����Ҫ����ʲô�Ǽ�ϯ��ѯ����ϯ��ѯ���û������Լ�������,����ѡ���ѯ����,ϵͳ�����û���ѡ��������Ӧ��ͳ�Ʊ�������ͨ��Ӧ�ò�ѯ�Ƕ��ƿ�����,��ϯ��ѯ���û��Զ����ѯ����
1. OLAP����
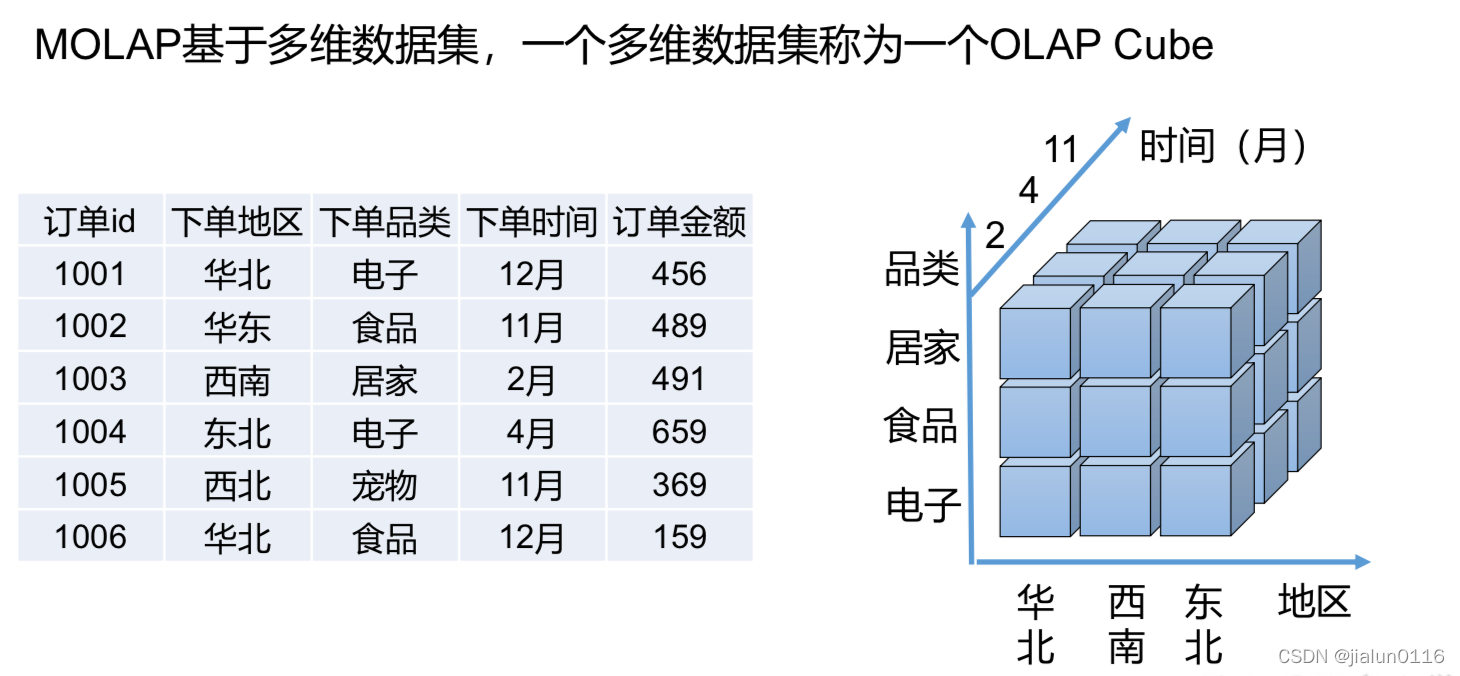
1.1 MOLAP
-
M����ʾ��ά(Multidimensional)�������MOLAP��Ʒ����ԭʼ���ݽ���Ԥ����,�õ��û�������Ҫ�����н��,����洢���Ż����Ķ�ά����洢��, �ܹ��ȶ��ؿ�����Ӧ,���и����ܡ�
-
�������ܲ�����û�д��۵ġ�����,MOLAP��Ҫ����Ԥ����,��Ứȥ�ܶ�ʱ�������ÿ��д���������ݺ��Ҫ����ȫ��Ԥ����,��Ȼ�ǵ�Ч�ʵ�,���֧�ֽ����������ݽ��е��������dz���Ҫ�����,���ҵ����������,��Ҫ����Ԥ��ģ��֮���µIJ�ѯ����,���е�MOLAPʵ��������Ϊ����,ֻ�����½��н�ģ��Ԥ���㡣
-
���,MOLAP�ʺ�ҵ������ȽϹ̶�,�������ϴ�ij�����
1.2 ROLAP
-
R����ʾ��ϵ��(Relational)����MOLAP�෴,ROLAP����Ԥ����,ֱ���ڹ��ɶ�ά����ģ�͵���ʵ����ά�ȱ��Ͻ��м��㡣��������չ��,�������ݵ����,����������¼���,�û����µIJ�ѯ����ʱֻ��д����ȷ��SQL��������ɻ�ȡ����Ľ����
-
��ROLAP�IJ���Ҳ������,������������������ij�����,�û��ύSQL��,��ȡ��ѯ��������ʱ����ȷԤ֪,�������,Ҳ������Ҫ������ʮ����������Сʱ��������,ROLAP�ǰ�MOLAPԤ���������ʱ���̯�����û���ÿ�β�ѯ��,�϶���Ӱ���û��IJ�ѯ������
-
���MOLAP,ROLAP��ʹ���ż�����,��������ͻ�ѩ����ģ�͵Ĺ���,������Ӧschema����ʵ����ά�ȱ����������ݺ�,�û�ֻ���д�����������SQL,�Ϳ��Եõ���Ҫ�Ľ������ȴ��������������塱,��Ȼ���ӷ��㡣
1.3 HOLA
- H��ʾ�����(Hybrid),MOLAP��ROLAP������ȱ��,�����ǻ���ġ�����ܹ������ߵ��ŵ���л���,��ô�Ǹ����õ�ѡ���ڲ�ѯƵ�����ȶ����ֺ�ʱ����ЩSQL,ͨ��Ԥ����������;���ڽϿ�IJ�ѯ�������������ٻ��µIJ�ѯ����,��ROLAPһ��ֱ��ͨ��SQL������ʵ����ά�ȱ�����
