Aurora 论文解读
SIGMOD 2017
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases.
Amazon Aurora是亚马逊开发的云原生分布式数据库,相关的文章于2017年发表于SIGMOD。亚马逊开发的云上服务一直是大家关注的重点之一,正是通过这篇paper才让我们能一窥这款云原生数据库的架构设计,本篇文章主要内容也是依据这篇paper而得到的。
介绍及基本架构
从传统的单机数据库转变为RAC的数据库集群或者其他的分布式数据库,在这个过程中,最重要的改变是对性能的影响瓶颈,原先的单机数据库,计算节点和存储节点在物理上同属于一个节点,因此在requet I/O上并不会遇到太大的瓶颈,影响系统性能的主要问题是节点的计算能力和存储能力。而在分布式数据库系统中,由于存储节点和计算节点被解耦,底层的存储节点可以无限扩展,分布式数据库中的主要问题集中在网络对requset I/O的影响以及整体系统改如何高效地保证一致性上。
Aurora 是亚马逊云服务AWS中的关系型数据库服务,主要面向OLTP场景。其基本设计理念是云上环境下,数据库的最大瓶颈不再是计算或者存储资源,而是网络,因此Aurora在原本MYSQL基本架构的基础上,通过构造一套存储与功能层分离架构,在数据交互层上仅将日志处理下推到存储层,进而解决网络瓶颈。
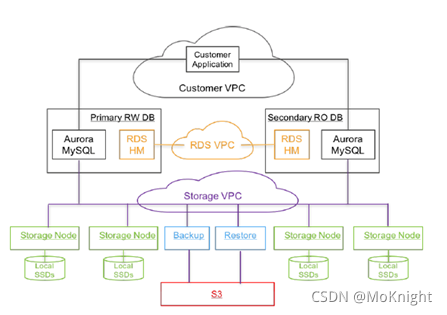
Aurora的整体架构如上图所示,主要分为3层:
- 第一层是用户层,主要是帮助用户在VPC(Virtual Private Cloud)上部署的应用实例。
- 第二层是Aurora的数据库层(功能层),主要负责完成关于数据请求的计算部分,这一层会部署Aurora中的数据读写节点1个和只读节点0-15个,主要完成从用户层接受读写请求,完成计算后传递到第三层数据存储层。读写节点和只读节点部署在不同的节点上,通过RDS VPC上的HM(Host Manager)对所有数据库层节点进行监控。
- 第三层是Aurora的数据存储层,在原本的MYSQL架构中,Aurora的第二层和第三层应该是完全耦合的,在新的设计架构中,Aurora选择将这两层解耦,放置在不同的节点之上。主要部署存储节点,同一物理区域的不同AZ中。备份/还原服务备份数据到S3 (Simple Storage Service) 中,必要时从S3恢复。 使用 Amazon DynamoDB 来管控存储层,储存配置,元数据信息,备份到S3数据的信息等。
独立的存储层
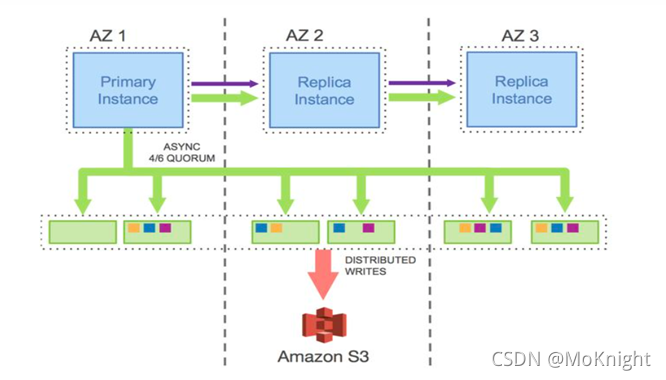
Aurora独立的存储层按照Quorum模型进行设计,基础的架构是如下图所示的3AZ,6副本架构。关于Aurora为什么选择这样的设计架构,需要首先解释Quorum是如何保证整体数据的一致性的。
?
