1.简单介绍一下 Flink
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink 提供了诸多高抽象层的API 以便用户编写分布式任务:
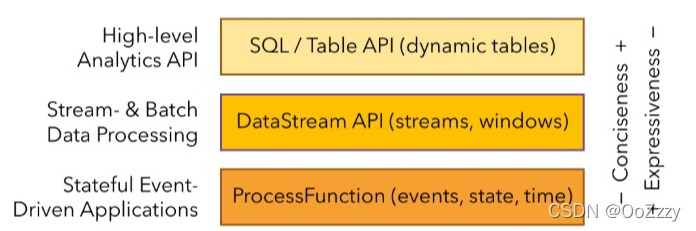
最底层为ProcessFunction,是可以获取状态的最底层的函数,可以获取当前事件和时间,中间的一层是DataStream,可以定义窗口windows,最上的一层是Flink sql和Table api,和hive一样可以通过SQL进行转换操作
1.DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用 Flink 提供的各种操作符对分布式数据集进行处理,支持 Java、Scala 和Python。
2.DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持 Java 和 Scala。
3.Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL的 DSL 对关系表进行各种查询操作,支持 Java 和 Scala。
此外,Flink 还针对特定的应用领域提供了领域库,例如: Flink ML,Flink 的机器学习库,提供了机器学习 Pipelines API 并实现了多种机器学习算法。 Gelly,Flink 的图计算库,提供了图计算的相关 API 及多种图计算算法实现。
2.Flink的架构
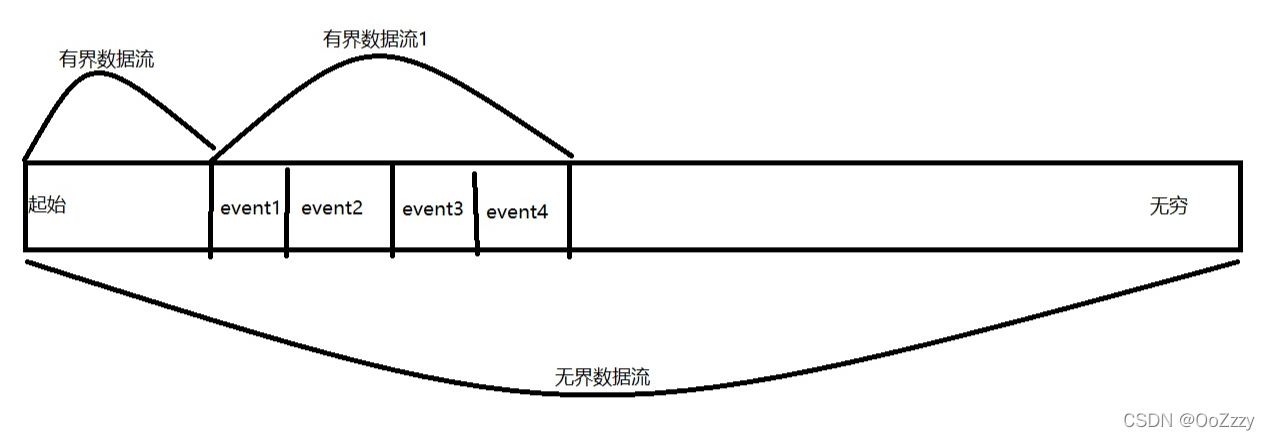
简单理解无界流和有界流
无界流:流数据不会停止,没有边界,需要实时处理,绝对的实时处理,来一条,处理一条。
有界流:定义了数据的范围,类比Spark-Streaming中的微批次处理,Hive离线Mr处理。
无界流相当于实时,有界流相当于离线
Fink可以部署在Yarn,K8s,Mesos多种资源调度框架中。
3.wordcount
maven
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<!--Flink sql/ table api-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20 </version>
</dependency>
</dependencies>
wc:
流式处理:
public class WordCount02 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> inputStream = env.readTextFile("E:\\atguiguDemo03\\leet-code\\flink04_java\\src\\main\\resources\\wc.txt");
DataStream<Tuple2<String, Integer>> resultStream = inputStream.flatMap(new WordCount01.MyFlatMapFunction()).keyBy(0).sum(1);
resultStream.print();
env.execute();
}
}
批处理:
public class WordCount01 {
// 批处理DataSet, 离线数据
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataSet<String> inputStream = env.readTextFile("E:\\atguiguDemo03\\leet-code\\flink04_java\\src\\main\\resources\\wc.txt");
AggregateOperator<Tuple2<String, Integer>> resultSet = inputStream.flatMap(new MyFlatMapFunction()).groupBy(0).sum(1);
resultSet.print();
}
public static class MyFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>>{
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(" ");
for (String s : arr) {
out.collect(new Tuple2<>(s, 1));
}
}
}
}

4.Flink的部署
解压
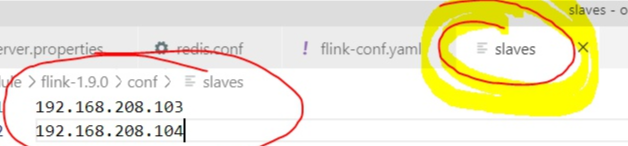
编写conf/slaves文件,填加从机IP地址。
slave
主master
分发文件到从机,分发脚本如下。
#!/bin/bash
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
p1=$1
fname=`basename $p1`
echo fname=$fname
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
user=`whoami`
//注意下一行你必须修改,换成主机名,或者你的IP
for((host=102;host<105;host++)); do
echo --------hadoop$host--------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
启动集群
bin/start-cluster.sh