数据库(牛客)
Distinct用于去除重复的元素
LIMIT m,n : 表示从第m+1条开始,取n条数据;
LIMIT n : 表示从第0条开始,取n条数据,是limit(0,n)的缩写。
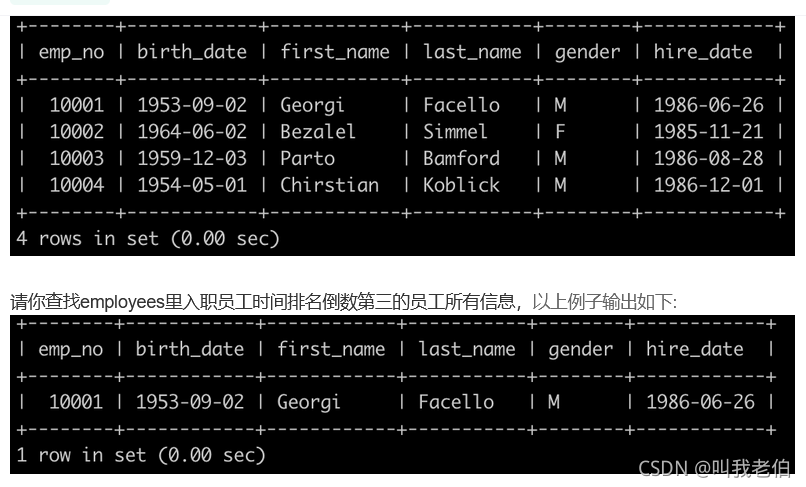
select *from employees where hire_date =(select DISTINCT hire_date from employee order by hire_date desc limit 2,1)
 ------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
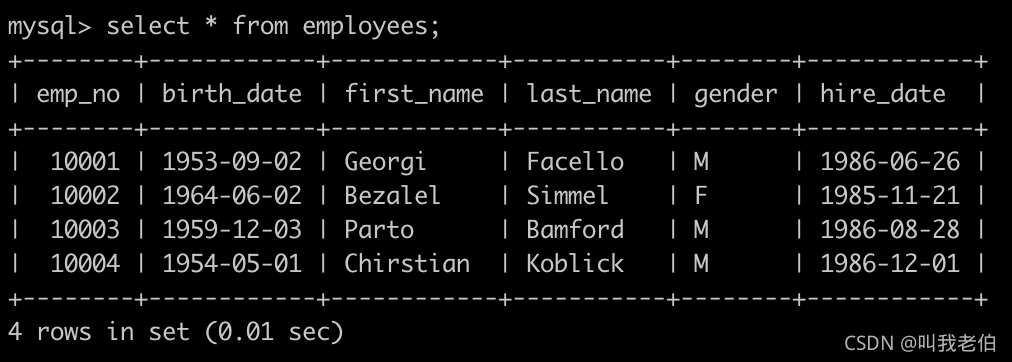
有一个员工表,employees简况如下:
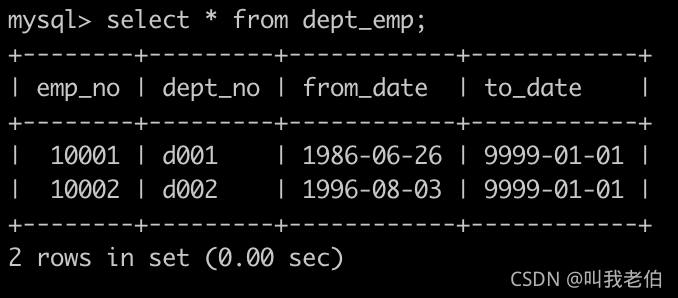
有一个部门表,dept_emp简况如下:
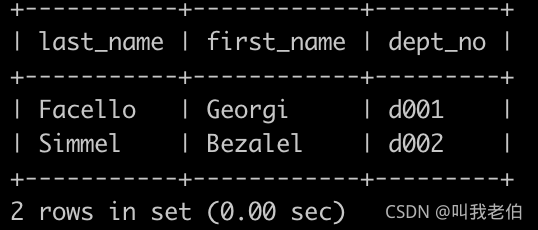
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:
简单说下我的思路:
1、查看employees和 dept_emp表结构,再观察结果数据是两个表共同的数据,确定是内连接 inner(可省略) join。
2、写查询语句。
SELECT
e.last_name,
e.first_name,
d.dept_no
FROM
dept_emp AS d
INNER JOIN
employees AS e
ON
e.emp_no = d.emp_no;