SparkSQL
ǰ��
���Ľ���SparkSQL�����֪ʶ;
Spark ֪ʶϵ������
?? �˴��������й�Spark���֪ʶ����������,����Ҫ�Ŀ��Խ��е�����ġ�
һ��SparkSQL ����
?? SparkSQL��Spark���������ṹ�����ݵ�һ��ģ��,���ṩ��������̳���:DataFrame,DataSet,������Ϊ�ֲ�ʽSql��ѯ��������á�
1.1 DataFrame
?? DataFrameҲ��һ���ֲ�ʽ����������Ȼ��DataFrame����ͳ���ݿ�Ķ�ά����,������������,����¼���ݵĽṹ��Ϣ,��schema��ͬʱ,��Hive����,DataFrameҲ֧��Ƕ����������(struct��array��map)��DataFrame��Ϊ�����ṩ��Schema����ͼ���������������ݿ��е�һ�������Դ�,DataFrameҲ����ִ���ġ������ϱ�RDDҪ��,��Ҫԭ��:
?? �Ż���ִ�мƻ�:��ѯ�ƻ�ͨ��Spark catalyst optimiser�����Ż���
1.2 DataSet
?? RDD�е�������û�нṹ�� + ���ݽṹ -> DataFrame + ������� �C> DataSet
1.3 RDD��DataFrame��DataSet���ߵĹ�ϵ
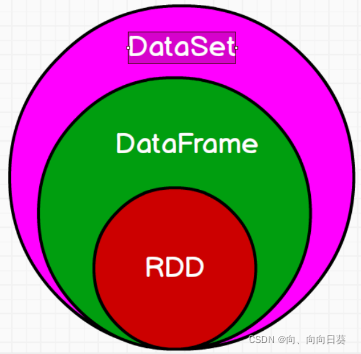
����SparkSQL�ı��
2.1 DataFrame
?? ��Spark SQL��SparkSession�Ǵ���DataFrame��ִ��SQL�����,����DataFrame�����ַ�ʽ:ͨ��Spark������Դ���д���;��һ�����ڵ�RDD����ת��;�����Դ�Hive Table���в�ѯ���ء�
2.1.1 ͨ��Spark������Դ���д���
(1)ͨ��SQL�ʵ��:
��������:
val df = Spark.read.json(��file:///opt/module/data/input/2.json��) #��ȡJson�ļ���
df.show