2. ����
2.1 ����
Apache Kylin ��һ����Դ�ķֲ�ʽ��������,�ṩ Hadoop/Spark ֮�ϵ� SQL ��ѯ�ӿ� ����ά����(OLAP)������֧�ֳ����ģ����,����� eBay Inc ��������������Դ������ ��������������ѯ��� Hive �����ÿռ任ʱ��,Ԥ����,��һ��MOLAPϵͳ
Apache Kylin? ��ʹ���߽�������,����ʵ�ֳ������ݼ��ϵ����뼶��ѯ��
- �������ݼ��ϵ�һ�����λ�ѩ����ģ��
- �ڶ�������ݱ��Ϲ���cube
- ʹ�ñ� SQL ͨ�� ODBC��JDBC �� RESTFUL API ���в�ѯ,�������뼶��Ӧʱ�伴�ɻ�ò�ѯ���
2.2 Kylin�ܹ�
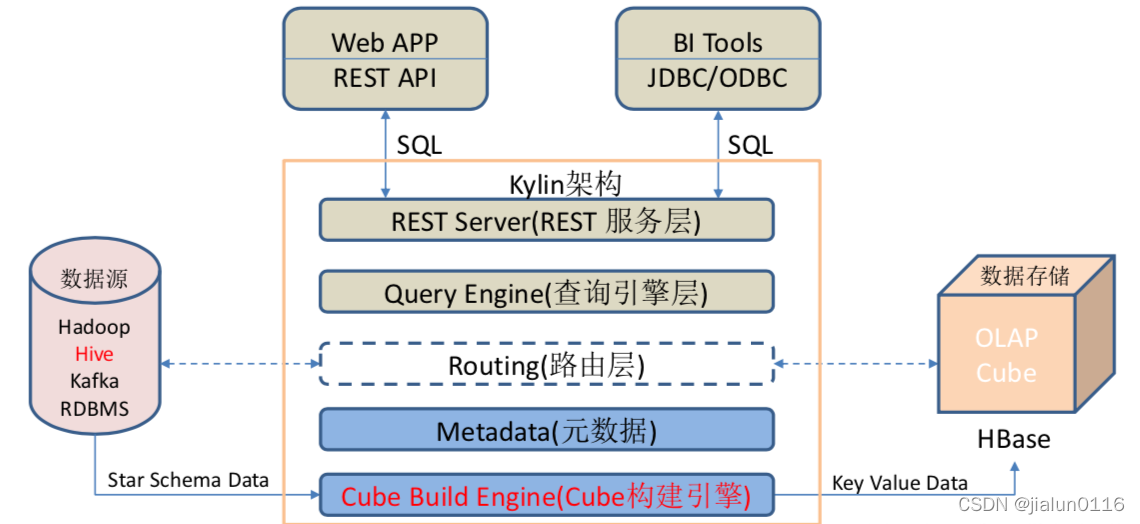
- REST Server Rest����㡣��ڵ�,�����ṩ��ѯ����ȡ��������� cube ��������ȡԪ�����Լ���ȡ�û�Ȩ���ȵ�,�������ͨ�� Restful �ӿ�ʵ�� SQL ��ѯ��
- Query Engine ��ѯ��������� cube ��������,��ѯ������ܹ���ȡ�������û���ѯ����SQLת��Ϊ��ʶ�Ĵ���
- Routing ·�ɲ���Hive �� Kylin ���ٶȲ������,�����û����Բ�ѯ���ٶ���һ�µ�����,�ܿ��ܴ� ������ѯ�����ھͷ��ؽ����,����Щ��ѯ��Ҫ�ȼ����ӵ���ʮ����,�������dz���⡣ ������·�ɹ����ڷ��а���Ĭ�Ϲرա�
- Metadata Ԫ��������һ��Ԫ����������Ӧ�ó���,Ԫ���ݹ������߱��� Kylin �е�����Ԫ����,���а�����Ϊ��Ҫ�� cube Ԫ������ Kylin ��Ԫ���ݴ洢�� hbase �С�
- Cube Build Engine Cube��������������������������,���а��� shell �ű���Java API �Լ� Map Reduce ����ȵȡ�
2.3 ����ԭ������
Apache Kylin�Ĺ���ԭ����������MOLAP(��ά���������),��������ģ����CubeԤ����,�����ü���Ľ�����ٲ�ѯ
-
ָ������ģ��,����ά�ȺͶ���
-
Ԥ����Cube,��������Cuboid������Ϊ�ﻯ��ͼ
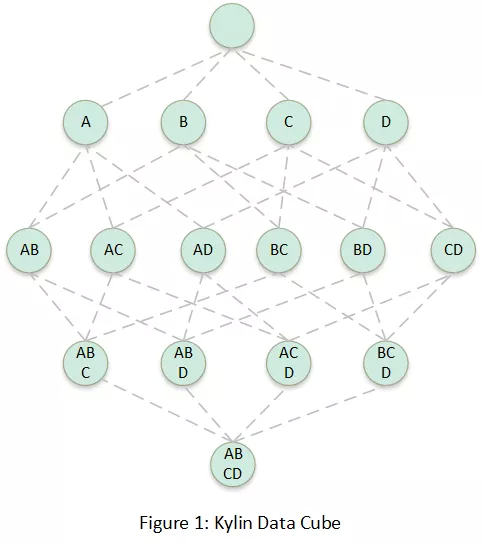
Kylin ������ģ�ͱ������ǽ���ά��(Hive ��)ת��Ϊ Cube,Ȼ�� Cube �洢�� HBase ����,Ҳ��������ת����
- ��һ��ת��,��ʵ���Ǵ�ͳ���ݿ�� Cube ��,Cube �� CuboId ���,��ͼÿ���ڵ㶼����Ϊһ�� CuboId,CuboId ��ʾ�̶��е��������ݼ���,���硰 AB�� ����ά����ɵ� CuboId �����ݼ��ϵȼ������� SQL �����ݼ���:
select A, B, sum(M), sum(N) from table group by A, B
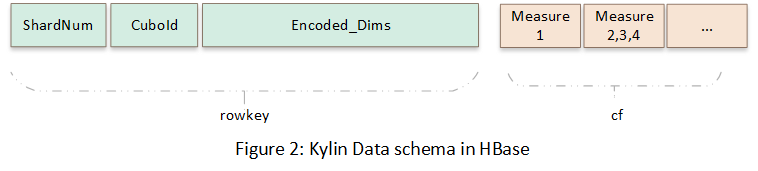
- �ڶ���ת��,�ǽ� Cube �е����ݴ洢�� HBase ��,ת����ʱ�� CuboId ��ά����Ϣ���л��� rowkey,����������д�����ת����ʱ�����ݽ�����Ԥ�ۺϡ���ͼչʾ�� Cube ������ HBase �еĴ洢��ʽ��
2.4 �ص�
-
�� SQL �ӿ�:Kylin ���Ա��� SQL ��Ϊ�������Ľӿڡ�
-
֧�ֳ������ݼ�: Kylin ���ڴ����ݵ�֧������������Ŀǰ���м�������Ϊ���ȵġ� ���� 2015 �� eBay �����������о���֧�ְ��ڼ�¼���뼶��ѯ,֮�����ƶ���Ӧ�ó����� ������ǧ�ڼ�¼�뼶��ѯ�İ�����
-
���뼶��Ӧ:Kylin ӵ������IJ�ѯ��Ӧ�ٶ�,��������Ԥ����,�ܶิ�ӵļ���, �������ӡ��ۺ�,�����ߵ�Ԥ��������о��Ѿ����,�����˲�ѯʱ������ļ�����, �������Ӧ�ٶȡ�
-
�������Ժ�������:���ڵ� Kylin ��ʵ��ÿ�� 70 ����ѯ,�����Դ Kylin �ļ� Ⱥ��
-
BI ������,ODBC��JDBC��RestAPI��Zepplin���
-
��װ Kylin ǰ���Ȳ���� Hadoop��Hive��Zookeeper��Hbase��Spark,
2.4 ��Druid �Ƚ�
-
Kylin����ȫ��Ԥ��������,ͨ��ö������ά�ȵ����,��������Cube������ǰ�ۺ�,��HBaseΪ������OLAP���档
-
Druid��������������ǰ�ۺ�(roll-up),ͬʱ�������������Լ�λͼ������߲�ѯЧ�ʵ�ʱ���������ݺʹ洢���� ����һ��ʵʱ����ʱ�����ݵ�Olap���ݿ�,��Ϊ�����������Ȱ���ʱ���Ƭ,��ѯ��ʱ��Ҳ�ǰ���ʱ����ȥ·��������
| Kylin | Druid | |
|---|---|---|
