���������Ʒ������Դ�����ƽ̨���л�������,����:������ʹ�á���������Hadoop��Ⱥ��ȫ�ֲ�ʽ��װ��Zookeeper��Ⱥ��ȫ�ֲ�ʽ��װ��HBase��ȫ�ֲ�ʽ��װ��Hive��Scala��Spark��Sqoop��Flume�İ�װ�����д�����ָ����
Ŀ¼
-
һ��������ʹ��
�����Ʒ�����,�ٶ��Ʒ�����,��Ѷ�Ʒ�������ѧ����������Ż�,��ֻ��һ̨���������õ�ѧ���Żݷֱ�������ƽ̨������һ̨��������������ݻ�����
1��������(centos7.3)
47.101.62.158��
172.19.46.110˽
2���ٶ���(centos7.3)
180.76.96.39 ��
192.168.0.4˽
3����Ѷ��(centos7.3)
132.232.131.91 ��
172.27.0.13 ˽
4����ȫ��ssh�˿ڿ���
ʹ�÷����������ǹؼ�������������ڸ���ҳ����ȥ������Ч�ʺܵ�,��Xshell����putty����Զ�����ӷ��������в�������������Ҫ���ø���������ȫ���ssh��22�˿�,Ȼ�����Զ�����ӡ�
-
����������
OS:CentOS 7.0+
Զ������:Xshell
| ��� | ���� | IP | ������ | �û��� | ���� |
| 1 | Baidu Cloud | 180.76.96.39 �� 192.168.0.4 ˽ | Hadoop2 | root | *** |
| 2 | Alibaba Cloud | 47.101.62.158 �� 172.19.46.110 ˽ | Hadoop1 | root | *** |
| 3 | Tencent Cloud | 132.232.131.91 �� 172.27.0.13 ˽ | Hadoop3 | root | *** |
Package:
Welcome to The Apache Software Foundation!(Apache����)
Hadoop��Ⱥ��װ(α|ȫ)
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
JDK��װ
�����wget�������ػ������:����:https://blog.csdn.net/weixin_42039699/article/details/82936624
MySQL��װ
https://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.41-linux-glibc2.12-x86_64.tar.gz
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
Pig��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/pig/pig-0.17.0/pig-0.17.0.tar.gz
Hive��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/stable-2/apache-hive-2.3.3-bin.tar.gz
HBase��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.2.7/hbase-1.2.7-bin.tar.gz
Zookeeper��Ⱥ��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
Sqoop��װ
Spark��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
Flume��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/flume/stable/apache-flume-1.8.0-bin.tar.gz
Storm��װ
https://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.2.2/apache-storm-1.2.2.tar.gz
-
����Hadoop3.1.1 ��Ⱥ������װ
�豸:
ʵ���豸���� 3 ̨������(CentOS7.0+)
ʵ�����谲װ��
����:
1.����������
1.1 ��Ⱥ�滮
| ��� | ���� | IP | ������ | �û��� | ���� |
| 1 | Baidu Cloud | 180.76.96.39 �� 192.168.0.4 ˽ | Hadoop2 | root | *** |
| 2 | Alibaba Cloud | 47.101.62.158 �� 172.19.46.110 ˽ | Hadoop1 | root | *** |
| 3 | Tencent Cloud | 132.232.131.91 �� 172.27.0.13 ˽ | Hadoop3 | root | *** |
1.2 ϵͳ��
3̨������(CentOS7.0+)
������װ�������tgzĿ¼��:

1.3 ��������(���������,�Ʒ���������)
Ϊÿ�� Hadoop ����������Ӧ�� IP ��ַ,ÿ̨�IJ���������ͬ��IP ��ַ����
ʵ�黷����������,���ʵ�黷��ʹ�õ��Ƕ�̬ IP ��ַ����������������ò���,������һ��������
1.3.1 �����������ļ�
1������,ȷ���� root �û��½��в�����ͨ�� vi ���������������ļ�
[root@localhost ~]#
vi /etc/sysconfig/network-scripts/ifcfg-eth0
2��Ȼ�� i ������༭ģʽ,������Ҫ�����е� BOOTPROTO=dhcp ��ΪBOOTPROTO=static ��˼������Ϊ��̬ IP,�� ONBOOT=no ��Ϊ ONBOOT=yes ��˼�ǽ��������� Ϊ��������,ͬʱ�������·�������������:
IPADDR= #��̬ IP
GATEWAY= #Ĭ������
NETMASK= #��������
DNS1= #DNS ����
3��������Ժ� Esc ���˳��༭ģʽ,�� Shift + : ���� wq ���б��沢�˳�!�ĺõ����ý�ͼ��
1.3.2 �����������
ͨ�� service network restart �����������,ʹ�ĵ�������Ч
[root@localhost ~]# service network restart
1.3.3 �鿴�����Ƿ��ijɹ�
ͨ�� ifconfig �������鿴��ǰ�� IP ��ַ��Ϣ
ͨ������IJ����Ժ�ֱ���̨ hadoop ���������ø�Ϊ :
hadoop1 IP,hadoop2 IP,hadoop3 IP
1.4 �رշ���ǽ
��̨ hadoop ��������Ҫ�����رշ���ǽ
1������,���� service iptables stop ����ֹͣ����ǽ������,��ͨ������
chkconfig iptables off ����رշ���ǽ��������
2��ִ����������:
[root@localhost ~]# service iptables stop
[root@localhost ~]# chkconfig iptables off
�鿴����ǽ״̬:
[root@localhost ~]# service iptables status
iptables: Firewall is not running.
ע��:
CentOS 7.0+Ĭ��ʹ�õ���firewall��Ϊ����ǽ
�رղ���ֹfirewall��������:
ֹͣ
systemctl stop firewalld.service ?????