df.creatTempView(��student��) #��DataFrame����ת����һ����ʱ��ͼ,������Sql��ѯ
spark.sql(��select * from student��).show #�Ϳ���дSQL��
ע��:��ʱ����Session��Χ�ڵ�,Session�˳���,����ʧЧ�ˡ������Ӧ�÷�Χ����Ч,����ʹ��ȫ�ֱ���ע��ʹ��ȫ�ֱ�ʱ��Ҫȫ·������,��:global_temp.people
��������:
df.createGlobalTempView("emp")
spark.sql("SELECT * FROM global_temp.emp").show()
(2)DSL����:
1��ֻ�鿴��name��������:
?? df.select(��name��).show()
2���鿴��name���������Լ���age+1������:
?? df.select($��name��, $��age�� + 1).show()
3���鿴��age�����ڡ�21�������� :
?? df.filter($��age�� > 21).show()
4�����ա�age������,�鿴��������:
?? df.groupBy(��age��).count().show()
2.1.2 RDDת��ΪDataFrame
2.1.2.1 �ֶ�ת��
��������:
import spark.implicits._ //������ʽת��
val rdd = sc.makeRDD(List((1,"zhangsan",20),(2,"lisi",12),(3,"wangwu",52)))
val df = rdd.toDF("id","name","age")
2.1.2.2 ͨ��������
��������:
case class people(id:Int,name:String,age:Int) //����������
val rdd = sc.makeRDD(List((1,"zhangsan",20),(2,"lisi",12),(3,"wangwu",52)))
val peopleRDD = rdd.map(t=>{people(t._1,t._2,t._3)})
val df = peopleRDD .toDF()
2.1.3 ��DataFrameת��ΪRDD