| �ŵ� | 1��֧�����ݹ�ģ����(HBase),��ȷȥ�� 2��������ǿ,֧�ֱ�SQL 3�����ܸܺ�,��ѯ�ٶȺܿ� | 1��֧�ֵ����ݹ�ģ��(���ش洢+DeepStorage�CHDFS) 2�����ܸ�,�д�ѹ��,Ԥ�ۺϼ��ϵ��������Լ�λͼ����,�뼶��ѯ 3����һ��ʵʱ����ʱ��������Olap���ݿ�,��Ϊ�����������Ȱ���ʱ���Ƭ,��ѯ��ʱ��Ҳ�ǰ���ʱ����ȥ·������,����ͨ��kafkaʵʱ�������� |
| ȱ�� | 1������Խ���,��֧��adhoc��ѯ;��û�ж�������,����ʱ����һ�㡣 2��������ʽ����,��Ҫ����CubeԤ����;��ά�ȳ���20��ʱ,�洢���ܻᱬըʽ����;������ѯ��ϸ������;ά������ 3��ʵʱ�Ժܲ�,�ܶ�ʱ��ֻ�ܲ�ѯǰһ���Сʱǰ�����ݡ� | 1�����������,��Ȼά��֮���������,����֧��adhoc��ѯ,����������ϲ�ѯ,����ʧ����ϸ���� 2�������Խϲ�,��֧��join,��֧�ָ���,sql֧�ֺ���(��Щ���������pinot��PQL����),ֻ��JSON��ʽ��ѯ;����ȥ�ز������ܾ�ȥ�ء� 3��������ʽ����,��Ҫ���������潫����join�ɿ���,ά����Ը���;���ڴ�Ҫ��ϸߡ� |
| ���ó��� | 1. �ʺ϶�ʵʱ��������,����Ӧʱ��ϸߵIJ�ѯ,��ά�Ƚ϶�,�����Ϊ�̶����ض���ѯ;�����ʺ�ʵʱ��Ҫ��ߵ�adhoc���ѯ�� 2. Hadoop/HBase ������ʹ洢,ʹ�� SQL ��ѯ,�ṩ JDBC/ODBC �����볣�� BI ������ | 1. �ʺ�������������,��ʵʱ��Ҫ�������Ӧʱ���,�Լ�ά�Ƚ���������̶��ļۺ����ѯ(sum,count,TopN),����storm��flink��Ͻ���Ԥ����;�����ʺ���Ҫjoin��update��֧��SQL�ʹ��ں����ȸ��ӵ�adhoc��ѯ�� 2. ���Լ������ķֲ�ʽ��Ⱥ,�ܹ�ʵʱ��������,���Լ��IJ�ѯ�ӿ�(��BI�����Խ���),ͨ��������ʵʱҪ��ߵij��� |
3. Cube ����ԭ��
3.1 ά�ȺͶ���
-
ά�� :���۲����ݵĽǶ�������Ա������,���Դ��Ա�Ƕ�������,Ҳ���Ը���ϸ��, ����ְʱ����ߵ�����ά�����۲졣ά����һ����ɢ��ֵ,����˵�Ա��е��к�Ů,����ʱ ��ά���ϵ�ÿһ�����������ڡ������ͳ��ʱ���Խ�ά��ֵ��ͬ�ļ�¼�ۺ���һ��,Ȼ��Ӧ �þۺϺ������ۼӡ�ƽ����������Сֵ�Ⱦۺϼ��㡣
-
����:�����ۺ�(�۲�)��ͳ��ֵ,Ҳ���Ǿۺ�����Ľ��������˵Ա�������в�ͬ�� ��Ա��������,�ֻ���˵��ͬһ����ְ��Ա���ж��١�
3.2 Cube �� Cuboid
? ����һ������ģ��,���ǿ��Զ����ϵ�����ά�Ƚ��оۺ�,���� N ��ά����˵,��ϵ����п����Թ��� 2^n �֡�����ÿһ��ά�ȵ����,������ֵ���ۺϼ���,Ȼ������� Ϊһ���ﻯ��ͼ,��Ϊ Cuboid������ά����ϵ� Cuboid ��Ϊһ������,��Ϊ Cube��

�����һ��������˵��,������һ�����̵��������ݼ�,����ά�Ȱ���ʱ��[time]�� ��Ʒ[item]������[location]��Ӧ��[supplier],����Ϊ���۶��ô����ά�ȵ���Ͼ��� 2^4 = 16 ��,����ͼ��ʾ: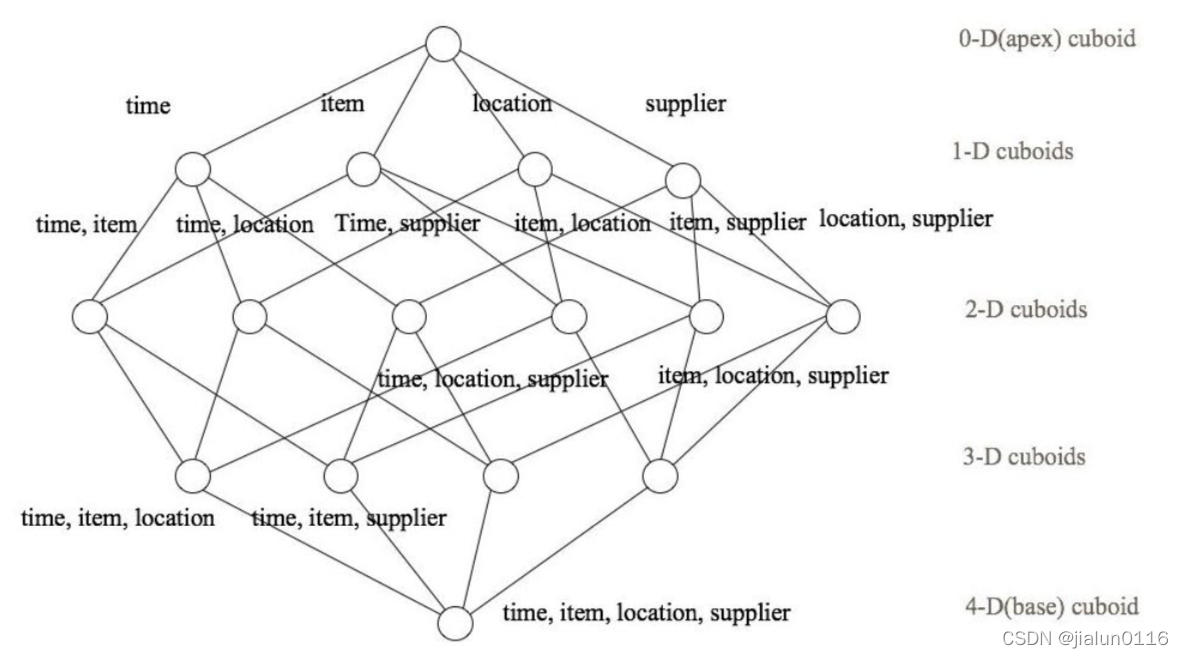
-
һά��(1D)�������:[time]��[item]��[location]��[supplier]4 ��;
-
����(2D)�������:[time, item]��[time, location]��[time, supplier]��[item, location]�� [item, supplier]��[location, supplier]3 ��;
-
��ά��(3D)�����Ҳ�� 4 ��;
-
�������ά��(0D)����ά��(4D)����һ��,�ܹ� 16 �֡�
ע��:ÿһ��ά����Ͼ���һ�� Cuboid,16 �� Cuboid �������һ�� Cube��
3.3 Cube �洢ԭ��
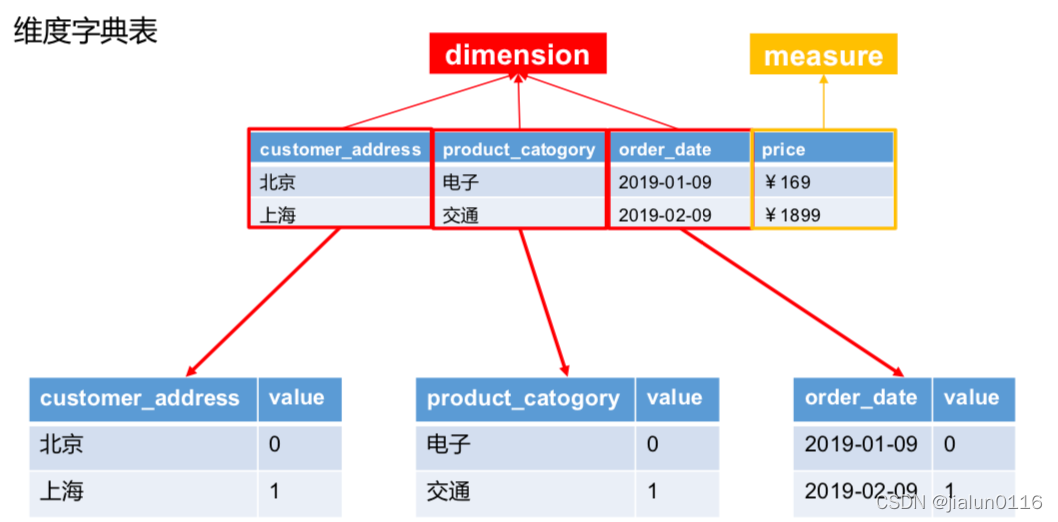
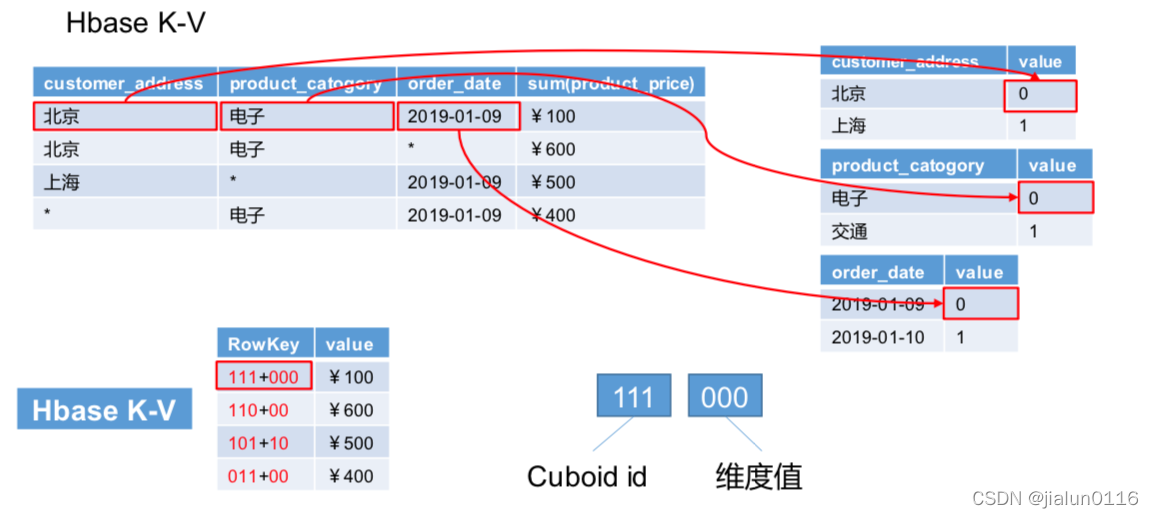
3.4 Cube��������
������property������
3.4.1 ��㹹���㷨 layer
ÿһ�ֵļ��㶼��һ�� MapReduce ����,�Ҵ���ִ��;һ�� N ά�� Cube,������Ҫ N �� MapReduce Job��
�������,���㷨��Ч�ʽϵ�,�����ǵ� Cube ά�����ϴ��ʱ��
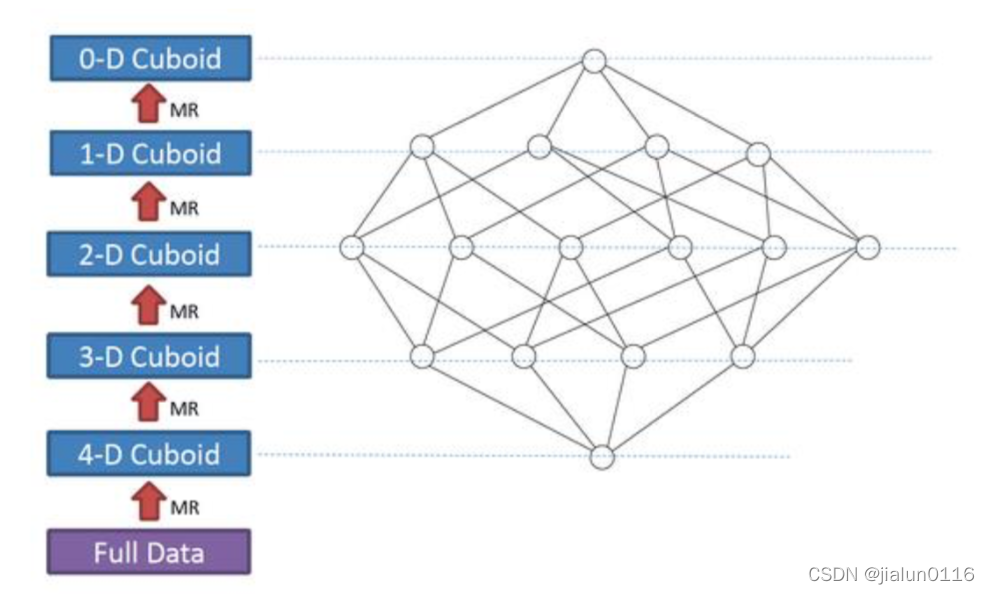
? ������㷨��,��ά����������������,ÿ���㼶�ļ���(���˵�һ��, ���Ǵ�ԭʼ���ݾۺ϶���),����������һ�㼶�Ľ���������������,[Group by A, B]�� ���,���Ի���[Group by A, B, C]�Ľ��,ͨ��ȥ�� C ��ۺϵ�����;�������Լ����ظ��� ��;�� 0 ά�� Cuboid ���������ʱ��,���� Cube �ļ���Ҳ������ˡ�һ����˵�Ƕ��MR����
�㷨�ŵ�:
-
