随机函数
clickhouse 是一款性能极高的OLAP数据库,由于不像传统OLTP数据库(诸如 MySQL,Oracle 等),它没有函数,没有存储过程,更没有循环语句。因此创建随机值的方式,也多少与众不同,今天我就来说说它的用法。
首先,输入 /usr/bin/clickhouse-client --host localhost --port 9000 进入命令行模式
整型
在键入 SELECT rand 后,按回车,会有提示
一共有4种
- rand
- rand32
- rand64
- randConstant

要注意随机数种子,因为 rand 是伪随机的。由于机制一样,如果没有设置不同的种子,同一次循环,得到的数值都会相同
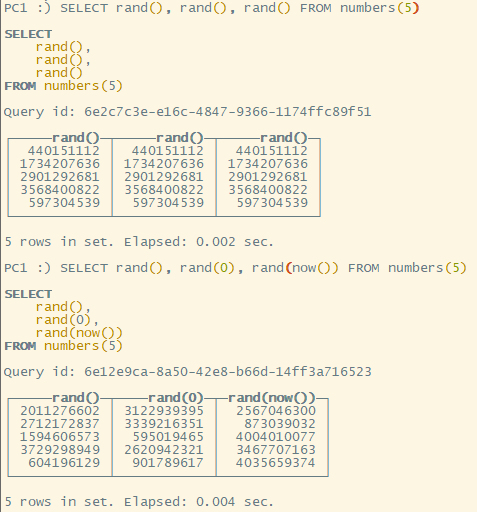
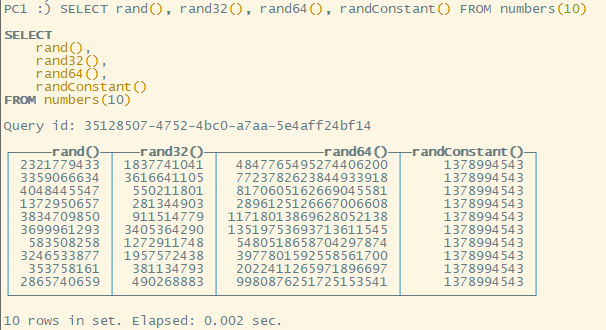
randConstant()在同一条 sql 中,得到的值都保持一致。
测试语句为:SELECT rand(), rand32(), rand64(), randConstant() FROM numbers(10)
浮点
由于clickhouse没有提供随机浮点数的方法,只能用一些方式来模拟
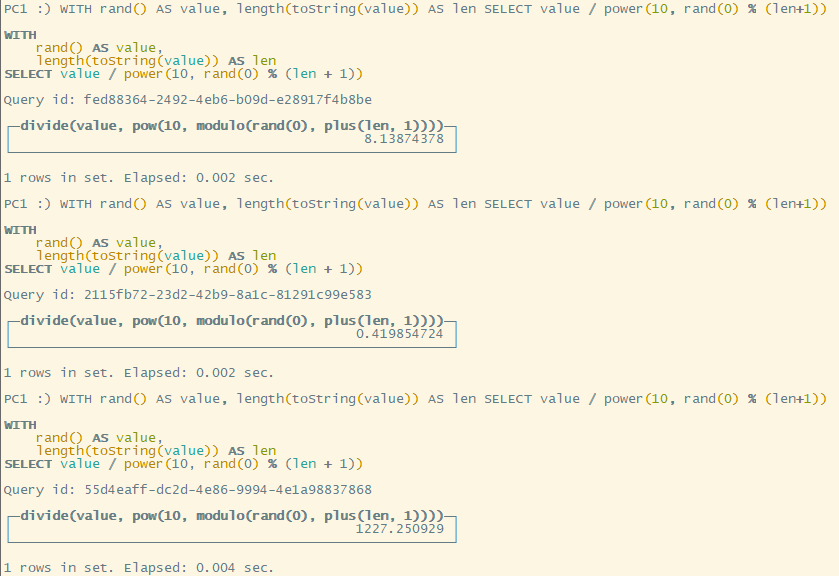
- 随机一个整数,然后随机一个位置插入小数点
WITH rand() AS value, length(toString(value)) AS len SELECT value / power(10, rand(0) % (len+1))
WITH <值> AS <变量>用在查询函数的最前面,用来定义变量length(<字符串>)用来获取字符串长度toString()可以将对象转为字符串FROM numbers(n)可以用来做循环使用
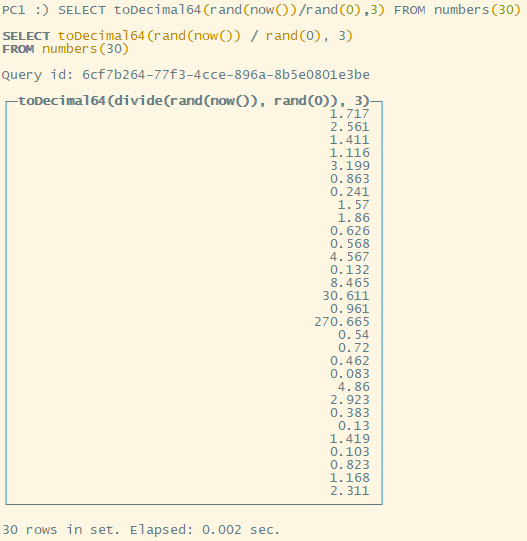
toDecimal64(rand(now()) / rand(0), 3)
语法为:toDecimal(<浮点数>, <保留几位小数>)
字符串
自带的方法
clickhouse 自带的字符串随机方法有4个