ֱ�ӵ���RDD����;
��������:
val dfToRDD = df.rdd
2.2 DataSet
Dataset�Ǿ���ǿ���������ݼ���,��Ҫ�ṩ��Ӧ��������Ϣ��
2.2.1 ͨ�������ഴ��
��������:
case class people(name:String,age:Int) //����������
val caseclassDS = Seq(people("andy",12)).toDS //����DataSet
2.2.2 RDDת��ΪDataSet
ת������:RDD + �ṹ -> DataFrame + ���� -> DataSet
��������:
case class people(name:String,age:Int) //����������
val peopleRDD = rdd.map(t=>{people(t._1,t._2)})//��RDD���Ͻṹ����person
val peopleDS = peopleRDD.toDS //ת����DataSet,ע��ת����DataFrame��.toDF
2.2.3 DataSetת��ΪRDD��DataFrame
ֱ����ds.rdd����;
DataFrame -> DataSet: df.as[person],���������;ͻ��Զ�ת����;
DataSet -> DataFrame: ds.toDF
2.3 RDD,DataFrame,DataSet�ת��ʾ��ͼ
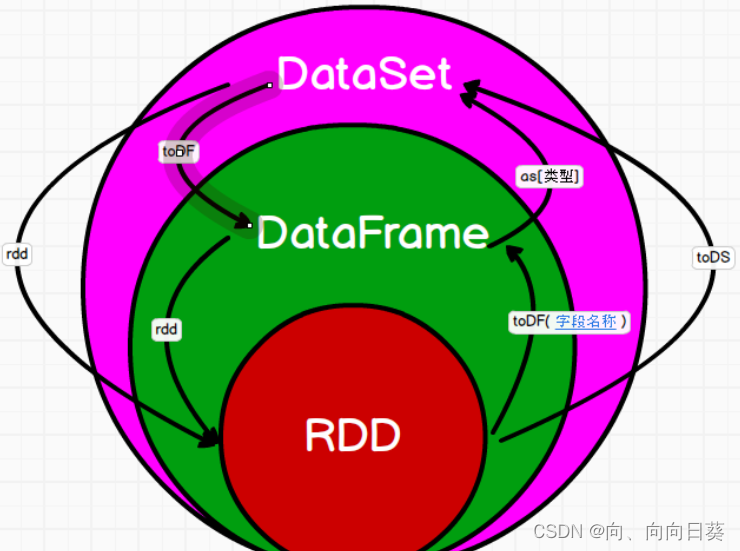
2.4 IDEAʵ�������ת��
����������:
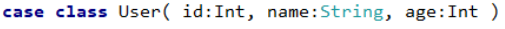
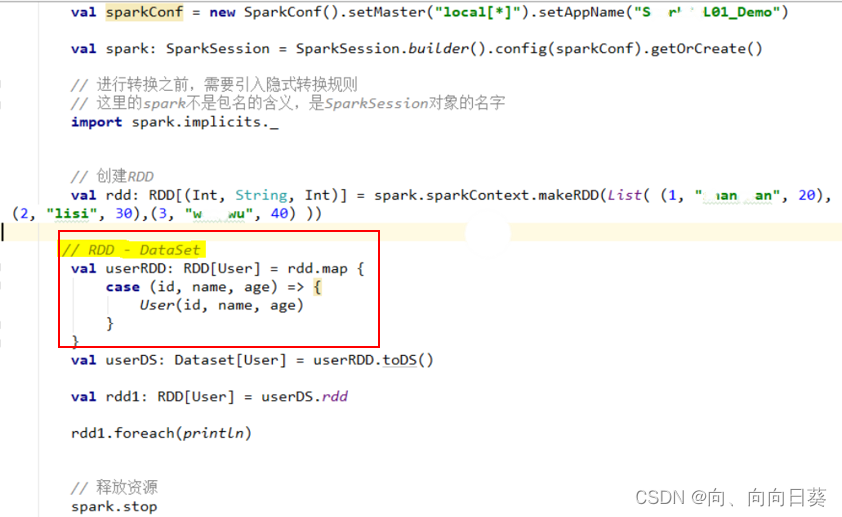
ʵ������ת��:

ʵ����RDDֱ��ת����DataSet:
2.5 �û��Զ��庯��
2.5.1 �û��Զ���UDF����
��������:
val df = Spark.read.json(��file:///opt/module/data/input/2.json��) #��ȡ���ݹ���DataFrame����
//�Զ��庯��:�ڴ��������ַ���ǰ����ϡ�name���ַ���:
spark.udf.register("addName",(x:String)=>"Name:"+x)
df.createTempView("users")//������ʱ��ͼ
spark.sql("select addName(name) from users").show //���ú����鿴Ч��
2.5.2 �û��Զ���ۺϺ���
�Զ����������ƽ��ֵ�ľۺϺ���
2.5.2.1 ������
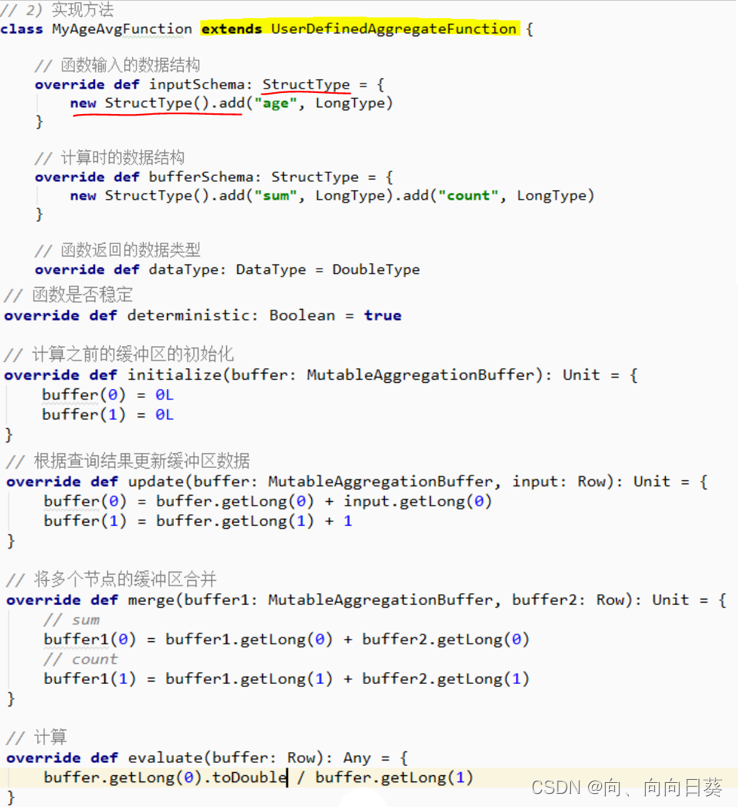
���ú���:
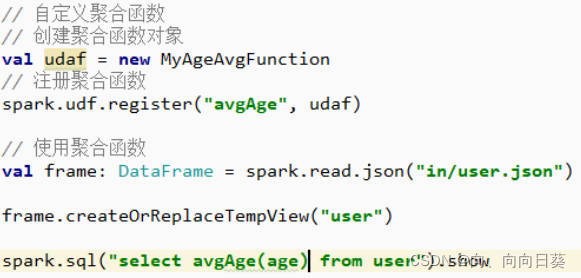
2.5.2.2 ǿ����
���÷��� -> ����������
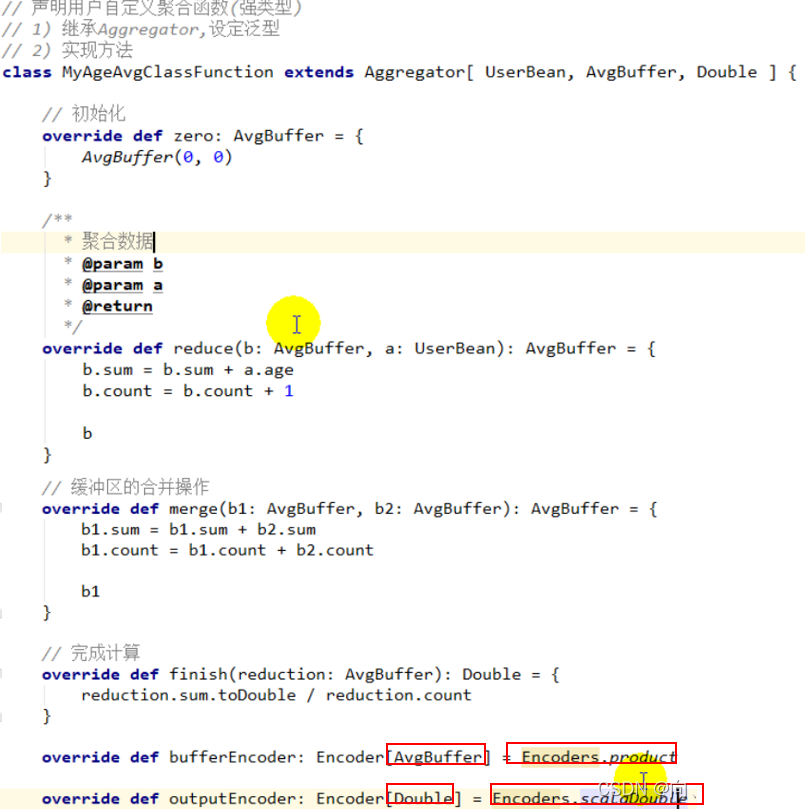
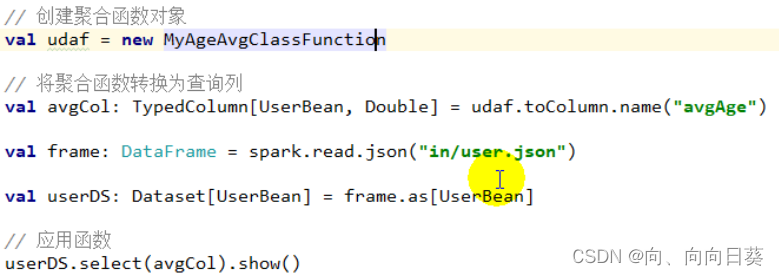
�Զ�������ת��������(����ע��),double������ת��������,���̶���;
���ú���:
����SparkSQL ������Դ
?? Spark SQL��Ĭ������ԴΪParquet��ʽ������ԴΪParquet�ļ�ʱ,Spark SQL���Է����ִ�����еIJ�������������spark.sql.sources.default����Ĭ������Դ��ʽ��

?? ������Դ��ʽ����parquet��ʽ�ļ�ʱ,��Ҫ�ֶ�ָ������Դ�ĸ�ʽ������Դ��ʽ��Ҫָ��ȫ��(����:org.apache.spark.sql.parquet),�������Դ��ʽΪ���ø�ʽ,��ֻ��Ҫָ����ƶ�json, parquet, jdbc, orc, libsvm, csv, text��ָ�����ݵĸ�ʽ��

�ļ�����,Ĭ�ϱ����ʽparquet:

����ΪĿ���ʽ(json):

�����ļ�д��ģʽ-��:

�ļ�д�������ģʽ:
(1)error(Ĭ��) ����ļ����ھͱ���
(2)append ��
(3)overwrite ��д
(4)ignore ���ݴ��������
�ܽ�
���Ľ�����SparkSQL�����֪ʶ;����в���֮�����߱��������ĵط���ӭ���ָ����