���㷨��������� MapReduce ���ŵ�,�������м临�ӵ������ shuffle ����,�ʶ� �㷨����������,����ά��;
-
������ Hadoop ����������,���㷨�dz��ȶ�,�����Ǽ�Ⱥ��Դ����ʱ,Ҳ�ܱ�֤�� ���ܹ���ɡ�
�㷨ȱ��:
-
�� Cube �бȽ϶�ά�ȵ�ʱ��,����Ҫ�� MapReduce ����Ҳ��Ӧ����;���� Hadoop �����������Ҫ�ķѶ�����Դ,�ر��Ǽ�Ⱥ���Ӵ��ʱ��,�����ݽ�������ɵĶ������ �൱�ɹ�;
-
���� Mapper ������δ���оۺϲ���,����ÿ�� MR �� shuffle ���������ܴ�,����Ч�ʵ��¡�
-
�� HDFS ����д�����϶�:����ÿһ�����������������һ����������,��Щ Key-Value ��Ҫд�� HDFS ��;�����м��㶼��ɺ�,Kylin ����Ҫ�����һ��������Щ �ļ�ת�� HBase �� HFile ��ʽ,�Ե��뵽 HBase ��ȥ;
3.4.2 ���ٹ����㷨(inmem)
���� ������Ҫ˼����,ÿ�� Mapper ���������䵽�����ݿ�,�����һ��������С Cube ��(�� ������ Cuboid)��ÿ�� Mapper ��������� Cube ������� Reducer ���ϲ�,���ɴ� Cube,
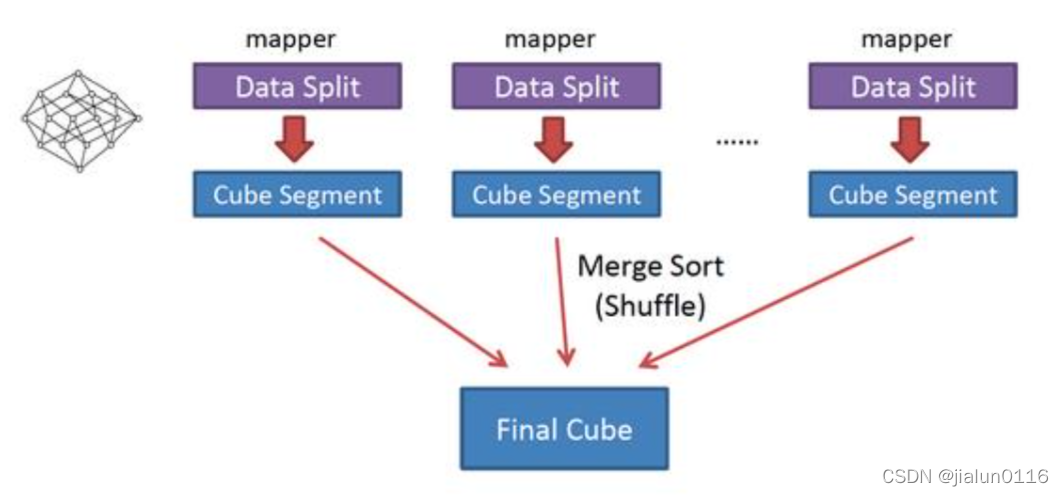
����㹹���㷨���,�����㷨��Ҫ�����㲻ͬ:
-
Mapper �������ڴ���Ԥ�ۺ�,����������;Mapper �����ÿ�� Key ���Dz�ͬ��, �������������� Hadoop MapReduce ��������,Combiner Ҳ������Ҫ;
-
һ�� MapReduce ���������в�εļ���,���� Hadoop ����ĵ��䡣
4. Cube�����Ż�
4.1 �������Cube
? ��Web GUI��Modelҳ��ѡ��һ��READY״̬��Cube,�����ǰѹ���Ƶ���Cube��Cube Size��ʱ,Web GUI����ʾCube��Դ���ݴ�С,�Լ���ǰCube�Ĵ�С����Դ���ݴ�С�ı���,��Ϊ������(Expansion Rate)��
? һ����˵,Cube��������Ӧ����0%~1000%֮��,���һ��Cube�������ʳ���1000%,��ôCube����ԱӦ����ʼ�ھ����е�ԭ��ͨ��,�����ʸ������¼��������ԭ��
-
Cube�е�ά�������϶�,��û�н��кܺõ�Cuboid��֦�Ż�,����Cuboid��������;
-
Cube�����ڽϸ�����ά��,���°�������ά�ȵ�ÿһ��Cuboidռ�õĿռ䶼�ܴ�,��ЩCuboid�ۻ��������Cube������;
4.2 ���������Ż�
? ��Segment��ijһ��Cuboid�Ĵ�С����һ������ֵʱ,ϵͳ�Ὣ��Cuboid�����ݷ�Ƭ�����������,��ʵ��Cuboid���ݶ�ȡ�IJ��л�,�Ӷ��Ż�Cube�IJ�ѯ�ٶ��������������Segment���ƵĴ�С,�Լ�����
- kylin.hbase.region.cut �����þ���Segment�ڴ洢�������ܹ���Ҫ�����������洢,����洢������HBase,��ô�����������Ͷ�Ӧ��HBase�е�Region������kylin.hbase.region.cut��Ĭ��ֵ��5.0,��λ��GB,Ҳ����˵����һ����С������50GB��Segment,����������������10��������
- kylin.hbase.region.count.min(Ĭ��Ϊ1)��kylin.hbase.region.count.max(Ĭ��Ϊ500)��������������ÿ��Segment���ٻ���౻���ֳɶ��ٸ�������
4.3 ʹ�þۺ���(Aggregation group)
�ۺ���(Aggregation Group)��һ��ǿ��ļ�֦���ߡ�����ҵ�����ֳ�������(��ȻҲ������һ����)
- ǿ��ά��(Mandatory),ǿ��ά���Լ�Ҳ���ܵ������֡�����涨��A,��ô�����ܹ��ṩ��ѯ�����������A
- �㼶ά��(Hierarchy),��-��-��,���µ�ʱ���������겻Ȼû�����塣��A����B
- ����ά��,��Щ����ά��Ҫôһ�����,Ҫô�������֡�
4.4 ʹ������ά��(derived dimension)
ʵ���Ͼ��ǰ�Ԥ�����ʱ���̯����ѯ��ʱ��,�����ά�ȱ�������ij��ά�ȱ�ά������Ҫ�ľۺϹ������dz���,��������ʹ������ά����
? ����ά����������Чά���ڽ�ά�ȱ��ϵķ�����ά���ų���,��ʹ��ά�ȱ�������(��ʵ����ʵ������Ӧ�����)��������ǡ�Kylin ���ڵײ��¼ά�ȱ�������ά�ȱ�����ά��֮����ӳ���ϵ,�Ա��ڲ�ѯʱ�ܹ���̬�ؽ�ά�ȱ������������롱����Щ������ά��,������ʵʱ�ۺϡ�

4.5 Row Key�Ż�
Kylin ������е�ά�Ȱ���˳����ϳ�һ�������� Rowkey,���Ұ������ Rowkey ���� ���� Cuboid �����е��С�
- ���������˵�ά�ȷ���ǰ�ߡ�
- �������ά�ȷ��ڻ���С��ά��ǰ�ߡ� ����㹹����ʱ��,����(1101��1110)������(11)�ľۺ�,��ѡ��cuboidС��(1101),���Ի������ά����ǰ��,�ܹ����þۺ�
5. ������Ŀ����
- ��½ϵͳ �� �������� (��Ŀ��������)
- ѡ���������ݵķ�ʽ(Hive�� ���� Kafka��),��ͬ������
- ����Model(���ƺ�����),ѡ����ʵ����ά�ȱ�,��join�ֶκͷ�ʽ(left��inner��);ѡ��ά����Ϣ,������Ϣ;���ӷ�����Ϣ����������
- ����Cube ,����������ά���ֶ�(������Ӱ�� Cuboid �ĸ���,����ֻ�ܴ� model ά���ֶ�����ѡ��),ѡ��ά�ȱ���ά���ֶκ�����(normal �� Derived),�����3������ά��cuboid������2^3 -1 = 7����������������ֵ�ֶ�(����Ԥ������ֶ�ֵ,ֻ�ܴ� model ����ֵ����ѡ��),��̬������ء��߽����á�property���á�Cube��Ϣչʾ,������ɡ����Բ鿴cube��ִ�мƻ��͵ײ�ִ�е�SQL
- ����Cube����Ԥ����,�鿴Build���Ⱥ���ϸִ�����
#!/bin/bash
# ÿ���Զ����� Cube
#�ӵ� 1 ��������ȡ
cube_name cube_name=$1
#�ӵ� 2 ��������ȡ���� cube ʱ��
if [ -n "$2" ]
then
do_date=$2
else
do_date=`date -d '-1 day' +%F` fi
#��ȡִ��ʱ��� 00:00:00 ʱ���(0 ʱ��)
start_date_unix=`date -d "$do_date 08:00:00" +%s`
#�뼶ʱ�������뼶
start_date=$(($start_date_unix*1000))
#��ȡִ��ʱ��� 24:00 ��ʱ��� stop_date=$(($start_date+86400000))
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'$start_date', "endTime":'$stop_date', "buildType":"BUILD"}' http://hadoop102:7070/kylin/api/cubes/$cube_name/build
6. ʹ��ע������
- ֻ�ܰ��չ��� Model ������������д SQL,����Modelʱ�õ���ʲôjoin��ֻ����ʲôjoin
- ��ѯʱ��ʵ����ǰ,ά�ȱ��ں�
- ֻ�ܰ��չ��� Cube ʱѡ���ά���ֶη���ͳ��
- ֻ��ͳ�ƹ��� Cube ʱѡ��Ķ���ֵ�ֶ