- randomFixedString
- randomString
- randomPrintableASCII
- randomStringUTF8
使用命令,循环打印这几个函数试试
WITH 10 AS len SELECT randomFixedString(len), randomString(len), randomPrintableASCII(len), randomStringUTF8(len) FROM numbers(20)
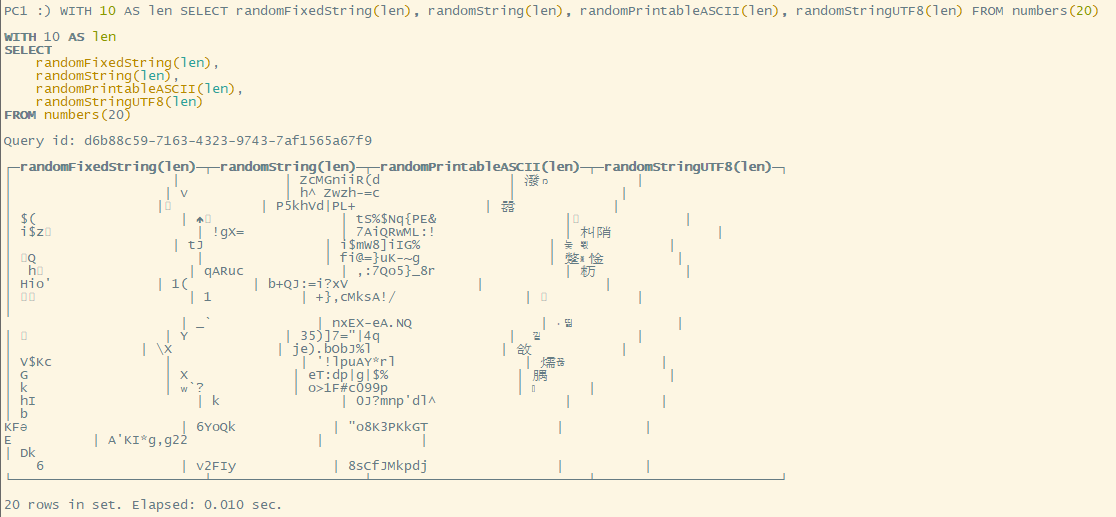
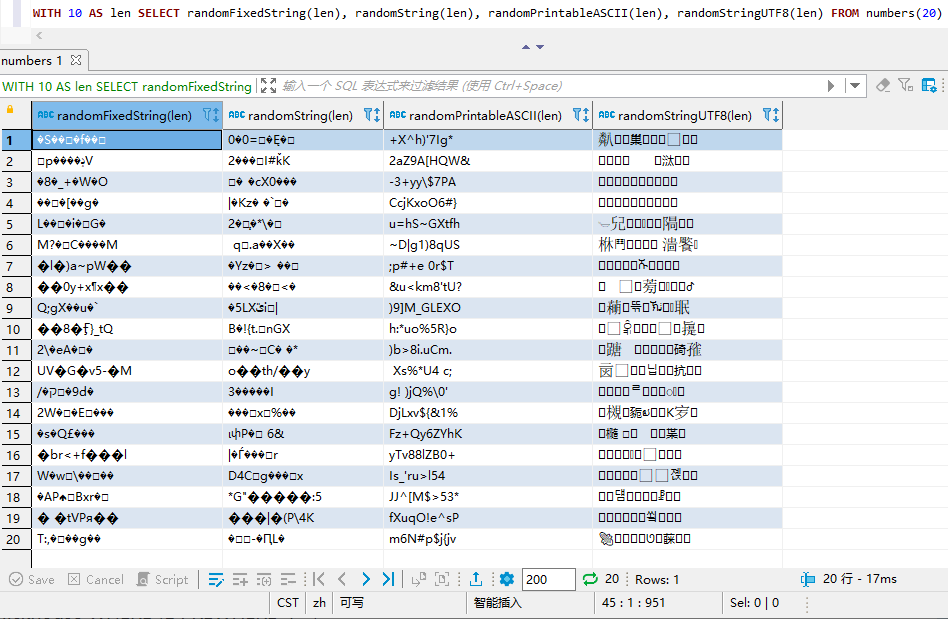
由于命令行界面无法对齐,用DBeaver查看格式化后的数据。可以发现:除了randomPrintableASCII()其它都含有很多乱码
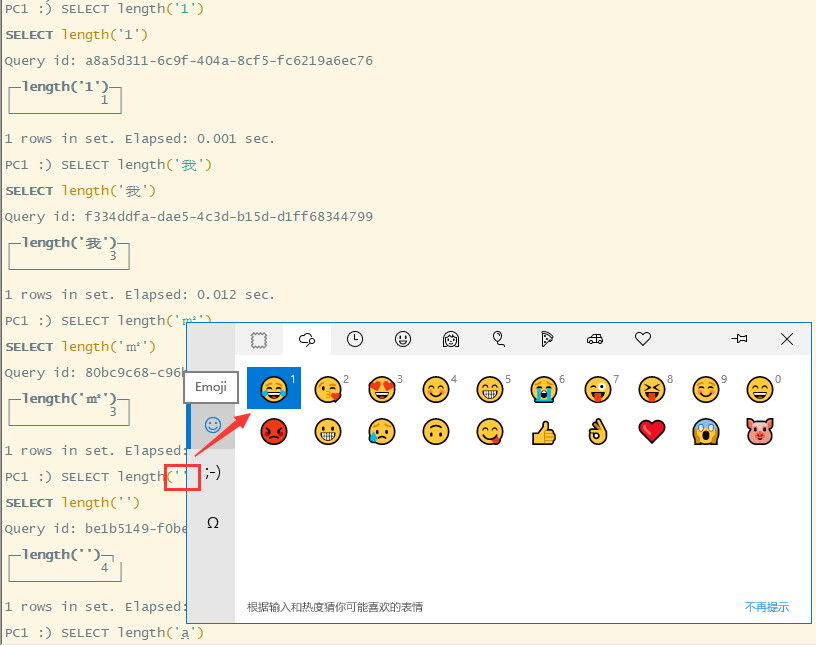
通过测试可以看出,length()函数返回的不是字符串长度,而是字符串所占的字节长度
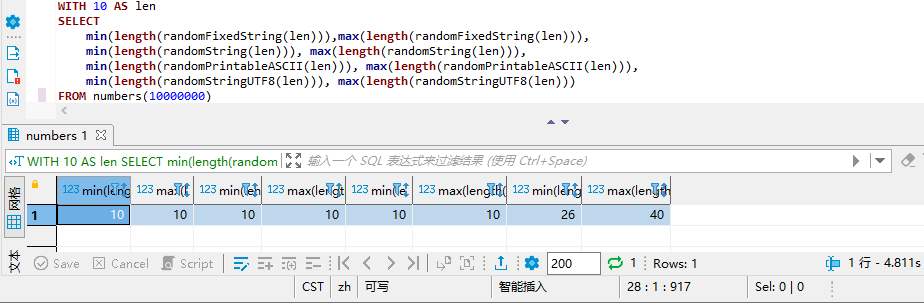
再来看一下随机字符串们的长度。可以发现length(<字符串长度>)得到的是字符串所占用的字节长度,而非字符串长度 - 前面3个,指定n位长度的字符,每个字符仅占用1字节
- UTF8的每个字符占用1-4个字节,所以只有它的长度是不固定的
WITH 10 AS len
SELECT
min(length(randomFixedString(len))),max(length(randomFixedString(len))),
min(length(randomString(len))), max(length(randomString(len))),
min(length(randomPrintableASCII(len))), max(length(randomPrintableASCII(len))),
min(length(randomStringUTF8(len))), max(length(randomStringUTF8(len)))
FROM numbers(10000000)
