Hive学习笔记(HiveQL数据查询基础)
HiveQL数据查询语句
SELECT语句
SELECT语法结构如下:
SELECT */field1,field2....FROM tableName,
例:sogo表中结构信息如下:

查询sogo总条数代码:
hive>SELECT cout(*) FROM sogo.sogo;
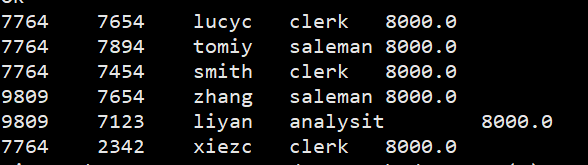
查询表的前10条数据代码为:
hive> SELECT *From sogo.sogo limit 10;
WHERE语句
SLEECT语句用于选取字段,WHERE语句语句用于过滤条件,
例:查询关键词包含亮剑的前5条记录,并且只显示te,uid,keyword:
hive>SELECT ts,uid,keyword FROM sogou.sogou_500w WHERE keyword like '%亮剑%' limit 5;
GROUP BY语句
GROUP BY语句通常会和聚合函数一起使用,其语意是按照一个或者多个列对结果进行分组,然后使用聚合函数对每个组执行聚合运算。
例如:
统计用户使用搜索引擎的次数,按照uid分组,相同uid的搜索记录被分配到一个组中进行聚合累加运算,

HAVING分组筛选
HAVING子句允许通过一个简单的语法,来完成原本需要通过子查询才能GROUPBY 语句产生的分组结果进行条件过滤的任务。
例如:搜索关键词中包含“亮剑”一词中用户及关键词搜索次数,并且过滤出搜索次数大于30的用户。
hive> SELECT t.uid,t.keyword,count(*) as cnt FROM (SELECT * FROM sogo.sogo WHERE keyword like '%亮剑%') t GROUP BY t.uid,t.keyword HAVING cnt>=30;
统计用户查询次数大于5次的用户总数,首先统计各个用户的查询次数,其次在用HAVING子句吧查询次数大于5次的用户过滤出来,代码如下:
hive>SELECT count(t.uid) FROM (SELECT uid,count(*) as cnt FROM sogo.sogo GROUP BY uid HAVING cnt>5)t;

ORDER BY语句和SORT BY语句
ORDER BY会对查询结果执行一次全局排序也就是说所有数据都通过一个reduce人进行处理的过程。对于大数据集,这个过程会消耗太多时间。
SORT BY语句,该语句只会在reducer中对数据排序,也就是说一个局部排序,因此可以保证每个reduce人的输出数据都是有序的。排序默认是升序排序,加DESC可以变为降序排序,升序关键词为ASC
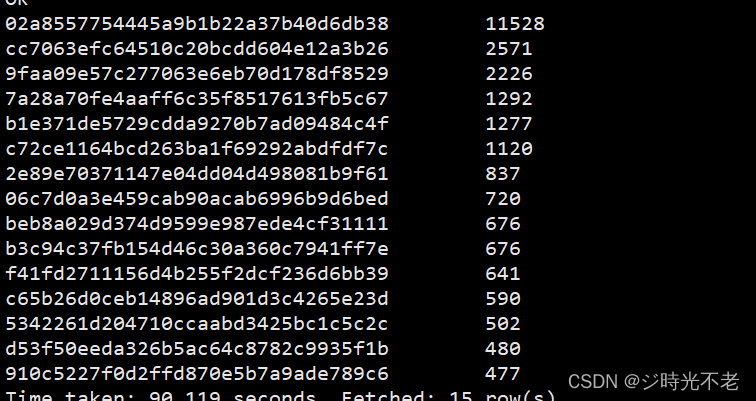
例:统计用户搜索引擎的频率并将搜索频率最高的前15用户ID及其搜索次数统计出来,操作命令如下:
hive>select uid,count(*) as cnt from sogo.sogou group by uid order by cnt desc limit 15;
HiveQL查询语句
HiveQL查询语句就是多表之间查询语句。
JOIN语句
我们吧Hive提供的一套类SQL查询语句称为HiveQL连接查询语句,其中包含了大量的连接查询方式,如内连接,自然连接外连接和自连接。
建立两个表,一个表为dep(部门表),表中含有deptno,dname,loc。
另一个表为emp(员工表),表中含有empno,ename,job,mgr,sal,deptno。
自连接
也可以简写成join,只有进行连接的两个表中,都存在与连接标准相匹配的数据才会保存下来,内连表连接分为等值连接和不等值连接。
等值连接是指,在使用等号操作符的连接。
例如:想查看部门30员工的姓名、职位、所属部门编号及部门名称。
员工姓名,职位在emp表中,部门编号和部门名称在部门表中dept中,做等值查询。
hive> select emp.ename,emp.job,dept.deptno,dept.dname from emp inner join dept on emp.deptno=dept.deptno where dept.deptno=30;

