1.前言
我之前从手机上传输到电脑上一些apk进行分析,都是使用es文件浏览器这款软件获取 app,传输方面使用QQ,这样很麻烦,走外网流量暂且不提,总是感觉浪费掉了局域网这个环境。简单研究了一下es文件浏览器的局域网传输文件的功能,感觉还是挺好用的,就是这个软件只有 安卓和ios版的,没有桌面版的,于是我就开始构思写一个桌面版的快传功能的软件,可以与 安卓/ios版的es文件浏览器的快传功能直接对接,从而实现 从安卓,ios通过局域网传输文件到电脑。
2.分析协议
要做到传输文件这种功能,首先就是要知道 es文件浏览器这款软件快传功能使用的是什么协议,所以需要抓包。
快传功能需要进行一些设置,否则手机会自动建立一个热点(手机建立wifi热点,另一台手机连接后其实也是在一个局域网):
2.1 如何发现接受设备
当手机要发送文件时,是如何发现另一台手机的,按照流程另一台手机是需要点击 接收 按钮的:

点击接受按钮后我直接在电脑上使用 wireshark 进行抓包:

看到,接受端需要发送一个 udp的组播数据包,组播地址是224.0.0.1 ,端口是6343,数据内容就是 用户名:ip地址:receive这种格式。
用python发送 udp组播数据包,测试发送端(手机)是否能发现:
import socket
import time
def get_host_ip():
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 53))
ip = s.getsockname()[0]
finally:
s.close()
return ip
def send_UDP():
localIp = get_host_ip()
port= 6343
castAddr = '224.0.0.1'
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
sock.bind((localIp,port))
sock.setsockopt(socket.IPPROTO_IP, socket.IP_MULTICAST_TTL , 1) #设置ttl
while True:
sock.sendto(b'%s:%s:receive' % (name.encode(),localIp.encode()), (castAddr,port) )
print("已发送")
time.sleep(1)
if __name__ == '__main__':
name = "wshuo"
send_UDP()

成功发现了,并且成功解析出我定义的名字了。其实这一步主要是找到接收方的IP地址。后面传输时会用到。
2.2 传输文件协议分析
具体传输文件使用协议不同于发现,发现用到是组播udp,局域网内的设备使用 wireshark 抓包都抓取到。
由于 es文件浏览器 没有桌面端的软件,我要实现抓包文件具体传输就需要让局域网传输的流量流经我的电脑。我采用电脑建立热点的这种方法,然后两个手机同时连接电脑的热点,这样俩个手机传输产生的数据包都会流经我的网卡。然后再使用 wireshark 进行抓包:

传输文件使用的是TCP协议,接受端在 42135端口建立服务,由于数据包大小限制,我们看到每一条数据都是零散的,可以使用追踪TCP流 来查看具体数据传输:

发送端发送一个请求头,可以看到是类似于HTTP请求,但是使用的是 MYPOST,不是POST,是一个自定义的 应用层 协议,基于TCP协议。 除去请求头后面的也不是具体的文件数据,因为这里传输的是一个图片,图片的文件头不是这样的。这部分数据经过我后续的分析其实是一个缩略图,并且由Append-Data 请求头决定,如果没有Append-Data请求头,这部分数据就不存在。
继续寻找图片数据:

可以看到,当获得完缩略图数据后,接受端会响应一个响应头,然后就继续接受数据了,首先是文件名,然后是file,这个相当于是类型,因为可能传输的是一个文件夹folder, 然后是文件大小,最后就是图片的数据了。

文件结束后,会有 File end 标识,然后整个传输流接受会有 OVER 标识。
3.总结
传输流程:

udp组播数据:用户名:ip地址:receive
tcp连接请求头: MYPOST /test2.jpg HTTP/1.1\r\nConnection: Keep-Alive\r\nContent-Type: application/file\r\nFiles-Number: 1\r\nItems-Number: 1\r\nContent-Length: 3700879\r\nUser-Agent: Dalvik\r\nHost: localhost\r\nsender-name: wshuo\r\n\r\n
| 字段 | 作用 |
|---|---|
| test2.jpg | 接收端显示的文件名,具体保存时使用的文件名在tcp连接数据流中 |
| Content-Type | application/file表示传输的是一个文件,application/folder表示是一个文件夹,同样显示时使用,不作为具体保存使用 |
| Files-Number | 传输文件数量,可以选择多个文件同时传输 |
| Items-Number | 传输条目数量,当传输一个文件夹时,会递归传输该文件夹内所有文件夹和文件 |
| Content-Length | 文件总大小,文件夹大小为0,所有文件大小之和 |
| sender-name | 发送端的名字 |
| Append-Data | 可有可无,如果有,表示是否添加缩略图数据,一般传输图片时会有此字段 |
tcp连接响应头:Transfer-Version: 1\r\nServer: ES Name Response Server\r\nContent-Type: text/html\r\nContent-Length: 2\r\nConnection: close\r\n\r\nOK
请求头,没啥解析的,上面这类的表示接收端接受数据。
tcp连接响应头:HTTP/1.1 404 Not Found\r\n\r\n
这类表示接收端拒绝接受数据。
tcp连接数据流:
文件数据流:
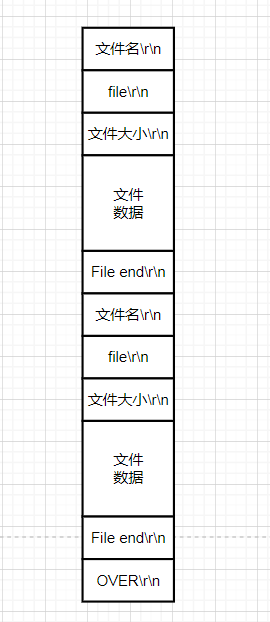
这是两个文件数据例子,如果多个文件继续叠加即可。
文件夹数据流:
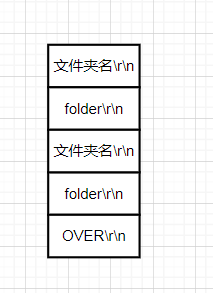
文件夹数据较为简单,字段也就两个。
4. python接收端编写
经过上面的分析,python代码需要实现分为以下几步:
- python发送udp组播数据包
- 使用socket建立tcp连接服务端
- 接收请求头数据
- 返回响应头数据
- 接收具体文件或文件夹数据流
- 从数据流中解析出文件夹和文件并将其保存
原理倒是不复杂,但是细节有些复杂,比如接受图片时会有 Append-Data字段,同时会有缩略图数据,由于 python socket服务端的recv会阻塞住,那么我就不知道什么时候才能将缩略图数据接受完毕,只有接受完所有数据才能返回响应头数据,否则可能会导致缩略图数据与真正的文件数据混到一起,从而导致无法解析。这部分我采用在读取缩略图数据是 循环读取,settimeout()方法,当没有数据返回是就会报错,容错处理跳出 读取循环。这样接下来返回响应头数据再次读取就是真正的文件流数据了(非阻塞的方法实现较为复杂,所以这一步比较粗暴但是很有效)。
另一个难点就是解析 从数据流中解析文件夹和文件,开始时我想在读取接收端的数据直接解析出来,后来发现这种方法很难实现,因为你无法保证真正的数据流中是否包含 File end或者\r\n这些关键数据,这这些数据都会对解析进行干扰。所以这里我采用两步,将真正数据流保存成数据文件,然后再对数据文件进行解析,这样就简单很多了,因为可以直接使用readline这样的函数来实现解析 \r\n 了。
receviceData.py
import socket
import time
import os
from threading import Thread
response = """\
Transfer-Version: 1
Server: ES Name Response Server
Content-Type: text/html
Content-Length: 2
Connection: close
OK"""
class MItemObject():
def __init__(self,f):
self.rootDir = "" #存储根目录
self.f = f
self.ItemName = f.readline()
self.ItemType = f.readline()
self.fileSize = None
self.fileRange = [None,None] # 文件数据位置
self.endPos = None #结束位置,也是下一条目开始位置
self.end = False #是否是最后一个条目
if (b"\r\n" not in self.ItemName) or (b"\r\n" not in self.ItemType):
raise BaseException(r"\r\n错误")
else:
self.ItemName = self.ItemName.strip(b"\r\n").decode()
self.ItemType = self.ItemType.strip(b"\r\n").decode()
if self.ItemType == "file":
self.fileSize = int(f.readline().strip(b"\r\n").decode())
self.fileRange = [f.tell(),f.tell()+self.fileSize]
f.seek(self.fileRange[1])
if f.readline().strip(b"\r\n").decode() != "File end":
raise BaseException(r"File end错误")
self.endPos = f.tell()
elif self.ItemType == "folder":
self.endPos = f.tell()
else:
raise BaseException(r"文件类型错误")
print(self.ItemName,self.ItemType,self.fileSize,self.fileRange,self.endPos)
if f.readline().strip(b"\r\n").decode() == "OVER":
self.end = True
self.saveData()
f.seek(self.endPos)
def saveData(self):
if self.ItemType == "folder":
if not os.path.exists(os.path.join(self.rootDir, self.ItemName)):
os.mkdir(os.path.join(self.rootDir, self.ItemName))
elif self.ItemType == "file":
self.f.seek(self.fileRange[0])
with open(os.path.join(self.rootDir, self.ItemName),"wb") as f:
f.write(self.f.read(self.fileSize))
self.f.seek(self.endPos)
def progress(arg):
scale = 50
i = int(arg * scale)
a = "*" * i
b = "." * (scale - i)
c = (i / scale) * 100
print("\r{:^3.0f}%[{}->{}]".format(c,a,b),end = "")
def get_host_ip():
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 53))
ip = s.getsockname()[0]
finally:
s.close()
return ip
def send_UDP():
localIp = get_host_ip()
port= 6343
castAddr = '224.0.0.1'
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
sock.bind((localIp,port)) #绑定发送端口到SENDERPORT
sock.setsockopt(socket.IPPROTO_IP, socket.IP_MULTICAST_TTL , 1) #设置使用多播发送
while True:
sock.sendto(b'%s:%s:receive' % (name.encode(),localIp.encode()), (castAddr,port) )
time.sleep(1)
def server():
s = socket.socket()
s.bind(("0.0.0.0",42135))
s.listen(1)
while True:
conn,addr = s.accept()
data = conn.recv(1024)
conn.settimeout(2)
# 读取头信息
header = data.split(b"\r\n\r\n")[0]
extraData = data.split(b"\r\n\r\n")[1]
headerData = header.decode().split("\r\n")[1:]
headerDict = {i.split(":")[0].strip():i.split(":")[1].strip() for i in headerData}
# 读取掉无用的数据,缩略图
while True:
try:
extraData += conn.recv(1024)
except Exception as e:
# print(e)
break
conn.settimeout(None)
conn.send(response.encode())
time.sleep(0.5)
# 读取主要数据
f = open("stream","wb")
streamLen = 0
allFileSize = int(headerDict["Content-Length"])
while True:
result = conn.recv(2048)
streamLen += len(result)
f.write(result)
if streamLen > allFileSize:
progress(1)
else:
progress(streamLen/allFileSize)
if not result:
break
f.close()
print("\n写入完成!")
f = open("stream","rb")
while True:
item = MItemObject(f)
if item.end:
break
f.close()
os.remove("stream")
if __name__ == '__main__':
name = "wshuo" #用户名
Thread(target=send_UDP).start()
server()
这个脚本最好在终端运行,因为有进度条效果:

可以接收文件夹,文件。
5. QT软件编写
只是一个接收端我还不满足,我还想实现发送端的功能,这样才算是一个完整的软件。而python编写发送端软件不太友好,因为选择文件传输时手动输入文件名或文件夹名很不友好。PyQt5 可以写界面,但是打包程序太大,思来想去还是用原生的c++ Qt来编写吧。
这其中遇到的难点也不少,比如 QTcpSocket 使用起来不会阻塞线程,通信方面都是信号槽的方式,让我有些不习惯。另外就是发送端的递归文件夹内部所有子文件夹或文件,将其变化为传输的数据流,这里依然采用两步操作。更多细节难点我就不说了,都解决了。
6.软件功能预览
主界面:

接收界面:
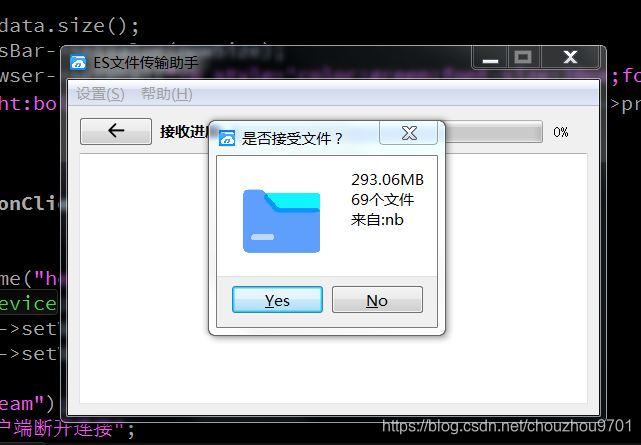
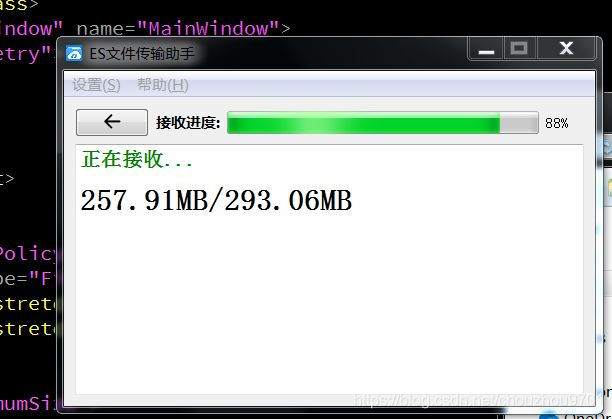
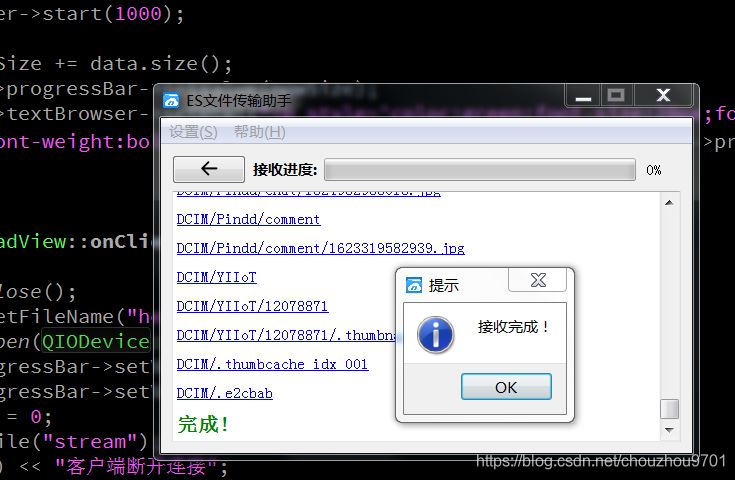
蓝色的字是可以点击的,打开对应文件夹或文件。
发送界面:
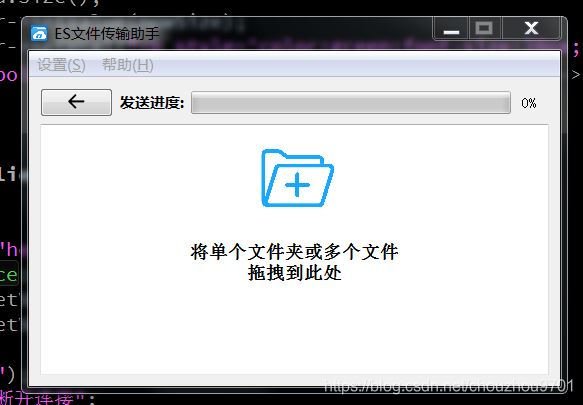
可以拖拽进一个文件夹,然后就会递归读取该文件夹下的所有文件夹与文件,或者可以拖拽进多个文件。但是不可以同时拖进文件夹和文件,因为同时处理文件夹和文件这部分逻辑逻辑比较复杂,所以我对这部分进行了限制。
设置界面:
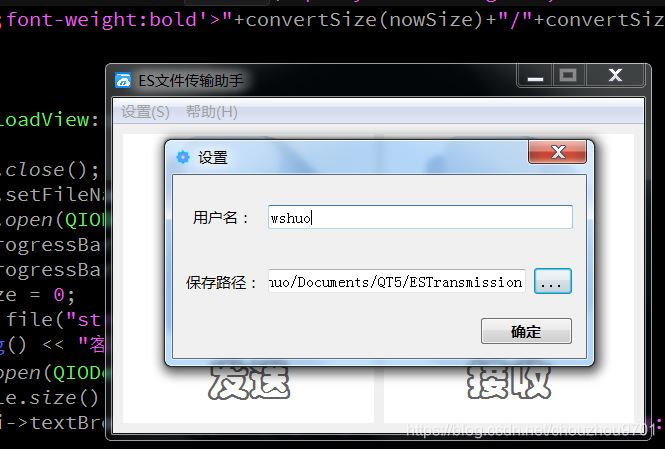
可以设置用户名,以及接收文件保存的路径。
另外,这个软件以及包含发送功能,和接受功能,这样也可以实现电脑与电脑之间传输文件使用了。相当于弥补了 ES文件浏览器 传输文件功能在桌面端的空白了。