自定义方法
鉴于上面都是乱码,不方便查看,因此有时候需要自定义一些方法
hex(int)方法,将整数转为十六进制字符串hex(rand())
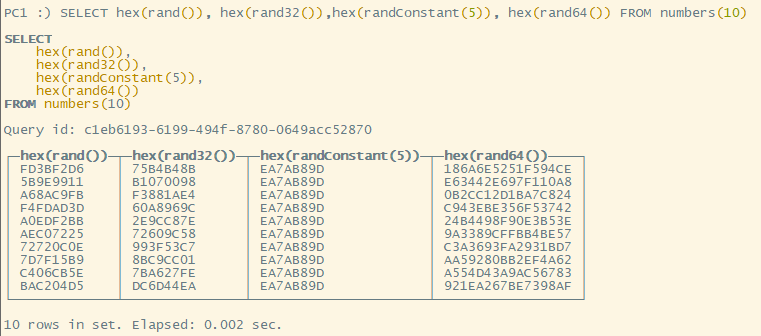
- 将有乱码的随机字符串进行Base64编码,然后倒置,并去除末尾的 “==”
注意:SQL与Java不同,编号是从1开始的,而不是0
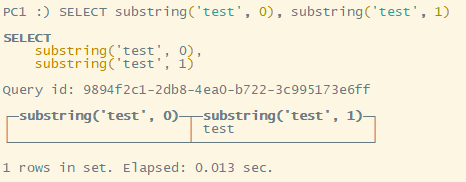
substring(<起始位置>, <长度>)起始位置从1开始,并且可以是负数;长度不能是负数
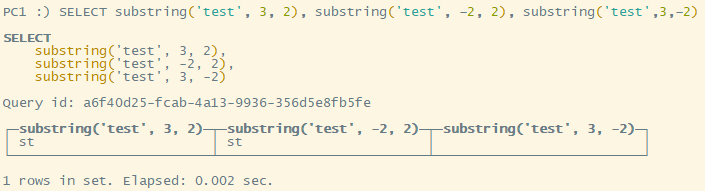
例如:substring(reverse(base64Encode(randomString(<字符串长度>))), 3)

- 指定字符集,通过concat进行连接
由于没有循环语句,因此要多少,只能自行拼接多少
concat(str1,str2,str3...)用来拼接多个字符串 ,里面传多个字符串arrayStringConcat([str1,str2,str3...], <分隔符>)用来将字符串数组连到一起,支持自定义分隔符

WITH <变量值> AS <变量名>用在sql的最前面,用来声明变量
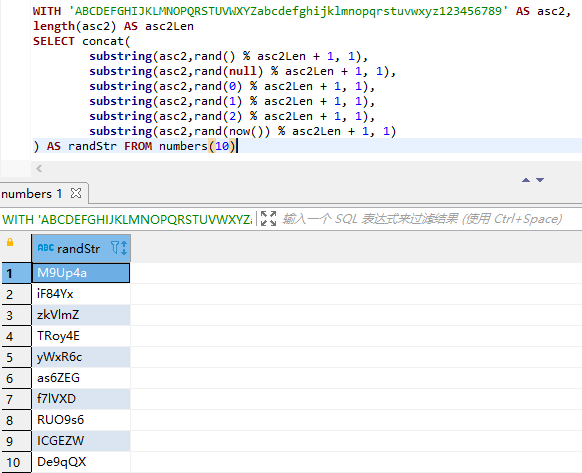
下面语句用来在字符串中随机抽取一个字符,然后进行拼接
WITH 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz123456789' AS asc2,
length(asc2) AS asc2Len
SELECT concat(
substring(asc2,rand() % asc2Len + 1, 1),
substring(asc2,rand(null) % asc2Len + 1, 1),
substring(asc2,rand(0) % asc2Len + 1, 1),
substring(asc2,rand(1) % asc2Len + 1, 1),
substring(asc2,rand(2) % asc2Len + 1, 1),