��ֹ��������
systemctl disable firewalld.service
����/����Firewalld
#systemctl start firewalld.service
#systemctl restart firewalld.service
��������/�رտ�������
#systemctl enable firewalld.service
#systemctl disable firewalld.service
�鿴״̬
#firewall-cmd --state
���Ŷ˿�:����������ȫ���˿ڱȽ�Σ��,���ױ��ڿ����ռCPU,������Ҫʲô�˿ڴ�ʲô��
firewall-cmd --permanent --zone=public --add-port=10-50010/tcp
firewall-cmd --permanent --zone=public --add-port=10-50010/udp
firewall-cmd --reloa
1.5 ����������
����������Ŀ����Ϊ�˷������,����һ̨ hadoop ���������Ƹ�Ϊ hadoop1,
�ڶ�̨��Ϊ hadoop2,����̨��Ϊ hadoop3������̨ hadoop �����ϰ�����ķ���
��ÿ̨����������
1������,ȷ���� root �û��½��в�����[root@localhost ~]# vi /etc/sysconfig/network
2��Ȼ�� i ������༭ģʽ,�� HOSTNAME=localhost ��Ϊ HOSTNAME=hadoop1
Ҳ���ǽ��û������Ƹ�Ϊ hadoop1������ɺ���Ҫ���� reboot ����������Ч
��������:
[root@localhost ~]# reboot
�鿴��ǰ����������:
[root@localhost ~]# hostname
1.6 �� hosts �ļ�
ÿ̨ hadoop ������������ͬ�� hosts ������¼
1���� hosts �ļ�
[root@hadoop1 ~]# vim /etc/hosts
2���ڵ�������������IJ���
IP hadoop1
IP hadoop2
IP hadoop3
�Ʒ������Hadoop��ȫ�ֲ�ʽhosts���ùؼ�:
��Master��������,Ҫ���Լ���ip���ó�����ip,������һ̨Slave��������ip���ó�����ip
ͬ������Slave��������,Ҫ���Լ���ip���ó�����ip,������һ̨Master��������ip���ó�����ip
1.7ʱ��ͬ������
ntpdate cn.pool.ntp.org
1.8 ���� SSH �������¼
hadoop ��ִ�����ù�����,master ��Ҫ�� salves ���в���,����������Ҫ�� hadoop1 �ڵ����� ssh �������¼ hadoop2��hadoop3.�� hadoop1 ������ִ�����µ�����:
1������ root ����ԱĿ¼,ִ�� ssh-keygen -t rsa һֱ�س�������Կ
[root@hadoop1 ~]# cd ~
[root@hadoop1 ~]# ssh-keygen -t rsa
2������ ~/.ssh Ŀ¼,�����ɺõ���Կͬ���� hadoop2 �� hadoop3 ��,��ִ��
ssh-copy-id �������Ҫ�����Ӧ hadoop ����������
[root@hadoop1 ~]# cd ~/.ssh
[root@hadoop1 .ssh]# ssh-copy-id hadoop2
[root@hadoop1 .ssh]# ssh-copy-id hadoop3
3��ִ��
[root@hadoop1 .ssh]# cat ~/.ssh/id_rsa.pub >~/.ssh/authorized_keys
4����֤ SSH �������¼�Ƿ�ɹ�
�� hadoop1 �����Ͽ��Բ����������뼴��Զ�̷��� hadoop2 �� hadoop3,��֤���������Ժ�ǵ�ʹ�� exit �����˳� ssh ����
��֤�������¼ hadoop2:
[root@hadoop1 .ssh]# ssh hadoop2
�˳� hadoop2 ����:
[root@hadoop2 ~]# exit
��֤�������¼ hadoop3:
[root@hadoop1 .ssh]# ssh hadoop3
[root@hadoop2 ~]# exit
�˳� hadoop3 ����:
[root@hadoop3 ~]# exit
���ܷ�ʽ2:
hadoop1��ִ��:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh-add ~/.ssh/id_dsa
scp ~/.ssh/authorized_keys hadoop2
scp ~/.ssh/authorized_keys hadoop3
ssh-copy-id hadoop2
ssh-copy-id hadoop3
ssh hadoop2
ssh hadoop3
��������:
��װopenssh
1. �
�Ȳ鿴openssh����ذ�rpm -qa openssh*
Ȼ������ж��
��װ yum install -y
yum install -y openssh-7.4p1-16.el7.x86_64;yum install -y openssh-clients-7.4p1-16.el7.x86_64;yum install -y openssh-server-7.4p1-16.el7.x86_64
Ȼ����������ssh����
systemctl start sshd.service
ͨ��ssh-keygen -t rsa��ssh-copy-id -i ������,���ܵ�¼��Ȼ��Ҫ��������������:
Ŀ¼�ļ���Ȩ��
.ssh��Ŀ¼��Ȩ����755,.sshĿ¼Ȩ����700,authorized_keys�ļ� 600

���������⡣
Ŀ¼������?
