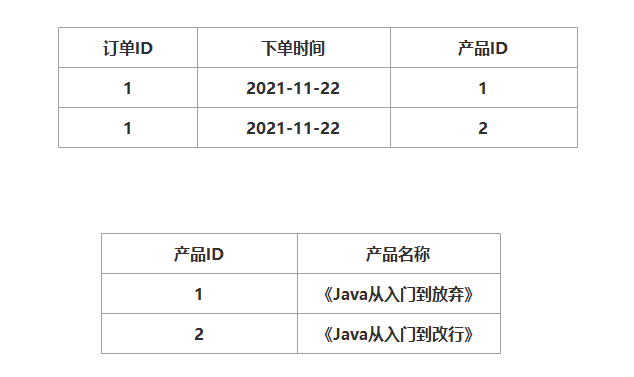
很明显,在订单表中存在 2 条相同的订单 ID 数据,不能确保其唯一性,不满足第二范式,而且产品 ID 和订单 ID 没有强关联,所以正常情况是把订单表进行拆分为订单表与订单与商品的中间表。
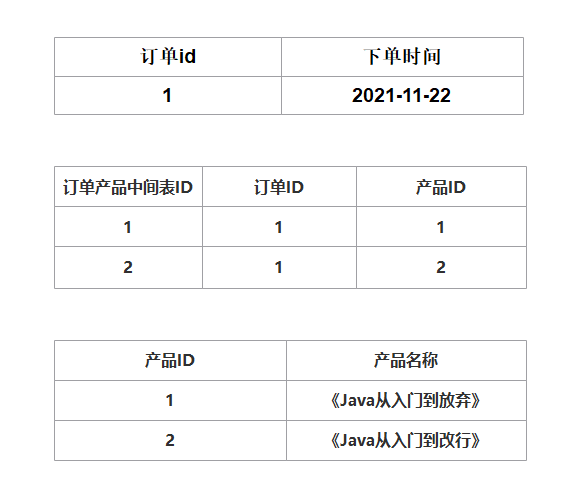
第三范式
3NF,是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
指每一个非非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式也应该构建它,否则就会有大量的数据冗余。
如下:
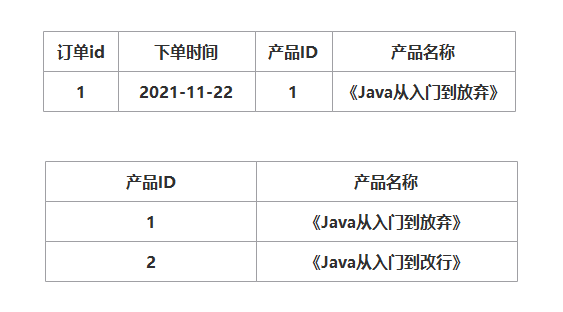
如果产品 ID 发生改变,产品名称也会改变,产品名称发生变化,这样不符合第三范式,应该把产品名称这一列从订单表中删除 。
反三范式
完全符合范式化的设计也不是完美无瑕的,在实际的业务查询中会大量存在着表的关联查询,而大量的表关联很多的时候非常影响查询的性能。
所谓得反范式化就是为了性能和读取效率考虑适当得对数据库设计范式得要求进行违反。允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间。
一些相对来说改变概率较低的,如商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放。
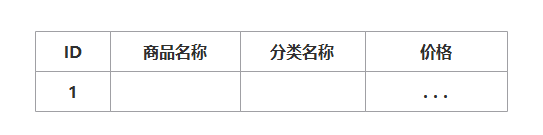
对比
对于范式化设计:
- 优点:可以尽量得减少数据冗余,使得更新快,体积小;
- 缺点:对于查询需要多个表进行关联,减少写得效率增加读得效率,更难进行索引优化。
对于反范式化设计:
- 优点:可以减少表得关联,可以更好得进行索引优化;
- 缺点:数据冗余以及数据异常,数据得修改需要更多的成本。
范式化和反范式化的各有优劣,怎么选择最佳的设计?
一般来说:我全都要,一般来说都是合理的中和两种情况,实际实践中也是这样,并不会完全的范式化和完全的反范式化设计。