Quorum机制
关于Quorum模型机制:假设复制拓扑中有V个节点,每个节点有一个投票权,读请求或写请求必须拿到 V r V_r Vr? 或 V w V_w Vw?个投票才能返回。为了满足一致性,需要满足两个条件,首先 V r + V w > V V_r + V_w > V Vr?+Vw?>V ,这个保证了每次读都能读到拥有最新数据的节点;第二, V w > V / 2 V_w > V/2 Vw?>V/2,每次写都要保证能获取到上次写的最新数据,避免写冲突。比如 V = 3 V=3 V=3,那么为了满足上述两个条件, V r = 2 V_r=2 Vr?=2, V w = 2 V_w=2 Vw?=2。
Aurora认为简单的2/3 Quorums是不够的。要理解为什么,需要首先了解AWS中可用区(AZ)的概念。AZ是通过低延迟链路连接到该区域其他AZ的区域的子集,但对于大多数故障(包括电源,网络,软件部署,洪水等)都是隔离的。跨AZ分发数据副本可确保典型的故障规模模式仅影响一个数据复制品。这意味着可以简单地将三个副本中的每个副本放置在不同的AZ中,并且除了较小的单个故障外,还可以容忍大规模事件。
3AZ的架构中,单一AZ上副本节点出现故障的概率通常是很高的,两AZ上副本节点同时故障的概率虽然低,但是并不意味着不会发生,而且,在单AZ单副本的架构下,这样的单一副本出错,就代表整个AZ的故障,因此这样的AZ设计并不符合Aurora的需求。
为了保证各种异常情况下的系统高可用,Aurora的数据库实例部署在3个不同AZ(Availablity Zone),这样保证最小的异地子集需求,每个AZ包含了2个副本,总共6个副本,每个A是一个独立的容错单元,包含独立的电源系统,网络,软件部署等。结合Quorum模型以及前面提到的两条规则, V = 6 V=6 V=6, V w = 4 Vw=4 Vw=4, V r = 3 Vr=3 Vr=3,Aurora可以容忍任何一个AZ出现故障,而不会影响写服务;任何一个AZ出现故障,以及另外一个AZ中的一个节点出现故障,不会影响读服务且不会丢失数据。
基于Quorum机制的读写一致性模型会导致每一个节点上接受到的log日志并不完备,如下图所示:

分段存储
关于AZ+1是否能够提供足够的可持久性。为了在该模型中提供足够的可持久性,必须确保在修复其中一种故障所需的时间内(MTTR - 平均修复时间),发生不相关故障的双重故障概率(MTTF - 平均故障时间)足够低。如果出现双重故障的概率较高,可能会出现一个AZ故障,以致打破Quorum。到目前为止,很难降低MTTF在独立故障上的概率。因此Aurora将重点放在降低MTTR上,从而降低双重故障的影响。为此,Aurora将数据库卷分为固定大小的小段,目前设置的大小是10G。这些数据段每个都会复制6份,组成一个PG,因此每个PG包含6个10GB的数据段,分布在3个AZ中,每个AZ包含两个数据段。存储卷由一组PG组成,在物理上使用Amazon EC2挂载SSD作为单个节点,由大量存储节点构成。构成存储卷的PG集合随着存储卷的增长而增大。我们目前最大支持单个存储卷达64T。
存储节点构成。构成存储卷的PG集合随着存储卷的增长而增大。我们目前最大支持单个存储卷达64T。
现在,数据段是背景噪声最小的故障和修复单元。监控是自动修复故障是服务的一部分。在10Gbps的网络连接条件下,一个10G的数据段可以在10秒内被修复。因此,想要打破Quorum,就必须在10秒的时间窗口中同时发生两个数据段故障加上一个AC故障,并且AZ故障不包含此前故障的两个数据段。即使在我们为客户管理的数据库量级上,通过我们观察到的故障率,这种情况出现的概率非常低。