������淽����û�н������,�ǿ�����.ssh��Ŀ¼�������������⡣
�����.ssh��Ŀ¼(..)�������������⡣
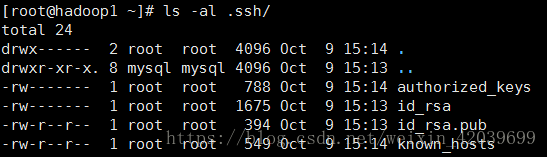
�������:
chown root:root /root
1.9 ��װ JDK ����

��wget����ֱ�����ص�JDK,��������ĸ�Դ��?ȥOracle�������ع�jdk,����֮ǰ��Ҫͬ��Oracle�İ�װЭ��,��Ȼ��������,������wget�ķ�ʽ,Ĭ���Dz�ͬ��,��Ȼ����������,���������������ļ���������,������Linux�Ͻ�ѹһֱʧ�ܡ�ȥ�������غ�,Ȼ����������,�ٽ�ѹ��û�������ˡ�
ʹ��Xshell���ش���JDK����������:
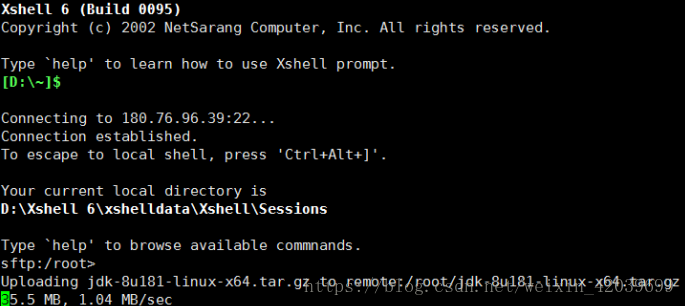
��̨ hadoop ��������Ҫ�������沽�谲װ JDK ����
ע:��װ����Ҫ����������tgzĿ¼��
1������ִ�� java -version �鿴 jdk �Ƿ��Ѿ���װ,������������������ʾ
�Ѿ���װ�������������һ����,���뻷������,��������汾���� java version "1.8.0_181"����Ҫ��������Ӧ�汾
[root@hadoop1]# java -version
2������������λ��,�� jdk ��װ�����Ƶ�/usr/lib/
[root@hadoop1 ~]# cd ~/tgz/
[root@hadoop1 tgz]# cp jdk-8u181-linux-x64.tar.gz /usr/lib
3������/usr/lib Ŀ¼����ѹ jdk-8u181-linux-x64.tar.gz
[root@hadoop1 tgz]# cd /usr/lib
[root@hadoop1 lib]# tar -zxvf jdk-8u181-linux-x64.tar.gz
4���Ļ�������
[root@hadoop1 lib]# vim /etc/profile
������������:
export JAVA_HOME=/usr/lib/jdk1.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
5�����»�������
[root@hadoop1 lib]# source /etc/profile
6��ִ�� java -version �鿴�Ƿ�װ���߸��³ɹ�
[root@hadoop1]# java -version

2.hadoop��Ⱥ��������
ע:��װ����Ҫ����������tgzĿ¼��
2.1 ��װ hadoop3.1.1
����ͨ����hadoop1���а�װhadoop,Ȼ��������Ӧ�������ļ�,���hadooop�����ļ�ͬ�������� hadooop �ڵ�(hadoop2��hadoop3)��Hadoop ·������Ϊ/opt/hadoop-3.1.1
�� hadoop1 ִ�����²���:
1�� ���Ƚ���������Ŀ¼
[root@localhost ~]# cd /opt/tgz/
2��ͨ�� cp ��� hadoop ��װ��(hadoop-3.1.1.tar.gz)���Ƶ�/opt Ŀ¼��
[root@localhost tgz]# cp hadoop-3.1.1.tar.gz /opt/
3�� ����/opt Ŀ¼,����ѹ hadoop-3.1.1.tar.gz ѹ����
[root@localhost tgz]# cd /opt/
[root@localhost opt]# tar -zxvf hadoop-3.1.1.tar.gz
2.2 ���� hadoop �����ļ�
2.2.1 �� core-site.xml �����ļ�
ͨ�� vi ������ core-site.xml �����ļ�,�� <configuration>
</configuration>�м�������������,fs.defaultFS ���������� HDFS ��Ĭ����
�ƽڵ�·�����������ǽ������� HDFS �ļ�ʱ,���û��ָ��·��,�ͻ���ϵ��
�ﶨ���·��������,ȥ��ϵ��̨����ȥѰ����·����
1���� core-site.xml �����ļ�����:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/core-site.xml
2����������:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.1/tmp</value>
</property>
2.2.2 �� hdfs-site.xml �����ļ�
ͨ�� vi ������ hdfs-site.xml �����ļ�,�� <configuration>
</configuration>�м����ӵ� 2 ��������
1���� hdfs-site.xml �����ļ�:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
2����������:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9001</value>
</property>
2.2.3 �� workers �����ļ�
ͨ�� vi ������ workers �����ļ�,����һ�е�localhost�ij�hadoop1,���ڵڶ����м��� hadoop2 �� hadoop3
1���� workers �����ļ�
[root@hadoop1]# vim /opt/hadoop-3.1.0/etc/hadoop/workers
2����������
hadoop1
hadoop2
hadoop3
2.2.4 �� mapred-site.xml �����ļ�
ͨ�� vi ������ mapred-site.xml �����ļ�,�� <configuration>
</configuration>�м����ӵ� 2 ��������
1���� mapred-site.xml �����ļ�����:
[root@hadoop1]# vim /opt/hadoop-3.1.0/etc/hadoop/mapred-site.xml
2����������
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/hadoop-3.1.1/etc/hadoop,
/opt/hadoop-3.1.1/share/hadoop/common/*,
/opt/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/hadoop-3.1.1/share/hadoop/hdfs/*,
/opt/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.1.1/share/hadoop/mapreduce/*,
/opt/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.1.1/share/hadoop/yarn/*,
/opt/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
2.2.5 �� yarn-site.xml �����ļ�
ͨ�� vi ������ yarn-site.xml �����ļ�,�� <configuration>
</configuration>�м����ӵ� 2 ��������
1���� yarn-site.xml �����ļ�����:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/yarn-site.xml
2����������
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
ȡ��yarn����ģʽ�������ڴ���,���������ڴ�ﲻ��Ҫ��Ҳ����kill������
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.2.6 �� hadoop-env.sh �����ļ�
ͨ�� vi ������ hadoop-env.sh �����ļ�,�ڵڶ��������ӵ� 2 ��������
1���� hadoop-env.sh �����ļ�����:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/hadoop-env.sh
2����������
export JAVA_HOME=/usr/lib/jdk1.8
4�����������ļ�
[root@hadoop1 ~]# source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