substring(asc2,rand(now()) % asc2Len + 1, 1)
) AS randStr FROM numbers(10)
UUID
generateUUIDv4 会生成 8-4-4-4-12 的随机 UUID
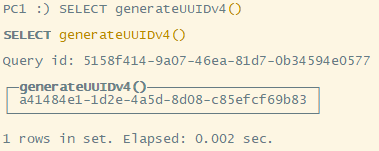
枚举
枚举字段的定义为 <字段名> Enum8('<key1>' = 0, '<key2>' = 1, ...)
枚举类型的赋值方式,可以用它的 key,也可以用它的 value
数组
- 随机长度
range(<数组最大长度>),注意:数组最大长度为它的参数大小

range(rand() % <数组长度>)可以得到一个随机长度的数组。
注意:a % b取余的话,最大只能达到b-1
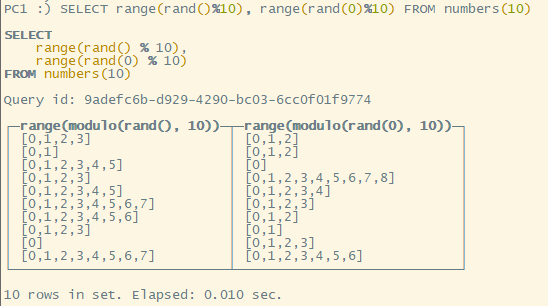
- 随机正序或倒序
clickhouse 中没有true和false,因此用 “0、null、NULL” 表示false,“非0的所有整数” 均为true
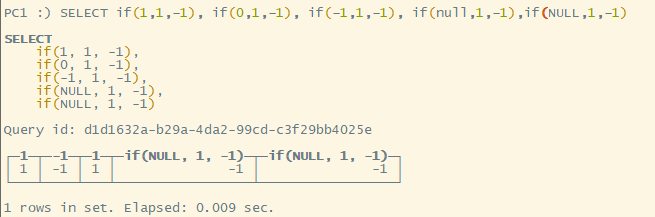
arraySort 的第一个函数是一个匿名函数
SELECT arraySort((x) -> if(rand()>rand(0),1,-1)*x, [3,2,5,1,6,4,9,8,0]) FROM numbers(10)
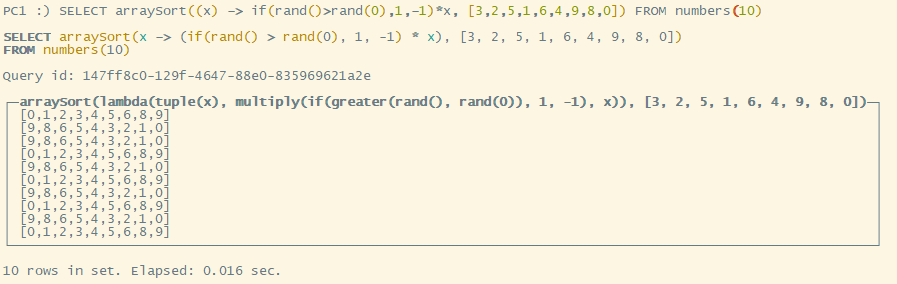
逐条插入
临时表引擎
通常用于测试,它会创建一张临时表,并对其进行操作,操作完成后自动删除该表
语法:nullable(<表结构>)
INSERT INTO function null('x UInt64') SELECT * FROM numbers_mt(1000000000);
上面的一句 sql 等价于下面3条语句
CREATE TABLE t (x UInt64) ENGINE = Null;
INSERT INTO t SELECT * FROM numbers_mt(1000000000);