不等值连接是指使用>、<、>!、<!等操作符的连接
例如:
我们部门想要获得编号不等于10的所有员工的姓名、职位以及员工所属部门名称和部门地理位置信息:
hive> select emp.ename,emp.job,dept.dname,dept.loc from emp inner join dept on emp.deptno=dept.deptno where dept.deptno!=10;

自然连接
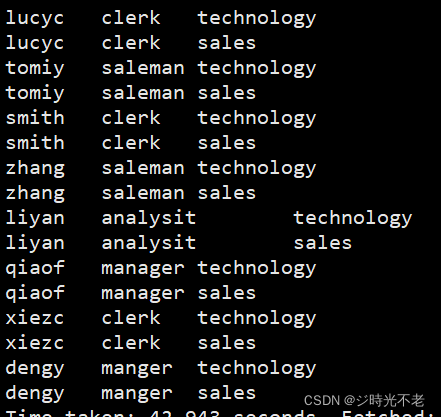
自然连接是在广义笛卡尔积中选出同名属性上符合相等条件的元祖,在进行投影,去掉同名属性,组成新的关系。自然连接死在两张表中寻找那些数据类型和列名都相同的字段,然后将它们连接起来。
例:我们想查询部门编号为10和30的所有员工的姓名、职位和部门名称:
hive>select ename,job,dname from emp natural join dept where dept.deptno in('10','30');
外连接
外连接分为左外连接查询、右外连接和全外连接。
左外连接
左外连接是以连接中的左表为主,返回左表的所有信心和右表中符合连接条件的信息,对于右表中不符合连接条件的则补空值。
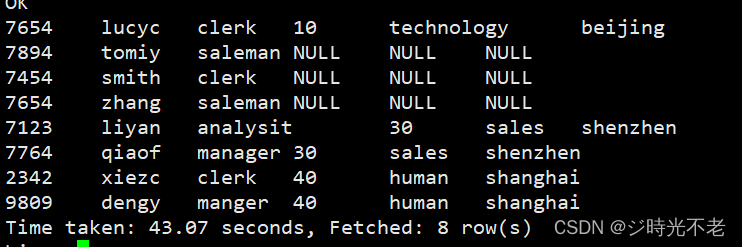
例如:查询所有员工信息和他们所在的部门信息,该需求涉及员工表和部门表dept。我们要先查询出所有员工的基本信息,其次是员工所在的部门信息,因此采用左外连接的方式,代码如下:
hive> selsect e.empno,e.ename,e.job,d.deptno,d.dname,d.loc from emp e left outer join dept d on e.deptno=d.deptno;
右外连接
右外连接以连接中的右表为主,返回右表中所有信息和左表中符合连接条件的信息对于左表中不符合的条件则补空值。
例:我们要查询部门所有信息和部门中员工的基本信息,那么有的部门有可能是刚刚建立还没有员工所以要采取右外连接,代码如下:
hive> select e.ename,e.job,d.deptno,d.dname,d.loc from emp e right outer join dept d on e.dept=d.deptno;

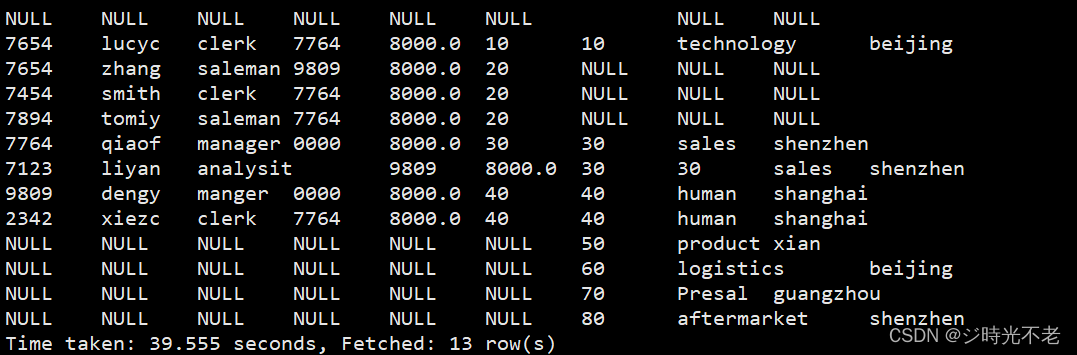
全外连接
查询结果等于左外连接和右外连接的。
例:员工表和部门表中所有信息都被查询出来,当然不符合连接条件的emp和dept都各自补空值。
hive>selecft e.*,d.* from emp e fulle outer join dept d on e.deptno=d.deptno;
自连接
连接的表时同一张表,使用自连接可以将自审表的一个镜像当成另一个表来对待满意自连接适用于表自己和自己的连接查询。
例如:在员工表emp中我们想查询经理的下属员工有哪些,那我们清楚经理和下属又有一定的从属关系,所以这时候需要用表的自连接来实现,代码如下:
hive>select e1.empno,e2.empno,e2.ename,e2.job,e2.sal from emp e1,emp e2 where e1.empno=e2.mgr;