2.2.7 �� start-dfs.sh �� stop-dfs.sh �����ļ�
1���� start-dfs.sh �����ļ�,�ڵڶ�����������������
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/start-dfs.sh
��������:
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2���� stop-dfs.sh �����ļ�,�ڵڶ�����������������
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/stop-dfs.sh
��������:
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.2.8 �� start-yarn.sh �� stop-yarn.sh �����ļ�
1���� start-yarn.sh �����ļ�,�ڵڶ�����������������
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/start-yarn.sh
��������:
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
2���� stop-yarn.sh �����ļ�,�ڵڶ�����������������
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/stop-yarn.sh
��������:
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
2.2.9 ȡ����ӡ������Ϣ
����ϵͳԤװ�� glibc ��ʱ 2.12 �汾,�� hadoop3.1.0 �ڴ����� 2.14 �汾,��
�Ժ������������ʱ����ӡ������Ϣ,���ǿ�������ȡ����ӡ������Ϣ
1���� log4j.properties �����ļ�,�����������ӵ� 2 ��������
[root@hadoop1 ~]# vim /opt/hadoop-3.1.1/etc/hadoop/log4j.properties
2����������
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
2.2.10 ͬ�� hadoop1 ���õ� hadoop2 �� hadoop3 ��
1��ͬ���Ѿ����úõ� hadoop �ļ��� hadoop2 ��
[root@hadoop1 ~]# cd /opt/
[root@hadoop1 opt]# scp -r hadoop-3.1.1root@hadoop2:/opt/
2��ͬ���Ѿ����úõ� hadoop �ļ��� hadoop3 ��
[root@hadoop1 ~]# cd /opt/
[root@hadoop1 opt]# scp -r hadoop-3.1.0 root@hadoop3:/opt/
2.2.11 ������̨ hadoop ������ profile �ļ�
1���� profile �ļ�,����������ӵ� 2 ���IJ�������
[root@hadoop1 ~]# vim /etc/profile
2����������
#SET HADOOP
HADOOP_HOME=/opt/hadoop-3.1.1
PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_HOME PATH
4�����»�������
[root@localhost ~]# source /etc/profile
[root@localhost ~]# source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
2.3 ��ʽ�� HDFS �ļ�ϵͳ
�� hadoop1 ��ͨ�� hdfs namenode -format ��������ʽ�� HDFS �ļ�ϵͳ
[root@hadoop1 ~]# hdfs namenode -format
��ʾ��ʽ�� HDFS �ļ�ϵͳ���
3.������Ⱥ
3.1 ������Ⱥ
1������ hadoop ��Ⱥ��֤�Ƿ�����������,���뵽/opt/hadoop-3.1.1/sbin/Ŀ
¼��ͨ��./start-all.sh ����ִ������
[root@hadoop1 ~]# cd /opt/hadoop-3.1.1/sbin/
[root@hadoop1 sbin]# ./start-all.sh
2���ڸ� hadoop �ڵ���ִ�� jps ����鿴 hadoop ����
[root@hadoop1 ~]# jps
3��ͨ�� web ���� HDFS �ļ�ϵͳ�� yarn
����ͨ���������ӷ��� hdfs �� yarn
����ip:8088��ip:9870
http://47.101.62.158:8088/cluster
-
�ġ�Zookeeper ��Ⱥ��װ����
����:
1.����������
2.��������
2.1 ��װ zookeeper3.4.10
2.1.1 ���Ƚ���������Ŀ¼
[root@hadoop1 ~]# cd tgz/
2.1.2 �� zookeeper ��װ��(zookeeper-3.4.10.tar.gz)��ѹ��/opt Ŀ¼��
[root@hadoop1 tgz]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/
2.1.3 ��ѹ��ɺ��ڻ������������� Zookeeper �İ�װ·��,���������ļ�,ʹ������Ч��
[root@hadoop1 tgz]# vi /etc/profile
������������:
#SET ZOOKEEPER
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
�˳���ִ�� source /etc/profile ������»�������
[root@hadoop1 opt]# source /etc/profile
2.2 ���� zookeeper �����ļ�
1������ zookeeper �����ļ�Ŀ¼:
[root@hadoop1]# cd /opt/zookeeper-3.4.10/conf
2������ zoo_sample.cfg �ļ�Ϊ zoo.cfg
[root@hadoop1]# cp zoo_sample.cfg zoo.cfg
3������������ݵ��ļ���:
[root@hadoop1 conf]# mkdir /opt/zookeeper-3.4.10/data
4������ myid �ļ�,���������� 0 (���ڵ�Ϊ 0,�ӽڵ�ֱ�Ϊ 1,2)
[root@hadoop1 conf]# vi /opt/zookeeper-3.4.10/data/myid
5���� zoo.cfg �����ļ�
[root@hadoop1 conf]# vi /opt/zookeeper-3.4.10/conf/zoo.cfg
�������ļ��� dataDir ��·����Ϊ/opt/zookeeper-3.4.10/data
���ڵײ��м������²���:
server.0=hadoop1:2888:3888
server.1=hadoop2:2888:3888
server.2=hadoop3:2888:3888
zoo.cfg �������
tickTime:��������ͻ���֮�佻���Ļ���ʱ�䵥Ԫ(ms)
initLimit:���� follower ���Ӳ�ͬ���� leader �ij�ʼ��ʱ��,���� tickTime
�ı�������ʾ�����������ñ����� tickTime ʱ��,������ʧ��
syncLimit:Leader �������� follower ������֮����Ϣͬ�����������ʱ���
��,��������μ��,Ĭ�� follower �������� leader ������֮��Ͽ�����
dataDir:���� zookeeper ����·��
clientPort:�ͻ��˷��� zookeeper ʱ������������ʱ�Ķ˿ں�
2.2.2 �ļ�ͬ��
1���� hadoop1 �����úõ� zookeeper �ļ�ͬ���� haoop2��hadoop3 �ڵ���:
[root@hadoop1]# scp -r /opt/zookeeper-3.4.10/ root@hadoop2:/opt
[root@hadoop1]# scp -r /opt/zookeeper-3.4.10/ root@hadoop3:/opt
2���� hadoop1 �Ļ�������ͬ���� haoop2��hadoop3 �ڵ���::
[root@hadoop1]# scp -r /etc/profile/ root@hadoop2:/etc/profile