DROP TABLE IF EXISTS t;
测试语句
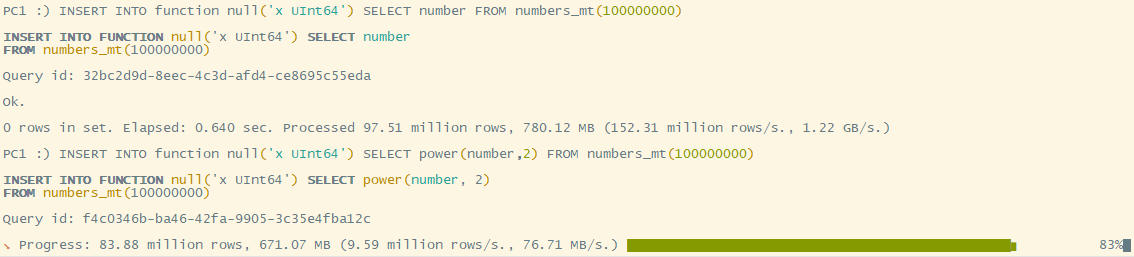
INSERT INTO function null('x UInt64') SELECT * FROM numbers_mt(100000000)
INSERT INTO function null('x UInt64') SELECT power(number, 2) FROM numbers_mt(100000000)
随机数生成表引擎
官网地址为:https://clickhouse.com/docs/en/sql-reference/table-functions/generate/
语法:ENGINE = GenerateRandom(random_seed, max_string_length, max_array_length)
- random_seed 计算机的随机数都是伪随机数,因此需要一个随机种子来标识起点。如果填null,会使用一个随机种子
- max_string_length 随机字符串的最大长度(包括该长度)。默认为10
- max_array_length 随机数组的最大长度(包括该长度)。默认为10
该引擎不支持分布式,且不支持如下特性
- ALTER
- SELECT … SAMPLE
- INSERT
- Indices
- Replication
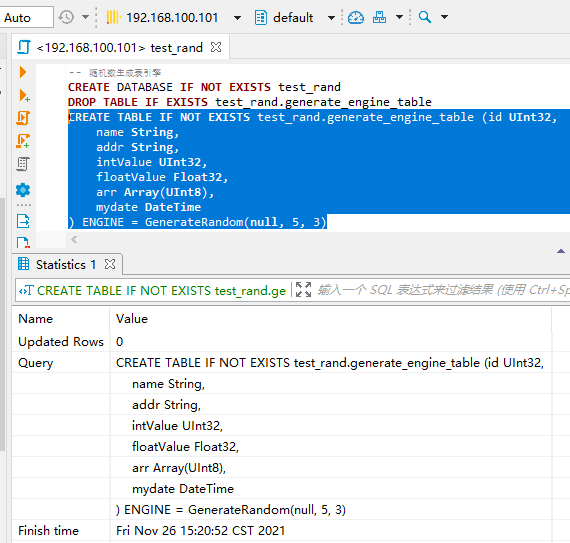
创建一个 “随机数生成表”
CREATE DATABASE test_rand
DROP TABLE IF EXISTS test_rand.generate_engine_table
CREATE TABLE IF NOT EXISTS test_rand.generate_engine_table (id UInt32,
name String,
addr String,
intValue UInt32,
floatValue Float32,
arr Array(UInt8),
mydate DateTime
) ENGINE = GenerateRandom(null, 5, 3)
