路线
- hadoop 高效计算
- spark 内存级引擎 数据挖掘与机器学习利器
- flink 大数据计算引擎
特点
- 大量 TB
- 快速
- 低价值密度 提纯
- 多样 结构化、非结构化
hadoop
分布式系统基础架构
解决
海量数据存储
海量数据分析计算
优势
- 高可靠性 维护多个副本
- 高扩展性 动态扩展节点
- 高效性 并行工作
- 高容错性 将失败的任务重新分配
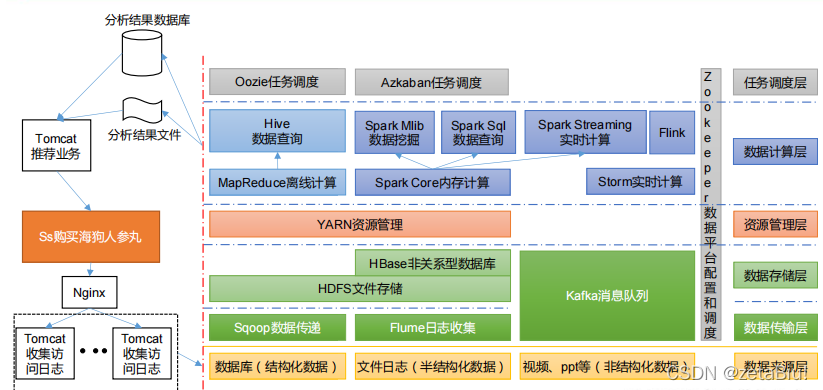
Hadoop Distributed file System HDFS 分布式文件系统
解决海量数据存储问题,适合一次写入多次多出的场景
组成
- nameNode(nn)存储文件的元数据
- dataNode 本地文件系统系统文件块数据
- Secondary NameNode 每隔一段时间对nameNode元数据备份,分担nameNode工作量如:定期合并Fsimage和Edits
- mapReduce 计算 分为map reduce ,map阶段并行输入数据,reduce对map结果汇总
- client 文件切分、与NameNode交互、与DataNode交互、管理HDFS
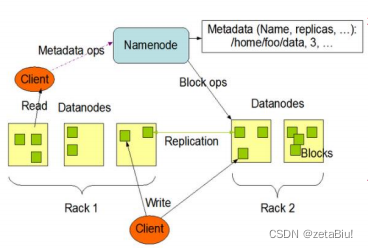
HDFS文件块大小block
配置dfs.block控制大小 默认128M。
寻址时间为纯属时间的1%为最佳状态
读写流程
写数据

读数据流程
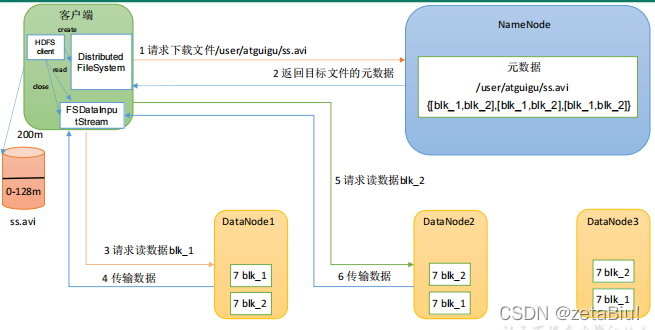
nameNode工作机制
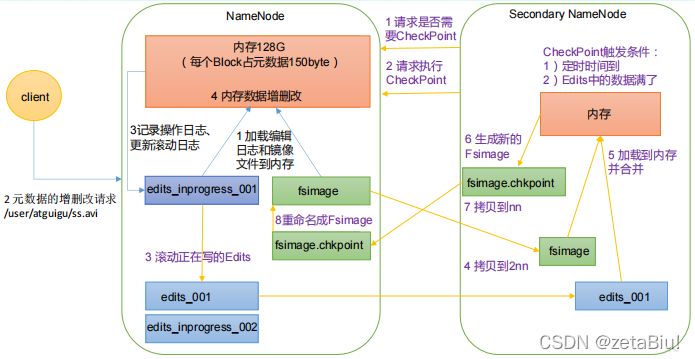
Fsimage 和Edits
Fsimage文件:一个永久性的检查点
checkPoint时间机制
掉线时限参数设置
网络拓扑 节点距离
节点距离:两个节点到达共同祖先的距离和
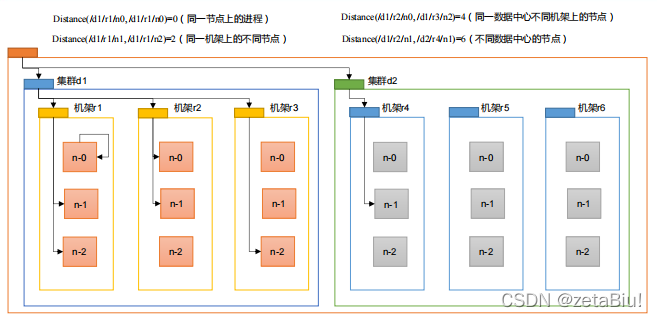
机架感知
副本节点的选择
mapReduce
序列化
输入数据 inputFormat
Shuffle
OutFormat
Join
ETL
压缩
p68
扩展
GFS-》HDFS
Map-Reduce->MR
BigTable->HBase