[root@hadoop1]# scp -r /etc/profile/ root@hadoop3:/etc/profile
3���������ڵ���ʹ������Ч:
[root@hadoop2]# source /etc/profile
[root@hadoop3]# source /etc/profile
4���� hadoop2 �� hadoop3 �ϵ� myid
�� hadoop2 �Ͻ� myid ��Ϊ 1
��������:
[root@hadoop2]# vi /opt/zookeeper-3.4.10/data/myid
hadoop1 �µ� myid:
hadoop2 �µ� myid
hadoop3 �µ� myid
���� zookeeper ��Ⱥ������
3.1 ���� zookeeper
1���ֱ����� hadoop1��hadoop2��hadoop3 �ڵ�� zookeeper ��Ⱥ����
[root@hadoop1]# zkServer.sh start
[root@hadoop2]# zkServer.sh start
[root@hadoop3]# zkServer.sh start
2���鿴�Ƿ������ɹ�����:
[root@hadoop1]# zkServer.sh status
����:
1.ִ��zkServer.sh start ����ʾ:
JMX enabled by default
Using config:/home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.jps����û��QuorumPeerMain����
3.�鿴zookeeper-3.4.5/data�µ�zookeeper-3.4.5.out,�����ʾ?binding to port 0.0.0.0/0.0.0.0:2181
ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally?java.net.BindException: Address already in use
˵��2181�˿ڱ�ռ��,ͨ��netstat -nltp | grep 2181����Ƿ��ѱ�ռ��,�������Ѷ�Ӧ�Ľ���kill��(kill ���̵�pid),Ȼ��������zookeeper
4..jps������QuorumPeerMain����,Ȼ��ִ��zkServer.sh status,�����ʾ:
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
˵��δ�����ɹ�,ͨ���鿴zookeeper-3.4.5.out,�����ʾ
Cannot open channel to 1 at election address hadoop05/10.37.129.105:3888
java.net.NoRouteToHostException: No route to host,˵��������Զ�̵���10.37.129.105:3888,���п��ܿ����˷���ǽ
ͨ��sudo service iptables status���,���ȷʵ����,��ͨ��sudo service iptables stop����ر�,����ٲ鿴״̬zkServer.sh status
��ʱ,�������ܹ�����������,��ʾ:
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader(��follower)
#�鿴�˿���û�б�ռ��
netstat -ntpl | grep �˿ں�
Top�鿴����
Kill -9 ����
-
�塢Hbase ��ȫ�ֲ�ʽ��װ
����:
1.1 ��ѹ��װ�� hbase
1.1.1 ���Ƚ���������Ŀ¼
[root@hadoop ~]# cd tgz/
1.1.2 ��ѹ��װѹ���� �� hbase ��װ��(hbase-1.2.7-bin.tar.gz)��ѹ���� /opt Ŀ¼��
[root@hadoop tgz]# tar -zxvf hbase-1.2.7-bin.tar.gz -C /opt
1.1.3 ���뵽/opt Ŀ¼
[root@hadoop ~]# cd /opt
1.1.4 ����ѹ�İ�װ��������
[root@hadoop ~]# mv hbase-1.2.7 /opt/hbase
1.1.5 ���û������� ���� hbase �İ�װ·��
[root@hadoop conf]# vi /etc/profile
���ļ�����ײ�������������
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
������ͼ:
�˳���ִ�� source /etc/profile ������»�������
[root@hadoop conf]# source /etc/profile
1.2:� Hbase α�ֲ�ģʽ
hadoop1
NameNode
DataNode
NodeManager
ResourceManager
SecondaryNameNode
HMaster
QuorumPeerMain
HRegionServer
1.2.1 �������� 1.1 ��ѹ������뵽�����ļ� conf Ŀ¼
[root@hadoop opt]# cd /opt/hbase/conf/
1.2.2 �༭ hbase-site.xml
[root@hadoop conf]# vi hbase-site.xml
��������
?<property>
?<name>hbase.rootdir</name>
?<value>hdfs://localhost:9000/hbase</value>
?</property>
?<property>
?<name>hbase.cluster.distributed</name>
?<value>true</value>
</property>
���ò���˵��:
hbase.rootdir:�ò����ƶ��� HReion ��������λ��,�����ݴ�ŵ�λ�á���Ҫ�˿�
��Ҫ�� Hadoop ��Ӧ����һ�¡�
hbase.cluster.distributed:HBase ������ģʽ��false �ǵ���ģʽ,true �Ƿֲ�ʽģʽ��
��Ϊ false, HBase �� Zookeeper ��������ͬһ�� JVM ���档Ĭ��Ϊ false��
1.2.3 �༭ hbase-env.sh ���� JAVA_HOME
[root@hadoop conf]# vi hbase-env.sh
�� export JAVA_HOME=/usr/lib/jdk1.8/
�����:
1.2.4 ���� hbase
���뵽 hbase �� bin Ŀ¼
[root@hadoop conf]# cd /opt/hbase/bin/
���� hbase
[root@hadoop bin]# ./start-hbase.sh
1.3:� Hbase ��ȫ�ֲ�ģʽ
��� ���� ��ɫ Ip ������ �˻� ����?
hadoop1
NameNode
ResourceManager
HMaster
QuorumPeerMain
hadoop2
DataNode
NodeManager
HRegionServer
QuorumPeerMain
hadoop3
NodeManager
DataNode
HRegionServer
QuorumPeerMain
1.3.1 ��ȫ���úõ� hadoop ��Ⱥ(��Ҫ����)
�ο� hadoop ��ȫ�ֲ�ʽ�
1.3.2 ��ȫ���úõ� zookeeper ��Ⱥ(��Ҫ����)
�ο� zookeeper ��ȫ�ֲ�ʽ�
1.3.3 �������� 1.1 ��ѹ������뵽�����ļ� conf Ŀ¼
[root@hadoop1 opt]# cd /opt/hbase/conf/
����ͼ:��Ҫ�� hbase-site.xml��regionservers��hbase-env.sh ���������ļ�
1.3.4 �༭ hbase-site.xml
[root@hadoop1 conf]# vi hbase-site.xml
������������
<configuration>
?<property>
?<name>hbase.rootdir</name>
?<value>hdfs://hadoop1:9000/hbase</value>
?</property>
?<property>
?<name>hbase.cluster.distributed</name>
?<value>true</value>
?</property>
?<property>
?<name>hbase.zookeeper.quorum</name>
?<value>hadoop1,hadoop2,hadoop3</value>
?</property>
</configuration>
���ò���˵��:
������������ļ���,��һ������ָ�������� hbase �Ĵ洢Ŀ¼;�ڶ�������ָ�� hbase ������
ģʽ,true ����ȫ�ֲ�ģʽ;���������ǹ��� Zookeeper ��Ⱥ�����á��ҵ� Zookeeper ��װ�� hadoop1
�� hadoop2��hadoop3 �ϡ�
1.3.5 �� regionservers
[root@hadoop1 conf]# vi regionservers
�� regionservers �ļ��������������� (ɾ��ԭ������� localhost)
hadoop2
hadoop3
1.3.7 �༭ hbase-env.sh ���� JAVA_HOME
[root@hadoop conf]# vi hbase-env.sh
�� export JAVA_HOME=/usr/lib/jdk1.8/
�� export HBASE_MANAGES_ZK=false (ʹ�������Լ���� zookeeper ��Ⱥ)
1.3.8 ���� hadoop1 �����úõİ�װ���ַ��� hadoop2 �� hadoop3 ��
scp -r /opt/hbase/ hadoop2:/opt
scp -r /opt/hbase/ hadoop3:/opt
1.3.9 ���� hbase ��Ⱥ
�� hadoop1 �Ͻ��뵽 hbase �� bin Ŀ¼
[root@hadoop conf]# cd /opt/hbase/bin/
���� hbase
[root@hadoop bin]# ./start-hbase.sh
��ÿ���ڵ��Ϸֱ��� jps �鿴����
hadoop1 �� HMaster
hadoop2 �� HRegionServer
hadoop3 �� HRegionServer
2:Hbase ��������
2.1��Hbase Shell ����
ʹ�� hbase shell �����������������е� Hbase ʵ�� �������� 1 �������úû�������
�����ֱ�������������� hbase shell ������ hbase
�����ɹ�����:
2.2:��ʾ HBase Shell �����ĵ�
���� help ���� Enter ��,������ʾ HBase Shell �Ļ���ʹ����Ϣ
2.3:�˳� HBase Shell
ʹ�� quit ����,�˳� HBase Shell ���ҶϿ��ͼ�Ⱥ������,����ʱ HBase ��Ȼ�ں�̨��
��,Ҳ����ֱ�� ctrl+c
2.4:�鿴 HBase ״̬ ֱ������ status �س�
3��hbase ���ݶ���(DDL)����
3.1:�����±�
ʹ�� create ����������һ���µı����ڴ�����ʱ��,����ָ����������������
create 'user', 'info '
3.2: �оٱ���Ϣ
ʹ�� list ����
list 'user'
3.3:��ȡ������
ʹ�� describe ����
describe 'user'
3.4:�����Ƿ����
ʹ�� exists ����
exists 'user'
�������ͼ����:
3.5:ɾ����
ɾ����֮ǰ,�� disable ��,��ʹ�� drop ����ʵ��ɾ�����Ĺ���
drop 'user'
�������ͼ����:
4�����ݹ���(DML)����
4.1:���������� 3 ��ɾ���� user ��,���´���һ�� user ��
create 'user', 'info'
4.2:����������
ʹ�� put ����,�����ݲ������:
put 'user', 'row1', 'info:a', 'value1'
4.3:һ����ɨ��ȫ������
һ�ֻ�ȡ HBase ���ݵķ�����ɨ��,ʹ�� scan ������ɨ��������ݡ�(��������ɨ���
��Χ)
scan 'user'
4.4:��ȡһ��������
ʹ�� get ���������ijһ�е�����:
get 'user', 'row1'
4.5:����һ����
�������Ҫɾ��һ������������������,���������������,����Ҫ���Ƚ��øñ���
ʹ�� disable ������ñ�,enable �����������ñ���
disable 'user'
enable 'user'
����ͼ��ʾ:
6:ɾ������
ɾ�����е�ij����ֵ
# �:delete <table>, <rowkey>, <family:column> , <timestamp>
delete 'user','rowkey001','info:a'
ɾ����
# �:deleteall <table>, <rowkey>, <family:column> , <timestamp>
deleteall 'user','row1'
ɾ�����е���������
# �: truncate <table>
truncate 'user'
-
����Hive��װ
1.��װMysql
1.1���Ƚ���������Ŀ¼
[root@hadoop1 ~]# cd tgz/
1.2��ѹ��mysql��/usr/localĿ¼
[root@hadoop1 haoodp-install]# tar -zxvf mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
1.3���뵽/usr/localĿ¼��������
[root@hadoop1 haoodp-install]# cd /usr/local/
[root@hadoop1 local]# mv mysql-5.6.40-linux-glibc2.12-x86_64 mysql?
1.4�������û�
[root@hadoop1 local]# groupadd mysql
�����û�mysql ���û���mysql
[root@hadoop1 local]# useradd -g mysql mysql
1.5��װmysql
Centos7��Ĭ�����ݿ�mysql�滻����Mariadb
[root@localhost?~]#?rpm?-qa|grep?mariadb??//?��ѯ�����Ѱ�װ��mariadb??
[root@localhost?~]#?rpm?-e?--nodeps?�ļ���??//?ж��mariadb,�ļ���Ϊ���������ѯ�������ļ�??
yum remove mariadb
rm -rf /etc/my.cnf
rm -rf /var/lib/mysql/
?yum --setopt=tsflags=noscripts remove MariaDB-client.x86_64;
ɾ��etcĿ¼�µ�my.cnf
1.5.1���뵽��װ��Ŀ¼
[root@hadoop1 local]# cd /usr/local/mysql
1.5.2����dataĿ¼��mysql�ļ���
[root@hadoop1 mysql]# mkdir ./data/mysql
cd data
chown -R mysql:mysql mysql
��������:
yum install -y perl perl-devel autoconf
yum install -y libaio.so.1
yum remove libnuma.so.1
yum -y install numactl.x86_64
1.5.3��Ȩ��ִ�нű�
[root@hadoop1 mysql]#?chown -R mysql:mysql ./
[root@hadoop1 mysql]# chown -R mysql:mysql /usr/local/mysql
[root@hadoop1 mysql]# ./scripts/mysql_install_db --user=mysql --datadir=/usr/local/mysql/data/mysql
��������������²���yum install -y perl-Module-Install.noarch,Ȼ����./scripts/mysql_install_db --user=mysql --datadir=/usr/local/mysql/data/mysql
1.5.4����mysql�����ļ���/etc/init.dĿ¼�²�������
[root@hadoop1 mysql]# cp support-files/mysql.server /etc/init.d/mysqld
1.5.5�ķ����ļ�Ȩ��
[root@hadoop1 mysql]# chmod 777 /etc/init.d/mysqld
1.5.6����mysql�������ļ���������
[root@hadoop1 mysql]# cp support-files/my-default.cnf /etc/my.cnf
1.5.7��mysql�����ű�
[root@hadoop1 mysql]# vi /etc/init.d/mysqld
����������
basedir=/usr/local/mysql/
datadir=/usr/local/mysql/data/mysql
1.5.8���û������� ����mysql�İ�װ·��
[root@hadoop1 conf]# vi /etc/profile?