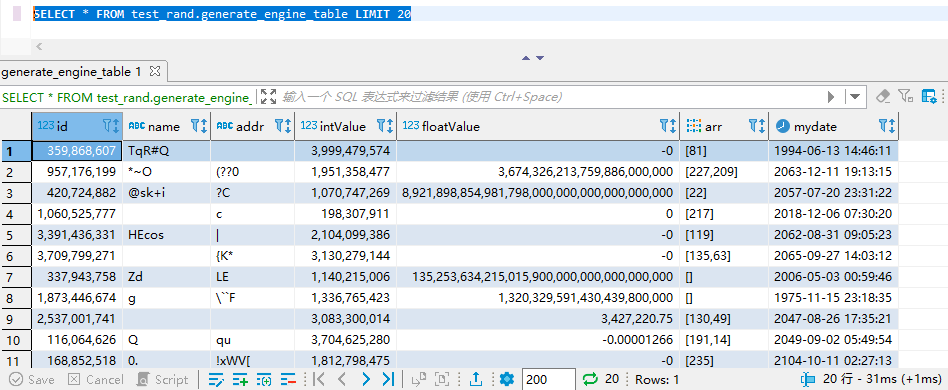
这是一个特殊的表,仅能用于查询。它是在你查询时,才自动生成临时数据并返回的,因此每次查询的数据均不同。你必须限制总查询的条数,不然会一直跑下去
例如 SELECT * FROM test_rand.generate_engine_table LIMIT 20
INSERT INTO test5.testMergeTree(id, name, value, date) SELECT id, name, id, now() FROM test5.generate_engine_table LIMIT 1000000000
SSB 性能测试
SSB(Star Schema Benchmark)的介绍论文地址:
https://www.cs.umb.edu/~poneil/StarSchemaB.PDF
官网链接 https://clickhouse.com/docs/en/getting-started/example-datasets/star-schema/
如果安装系统时,时最小化mini安装,经常会提示很多命令不存在
- 提示 git 不存在,使用
yum install git安装即可 - 提示
make: command not found,使用以下命令安装 makeyum install -y gcc gcc-c++ automake autoconf libtool make
ssb-dbgen 测试工具 GitHub 地址 https://github.com/vadimtk/ssb-dbgen
下载并编译测试工具
git clone https://github.com/vadimtk/ssb-dbgen.git
cd ssb-dbgen
make
之后就会在当前目录生成 dbgen 的可执行文件

dbgen是用来生成TPCH 所需要的数据来使用的
TPCH :针对于数据库查询性能的压测方法
|
| 命令 | 结果 |
|---|---|
./dbgen -s 1 -T c | customer.tbl |
./dbgen -s 1 -T p | part.tbl |