���ļ�����ײ�������������
export PATH=$PATH:/usr/local/mysql/bin
�˳���ִ��source /etc/profile������»�������
[root@hadoop1 conf]# source /etc/profile
1.5.10��mysql����Զ�̵�¼
[root@hadoop1 mysql]# vi /etc/my.cnf
��[mysqld]�����
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port=3306
server_id=1
socket=/tmp/mysql.sock
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
1.5.11��ʼ��mysql
[root@hadoop1 mysql]# /usr/local/mysql/scripts/mysql_install_db --user=mysql
1.5.12����mysql����
[root@hadoop1 mysql]# service mysqld start
�鿴mysql����״̬
[root@hadoop1 ~]# service mysqld status
1.5.13��¼mysql
[root@hadoop1 ~]# mysql -u root -p
��һ�ε�¼����Ҫ����,ֱ�ӻس�
1.5.14���ñ���mysql�û���������
mysql> use mysql;
mysql>?update user set password =password('root') where user ='root';?
1.5.15����Զ�̵�¼�û�
mysql>?GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
1.5.14����hive���ݿ�,���洢hiveԪ������Ϣ
mysql>create database hive;
����ֱ��Ctrl+c �˳�mysql����exit
2.��װHive
2.1���Ƚ���������Ŀ¼
[root@hadoop ~]# cd tgz/
2.2��ѹ��װѹ����? ��hive��װ��(apache-hive-2.3.3-bin.tar.gz)��ѹ����/optĿ¼��
[root@hadoop tgz]#?tar -zxvf?apache-hive-2.3.3-bin.tar.gz?-C /opt
2.3���뵽/optĿ¼
[root@hadoop ~]# cd? /opt
2.4����ѹ�İ�װ��������
[root@hadoop opt]# mv?apache-hive-2.3.3-bin?hive
2.5���û������� ����hive�İ�װ·��
[root@hadoop conf]# vi /etc/profile?
���ļ�����ײ�������������
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
�˳���ִ��source /etc/profile������»�������
[root@hadoop conf]# source /etc/profile
2.6.����hive
2.6.1?���뵽hive�������ļ�Ŀ¼
[root@hadoop opt]# cd /opt/hive/conf/
2.6.2?����hive-env.sh.template һ�ݲ�������Ϊhive-env.sh
[root@hadoop conf]# cp hive-env.sh.template hive-env.sh
��hive-env.sh,���ü���HADOOP_HOME=/opt/hadoop-3.1.1
[root@hadoop conf]# vi hive-env.sh
2.6.3?�½�hive-site.xml
[root@hadoop conf]# vi hive-site.xml
��Ҫ�� hive-site.xml �ļ������� MySQL ���ݿ�������Ϣ �����������ݵ��½��ļ���
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
2.6.4?����mysql������ ��mysql�����ŵ�hive��װ·����libĿ¼��
[root@hadoop1]# cp?tgz/mysql-connector-java-5.1.47.jar /opt/hive/lib/
2.6.5 hive������ǰ������Ԫ���ݳ�ʼ��
[root@hadoop1 conf]# schematool -dbType mysql -initSchema
����schemaTool completed ���ʼ�����?

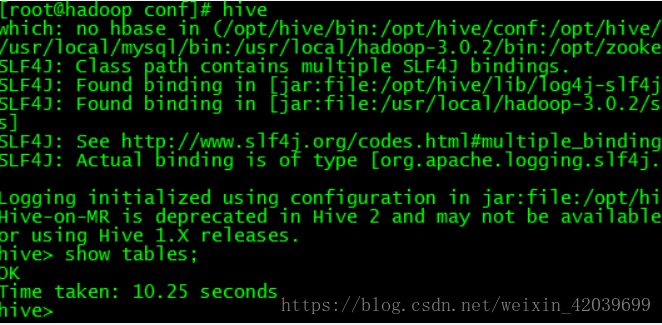
���hive �Ƿ�ɹ� ֱ��������������hive����hive (��Ҫhadoop��װ������)
�����ɹ�����:
-
�ߡ�Scala��װ
scala����:https://www.scala-lang.org/download/
https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
��ѹ��/opt��
vim /etc/profile
export PATH=$PATH:/opt/scala/bin
source?/etc/profile
$?scala
-
�ˡ�Spark��װ
��װǰ��
Java1.8? ? ? ?zookeeper? hadoop? ? ? ?Scala? ? ? ? ?
��Ⱥ�滮
?�� ��Ⱥ��װ
1? ��ѹ��
tar zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /opt/
mv spark-2.3.1-bin-hadoop2.7 spark
2? �������ļ�
(1)���������ļ�����Ŀ¼cd /opt//spark/conf/
(2)����spark-env.sh.template��������Ϊspark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
�༭�����ļ�ĩβ����������������
export JAVA_HOME=/usr/lib/jdk1.8
#ָ��Ĭ��master��ip��������
export SPARK_MASTER_HOST=hadoop1
#ָ��master�ύ�����Ĭ�϶˿�Ϊ7077
export SPARK_MASTER_PORT=7077
#ָ��master�ڵ��webui�˿�
export SPARK_MASTER_WEBUI_PORT=8080
#ÿ��worker�ӽڵ��ܹ�֧����ڴ���
export SPARK_WORKER_MEMORY=1g ???????
#����SparkӦ�ó����ڼ������ʹ�õĺ�������(Ĭ��ֵ:���п��ú���)
export SPARK_WORKER_CORES=1
#ÿ��worker�ӽڵ��ʵ��(��ѡ����)
export SPARK_WORKER_INSTANCES=1
#ָ�����Hadoop��Ⱥ��(�ͻ���)�����ļ���Ŀ¼,������Yarn�����ô���
export HADOOP_CONF_DIR=/opt/hadoop-3.1.1/etc/hadoop
#ָ��������Ⱥ״̬��ͨ��zookeeper��ά����,������Ⱥ�ָ�
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181
-Dspark.deploy.zookeeper.dir=/spark"
cd /opt/spark/conf
cp log4j.properties.template log4j.properties
Log4j.rootCategory=INFO, console��Ϊ
Log4j.rootCategory=WARN, console
(3)����slaves.template��slaves,������������
cp slaves.template slaves
vi slaves
�Ĵӽڵ�
hadoop1
hadoop2
hadoop3
(4)����װ���ַ��������ڵ�
��hadoop2�ڵ���conf/spark-env.sh���õ�MasterIPΪSPARK_MASTER_IP=hadoop2
��hadoop3�ڵ���conf/spark-env.sh���õ�MasterIPΪSPARK_MASTER_IP=hadoop3
3? ���û�������
���нڵ��Ҫ����
vi /etc/profile
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile
�� ������Ⱥ
1 ����zookeeper��Ⱥ
����zookeeper�ڵ��Ҫִ��
zkServer.sh start
2 ����Hadoop��Ⱥ
3 ����Spark��Ⱥ
����spark:����master�ڵ�:sbin/start-master.sh ����worker�ڵ�:sbin/start-slaves.sh
����:sbin/start-all.sh
ע��:����master�ڵ�hadoop2,hadoop3��Ҫ�ֶ�����
sbin/start-master.sh
4 �鿴����
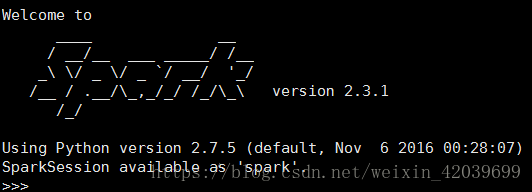
����spark
cd /opt/spark/bin
./pyspark
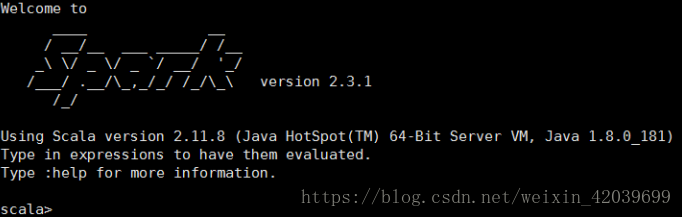
./spark-shell
-
�š�Sqoop��װ
1.��ѹ��
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/
cd /opt/
������mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
2.�Ļ�������vi /etc/profile
export SQOOP_HOME=/opt/sqoop
export PATH=$SQOOP_HOME/bin:$PATH
source /etc/profile
3.��MySQL������������lib��
4.��sqoop-env-template.sh,����HADOOP_HOME��HBASE_HOME��HIVE_HOME·��
vim sqoop-env-template.sh
-
#Set path to where bin/hadoop is available
-
export HADOOP_COMMON_HOME=
-
#Set path to where hadoop-*-core.jar is available
-
export HADOOP_MAPRED_HOME=
-
#set the path to where bin/hbase is available
-
export HBASE_HOME=
-
#Set the path to where bin/hive is available
-
export HIVE_HOME=
5.��$SQOOP_HOME/bin/configure-sqoop
ע�͵�HCatalog,Accumulo���(��������ʹ��HCatalog,Accumulo��HADOOP�ϵ����)?
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HCAT_HOME}" ]; then
# echo "Warning: $HCAT_HOME does not exist! HCatalog jobs willfail."
# echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
#fi
#if [ ! -d "${ACCUMULO_HOME}" ];then
# echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports willfail."
# echo 'Please set $ACCUMULO_HOME to the root of your Accumuloinstallation.'
#fi?
ִ��:sqoop version
��������:��ʾmysql���ݿ��б�:
sqoop list-databases --connect jdbc:mysql://ip:3306/ --username hive --password hive
��ʾ���ݿ������б�:
sqoop list-tables --connect jdbc:mysql://ip:3306/hive --username hive --password hive
-
ʮ��flume��װ
����
centos:7.3
JDK:1.8
Flume:1.8
һ��Flume ��װ
1������
wget?http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
?2����ѹ
tar �Czxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin /usr/local/flume
3�����û�������
export FLUME_HOME=/opt/flume
export PATH=$FLUME_HOME/bin:$PATH
Source /etc/profile
?4������java_home
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/usr/lib/jdk1.8
export HADOOP_HOME=/opt/hadoop-3.1.1
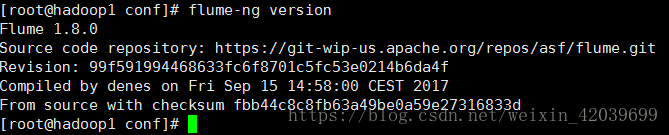
�鿴�汾:flume-ng version
���˴����ݻ���ƽ̨��������,�����ھ��������ļ�������������䡣���Ľ����ο�,���д���,��ָ�����м�����!
ҵ������벻���Ʒ�����,ѡ����ʵ�ƽ̨����Ҫ!
��Ŀǰ�����Ƽ����г��ĸ������,�����Ƽ���ǰ��ǿ�ֱ��ǰ����ơ���Ѷ�ƺͻ�Ϊ��,�����ơ���Ѷ����Ϊ����������ƽ̨����ҵ,��ƫ����B���û�;��Ϊ����Ϊ��ͳ��ͨ�ž�ͷ,��ƫ����G�ˡ�
���˴����Ƽ�����ع����������ж���,������������ƽ̨���Ӵ���,�������ǵ����ۼ������Ŷ�,�Ը��ҵIJ�ƷҲС���˽�,����ָ�������ټ���ҵǨ������,����ƽ̨ѡ��Ҳ��һ���ķ���Ȩ!
�����кܶ�����,��������Ҳ�廨����,˵˭�õĶ���,�����ƪ���ķ������ܵķdz���ϸ,���������,�ĵ���ַ:
����1:�Ʒ������ļҺ�!�����ơ���Ѷ�ơ���Ϊ�Ƶķ��������ü��۸�Ա�??
����2:�����Ʒ�����ͻ����t6��n4��s6��c5��c6��ôѡ?����Ѷ�Ʒ���������s3��sn3ne��s4��s5��sa2����ļҺ�?ȫ�����
����Ǹ߲���,��IOҵ��,��Ҫȷ�����������,����ҵ��Ӧ�����ܷ��ӵ����,�ο��ٷ��ĵ�:
�����Ʒ��������:���ʵ���� - �Ʒ����� ECS
��Ѷ�Ʒ��������:���ʵ���� - �Ʒ�����CVM