./dbgen -s 1 -T s | supplier.tbl |
./dbgen -s 1 -T d | date.tbl |
./dbgen -s 1 -T l | lineorder.tbl |
./dbgen -s 1 -T a | 一次性生成以上所有表 |
这里数据量业界有一个统称叫做SF 1SF == 1G
[root@localhost dbgen]# ./dbgen -s 1 ###装载数据 1G -s 1 == 1G #:但这样有一个弊端 那就是如果装载的数据量特别大的时候例如 1T 这样基本需要花费一天的时间 所以我来用多线程的dbgen方法
#方法如下:
#!/bin/sh
./dbgen -vfF -s 1000 -S 1 -C 16 &
./dbgen -vfF -s 1000 -S 2 -C 16 &
./dbgen -vfF -s 1000 -S 3 -C 16 &
./dbgen -vfF -s 1000 -S 4 -C 16 &
./dbgen -vfF -s 1000 -S 5 -C 16 &
./dbgen -vfF -s 1000 -S 6 -C 16 &
./dbgen -vfF -s 1000 -S 7 -C 16 &
./dbgen -vfF -s 1000 -S 8 -C 16 &
#:参数详解
-v 详细信息
-s 表示生成G数据
-S 切分数据
-f 覆盖之前的文件
####建表
dss.ddl 这个文件存储的是建表的语句
cat dss.ddl 逐一执行里面的建表语句
CentOS 7 时区设置
timedatectl # 查看系统时间方面的各种状态
timedatectl list-timezones # 列出所有时区
timedatectl set-local-rtc 1 # 将硬件时钟调整为与本地时钟一致, 0 为设置为 UTC 时间
timedatectl set-timezone Asia/Shanghai # 设置系统时区为上海
其实不考虑各个发行版的差异化, 从更底层出发的话, 修改时间时区比想象中要简单:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime